什么时候用HIVE
收集一段时间的数据来进行分析,而Hive就是分析历史数据绝佳的工具。在处理已经存在关联模式的数据时,Hive拥有极为出色的表现。Hive的优势在于其基于HDFS上的数据系统模式而设计完成。其能够在各可接受分区内容纳大量数据,但却不适合利用大量分区分别容纳少量数据。毕竟分区的存在意义在于加快特定数据查询速度,而不需要对整体数据集进行操作。分区数量的减少,意味着我们能够实现最低负载并最大程度提升集群资源利用率。
什么时候用Pig
Apache Pig的胃口可以用“毫不挑食”来形容,其能够消费各种数据类型,包括结构化、半结构化以及非结构化。与Hive不同,Pig不会使用任何相关metastore,但却能够利用Hive中的Hcatalog。事实上,Pig的设计初衷正是为了立足于大规模数据集执行复杂的可扩展操作,因为其能够随时随地进行自我优化。尽管Pig看起来采用多级脚本结构,但其各项内部操作都会在执行时得到优化,这就显著减少了数据的实际扫描次数。
为什么用Hive的人比较多,Pig的人少
Hive的初步设计思路在于提供与SQL类似的使用体验,开发人员只需要掌握Sql相关的知识就可以使用。
Pig提供一套高级语言平台,用于对结构化与非结构化数据集进行操作与分析。这种语言被称为Pig Latin, 拥有更多规程化方案。 但是同时需要额外的学习成本。
基本信息对比

细节对比


设计思路与原理
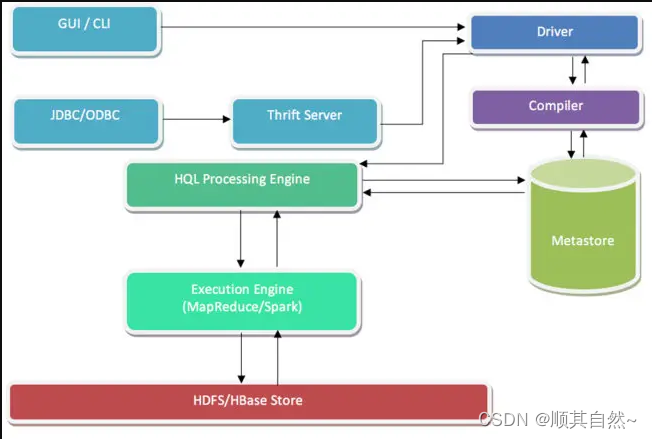
Hive:
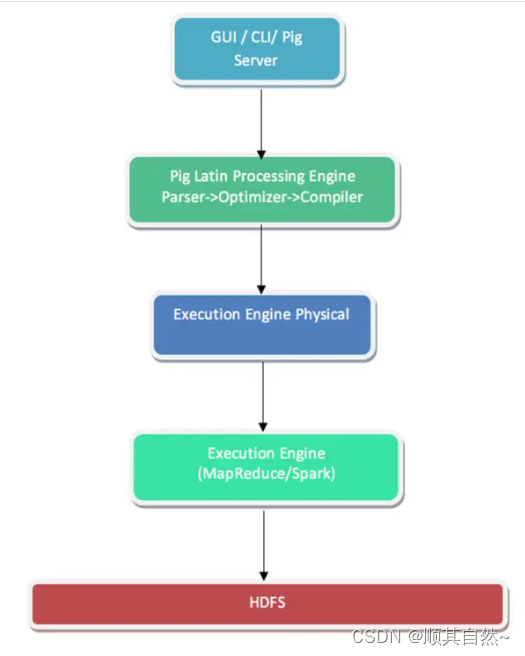
Pig:
总结: Hive在本质上属于一套数据仓储平台,用于同存储在HDFS或者HBase内的大规模结构化数据集进行交互。Hive查询语言在这一点上类似于SQL,二者都能够与Hadoop实现良好集成。而Pig则不同,其执行流程为纯声明性,因此适合供数据科学家用于实现数据呈现与分析。
Pig其属于一种脚本形式,用户所创建的脚本会在初始阶段由Pig Latin处理引擎进行语义有效性解析,而后被转换为包含整体执行初始逻辑的定向非循环图(简称DAG)。另外,这套处理引擎亦可接受DAG并在内部执行计划优化——具体优化方式包括PIG程序方法以及惰性计算。
转自:https://www.jianshu.com/p/30d4daa6e65b