一、聊聊常见的负载均衡算法
所谓负载均衡, 就是把压力(运算压力、网络压力、存储压力等等)分散到多个服务节点上。常见的负载均衡算法包括轮询(round robin)、随机、加权轮询、加权随机、平滑加权随机、传统Hash、一致性Hash等等。
先看以下几类负载均衡算法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LCcdZmWU-1666459779866)(evernotecid://27EA8193-8C04-4ED5-9955-5AC48B5858F4/appyinxiangcom/14237713/ENResource/p34)]](https://img-blog.csdnimg.cn/79873e3e33dc45678867d993ec8227f2.png)
1.随机、轮询: 最简单, 一视同仁
随机: 随机选取一个节点。
轮询: 按照顺序依次选取节点。
以上两种算法的优点是实现简单、配置简单。
但当集群中节点的性能存在差异时,这两种算法就无法满足需求。例如集群中的服务节点有2核、4核、16核等多种规格,我们希望16核的机器被分配更多的流量。
2.加权: 差异对待, 能力越大责任越大
加权随机、加权轮询: 是在随机、轮询算法的基础上考虑到了节点的性能, 支持性能更强大的节点承担更多的负载。
在使用加权随机、加权轮询时, 不仅要配置节点列表, 还要配置节点的权重。
例如:
| 节点 | 机器核心数 | 权重 |
|---|---|---|
| node0 | 4 | 2 |
| node1 | 10 | 5 |
| node2 | 14 | 7 |
3.平滑加权
加权轮询考虑了节点间的性能差异, 但在使用中会发现权重高的节点总是会被连续选中, 例如编号1、2、3、4、5的5个节点权重分别是4、1、1、1、1, 加权轮询的选中顺序可能是这样的:
1,1,1,1,2,3,4,5,1,1,1,1,2,3,4,5,1,1,1,1,2,3,4,5…
权重最高的节点1经常会被连续选中, 对于某些程序来说, 连续的选择同一个节点导致的高并发会影响运行效率, 会希望选中的节点"打散"一些,类似下面这样:
1,2,1,3,4,1,5,1,1,2,1,3,4,1,5,1,1,2,1,3,4,1,5,1…
平滑加权轮询的"平滑"就是解决上述问题, 平滑轮询算法的实现除了要求设置每个节点的"设定权重"外,还要为每个节点维护额外的变量"当前权重"。
计算方式如下:
-
各节点 当前权重© 初始值设为 各节点的 设定权重(w), 计算出 权重和(wSum)
-
选取 当前权重最大 的节点(cMax), 更新该节点的 当前权重©=当前权重©-权重和(wSum)
-
各节点的当前权重© = 各节点当前权重© + 各节点设定权重(w)
至此, 我们已经有了很多负载均衡策略可供选择。但仍有些应用场景无法满足。
例如:
- 需要做会话保持的场景(重连后被分配到同一个节点)。
- 需要持久化数据的场景(数据持久化时使用负载均衡算法做分片,查询时要能知晓数据存储在哪个节点上)。
4.传统Hash算法: 节点不变,映射不变
传统Hash算法:在节点不变的情况下, 同一id总会被映射到同一节点
例如有5个请求, 各自有一个id(使用参数中某个字段做散列):
requests = [
reqeust0:{id:0},
reqeust1:{id:1},
reqeust2:{id:2},
reqeust3:{id:3},
reqeust4:{id:4}]
此时我们有3个服务节点 nodes = [node1, node2, node3]
传统Hash利用以下规则选取节点:
请求中某个字段散列得作为id,使用id对节点总数取余, 得到节点的下标。
request0 映射到 node1 (0 % 3 = 0)
request1 映射到 node2 (1 % 3 = 1)
request4 映射到 node2 (4 % 3 = 1)
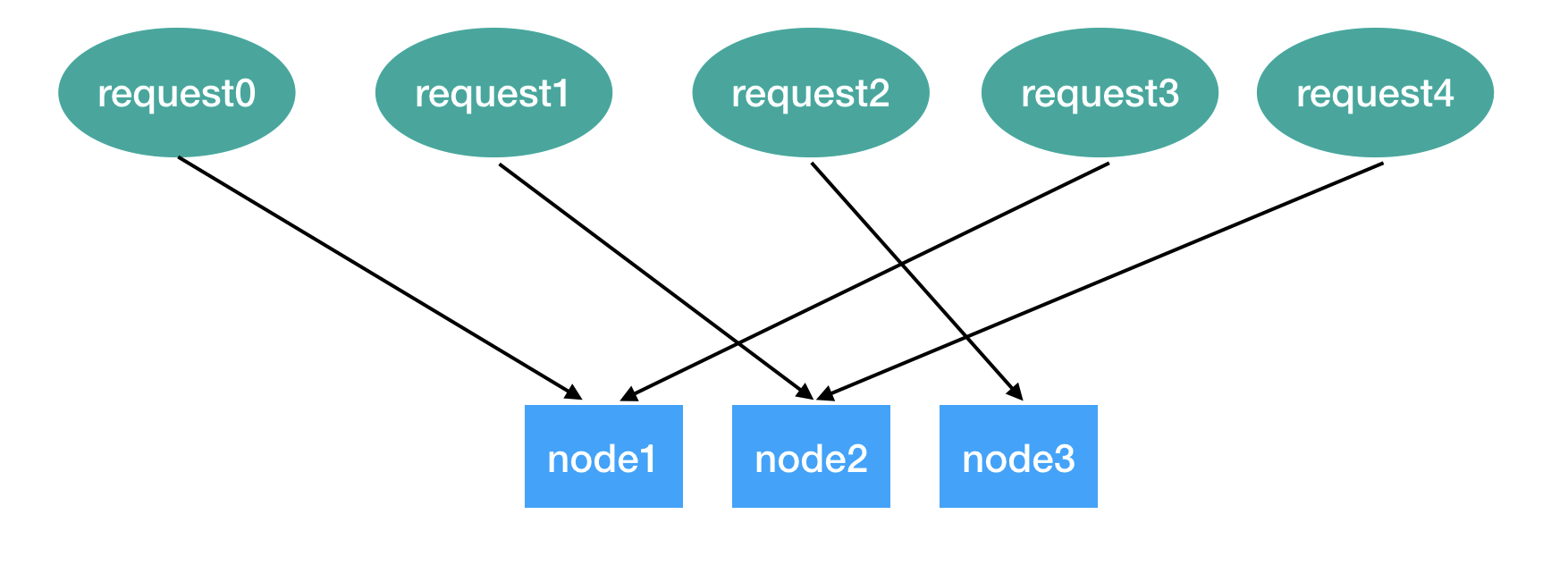
有了这样的映射规则, 一个请求被哪个节点处理了, 一个数据分片存储到哪个节点上都可以计算出来, 无需自行维护一份映射关系。
但这份美好的前提是"节点数量不变"。
在持久化存储场景下, 当服务节点需要扩缩容、停机、维护、更新或者发生故障时总无法避免节点数量发生变化。节点数量发生变化, 映射就有了新的规则, 通过新规则查老数据是行不通的, 同一份数据可能被新老规则映射到不同的节点。此时一种常见的应对方案是让老数据"搬家"(重平衡)。
二、传统Hash重平衡的代价
重平衡(reblance), 即通过数据迁移将数据放到符合"新规则"的位置。
我们看一下让老数据"搬家"的代价吧, 假如有1w条数据id从0到9999,分布在5个节点上, 当节点数变为4或者6时, 有多少数据需要迁移? 我写了一段代码模拟如下。
public static void main(String[] args) {
reBalance(10000, 5, 4);
System.out.println();
reBalance(10000, 5, 6);
}
public static void reBalance(int dataCount, int nodeCountBefore, int nodeCountAfter) {
System.out.println("数据量:" + dataCount + ", 迁移前节点数:" + nodeCountBefore + ", 迁移后节点数:" + nodeCountAfter);
int[] transfer = new int[nodeCountBefore];
int transferTotal = 0;
for (int i = 0; i < dataCount; i++) {
int nodeIdBefore = i % nodeCountBefore;
int nodeIdAfter = i % nodeCountAfter;
if(nodeIdBefore != nodeIdAfter) {
transfer[nodeIdBefore] += 1;
}
}
for (int i = 0; i < transfer.length; i++) {
transferTotal += transfer[i];
System.out.println("需要从节点" + i + "迁出" + transfer[i] + "条数据");
}
System.out.println("共迁出" + transferTotal + "条数据,占比:" + transferTotal*1.0d/dataCount);
}
这段代码的执行结果是:
数据量:10000, 迁移前节点数:5, 迁移后节点数:4
需要从节点0迁出1500条数据
需要从节点1迁出1500条数据
需要从节点2迁出1500条数据
需要从节点3迁出1500条数据
需要从节点4迁出2000条数据
共迁出8000条数据,占比:0.8
数据量:10000, 迁移前节点数:5, 迁移后节点数:6
需要从节点0迁出1666条数据
需要从节点1迁出1666条数据
需要从节点2迁出1666条数据
需要从节点3迁出1666条数据
需要从节点4迁出1666条数据
共迁出8330条数据,占比:0.833
可以看出当节点数量从5变化到4、从5变化到到6, 需要迁移的数据量占比分别为总量的80%和83.33%, 这是一个很恐怖的数字。
尤其在分布式存储场景, 如此大的迁移量会造成带宽和计算资源的浪费, 更严重的是短时间大量迁移数据造成机器资源挤兑会导致服务一段时间内不可用。
三、一致性Hash
1.一致性Hash算法介绍
降低重平衡的代价, 就是尽量保持"不动", 一致性Hash是这样做的:
- 使用一串连续的数字(例如数字0到9999)首尾相连构造成一个Hash环。
- 将节点分散到Hash环上(一般会使用节点的某个tag做散列), 记住节点对应位置的数字。
例如:node0:2000, node1:4000, node2:6000, node3:8000
- 有10000条数据要分配到4个节点上, 将数据散列到0到9999范围内。
- 假如某一条数据data的id散列后是位置是666,那么在Hash环上找到这个点的位置, 顺时针方向查找最近的节点, 本例中data顺时针方向最近的节点是node0:2000。
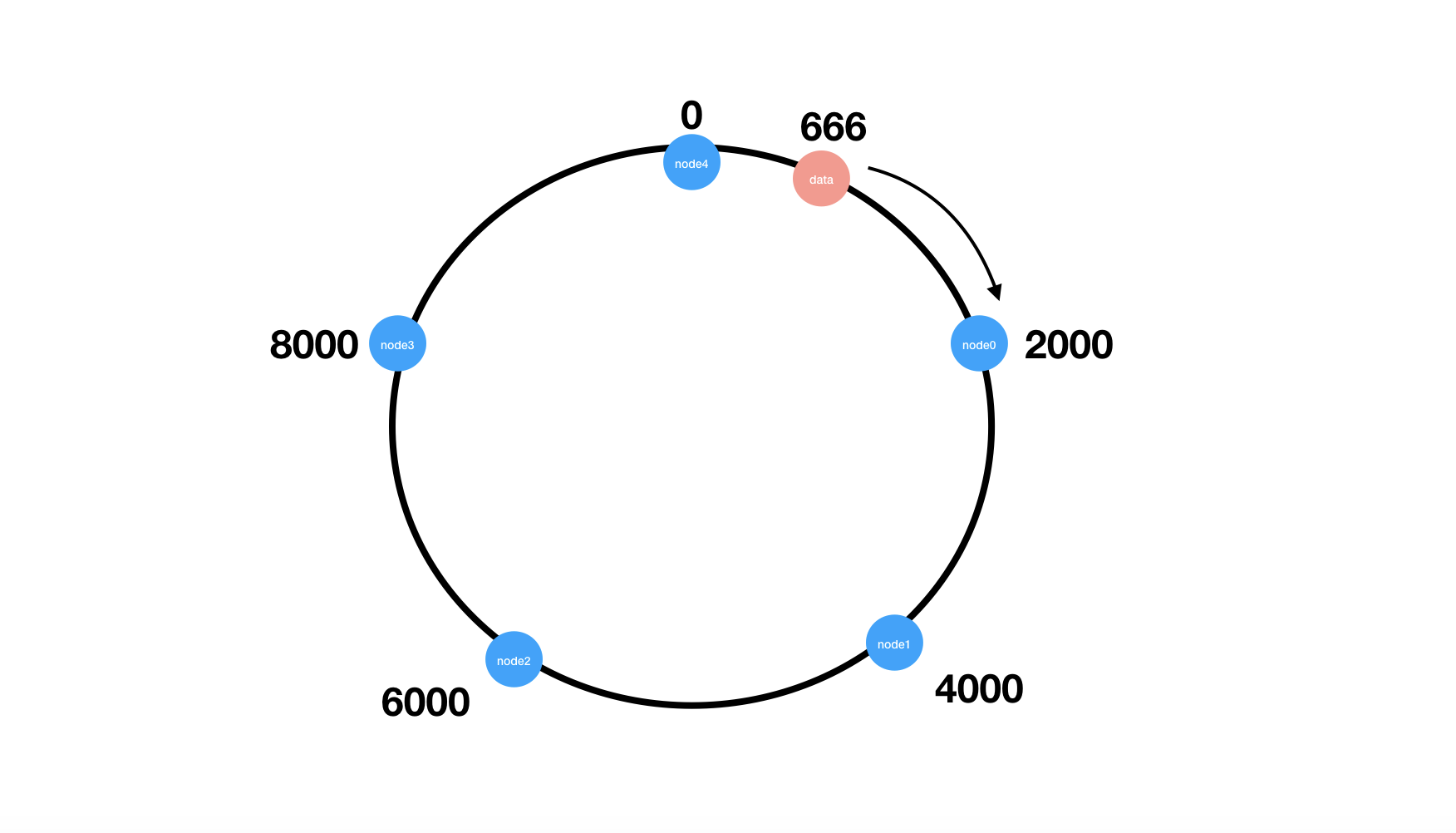
2.一致性Hash算法的重平衡(reBalance)
现在让我们看看减少一个节点(node0)时, 一致性Hash算法要做哪些数据迁移。
只需要将node0的数据迁移到顺时针方向最近的节点(node1)即可。
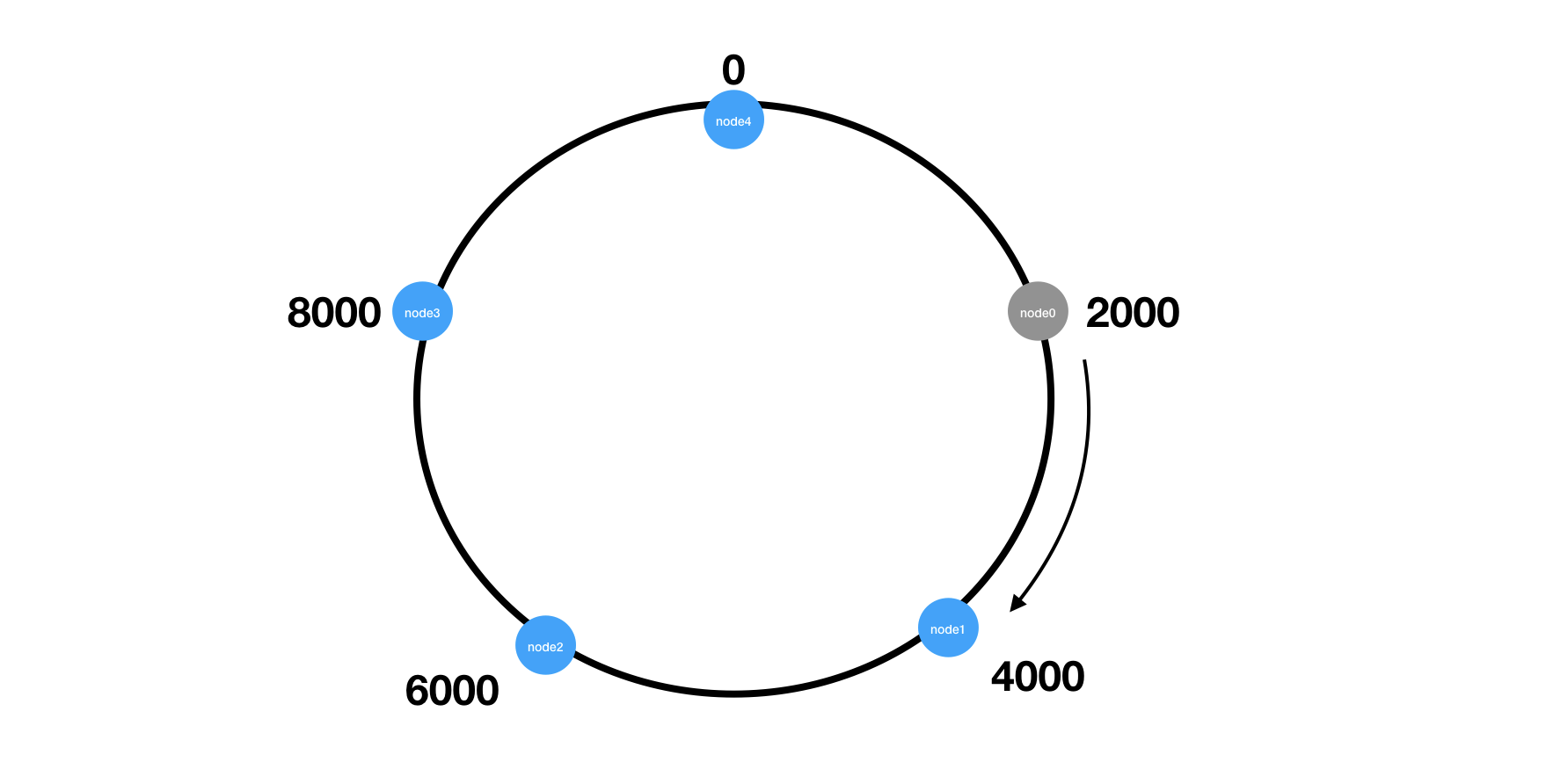
这就是一致性Hash最神奇的地方, 除了node0节点的数据,我们可以让其它节点的数据保持不动。
那增加一个节点呢?
例如再node4和node0之间增加一个node5, 那么原本一些需要node0承担的量被node5"拦截住了", 那么只需要将这部分数据从node0迁移到node5(图中橙色部分)。
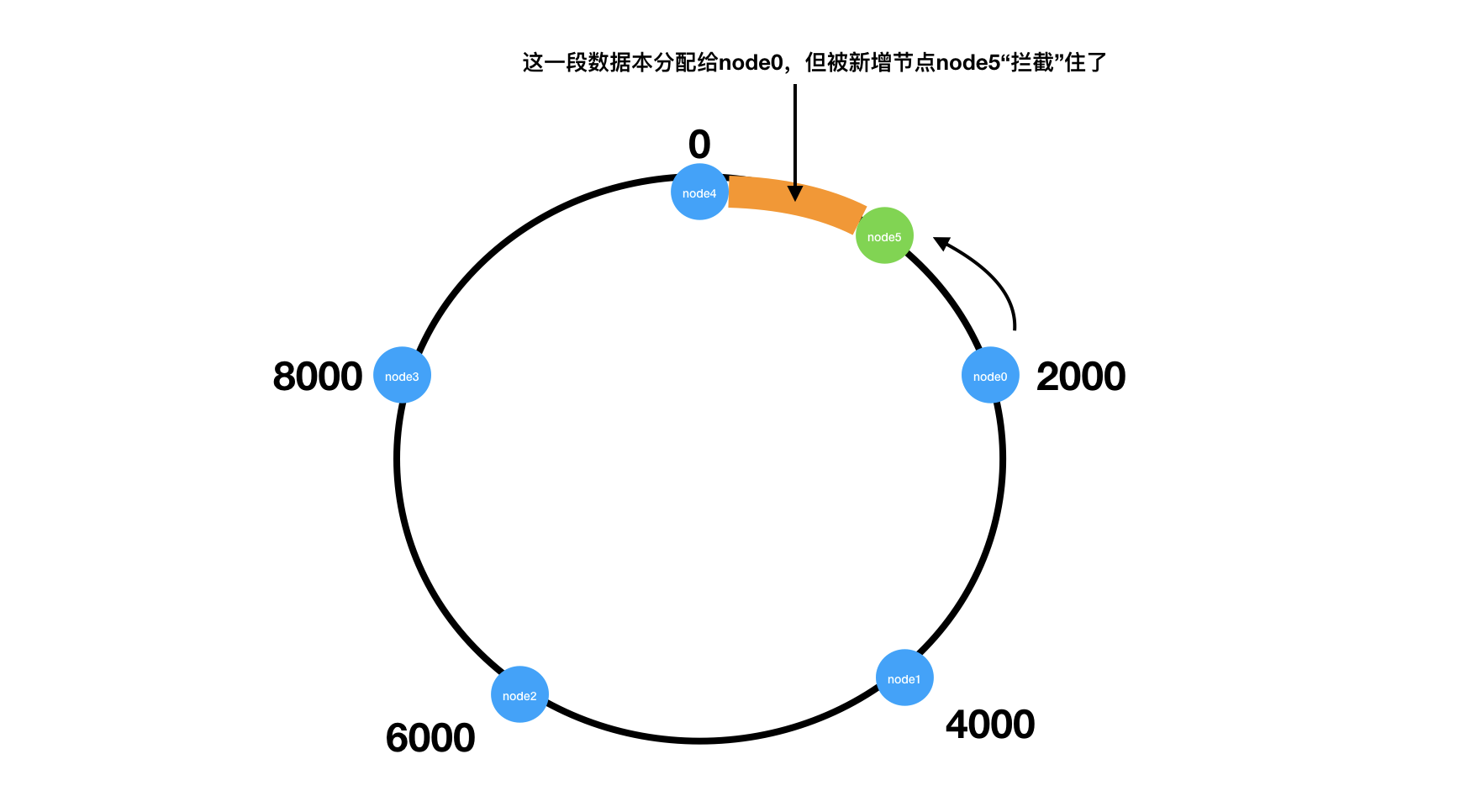
这样数据的迁移量就被控制在一个较小的范围内。
但是,等等好像有什么不对?
虽然迁移的数据量是减少了, 但是当减少一个节点(node0)时, 顺时针方向邻节点(node1)承担了所有原本属于node0的压力, 这是不可接受的, 我们不能让各节点平时都预留如此多的冗余资源。
当新增一个节点(node5)时, 只是减轻了顺时针方向邻节点(node0)的压力, 其它节点的压力没有得到丝毫减轻。
为了解决这个问题,一致性Hash引入了虚拟节点。
3.一致性Hash的虚拟节点
虚拟节点就是给真实节点创造足够多的虚拟"分身", 分散到Hash环上。分身足够多,足够分散,就能避免压力分布不均的情况。
向集群中添加一个真实节点时, 以一定规则向Hash环上分散的添加多个"分身"(一种实现方式是节点id加上数字后缀, 例如node0_0, node0_1, node0_2, node1_0, node1_1, node1_2…), 使用了虚拟节点的Hash环大概长下面这个样子:
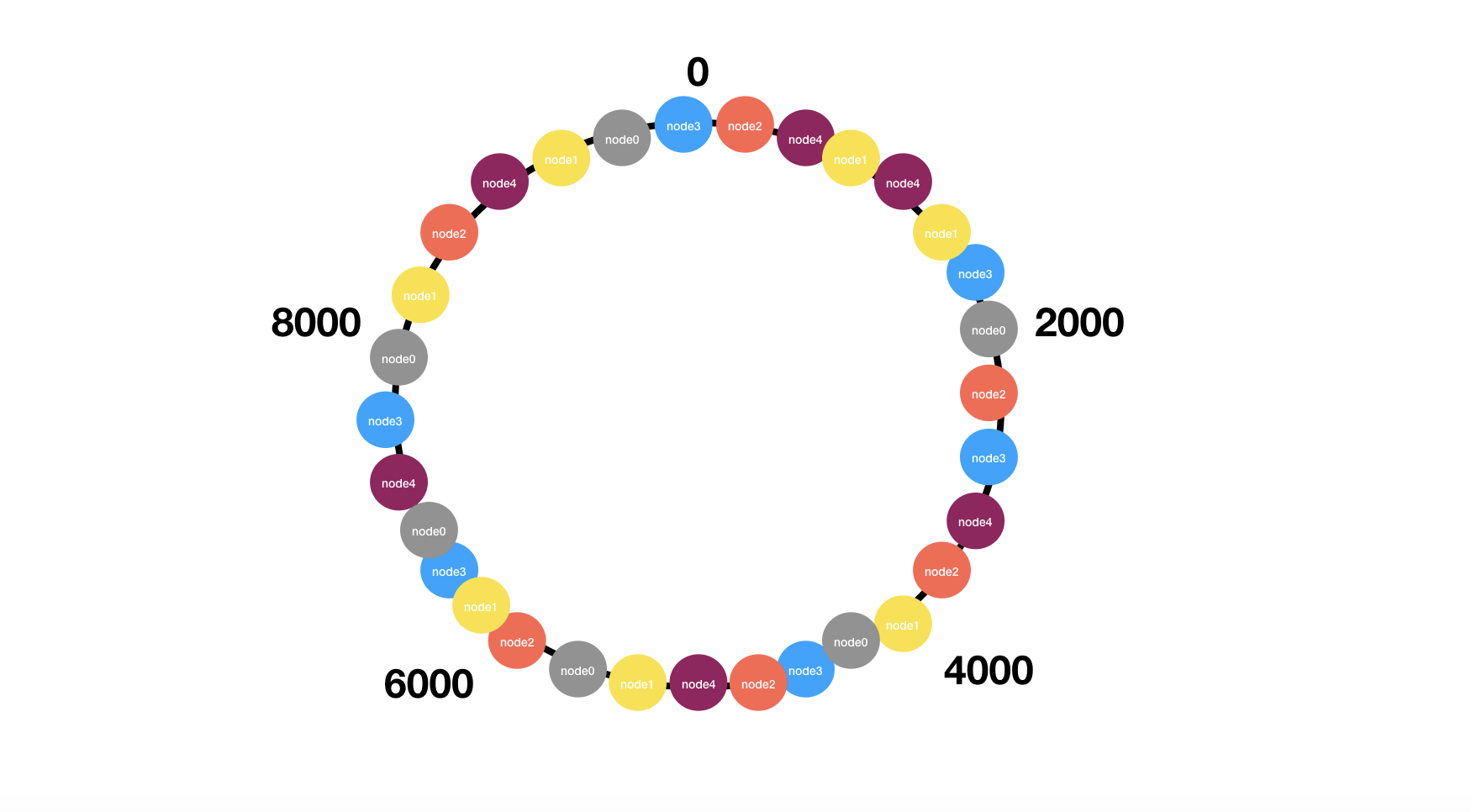
减少一个真实节点时, 也要相应的把该节点的"分身"全部删除,这样其它各个节点的虚拟节点有机会承载它的压力。
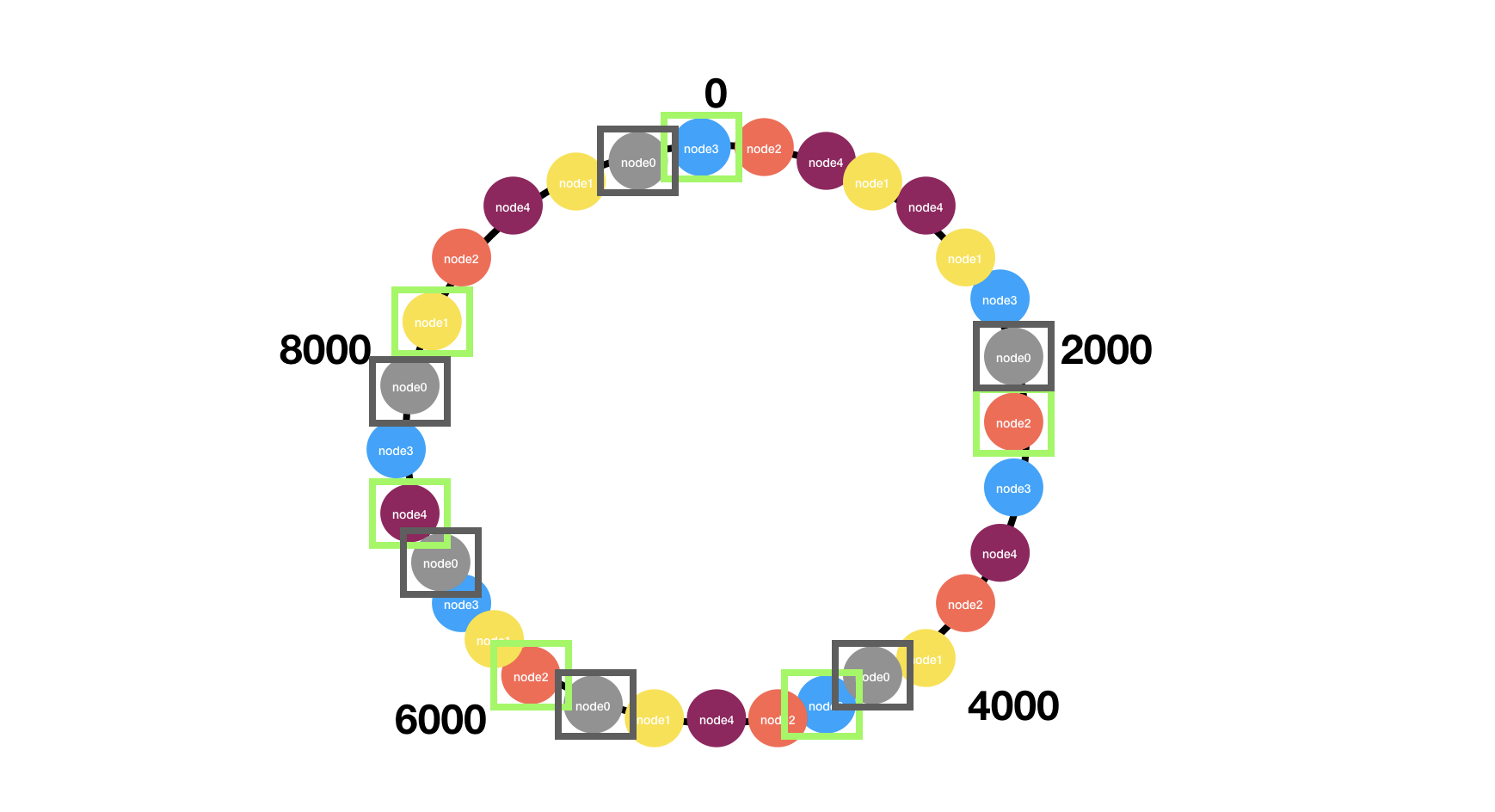
图中下线了node0节点,它的虚拟节点顺时针方向最近的虚拟节点分别代表node3、node2、node3、node2、node4、node1
它的负载也被这些节点所分担。
至此一致性Hash算法的基本内容就介绍完毕。
关于一致性Hash的"实现细节"、“散列函数选择”、“如何在使用一致性Hash时考虑节点性能差异”、"虚拟节点数量该如何设置"等话题将另作探讨。
一致性Hash作为分布式存储技术的基石之一, 它的简洁与强大在各种对象存储、分布式数据库、分布式缓存产品中得以体现。在某些非数据存储领域用作负载均衡策略往往也是一个不错的选择。
但技术方案的选择并没有"万金油", 选用哪种负载均衡算法还是取决于具体的业务场景, 毕竟合适的才是最好的。作为开发者, 还是要多积累、多吸收, 才能做出好的决策。