目录
情况2:此时我将该程序运行的结果输出重定向到一个文本文件中:
一.什么是缓冲区?
说到缓冲区就需要先来看一个程序代码来了解一下什么是缓冲区。

1.1实验案例1:
#include<stdio.h>
#include<sys/types.h>
#include<wait.h>
#include<unistd.h>
#include<string.h>
int main(){
//C语言库函数
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char* str="hello fputs\n";
fputs(str,stdout);
//系统调用
const char* buf="hello write\n";
write(1,buf,strlen(buf));
fork(); //创建子进程
return 0;
} 代码解析:开头我写了3个输出函数printf、fprintf、fputs,然后又调用了一个系统调用函数write,它也是一个将内容写入到指定的文件流函数。我将这4个函数全都设为输出到stdout标准输出流(屏幕)中去。然后调用了fork函数,创建了一个子进程后,进程就退出了。
情况1:运行该程序
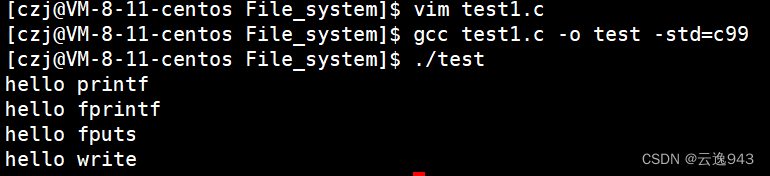 结果共输出四句话,代码程序无误。
结果共输出四句话,代码程序无误。
情况2:此时我将该程序运行的结果输出重定向到一个文本文件中:
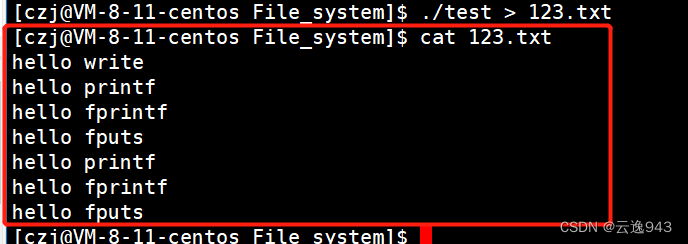
./test > 123.txt语句的作用:将./test运行的结果打印到123.txt文本文件中,然后我们来看一看该文本文件中的内容,发现一共有7条语句!通过上面运行test可执行文件的结果也不过才输出了4条语句,可为什么这次输出了7条语句?
通过结果分析:我们发现关于C语言库函数printf、fprintf、fputs的语句各有两条,而系统调用函数write的语句只有一条。根据结果推测出只有采用C语言函数的语句会额外多出来一份!
而导致这个奇怪问题的“罪魁祸首”就是缓冲区了。我们在学习C语言的过程中,经常用到printf函数,该函数的作用就是将想所写的内容打印到屏幕中去,而在打印的过程中其实还需要经历很重要的一步:会经过一段空间,而这段空间就是缓冲区。 例如,printf("hello world\n"); 我们想要在屏幕中打印字符串"hello world\n",就需要先将该字符串放到缓冲区中,然后在缓冲区中,读取传过来的" hello world\n",在读到\n字符时,缓冲区就立即刷新到屏幕中。遇到\n字符就刷新缓冲区的情况是显示器stdout的特性,它是行缓冲方式。
而fprintf、fputs函数也是如此,都需要经过缓冲区,而一遇到\n字符都会立即刷新缓冲区到屏幕中;对于系统调用函数write,它就不会经过缓冲区,而是直接打印到屏幕中去。原因就是缓冲区是printf、fprintf、fputsC库函数特有的,而系统调用没有。之后便是fork函数了,作用是创建一个子进程,这时该进程中共有父子两个进程,注:创建出的子进程会继承到父进程的大部分属性数据哟!
因为在情况1中,三个C语言输出函数都是将各自的内容打印到stdout中,且都有\n字符,根据显示器行缓冲的策略可知:这些内容一旦经过缓冲区就立即被刷新到了屏幕中,缓冲区的内容就会被清空了,子进程继承父进程的属性时,没有继承到缓冲区内容。
而在情况2中,输出重定向从stdout到了文本文件123.txt中,即使C库函数有\n字符,缓冲区也不会立即刷新到文件中,因为文件的刷新策略是全缓冲,只有当缓冲区满了或者进程退出了才会刷新缓冲区,而对于系统调用write来说,它由于没有缓冲区,所以直接输出内容到文件中了。
于是当fork创建出子进程后,子进程会继承父进程的属性数据(包括缓冲区中存留的内容),正好遇到了留在缓冲区的3行内容还没刷新到指定文件的情况,于是根据写实拷贝的原理,子进程也拥有了缓冲区的3行函数输入的内容,之后便是执行return 0;当父子进程中的某一个先退出后(谁先谁后退出没有关系),触发了文件的缓冲刷新策略,该进程的缓冲区立即刷新到文件中,然后另一个进程也退出了,也触发了文件的缓冲刷新策略,于是共有两份的C库函数的内容和一份系统调用函数的内容——7行被输出到了该文件中,那么最终的原因也就理清了。
注:上文提到的缓冲区的刷新策略下面会讲~~
二.为什么要有缓冲区?
同样的,我来举个例子方便大家理解缓冲区的意义:
小明和小丽都是大学生,他们是男女朋友关系,由于高考分数的差异,他们分别在北京和陕西上大学,将最近是期末考试,他发现过两天是小丽的生日且想要送小丽生日礼物,但时间紧迫,做法1:于是他买好后带着礼物赶忙从北京坐飞机、动车、出租来到了小丽所在的学校将礼物送给她,然后飞快的回到学校应对考试;做法2:他将买好的礼物拿到快递站中让快递员给他邮过去。
这个案例说明了什么?
说明了小明亲自带着礼物去很花时间;而使用快递邮过去的方法节省了大量时间。(注:这里不谈男朋友亲自送过来怎么怎么样.....,望大家不要杠~哈哈哈)。
所以快递公司就好比是缓冲区,小明是进程,小丽是磁盘文件,这就相当于是进程通过缓冲区对磁盘文件进行数据 I/O的高效传输行为。
但是邮快递也是需要注意这样一个问题,你去快递公司邮东西时,快递员无法立即给你打包好出发,只有当去往该地的快递货车在出货量达满或者达到一定要求后才会出发。
假如有一块1024字节大小的数据,是一次性写到磁盘(外设)好呢还是少量多次的写到磁盘好呢?很明显,是一次写入磁盘的效率是最高的,是最省时间的。因为写内容到指定文件中是需要先访问的,先访问就需要调用open、fopen函数,调用的次数多了,效率也就下去了。
于是引出了缓冲区的刷新策略:
策略1:立即刷新 —— 无缓冲 —— 传输的内容很少,所以直接刷新缓冲区到指定地方。
策略2:行缓冲 ——显示器(给用户看的)—— 行缓冲是几行几行的从缓冲区中刷新内容,人们的习惯是一次几行几行的看,若是一次输出一整篇文章,反而看的有些痛苦。
策略3:全缓冲 ——磁盘文件 —— 效率最高,会将内容全都传输到文件中去。
我们大部分用的就是行缓冲或者全缓冲策略,在行缓冲区中使用C库输出函数遇到\n字符,或者使用系统调用函数fflush(stdout);强制刷新缓冲区的内容,或者等到进程退出也有可以刷新缓冲区内容。
这就是缓冲区存在的意义,能够给使用者节约大量的时间。 假如进程对磁盘文件进行数据IO的时间为1秒,那么有990毫秒是在进行数据的拷贝,而10毫秒是在进行数据的传输。
三.缓冲区在哪
根据上面的案例可知:我们所说的缓冲区是语言级别的缓冲区,它一定不在系统内核中,否则write函数在重定向到文件时它也会出现两次。因为printf、fprintf、fputs是会自带缓冲区的,这是C库函数自带的,而我们又知道在使用fopen函数访问文件时,它的返回值是FILE*的指针,所以缓冲区就和C语言给我们提供的FILE类型有关:
FILE也是一种数据类型,说明它也是一个结构体,我们可以在Linux的路径:/usr/include/libio.h源代码中查找FILE:


所以缓冲区就在struct _IO_FILE结构体内。
而write等系统调用函数是没有FILE数据类型的,所以它们也就没有缓冲区。