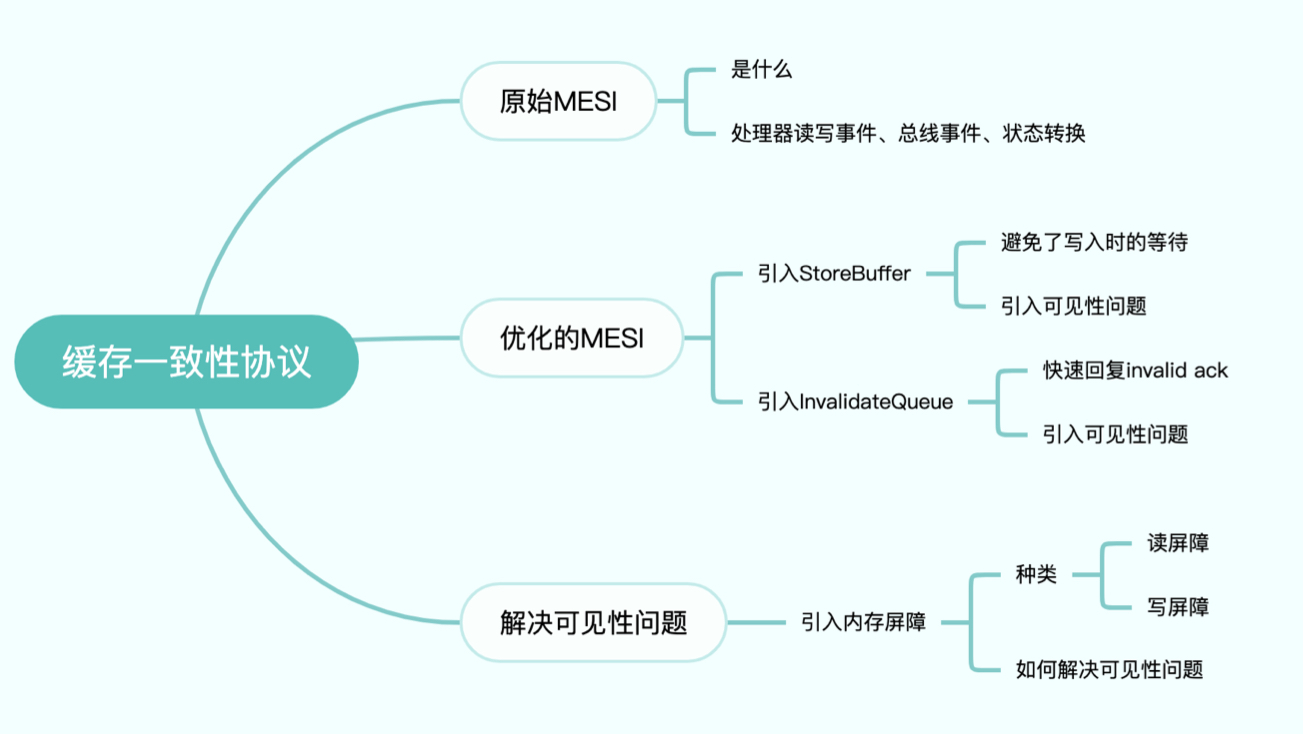
一、背景
CPU在执行任务时会频繁读写内存中的数据,等待内存数据的读写完成是耗时操作,会拖慢CPU的运行速度。
所以一般在CPU上都集成了比内存更快的高速缓存。CPU会尽量多与高速缓存打交道,即将数据从主内存加载到缓存,后续对这个数据的操作在缓存内进行,再适时将缓存数据刷入主内存,以此提高CPU任务执行效率。
但这也带来了问题,在多核心的情况下,多核心操作同一数据时都将数据加载到自己的缓存中,后续某个核心对该数据的修改在刷入主内存前对其它核心是不可见的,这就带来了一致性问题。
缓存一致性协议就是为了解决这种问题发明的,MESI协议是支持写回(write-back)缓存的常用协议, 也称为伊利诺伊协议。现代CPU使用的缓存一致性协议很多都是在MESI的基础上发展而来的。
二、原始MESI解读
1.四种状态
MESI协议中,缓存有四种状态:
- M(modified) 已修改: 缓存行已被修改
- E(exclusive) 独占: 缓存行只被该核心缓存(因为是独占的,修改数据不需要问其它核心)
- S(shared) 共享: 缓存行被多个核心缓存(不能直接写,需要通知其它核心)
- I(invalid) 失效: 缓存行失效(读取时要从其它缓存或主内存读)
2.两类请求
(1)处理器读写请求
一类是处理器对缓存的请求,包括读请求和写请求。
- PrRd:处理器请求读缓存。
- PrWr:处理器请求写缓存。
(2)总线请求
处理器之间、处理器与主内存之间通过Bus(总线)交换事件和数据。
- Bus:可以理解为多核心之间、核心与内存之间交流的一个通道。
- Bus Snooping:用来监听总线事件。
前面提到的处理器对缓存的读、写请求会根据需要触发总线请求,总线请求会在总线上广播,其它处理器侦听到总线请求后根据自己的状态作出回应,总线请求、回应的过程叫作总线事务。MESI相关的总线请求有如下几种。
- BusRd:有处理器发起了读请求。
- BusRdX:有处理器发起了写请求,但它没有该缓存行。
- BusUpgr:有处理器发起了写请求,它有该缓存行。
- Flush:处理器将缓存刷到了主内存。
- FlushOpt:处理器将缓存数据发送给Bus。
3.状态转换的一个例子
这里列举一个例子简单说明缓存行状态、总线事件、总线侦听之间的关系:
cpu0要读一行数据(主内存内a=1),这行数据还没有被加载到处理器缓存中,这个缓存行的初始状态就是I(invalid),需要从主内存读取。
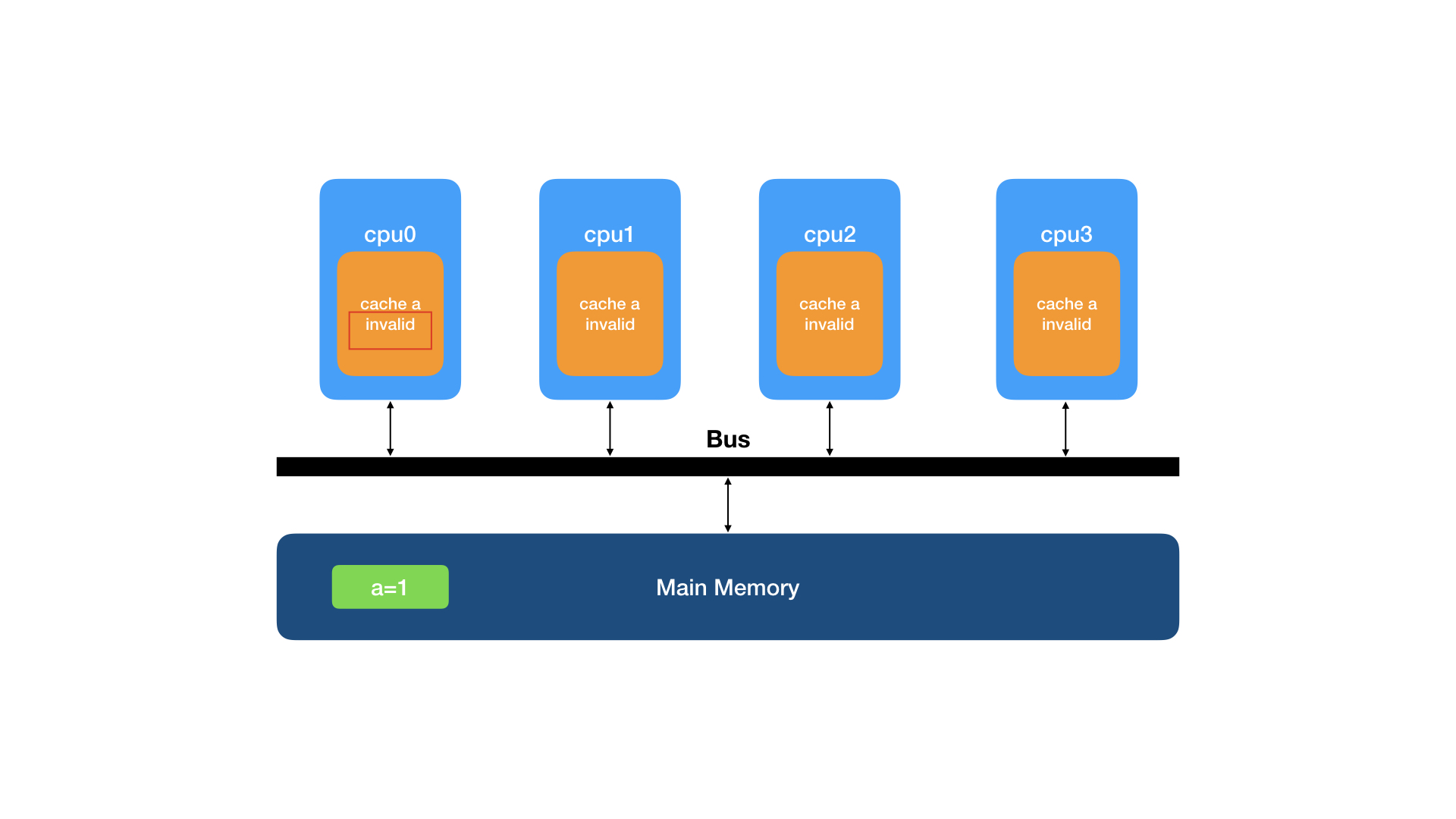
从主内存加载到高速缓存后,该行数据被该缓存独占,该缓存的状态就变成了E(exclusive)。
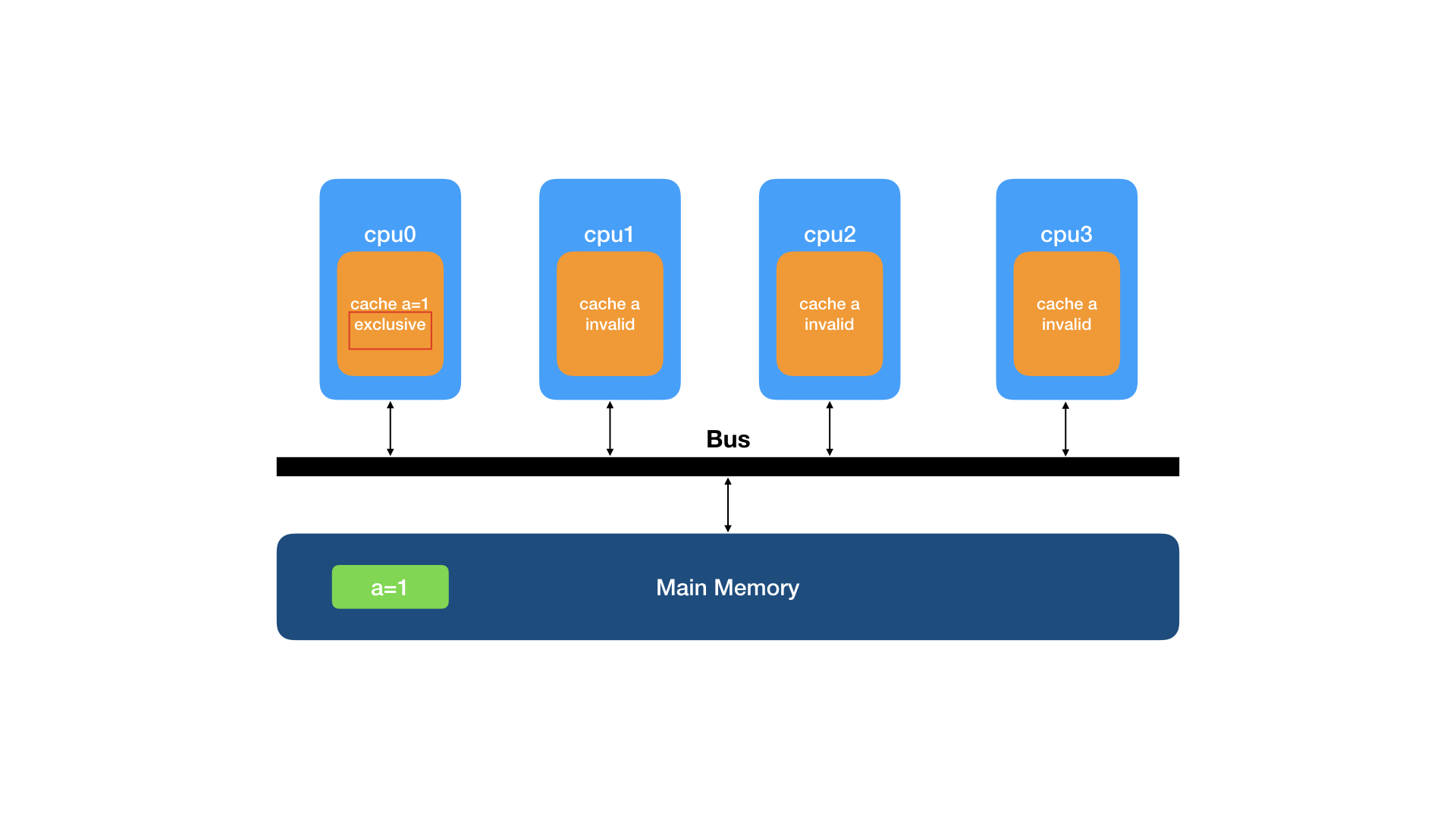
cpu1也要读同这行数据,cpu1该缓存行初始状态也为I(invalid)。
cpu1向总线发送BusRd请求,BusRd请求在总线上被广播。
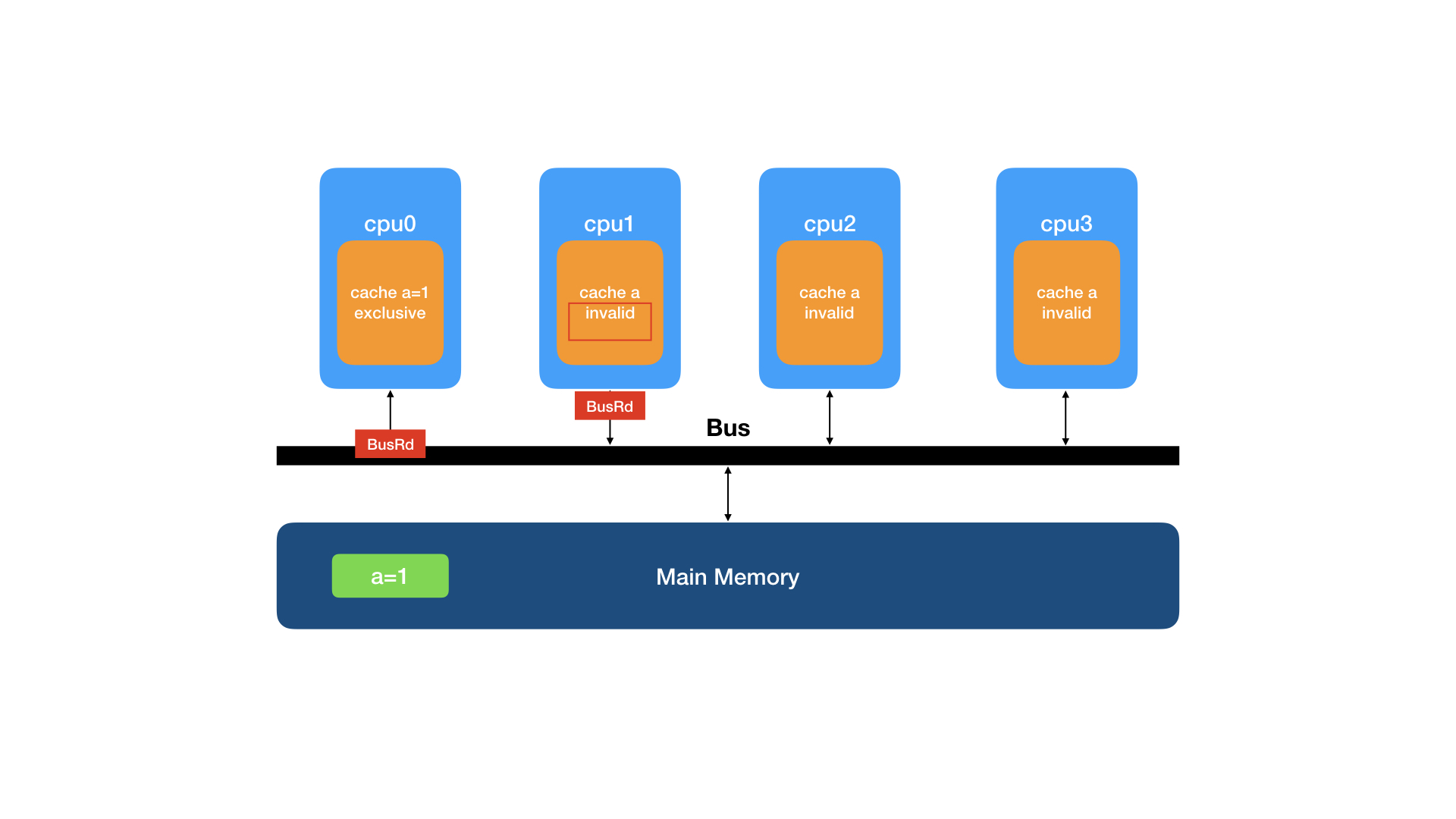
cpu0监听到BusRd请求后,发现自己拥有该缓存行的数据,就将缓存行的状态变更为S(shared),然后将数据与FlushOpt事件发送给总线以回应cpu1的请求。
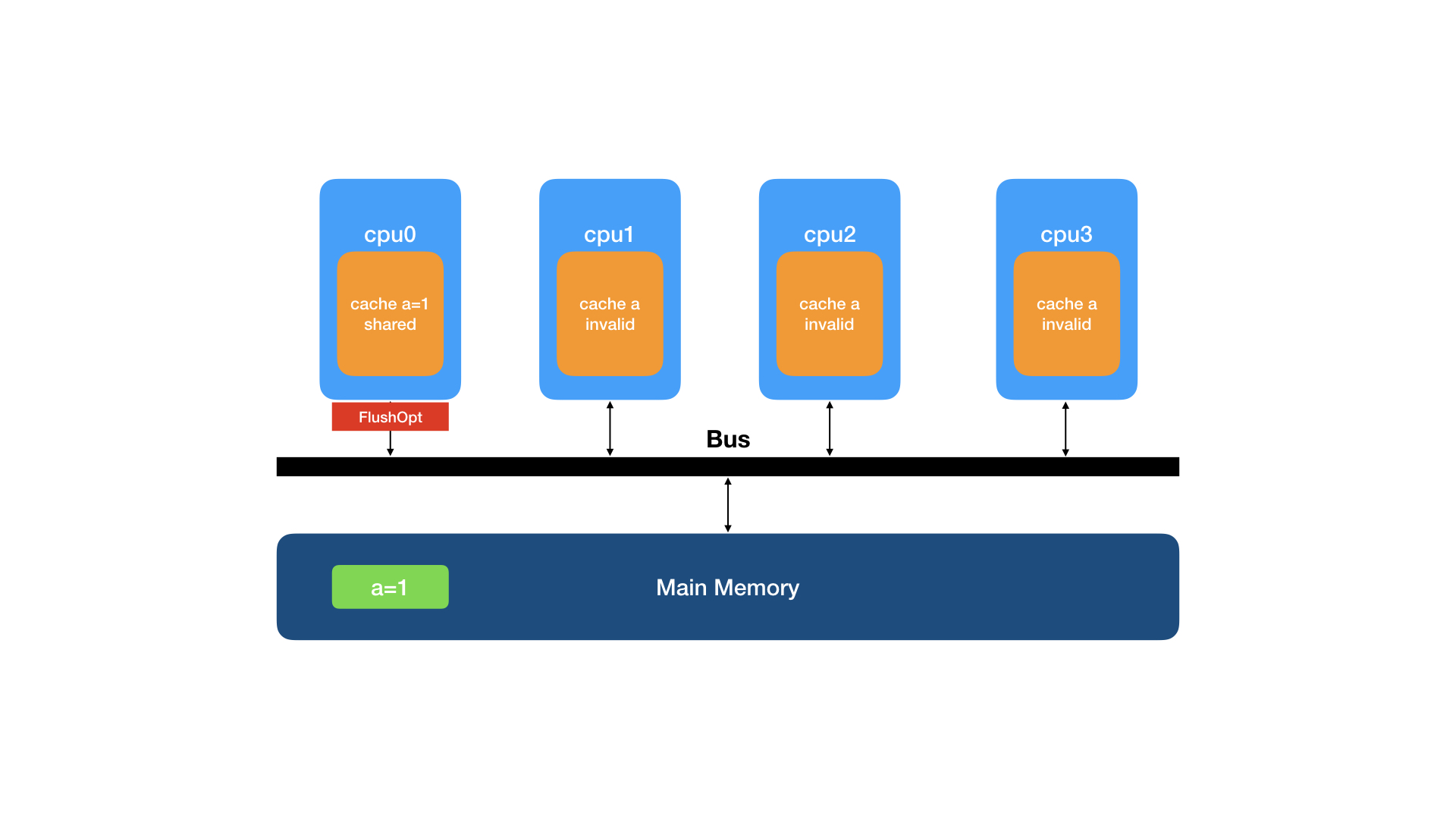
cpu1收到了cpu0回应的缓存行数据,将数据复制到自己的缓存,并将该缓存行的状态置为S(shared)。
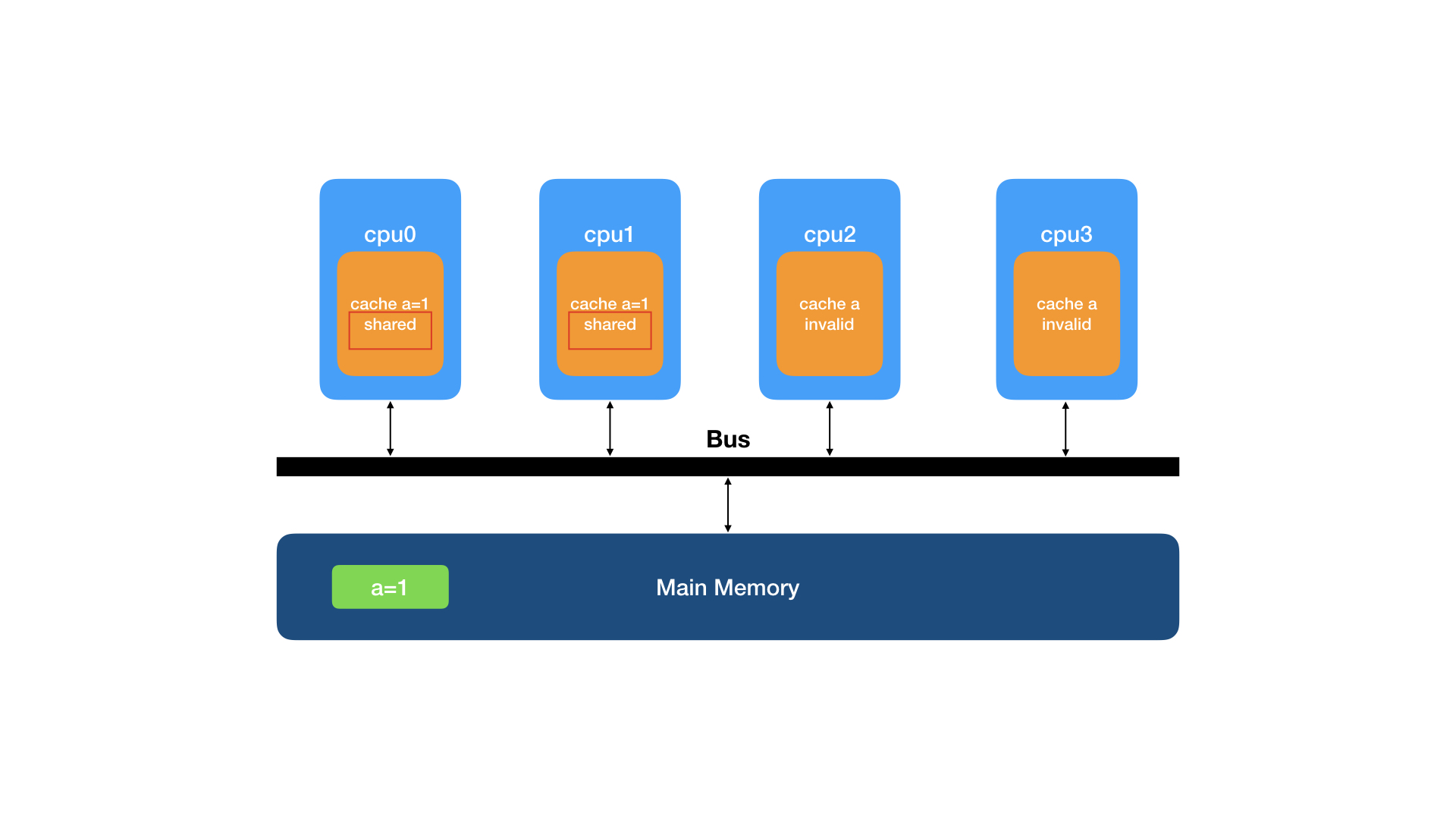
cpu1要将数据修改为a=2,向缓存发起PrWr请求。
因为cpu1的缓存内有该缓存行,不需要从其它处理器的缓存读取,但要通知其它处理器"失效"该行缓存,所以向总线发送BusUpgr事件。
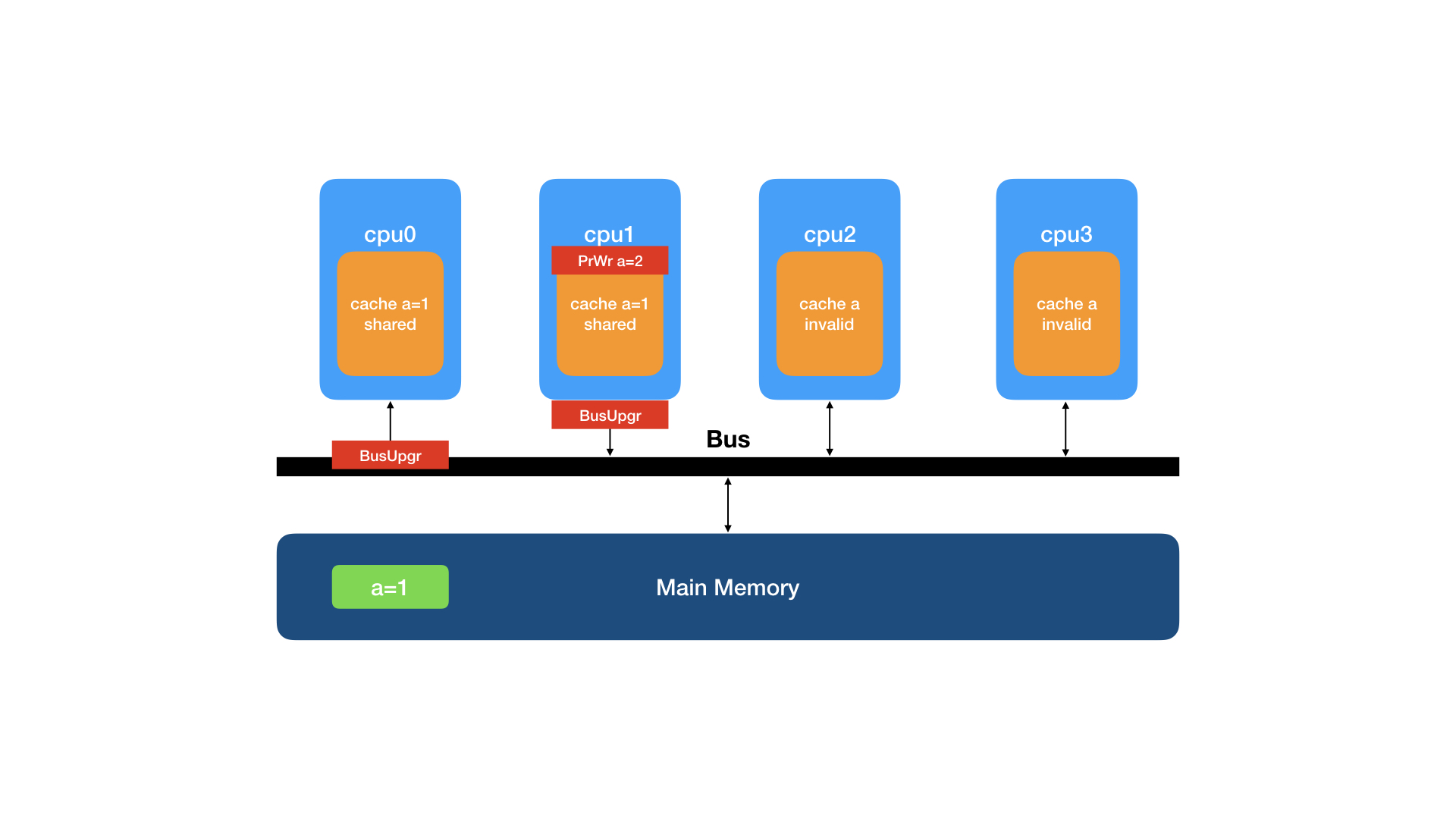
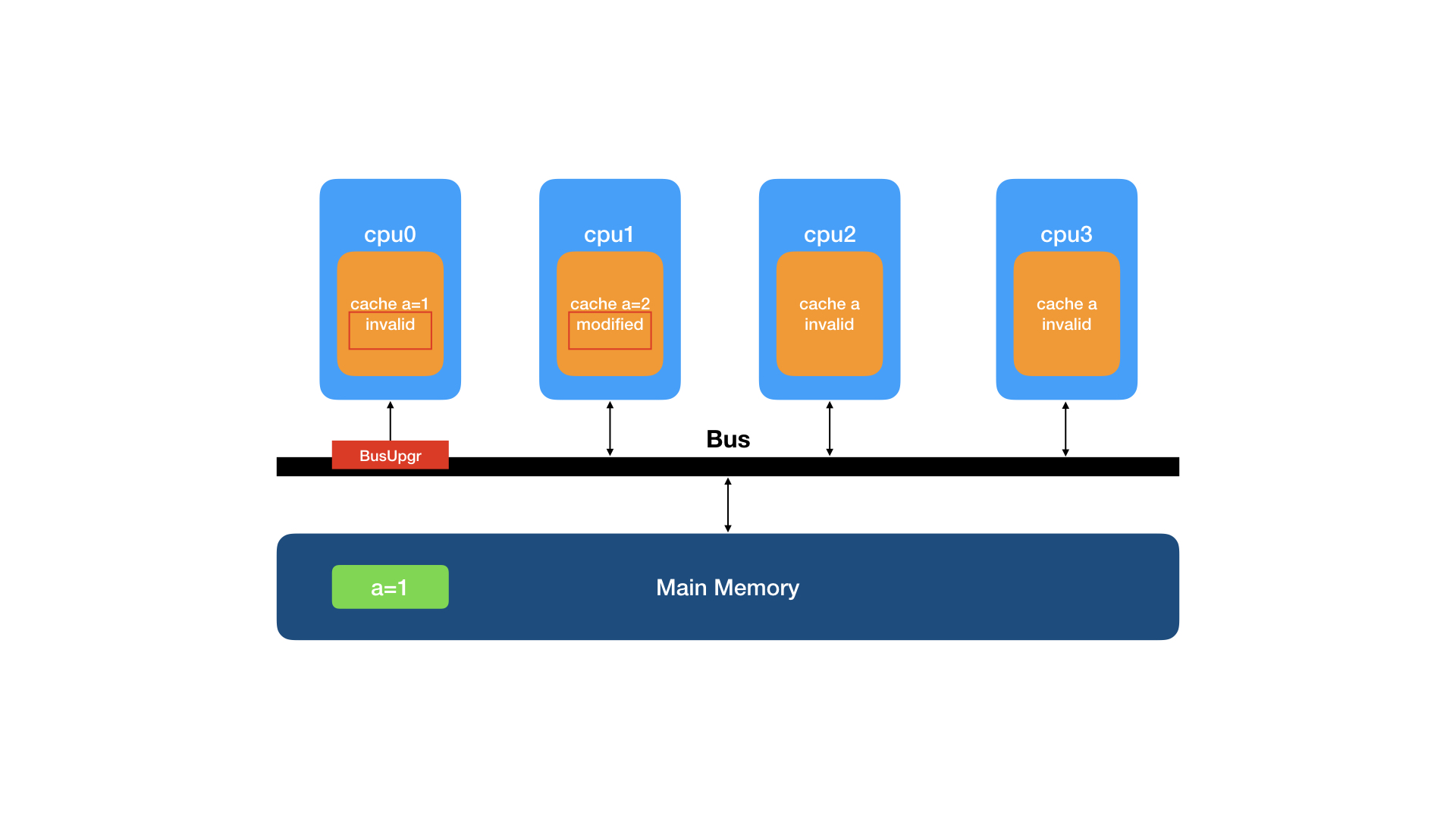
cpu0监听到BusUpgr事件,知道其它处理器要修改该行数据,就将本地缓存行状态设置为I(invalid)并回复invalid ack, cpu1的缓存行状态变更为M(modified)
4.完整的状态转换表
| 状态 | 操作 | 处理 |
|---|---|---|
| I(invalid) | PrRd | 发布BusRd事件 若其它处理器有该缓存行,接受其它处理器的缓存数据,状态置为S(shared) 否则从主内存读取,状态变更为E(exclusive) |
| I(invalid) | PrWr | 发布BusRdX事件 若其它处理器有该缓存行,接受其它处理器的数据 否则从主内存读取 状态变更为M(modified) |
| E(exclusive) | PrRd | 不发布Bus事件,不改变状态 |
| E(exclusive) | PrWr | 不发布Bus事件,状态变更为M(modified) |
| M(modified) | PrRd | 不发布Bus事件,不改变状态 |
| M(modified) | PrWr | 不发布Bus事件,不改变状态 |
| S(shared) | PrRd | 不发布Bus事件,不改变状态 |
| S(shared) | PrWr | 发布BusUpgr事件 其它拥有该缓存行的处理器将状态变更为I(invalid) 本处理器缓存行状态变更为M(modified) |
三、优化的MESI
1.Store Buffer
原始的MESI协议,在处理器写缓存时,为了保障一致性,要发布BusRx或BusUpgr事件通知其它处理器失效它们的缓存。
其它处理器处理了invalid请求后会答复invalid ack消息,写缓存的处理器要等待其它持有该缓存行的处理器全部回复后才能进行下一步的写入动作,这个等待的过程就浪费了cpu时间。
为了避免等待,引入了store buffer,它的作用就是写操作无需等待其它处理器的回复,先将要写的值存入store buffer,然后继续执行后面的指令。
后面的指令在读取数据值时会先检索本处理器的store buffer以获取最新的值。
但是其它处理器无法这么做,本处理器的store buffer对其它处理器是不可见的,这里引入了一个可见性的问题。
其它处理器的invalid ack都答复完毕后,再将store buffer中的数据刷入本处理器的缓存。
2.Invalidate Queue
处理器可以将invalid请求放到Queue中存储并立即答复,invalid请求会在后面某个时间被处理。
该数据对于该处理器并没有真正失效,后续读取是可能读到"旧"数据的。
3.内存屏障的需求
store buffer和invalidate queue的引入带来了可见性问题,在适当的地方插入内存屏障可以解决可见性问题。
写内存屏障(store barrier):处理器遇到了写内存屏障,要将store buffer中的数据都刷到缓存后,再继续执行后面的指令。
读内存屏障(store barrier):处理器遇到了读内存屏障,要将invalidate queue中的失效请求都处理完成后,再继续执行后面的指令。
四、总结、思考
本文提到的内容中都在解决"延迟大"的问题。在遇到类似的速度不匹配、延迟大的问题时,能条件反射般的想到"加缓存"去解决,一般都行之有效。
- 为了解决cpu与主内存之间的访问延迟大问题, 引入了cpu高速缓存(cache)。
- 为了解决cpu写本地缓存时要花费较长时间等待其它处理器答复的问题, 引入了store buffer。
- 为了cpu快速响应invalid request,引入了 invalidate queue。
“加缓存”的代价就是容易引入一致性、可见性的问题。
这就要求开发人员在并发场景下能够意识到可能会出现的一致性问题,并合理利用手段(例如内存屏障)去保障程序的运行符合预期。