非平衡数据产生现象及原因
非平衡数据是人工智能安全中经常遇到的问题,一方面,在采集和准备数据时,由于安全事件发生的可能性不同等因素的影响,使得训练数据存在非平衡,另一方面,机器学习模型的攻击者也可能利用非平衡数据学习所产生的分类效果在多数类上的偏斜,而成为攻击者对机器学习模型攻击的一种手段,不管哪种情况,对机器学习系统的数据进行非平衡数据处理都是非常有必要的
在网络信息安全问题中,诸如恶意软件检测、SQL注入、不良信息检测等许多问题都可以归结为机器学习分类问题。这类机器学习应用问题中,普遍存在非平衡数据的现象
产生的原因:攻击者的理性特征使得攻击样本不会大规模出现。 警惕性高的攻击者,会经常变换攻击方式避免被防御方检测出来。少数类样本的信息量比多数类要少得很多。

非平衡数据对各种分类器的影响 KNN Bayes 决策树 Logistic回归 当用于非平衡数据分类时,为了最大化整个分类系统的分类精度,必然会使得分类模型偏向于多数类,从而造成少数类的分类准确性低
非平衡数据处理方法

欠抽样方法通过减少多数类样本来提高少数类的分类性能
常见的欠采样方法有随机欠采样、启发式欠采样等。随机欠采样通过随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类的一些重要信息,不能够充分利用已有的信息
启发式欠采样基本出发点是保留重要样本、有代表性的样本,而这些样本的选择是基于若干启发式规则。经典的欠采样方法是邻域清理(NCL,Neighborhood cleaning rule)和Tome links法,其中NCL包含ENN,典型的有以下若干种
Edited Nearest Neighbor (ENN) 对于多数类的样本,如果其大部分k近邻样本都跟它自己本身的类别不一样,就将他删除。 也可以从少数类的角度来处理:对于少数类样本,如果其大部分k近邻样本都是少数类,则将其多数类近邻删除
把多数类样本转换为少数类 Condensed Nearest Neighbor(CNN) 对点进行KNN分类,如果分类错误,则将该点作为少数类样本。在实际运用中,选择比较小的K
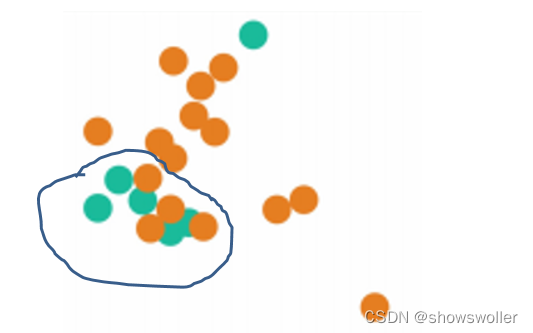
Near Miss(NM) NearMiss-1:对于每个多数类样本,计算其与最近的三个少数类样本的平均距离,选择最小距离对应的多数类样本。 NearMiss-
2:与NearMiss-1相反,计算与最远的三个少数类样本的平均距离,并选择最小距离对应的多数类样本。 NearMiss-
3:对每个少数类样本,选择与之最接近的若干个多数类样本
NearMiss-1针对数据分布的局部特征;
NearMiss-2针对数据分布的全局特征。
NearMiss-1倾向于在比较集中的少数类附近找到更多的多数类样本,而在离群的少数类附近找到更少的多数类样本
Tomek Links方法 如果有两个不同类别的样本,它们的最近邻都是对方,也就是A的最近邻是B,B的最近邻是A,那么A,B就是Tomek link。 数学语言:两个不同类别的样本点xi和xj,它们之间的距离表示为d(xi,xj),如果不存在第三个样本点xl使得d(xl,xi)<d(xi,xj)或者d(xl,xj)<d(xi,xj)成立,则称(xi,xj)为一个Tomek link
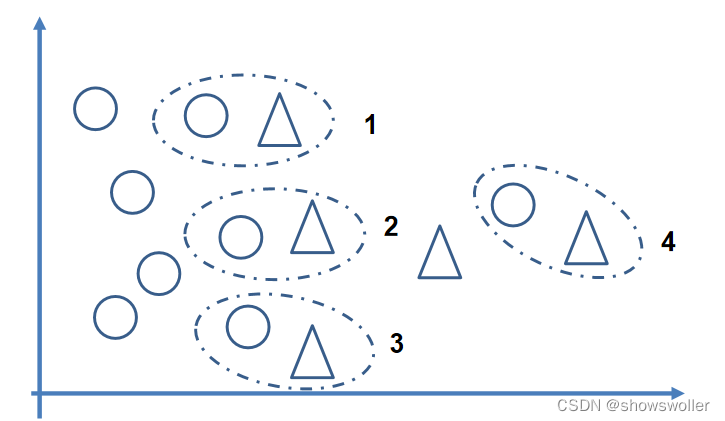
Tomek Link Removal 处理方法:把所有Tomek link都删除掉,即对于Tomek link的两个样本,如果有一个属于多数类样本,就将该多数类样本删除掉
过采样
Synthetic Minority Oversampling Technique(SMOTE)

该算法只是简单在两个近邻之间进行插值采样,而没有考虑到采样点附近的样本分布情况,从而可能产生趋向于其他类别的样本,以及样本重复等问题
该算法根据少数类近邻样本的类别分布情况,判断该样本以后被误分的可能性,从而有选择地进行线性插值采样生成新的少数类样本

在DANGER数据集中的点不仅从S集中求最近邻并生成新的少数类点,同时也在L数据集中求最近邻,并生成新的少数类点。这会使得少数类的点更加接近其真实值
