Q1.用scrapy shell “http://****”命令测试过xpath,可以确定xpath没有问题,但pycharm就是提示xpath有问题
A1: 把xpath中的"改成’,'改成",如果这个方法还不行,就重启pycharm重试下
Q2:控件class名或id名都对,xpath就是报错,用scrapy shell “http://****”命令测试xpath也是报错,
举例:response.xpath(’//article[@class=“news”]//a’)
A2:关注下页面中控件对应的class或id,是不是有多个,换个别的控件作为查找依据~
例子:页面上class为news的article很多,导致在找a标签过程中有报错,换个别的元素,比如父类div,或者子类p
Q3:控件class名或id名都对,排除Q2情况,xpath就是报错,用scrapy shell “http://****”命令测试xpath也是报错,
举例:获取百度主页左上角的按钮列表
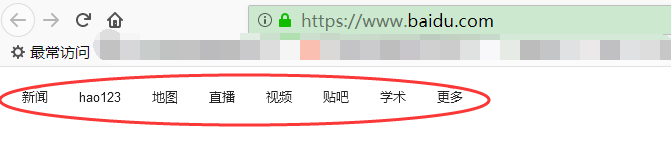
A3: 主要原因是通过浏览器访问的html和scrapy抓取到的html是不一样
例子:如果通过浏览器访问,页面源码如图所示

我们可以通过xpath("//div[@id=‘s-top-left’]//a"),用firefox浏览器的Try Xpath插件可以看到xpath语句是没有问题的
![Try Path插件运行xpath("//div[@id='s-top-left']//a")(guggle简书原创)](https://img-blog.csdnimg.cn/img_convert/a07bee6aac9eb5024efb9fdf516d2d82.png)
如果要看scrapy访问页面的源码,可以在cmd命令窗口输入
>scrapy shell "https://www.baidu.com"
命令完成后,屏幕显示In [1]: ,再输入
>view(response)
浏览器自动打开scrapy抓到的html,源码为

我们需要通过xpath("//div[@id=‘u1’]//a")才能找到按钮列表,用firefox浏览器的Try Xpath插件验证结果
![Try Path插件运行xpath("//div[@id='u1']//a")(guggle简书原创)](https://img-blog.csdnimg.cn/img_convert/ff2e4708c3c17761423204d1520ea518.png)
我们在spider脚本中,写response.xpath("//div[@id=‘u1’]//a")才能找到百度首页的这些按钮列表,通过response.xpath("//div[@id=‘s-top-left’]//a")可是找不到的哦~
Q4:使用scrapy自带的’scrapy.pipelines.images.ImagesPipeline’,setting中配置下载目录IMAGES_STORE = “guggle_jianshu”,图片无法下载到本地
A4:spider中parse方法中返回的item,需要使用image_urls这个key值,并且这个image_urls对应的value值是个list

PS:如果需要使用scrapy.pipelines.files.FilesPipeline,系统默认是使用file_urls这个key值
如果需要使用scrapy.pipelines.images.ImagesPipeline,但是不用系统自定义的key值,需要在setting中配置IMAGES_URLS_FIELD = “guggle_img”
