上篇文章初步接触了GenericAPIView,这次来更加深入的学习它,了解里面的一些使用和方法
- get_object:源码中:处理查询集,并含有所需要得pk值,lookup_field
- get_queryset:源码中:先判断queryset是否为空,不为空得话就会替代queryset,所以事先要先声明,
- 后面可以轻松重写的queryset,实现不同接口使用不同查询集
- get_serializer:源码中:先判断serializer_class是否为空,不为空就返回serializer_class
return serializer_class(*args, **kwargs);
- 后面我们可以根据不同接口,重写get_serializer_class这个方法,实现不同接口返回不一样的字段
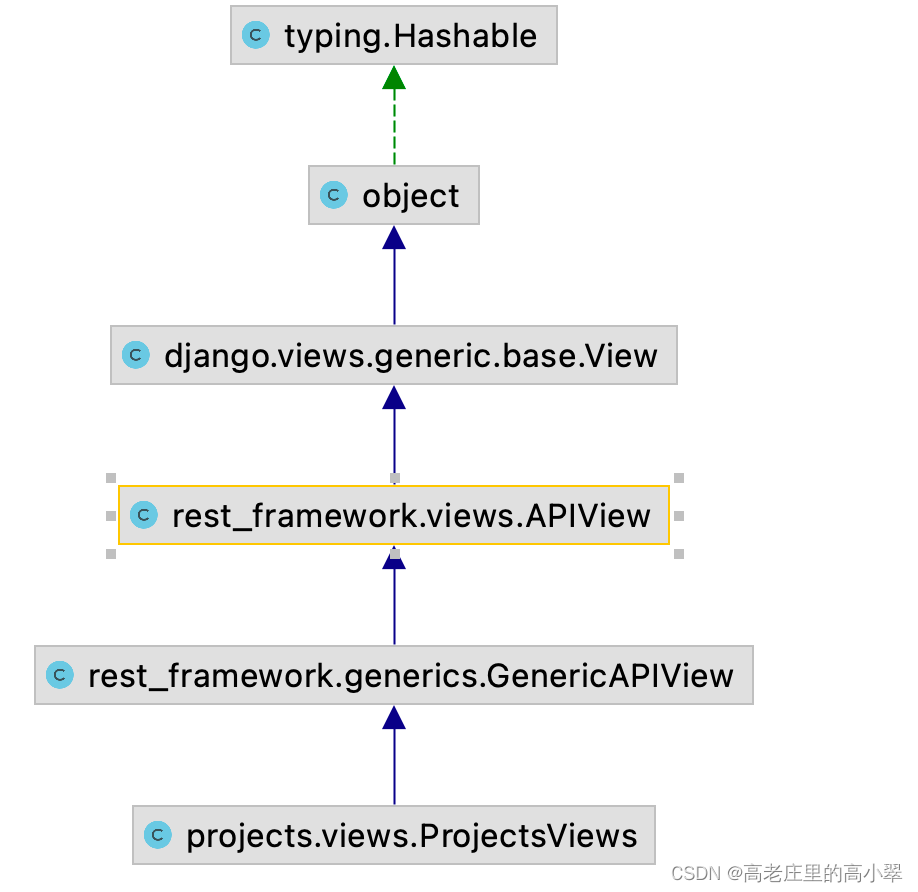
- 继承关系:generic.genericAPIView继承View.APIView(如图)
补充说明
1、queryset
一般使用类属性的queryset只会查一次,因为queryset是惰性查询;
1、如果还是使用queryset的话,在调用一次queryset后,后面再调用时候就不会改变,
2、这里的queryset不太容易重写,因为每个接口使用的数据源是不一样的,不一定都使用某一个模型类的查询集,不会使用一模一样的数据
2、serializer_class
一般不会使用serializer_class来获取序列化器类
1、因为每个接口需要返回的字段不一定都是相同的,无法实现定制化
3、(路由表中的主键名称pk):

1、如果定义路由表时,指定的主键名称为pk,那么无需指定lookup_field;
2、如果不想请求数据里的主键名称为pk,比如想叫做id之类的,可以在对应的视图类里重写 lookup_field属性
lookup_field = 'Id'

同时应用里的路由表里的路径参数也要保持一致,修改urlpatterns配置:
path('projects/<int:Id>/',views.ProjectsDetailViews.as_view())一、过滤
方式一:手写过滤逻辑代码实现功能
# 查询全部数据
def get(self, request):
qs = self.get_queryset()
param=request.query_params.get('name')
qs=qs.filter(name__icontains=param)
serializer_obj = self.get_serializer(instance=qs, many=True)
return Response(serializer_obj.data, status=status.HTTP_200_OK)param=request.query_params.get('name')为获取查询字符串参数的值,例如下面请求里的name=1

方式二:使用的是rest_framework中的filters.py中SearchFilter查询类
1、全局使用过滤引擎
1.1 可以在全局配置文件setting.py中,指定默认的过滤引擎,引用rest_framework的过滤引擎(所有获取列表数据的接口都会支持过滤功能)

'DEFAULT_FILTER_BACKENDS': ['rest_framework.filters.SearchFilter'],1.2 在对应的视图类里 定义需要过滤的字段
search_fields=['name','id']1、'^': 'istartswith',name以什么开头进行过滤(search_fields=['^name','id']) 2、'=': 'iexact',以name等于什么,进行精确匹配过滤(search_fields=['=name','id']) 3、'@': 'search',不常用 4、'$': 'iregex',name字段支持正则匹配(search_fields=['$name','id']) 5、如果不写前缀,默认使用icontains进行匹配过滤

默认情况下,过滤字段是search,如果需要自定义过滤字段,可以在setting.py配置文件中重写SEARCH_PARAM属性
'SEARCH_PARAM': 'Search', 
2、局部使用过滤引擎
如果不想全局引用过滤引擎,只想给指定的列表接口添加过滤引擎,那就不需要再setting.py中引用过滤引擎,可以在特定的类视图中指定filter_backends过滤引擎,也可以指定排序引擎

1、可以使用GenericAPIView内置的filter_queryset方法 ,对查询集进行过滤,省略自己的的代码,达到简化代码的目的
2、filter_queryset的第一个参数是查询集对象
3、注意:视图类里声明的引擎列表里过滤引擎和排序引擎不是字符串参数
二、排序
方式一:自定义代码逻辑进行排序
# 查询全部数据
def get(self, request):
qs = self.get_queryset()
#param=request.query_params.get('name')
qs=qs.filter().order_by('-name')
serializer_obj = self.get_serializer(instance=qs, many=True)
return Response(serializer_obj.data, status=status.HTTP_200_OK)
方式二:使用的是rest_framework中的filters.py中OrderingFilter查询类
1、全局配置排序引擎
1.1 可以在全局配置文件setting.py中,指定默认的排序引擎,引用rest_framework的过滤引擎(所有获取列表数据的接口都会支持排序功能)
'DEFAULT_FILTER_BACKENDS': ['rest_framework.filters.SearchFilter'],
'ORDERING_PARAM': 'ordering',1.2 在视图类里定义需要排序的字段
# 定义需要排序的字段
ordering_fields=['id','name']2、局部使用排序引擎
class ProjectsViews(GenericAPIView):
# 指定当前类视图需要使用的查询集
queryset = ProjectsModel.objects.all()
# 指定当前类视图需要使用的序列化器类
serializer_class = ProjectModelSerializer
# lookup_field = 'Id'
# 声明需要使用的引擎类
filter_backends = [filters.SearchFilter,filters.OrderingFilter]
# 定义需要过滤的字段
search_fields=['name','id']
# 定义需要排序的字段
ordering_fields=['id','name']
- 如果不想全局引用排序引擎,只想给指定的列表接口添加排序引擎,那就不需要再setting.py中引用排序引擎,可以在特定的类视图中指定filter_backends排序引擎
- 视图类中添加排序引擎 filter_backends =[filters.OrderingFilter]
- 定义需要排序的字段 ordering_fields=['id','name']
api的可浏览界面中会添加排序功能
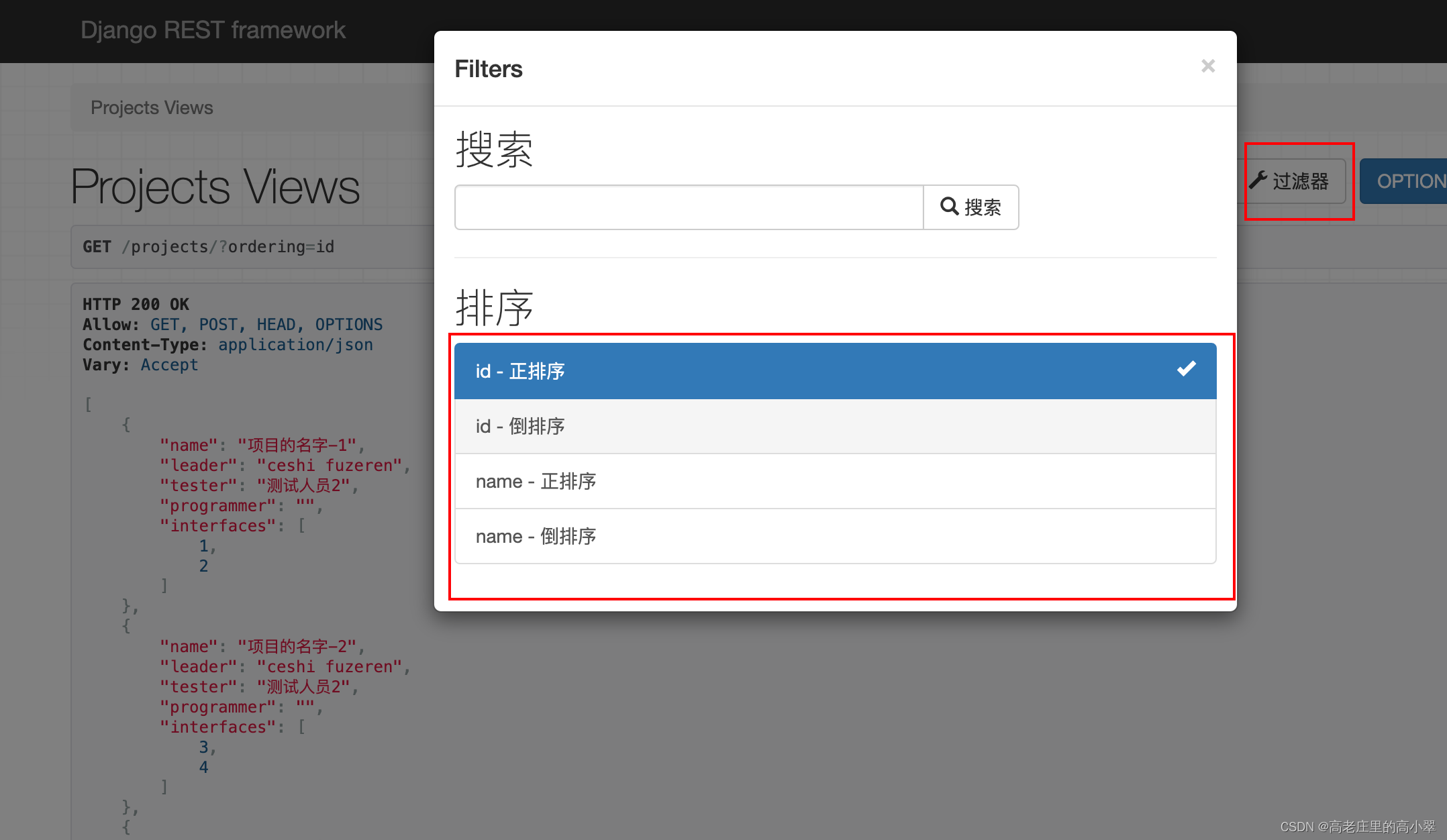

默认情况下,排序字段是ordering,如果需要自定义过滤字段,可以在setting.py配置文件中重写ORDERING_PARAM属性
'ORDERING_PARAM': 'ordering',三、分页
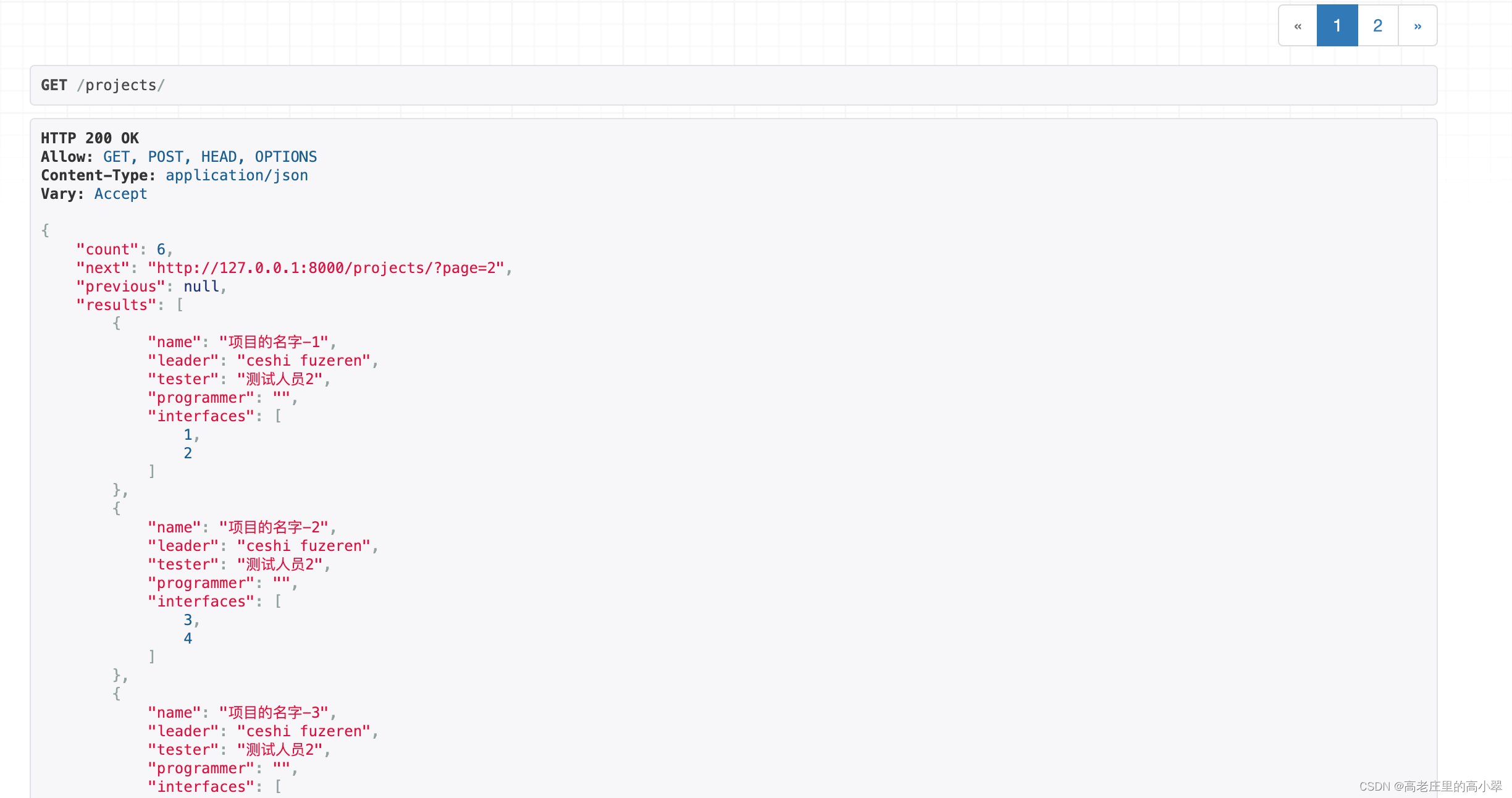
1、使用rest_framework中的分页引擎
全局配置文件中指定分页引擎DEFAULT_PAGINATION_CLASS,并且指定每页数据数量参数PAGE_SIZE;
'DEFAULT_PAGINATION_CLASS':'rest_framework.pagination.PageNumberPagination',
'PAGE_SIZE': 3, # 查询全部数据
def get(self, request):
qs = self.get_queryset()
qs=self.filter_queryset(qs)
#需要调用paginate_queryset方法,需要传递序列化之后的字典或者嵌套字典的列表
page_queryset=self.paginate_queryset(qs)
#如果定义了分页引擎,则使用get_paginated_response进行返回,否则默认返回不分页的全部数据
if page_queryset is not None:
serializer_obj = self.get_serializer(instance=page_queryset, many=True)
return self.get_paginated_response(serializer_obj.data)
serializer_obj = self.get_serializer(instance=page_queryset, many=True)
return Response(serializer_obj.data, status=status.HTTP_200_OK)
- 调用paginate_queryset方法,需要传递查询集对象
- 需要调用get_paginated_response方法,需要传递序列化之后的字典或者嵌套字典的列表
- 如果定义了分页引擎,则使用get_paginated_response进行返回,否则默认返回不分页的全部数
- get_paginated_response返回Response对象,在返回的数据中,添加了特定的数据
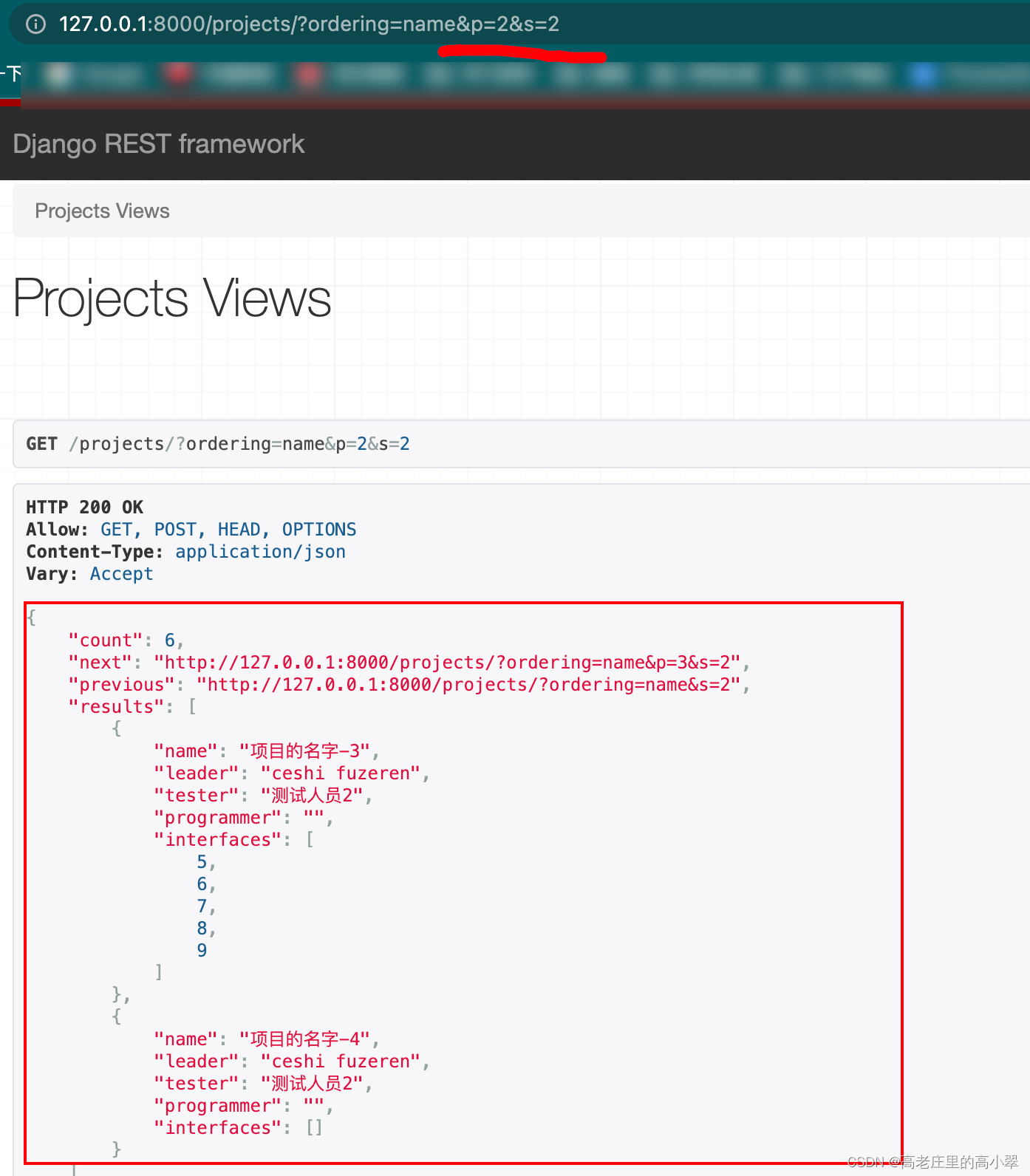
2、自定义分页引擎类
2.1 自定义一个分页引擎类
from rest_framework.pagination import PageNumberPagination as _PageNumberPagination
class PageNumberPagination(_PageNumberPagination):
# 分页关键字,来查看对应页的数据
page_query_param='p'
# 每页指定展示多少条数据
page_size_query_param='s'
# 设置每页数据量虽大值
max_page_size=20
# 无效页面提示信息
invalid_page_message='这是个无效页面,请检查后重新输入....'2.2 然后再全局配置文件setting.py里替换掉自己定义的分页类
'DEFAULT_PAGINATION_CLASS':'utils.pagination.PageNumberPagination',
'PAGE_SIZE': 3,接下来url里拼接上p=2&s=1,表示展示第二页,每页展示1条数据
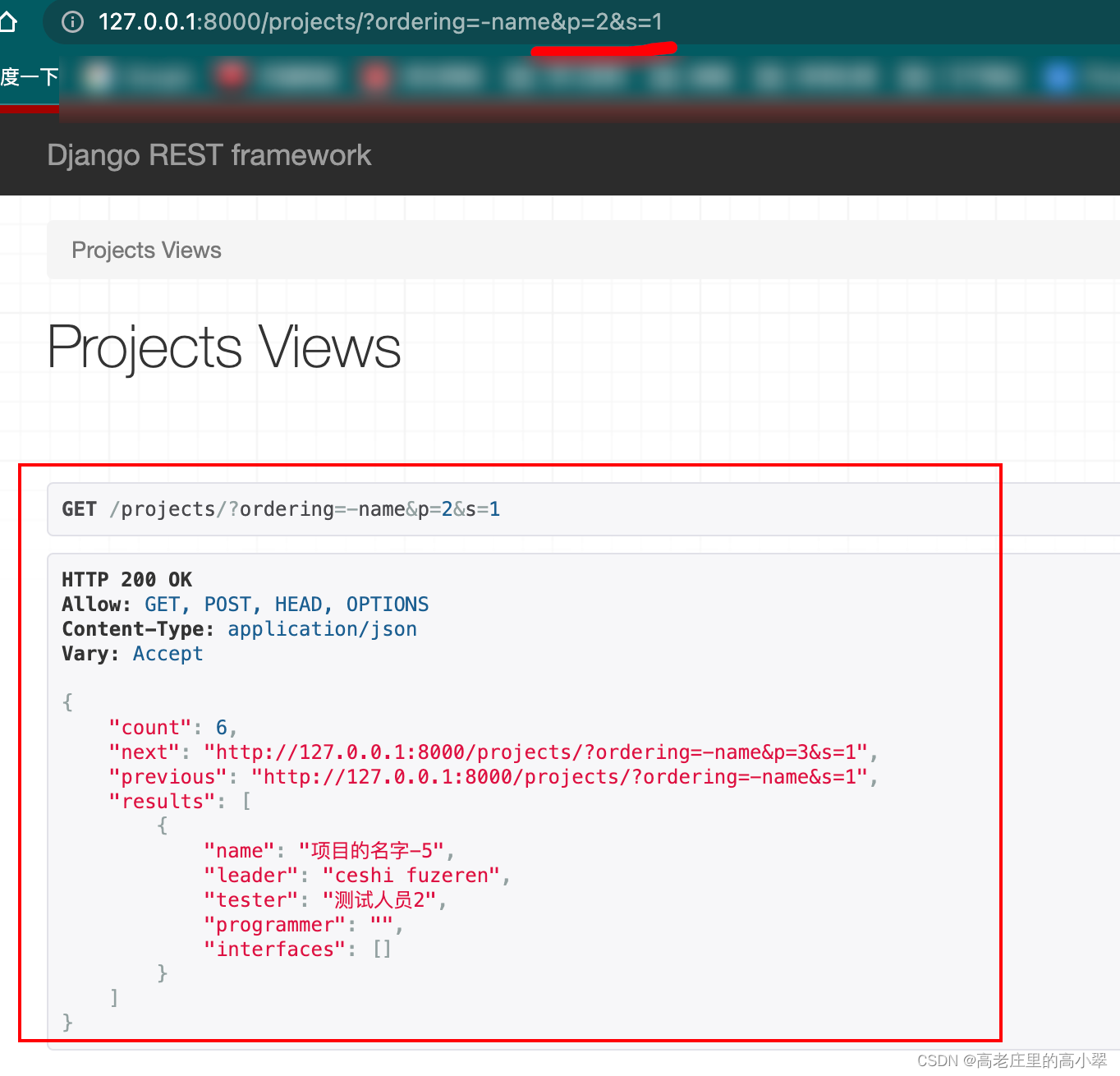
当输入的页数不存在时,就会抛出自定义的无效分页的描述

3、给指定的类视图定制一个分页引擎
就需要在指定的类视图中引用我们自定义的分页引擎
3.1 导入自定义分页引擎类
from utils.pagination import PageNumberPagination3.2 声明需要使用的分页引擎
pagination_class = PageNumberPagination如果我们还是按照全局分页引擎来分页,是无效的
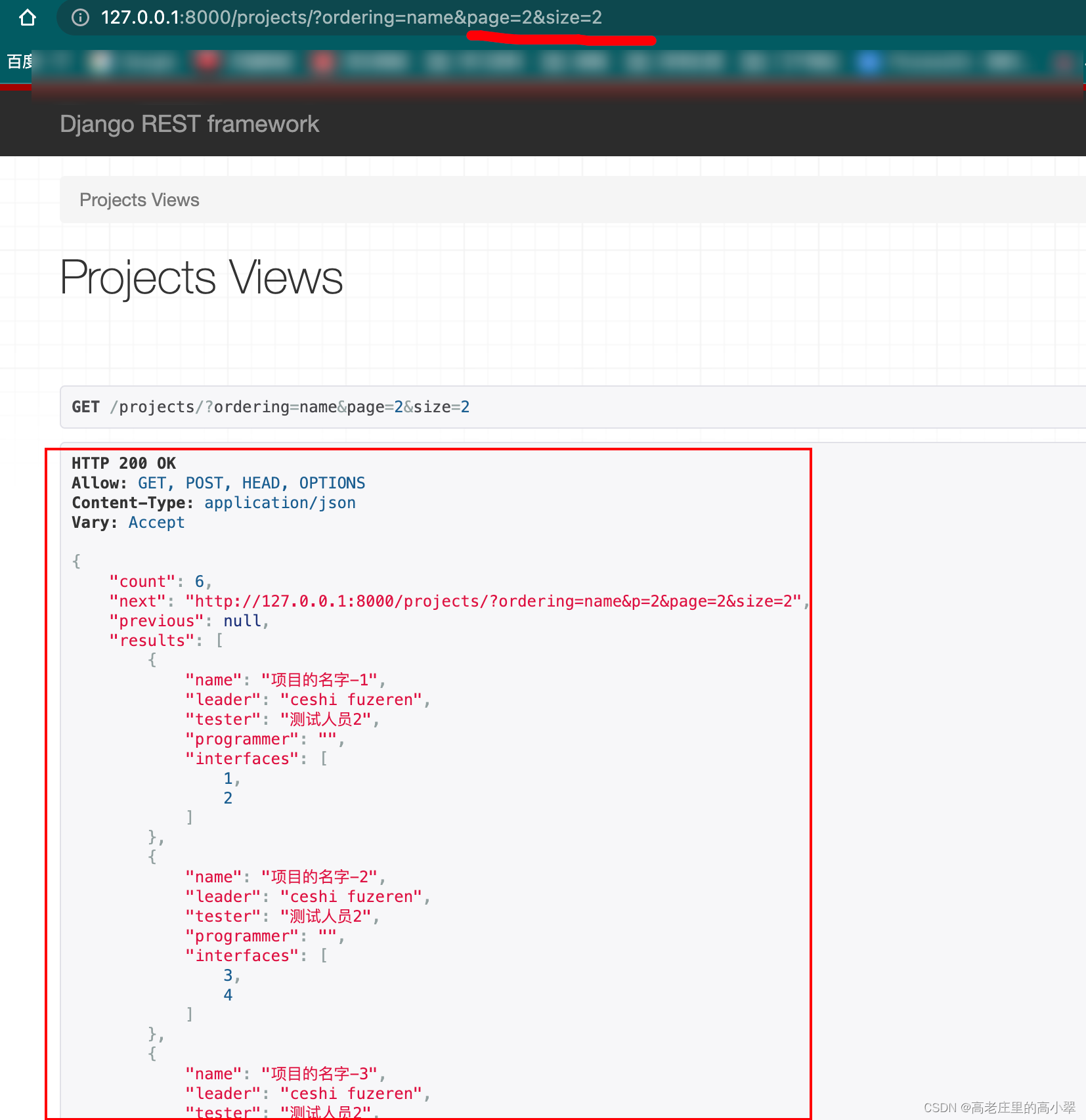
如果我们按照自定义的分页引擎来分页,是有效的