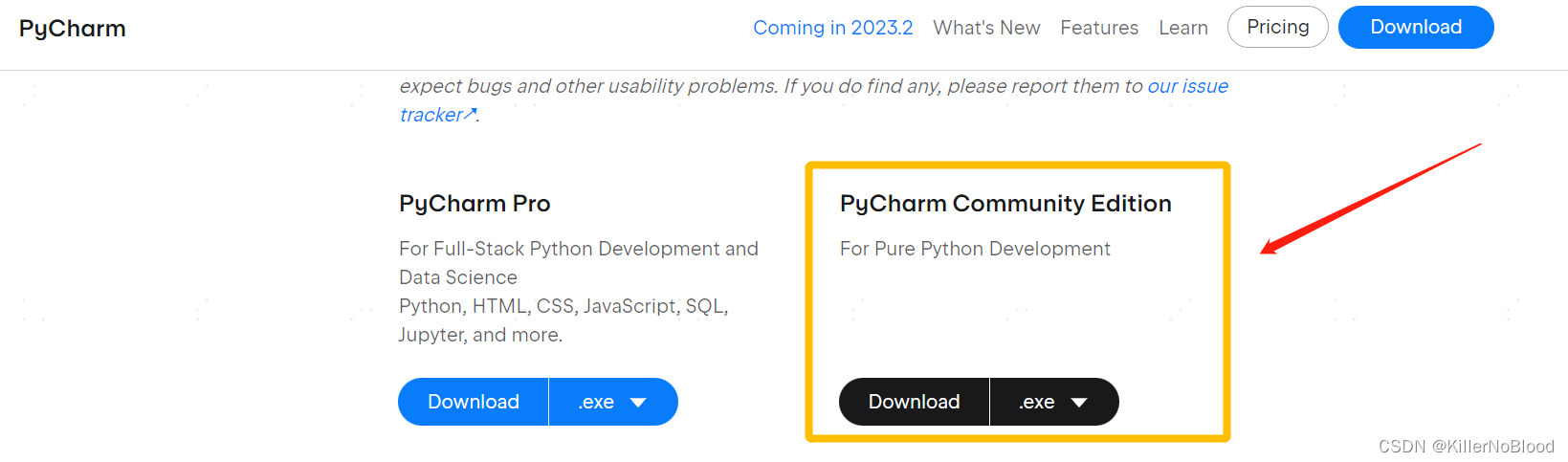
1、下载Python编译器
- PyCharm官网下载地址
- 对于个人编程,下载免费版的Community即可
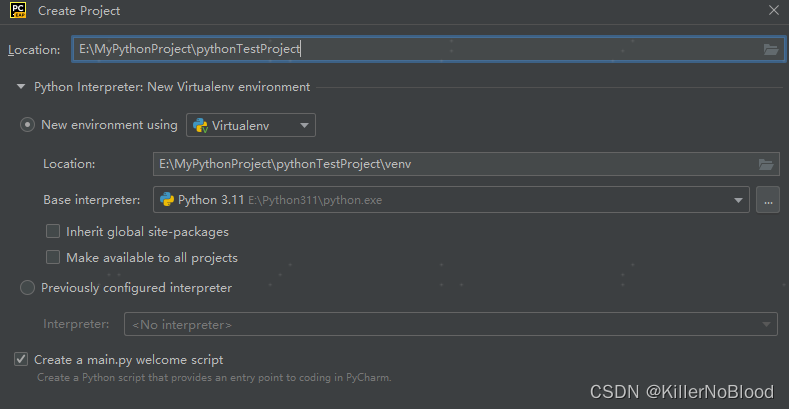
2、创建一个Python项目
- Python的最佳实现是为每个项目创建virtualenv。
- 为此,请展开Project Interpreter:New Virtualenv Environment节点,然后选择用于创建新虚拟环境的工具。
- 现在选择Virtualenv工具,并指定用于新虚拟环境的位置和基本解释器。
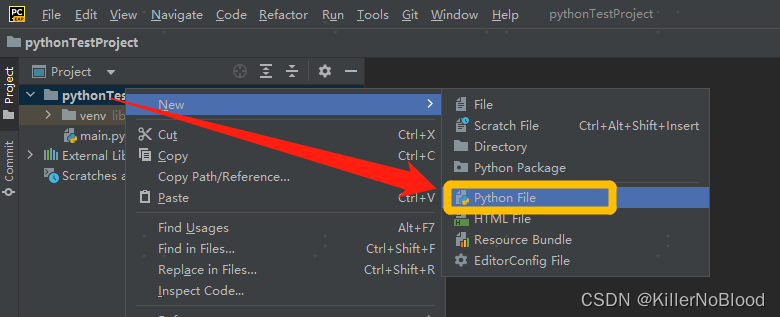
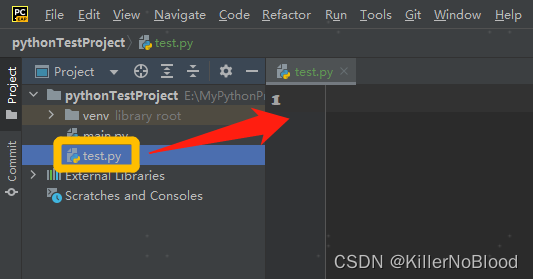
- 创建一个python file,就可以开启编程之旅了
添加/更换解释器
- 有时,我们要使用一些库的资源,但是程序无法运行,可能是python解释器版本太高,这时,我们需要降低解释器版本。具体操作如下:
- 选择需要的版本进行下载
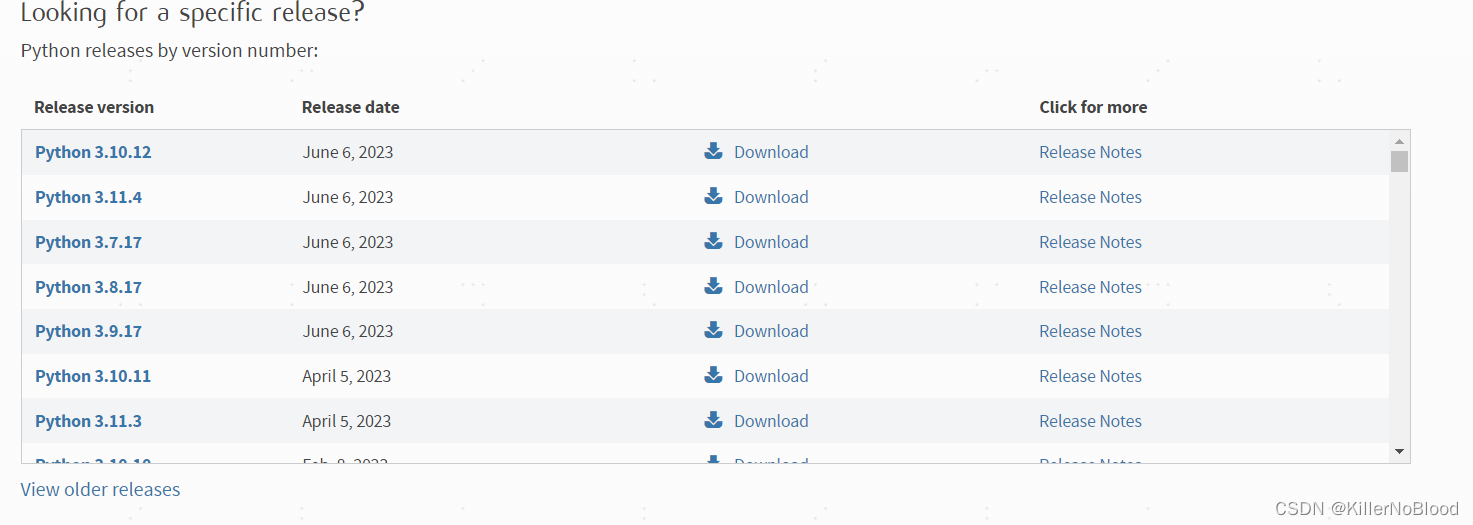
注:有一些版本时不持支下载的,需要再找其他版本下载
- 支持下载版本的页面
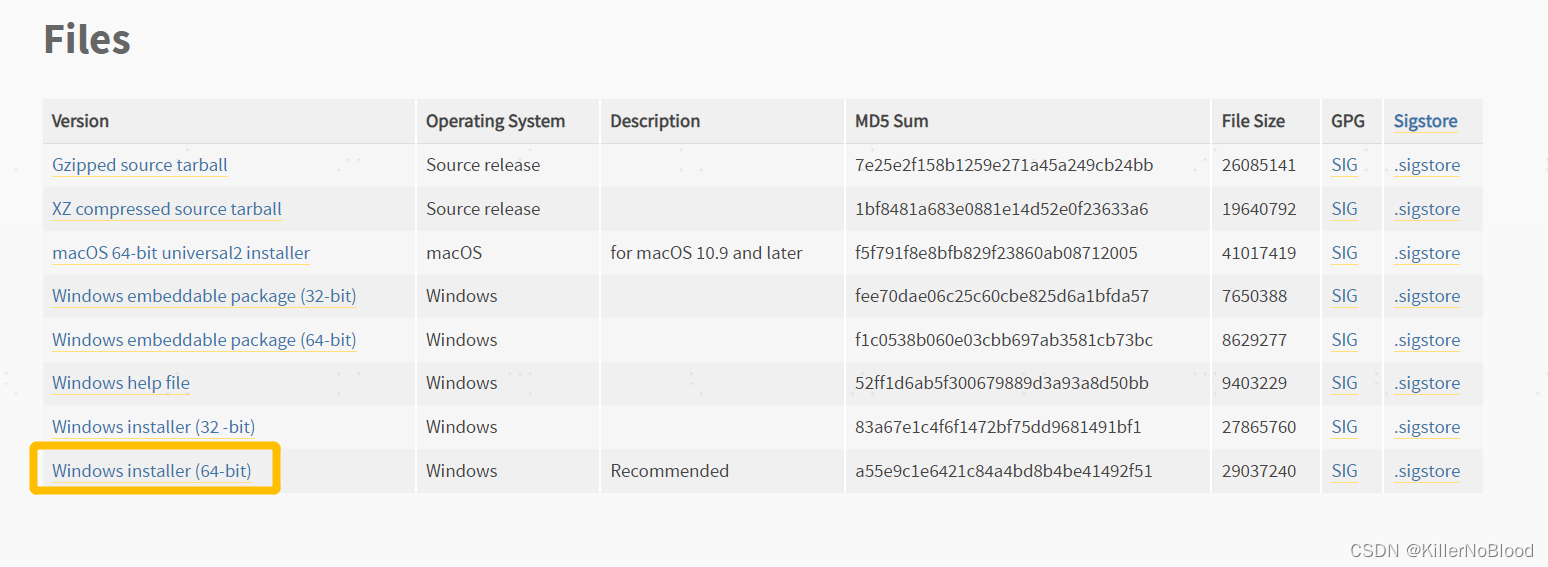
- 不支持下载版本的页面
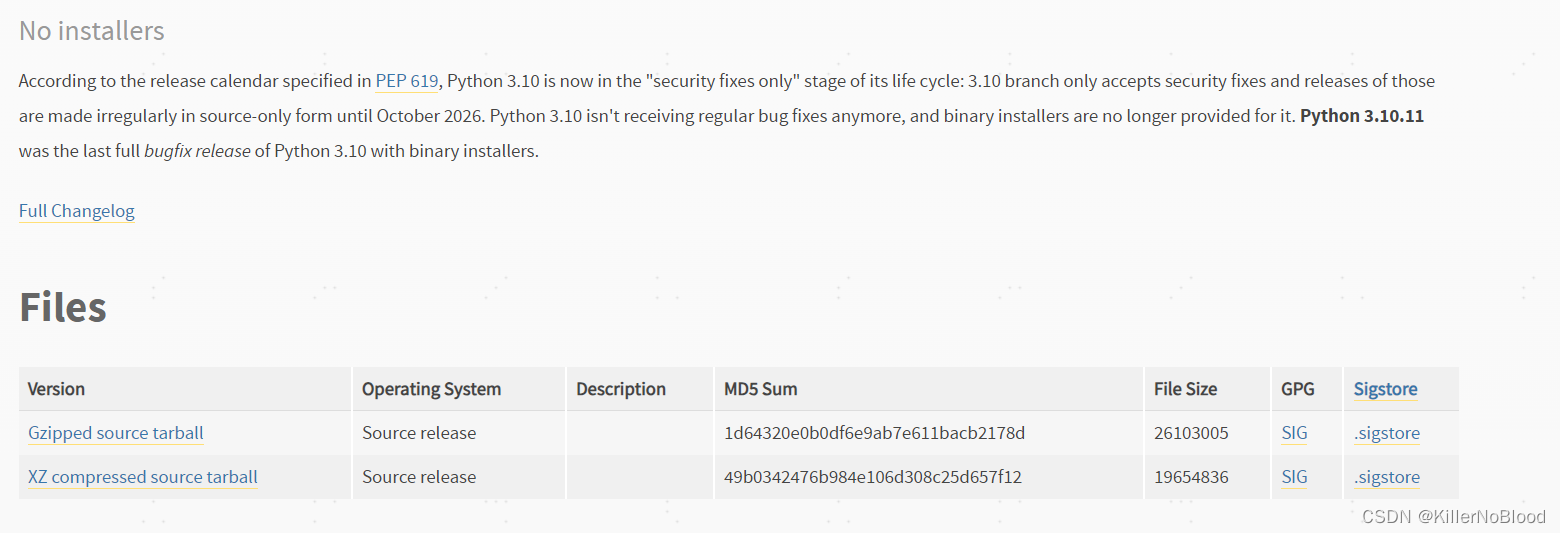
- 下载完成之后,双击运行安装

- 选择自定义安装,勾选add to PATH
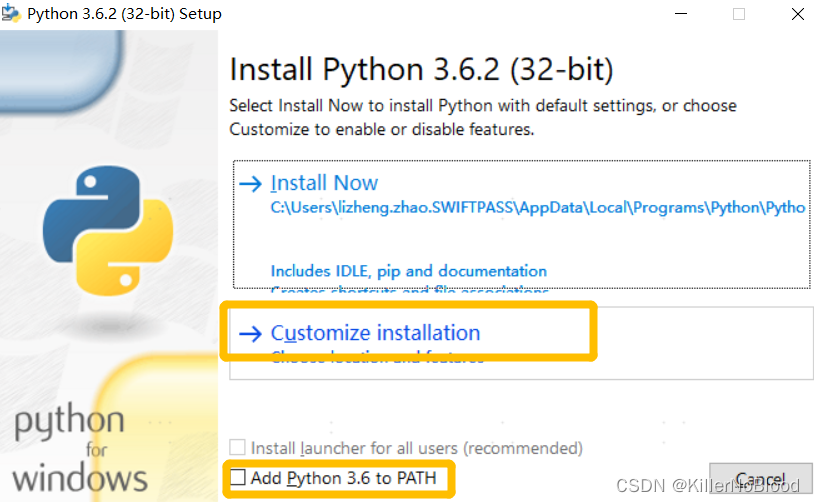
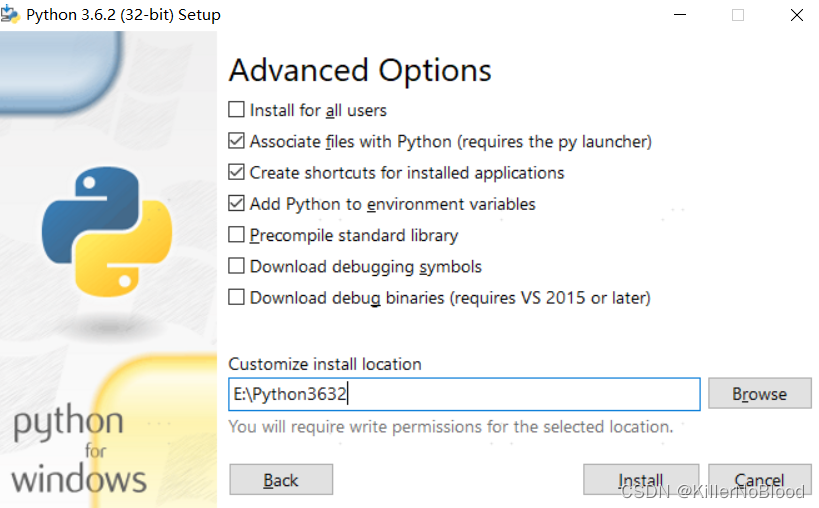
点击安装,等待安装完成即可
- 在编译器右下角进行解释器添加
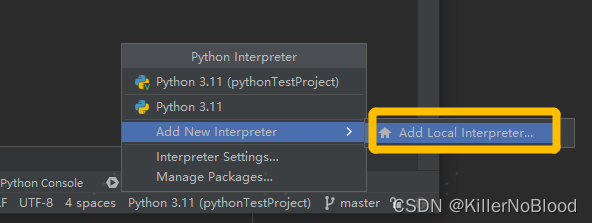
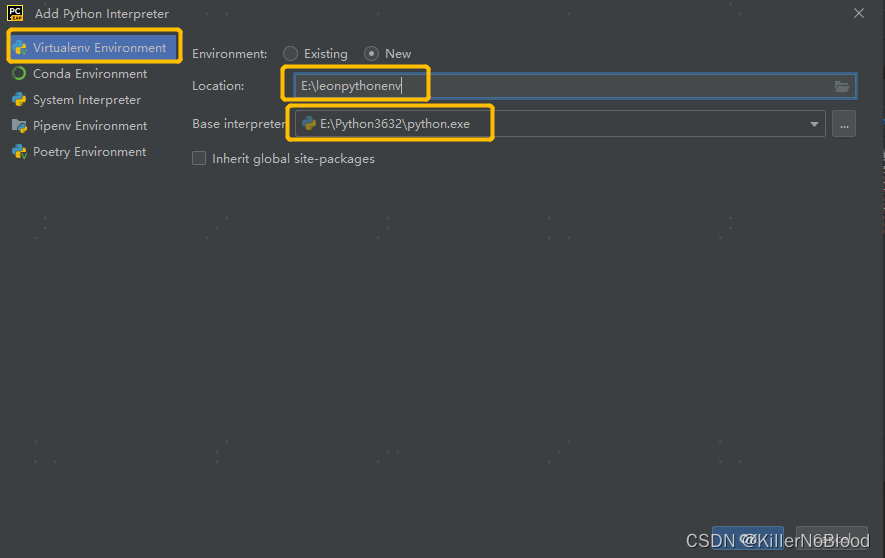
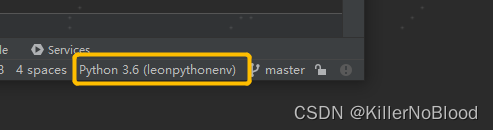
- 右下角替换为所选版本解释器,即添加完成
3、牛刀小试:python开发几个小工具
- 注:要在python 3.8环境下使用
| 工具 | 功能 |
|---|---|
| Jpg2Png.py | 将同目录下的jpg转换为png |
| Word2Pdf.py | 将同目录下的word文档转换为pdf |
| Compress.py | 将指定目录下的文件压缩为zip/7z |
| Decompress.py | 将当前目录下的zip/7z/rar解压 |
3.1、jpg转png
#####################################
#####################################
# @author leon
# @date 2023-06-26
# @description 将同目录下的jpg转换为png
#####################################
#####################################
import glob
import msvcrt
import os
from PIL import Image
# 搜索当前文件夹中的jpg
jpg_files = glob.glob("*.jpg")
jpg_cnt = len(jpg_files)
# 开始转换
if jpg_cnt > 0:
print(f"当前文件夹有{
jpg_cnt}张jpg")
for jpg_file in jpg_files:
jpg_name = os.path.basename(jpg_file)
png_name = jpg_name.replace("jpg", "png")
print(f"{
jpg_name} ------> {
png_name}\n")
print("转换中, 请等待......")
image = Image.open(jpg_name)
image.save(png_name)
print("转换完毕\n\n按下任意键结束")
else:
print("当前文件夹中没有jpg\n")
print("按下任意键结束")
# 防止程序自行结束
msvcrt.getch()
3.2、Work2Pdf.py
########################################
########################################
# @author leon
# @date 2023-06-26
# @description 将同目录下的word文档转换为pdf
########################################
########################################
import glob
import msvcrt
import os
from docx2pdf import convert
# 搜索当前文件夹中的docx/doc
word_files = glob.glob("*.docx") + glob.glob("*.doc")
word_cnt = len(word_files)
# 开始转换
if word_cnt > 0:
print(f"当前文件夹有{
word_cnt}个word文档(docx/doc)")
for word_file in word_files:
word_name = os.path.basename(word_file)
pdf_name = word_name.replace(".docx", ".pdf") if word_name.endswith(".docx") else word_name.replace(".doc", ".pdf")
print(f"{
word_name} ------> {
pdf_name}\n")
print("转换中, 请等待......")
convert(word_name, pdf_name)
print("转换完毕\n\n按下任意键结束")
else:
print("当前文件夹中没有docx/doc文档\n")
print("按下任意键结束")
# 防止程序自行结束
msvcrt.getch()
3.3、Compress.py
########################################
########################################
# @author leon
# @date 2023-06-26
# @description 将指定目录下的文件压缩为zip/7z
########################################
########################################
import msvcrt
import zipfile
import py7zr
import os
input_folder_path = input("输入文件路径进行压缩: ")
input_compress_format = input("输入压缩格式(zip/7z): ")
# 压缩为zip
def compress_zip(folder_path, compress_file_name):
with zipfile.ZipFile(compress_file_name, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
print(f"compress --- {
file_path}")
zipf.write(file_path, os.path.relpath(file_path, folder_path))
# 压缩为7z
def compress_7z(folder_path, compress_file_name):
with py7zr.SevenZipFile(compress_file_name, 'w') as seven_z_f:
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
print(f"compress --- {
file_path}")
seven_z_f.write(file_path, os.path.relpath(file_path, folder_path))
# 开始压缩
if len(input_folder_path) > 0:
if len(input_compress_format) > 0:
if input_compress_format == "zip":
zip_file_name = "compress_file.zip"
print(f"{
input_folder_path}中的文件被压缩至{
zip_file_name}")
print("压缩中, 请等待......")
compress_zip(input_folder_path, zip_file_name)
print("压缩完毕\n\n按下任意键结束")
elif input_compress_format == "7z":
seven_z_file_name = "compress_file.7z"
print(f"{
input_folder_path}中的文件被压缩至{
seven_z_file_name}")
print("压缩中, 请等待......")
compress_7z(input_folder_path, seven_z_file_name)
print("压缩完毕\n\n按下任意键结束")
else:
print("输入的不是zip或7z格式,无法压缩\n")
print("按下任意键结束")
# 防止程序自行结束
msvcrt.getch()
3.4、Decompress.py
########################################
########################################
# @author leon
# @date 2023-06-26
# @description 将当前目录下的zip/7z/rar解压
########################################
########################################
import glob
import msvcrt
import os
import zipfile
import rarfile
import py7zr
# 解压zip
def decompress_zip(zip_file_name, decompress_file_name):
with zipfile.ZipFile(zip_file_name, "r") as zip_ref:
for file_info in zip_ref.infolist():
# try:
# file_info.filename = file_info.filename.encode('cp437').decode('utf-8')
# # file_info.filename = unidecode(file_info.filename)
# except UnicodeDecodeError:
# file_info.filename = file_info.filename.encode('cp437').decode('gbk')
print(f"decompress --- {
file_info.filename}")
zip_ref.extract(file_info, decompress_file_name)
# 解压7z
def decompress_7z(seven_z_file_name, decompress_file_name):
with py7zr.SevenZipFile(seven_z_file_name, "r") as seven_z_archive:
seven_z_archive.extractall(decompress_file_name)
# files = seven_z_archive.list()
# for file_info in files:
# file_name = file_info.filename
# print(f"decompress --- {file_name}")
# seven_z_archive.extract(decompress_file_name)
# 解压rar
def decompress_rar(rar_file_name, decompress_file_name):
with rarfile.RarFile(rar_file_name, "r") as rar_ref:
for file_info in rar_ref.infolist():
# try:
# file_info.filename = file_info.filename.encode('cp437').decode('utf-8')
# except UnicodeDecodeError:
# file_info.filename = file_info.filename.encode('cp437').decode('gbk')
print(f"decompress --- {
file_info.filename}")
rar_ref.extract(file_info, decompress_file_name)
# 搜索当前文件中的zip/rar
compress_files = glob.glob("*.zip") + glob.glob("*.7z") + glob.glob("*.rar")
compress_cnt = len(compress_files)
# 解压文件名
def get_decompress_name(temp_compress_name):
if temp_compress_name.endswith(".zip"):
return temp_compress_name.replace(".zip", "")
elif temp_compress_name.endswith(".7z"):
return temp_compress_name.replace(".7z", "")
else:
return temp_compress_name.replace(".rar", "")
# 开始解压
if compress_cnt > 0:
print(f"当前文件夹有{
compress_cnt}个压缩文件(zip/rar/7z)")
for compress_file in compress_files:
compress_name = os.path.basename(compress_file)
decompress_name = get_decompress_name(compress_name)
print(f"{
compress_name} ------> {
decompress_name}")
print("解压中, 请等待......")
if compress_name.endswith(".zip"):
# zip
decompress_zip(compress_name, decompress_name)
print("解压完毕\n\n按下任意键结束")
elif compress_name.endswith(".7z"):
# 7z
decompress_7z(compress_name, decompress_name)
print("解压完毕\n\n按下任意键结束")
else:
# rar
decompress_rar(compress_name, decompress_name)
# patoolib.extract_archive(compress_name, decompress_name)
print("解压完毕\n\n按下任意键结束")
else:
print("当前文件夹中没有zip/rar文档\n")
print("按下任意键结束")
# 防止程序自行结束
msvcrt.getch()