MySQL数据库中提供了很丰富的函数。MySQL函数包括数学函数、字符串函数、日期和时间函数、条件判断函数、系统信息函数、加密函数、格式化函数、聚合函数等。
数学函数
| 函数 | 作用 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| CEIL(x),CEILING(x) | 向上取整,返回大于或者等于x的最小整数 |
| FLOOR(x) | 返回小于或者等于x的最大整数 |
| RAND() | 返回0~1的随机数 |
| RAND(x) | 返回0~1的随机数,x值相同时返回的随机数相同 |
| SIGN(x) | 返回x的符号,x是负数、0、正数分别返回-1、0和1 |
| PI() | 返回圆周率 |
| TRUNCATE(x,y) | 返回数值x保留到小数点后y位的值 |
| ROUND(x) | 四舍五入,返回离x最近的整数 |
| ROUND(x,y) | 四舍五入,保留x小数点后y位的值,但截断时要进行四舍五入 |
| POW(x,y),POWER(x,y) | 返回x的y次方 |
| SQRT(x) | 返回x的平方根 |
| EXP(x) | 返回e的x次方 |
| MOD(x,y) | 返回x除以y以后的余数 |
| LOG(x) | 返回自然对数(以e为底的对数) |
| LOG10(x) | 返回以10为底的对数 |
示例:
ABS(x)
- 作用:返回x的绝对值
- 参数x:数值
---------
CEIL(x) 和 CEILING(x)
- 作用:向上取整
- 参数x:数值
SELECT CEIL(10.2),CEILING(10); #结果: 11,10
----------
FLOOR(x)
- 作用:向下取整
- 参数x:数值
SELECT FLOOR(10.6); #结果 :10
----------
RAND(x)
- 作用:返回0~1的随机数,x值相同时返回的随机数相同
- 参数x:无或者任意值(字符或者数值)
SELECT RAND('a'),RAND('a'); #结果:返回两个相同的随机数
----------
SIGN(x)
- 作用:返回x的符号,x是负数、0、正数分别返回-1、0和1
- 参数x:数值
SELECT SIGN(-10); #结果:-1
----------
PI()
- 作用:返回圆周率
- 参数x:无
---------
TRUNCATE(x,y)
- 作用:返回数值x保留到小数点后y位的值
- 参数xy:数值
----------
ROUND(x)
- 作用:四舍五入,返回离x最近的整数
- 参数x:数值
SELECT ROUND(10.51); #结果:11
从第一个小数开始四舍五入,取整数。
----------
ROUND(x,y)
- 作用:四舍五入,保留x小数点后y位的值
- 参数xy:数值
SELECT ROUND(10.525 , 2); #结果:10.53
从第3个小数开始四舍五入,保留两位小数。
----------
POW(x,y) 和 POWER(x,y)
- 作用:返回x的y次方
- 参数xy:数值
SELECT POW(10,2); #结果:100
10的2次方等于100
SQRT(x)
- 作用:返回x的平方根
- 参数x:数值
SELECT SQRT(4); #结果:2
4的平方根等于2
EXP(x)
- 作用:返回e的x次方
- 参数x:数值
SELECT EXP(0); #结果:1
e的0次方等于1
MOD(x,y)
- 作用:返回x除以y以后的余数
- 参数xy:数值
SELECT MOD(10,3); #结果:1
10%3 = 1
LOG(x)
- 作用:返回自然对数(以e为底的对数)
- 参数x:数值
SELECT LOG(1); #结果:0
e的0次方等于1
LOG10(x)
- 作用:返回以10为底的对数
- 参数x:数值
SELECT LOG10(100); #结果:2
10的2次方等于100
================
字符串函数
| 函数 | 作用 |
|---|---|
| CHAR_LENGTH(s) | 返回字符串s的字符长度(不考虑位数) |
| LENGTH(s) | 返回字符串s的字节长度(需要考虑位数) |
| CONCAT(s1,s2,…) | 将字符串s1,s2等多个字符串合并为一个字符串 |
| CONCAT_WS(x,s1,s2,..) | 同CONTAC(S1,S2,…)函数,但是每个字符串要直接加上x |
| INSERT(s1,x,len,s2) | 将字符串s2替换s1的位置开始长度为len的字符串 |
| UPPER(s),UCASE(s) | 将字符串s的所有字母都变成大写字母 |
| LOWER(s),LCASE(s) | 将字符串s的所有字母都变成小写字母 |
| LEFT(s,n) | 返回字符串s前n个字符 |
| RIGHT(s,n) | 返回字符串s后n个字符 |
| LPAD(s1,len,s2) | 字符串s2来填充s1的开始处,使字符串的长度达到len |
| RPAD(s1,len,s2) | 字符串s2来填充s1的结尾处,使字符串的长度达到len |
| LTRIM(s) | 去掉字符串s开始处的空格 |
| RTRIM(s) | 去掉字符串s结尾处的空格 |
| TRIM(s) | 去掉字符串s开始处和结尾处的空格 |
| TRIM(s1 FROM s) | 去掉字符串s开始处和结尾处的字符串s1 |
| REPEAT(s,n) | 将字符串s重复n次 |
| SPACE(n) | 返回空格n次 |
| REPLACE(s,s1,s2) | 用字符串s2代替字符串s中的字符串s1 |
| STRCMP(s1,s2) | 比较字符串s1,s2 |
| SUBSTRING(s,n,len) | 获取从字符串s中第n个位置开始长度为len的字符串 |
| MID(s,n,len) | 同SUBSTRING(s,n,len) |
| LOCATE(s1,s),POSITION(s1 IN S) | 从字符串s中获取字符串s1的开始位置 |
| INSTR(s,s1) | 从字符串s中获取字符串s1的开始位置 |
| REVERSE(s) | 将字符串s的顺序反过来 |
| ELT(n,s1,s2,…) | 返回第n个字符串 |
| FIELD(s,s1,s2,…) | 返回第一个与字符串s匹配的字符串的位置 |
| FIND_IN_SET(s1,s2) | 返回在字符串s2中与字符串s1匹配的字符串的位置 |
| MAKE_SET(x,s1,s2,…) | 按x的二进制数从s1,s2,…,sn中选取字符串 |
示例:
CHAR_LENGTH(s)
- 作用:返回字符串s的字符长度
- 参数:字符串
SELECT CHAR_LENGTH('Jack你好'); #结果:6
- 说明:返回的是字符的长度,有几个字符就是多少长度
----------
LENGTH(s)
- 作用:返回字符串s的字节长度
- 参数:字符串
SELECT LENGTH('Jack你好'); #结果:10
- 说明:返回的是字节长度,需要考虑位数。上面一个中文字符算作3个字节。
----------
CONCAT(s1,s2,…)
- 作用:将字符串s1,s2等多个字符串合并为一个字符串
- 参数:字符串
SELECT CONCAT('aa' , 'bb' , 'cc'); #结果:aabbcc
----------
CONCAT_WS(x,s1,s2,..)
- 作用:同CONTAC(S1,S2,…)函数,但是每个字符串要直接加上x
- 参数:字符串
SELECT CONCAT_WS('S','aa','bb','cc'); #结果:aaSbbScc
- 说明:从s2开始,每个字符前都要加上x
----------
INSERT(s1,x,len,s2)
- 作用: 把字符串s1由位置x起len个字符长的子串替换为字符串s2
- 参数:字符串(s1,s2)和数值(x,len)
SELECT INSERT( 'abcde' , 3 , 2 , 'cc' ); #结果:abcce
- 说明:abcde 从第三个字符 c 开始截取两个字符即 cd 替换为 cc ,最后变为 abcce
----------
UPPER(s) 和 UCASE(s)
- 作用:将字符串s的所有字母都变成大写字母
- 参数:字符串
SELECT UPPER('abcDE'); #结果:ABCDE
----------
LOWER(s) 和 LCASE(s)
- 作用:将字符串s的所有字母都变成小写字母
- 参数:字符串
SELECT UPPER('abcDE'); #结果:abcde
----------
LEFT(s,n) 和 RIGHT(s,n)
- 作用:返回字符串s前(后)n个字符
- 参数:字符串(s),数值(n)
SELECT LEFT('abcDE',3); #结果:abc
SELECT RIGHT('abcDE',3); #结果:cDE
----------
LPAD(s1,len,s2) 和 RPAD(s1,len,s2)
- 作用:如果s1长度不足len,在左边(右边)使用s2填充
- 参数:字符串(s1,s2),数值(len)
SELECT LPAD('abc',5,'s'); #结果:ssabc
SELECT RPAD('abc',5,'s'); #结果:abcss
如果s1长度大于len,则就是截取s1
SELECT LPAD('abc',1,'s'); #结果:a
----------
LTRIM(s) 和 RTRIM(s)
- 作用:去掉字符串s左边(右边)的空格
- 参数:字符串
SELECT LTRIM(' abc'); #结果:abc
SELECT RTRIM('abc '); #结果:abc
----------
TRIM(s)
- 作用:去掉字符串s两边的空格
- 参数:字符串
SELECT TRIM(' abc '); #结果:abc
----------
TRIM(s1 FROM s)
- 作用:去掉字符串s开始处和结尾处的字符串s1
- 参数:字符串
----------
REPEAT(s,n)
- 作用:将字符串s重复n次
- 参数:字符串(s),数值(n)
SELECT REPEAT('s',5); #结果:sssss
----------
SPACE(n)
- 作用:返回空格n次
- 参数:数值
SELECT SPACE(50); #结果:
----------
REPLACE(s,s1,s2)
- 作用:用字符串s2代替字符串s中的字符串s1
- 参数:字符串
SELECT REPLACE('abcde','cd','ss'); #结果:absse
可以用来去空格
SELECT REPLACE( 'ab c de' , ' ' , ''); #结果:abcde
----------
STRCMP(s1,s2)
- 作用:比较字符串s1,s2,比较的是ASCII码。s1大于、等于、小于s2,返回1 、0 、-1
- 参数:数值
SELECT STRCMP('ab','ba'); #结果:-1
----------
SUBSTR(s,n,len) 、SUBSTRING(s,n,len) 和 MID(s,n,len)
- 作用:获取从字符串s中第n个位置开始长度为len的字符串
- 参数:字符串(s)、数值(n、len)
SELECT SUBSTR('abcde',2,3); #结果:bcd
----------
LOCATE(s1 , s) 和 POSITION(s1 IN S)
- 作用:从字符串s中获取字符串s1的开始位置
- 参数:字符串
SELECT LOCATE('bc','abcde'); #结果:2
SELECT POSITION('bc' IN 'abcde'); #结果:2
----------
INSTR(s , s1)
- 作用:返回以10为底的对数
- 参数:字符串
SELECT INSTR('abcde','bc'); #结果:2
- 说明: 注意和上面那个参数区别
----------
REVERSE(s)
- 作用:将字符串s的顺序反过来
- 参数:字符串
SELECT REVERSE('abcde'); #结果:edcba
----------
ELT(n,s1,s2,…)
- 作用:返回第n个字符串
- 参数:字符串(s1、s2...)、数值(n)
SELECT ELT(2,'a','b','c'); #结果:b
----------
FIELD(s,s1,s2,…)
- 作用:返回第一个与字符串s匹配的字符串的位置
- 参数:字符串
SELECT FIELD('c','a','b','c'); #结果:3
----------
FIND_IN_SET(s1,s2)
- 作用:返回字符串s2在字符串s1中匹配的字符串的位置
- 参数:字符串
SELECT FIND_IN_SET( 'c' , 'a,b,c,d,e' ); #结果:3
- 说明:s2 必须用逗号隔开
================
日期和时间函数
| 函数 | 作用 |
|---|---|
| CURDATE(),CURRENT_DATE() | 返回当前日期,如2016-07-30 |
| CURTIME(),CURRENT_TIME() | 返回当前时间,如22:13:41 |
NOW(),CURRENT_TIMESTAMP(), LOCALTIME(),SYSDATE(),LOCALTIMESTAMP() |
返回当前日期和时间 |
| UNIX_TIMESTAMP() | 以UNIX时间戳的形式返回当前时间 |
| UNIX_TIMESTAMP(d) | 将时间d以UNIX时间戳的形式返回 |
| FROM_UNIXTIME(d) | 把UNIX时间戳的时间转换为普通格式时间 |
| UTC_DATE() | 返回UTC日期 |
| UTC_TIME() | 返回UTC时间 |
| MONTH(d) | 返回日期d中月份值,范围为1~12 |
| MONTHNAME(d) | 返回日期d中的月份名称,如January,Febuary |
| DAYNAME(d) | 返回日期d是星期几,如Monday,Tuesday |
| DAYOFWEEK(d) | 返回日期d是星期几,如1是星期一,2是星期二等 |
| WEEKDAY(d) | 返回日期d是星期几,如0是星期一,1是星期二等 |
| WEEK(d) | 计算日期d是本年的第几周,范围0~53 |
| WEEKOFYEAR | 计算日期d是本年的第几周,范围1~54 |
| DAYOFYEAR(d) | 计算日期d是本年的第几天 |
| DAYOFMONTH(d) | 计算日期d是本月的第几天 |
| YEAR(d) | 返回日期d的年份值 |
| QUARTER(d) | 返回日期d是第几个季度,范围1~4 |
| HOUR(t) | 返回时间t中的小时值 |
| MINUTE(t) | 返回时间t中的分钟值 |
| SECOND(t) | 返回时间t中的秒钟值 |
| EXTRACT(type FROM d) | 从日期d中获取指定值,type指定返回的值,如YEAR,HOUR等 |
| TIME_TO_SEC(t) | 将时间t转换为秒 |
| SEC_TO_TIME(s) | 将以秒为单位的时间s转换为时分秒的格式 |
| DATEDIFF(d1,d2) | 计算日期d1~d2之间相隔的天数 |
| SUBDATE(d,n) | 计算起始日期d减去n天的日期 |
示例:
CURDATE() 和 CURRENT_DATE()
- 作用:返回当前日期,如2018-01-01
- 参数:无
SELECT CURDATE(); #结果:2018-06-05
----------
CURTIME() 和 CURRENT_TIME()
- 作用:返回当前时间,如22:13:41
- 参数:无
SELECT CURTIME(); #结果:16:36:28
----------
NOW()、CURRENT_TIMESTAMP()
、LOCALTIME()、SYSDATE() 和 LOCALTIMESTAMP()
- 作用:返回当前日期和时间
- 参数:无
SELECT NOW(); #结果:2018-06-05 16:39:29
----------
UNIX_TIMESTAMP()
- 作用:以UNIX时间戳的形式返回当前时间(毫秒形式)
- 参数:无
SELECT UNIX_TIMESTAMP(); #结果:1528188019
----------
UNIX_TIMESTAMP(d)
- 作用:将时间d以UNIX时间戳的形式返回
- 参数:日期字符串
SELECT UNIX_TIMESTAMP('2018-06-05 16:39:29'); #结果:1528187969
----------
FROM_UNIXTIME(d)
- 作用:把UNIX时间戳的时间转换为普通格式时间
- 参数:字符串或数值
SELECT FROM_UNIXTIME(1528187969); #结果:2018-06-05 16:39:29
----------
UTC_DATE()
- 作用:返回UTC日期
- 参数:无
SELECT UTC_DATE(); #结果:2018-06-05
----------
UTC_TIME()
- 作用:返回UTC时间
- 参数:无
SELECT UTC_TIME(); #结果:08:48:11
----------
MONTH(d)
- 作用:返回日期d中月份值,范围为1~12
- 参数:日期字符串
SELECT MONTH('2018-06-05'); #结果:6
----------
MONTHNAME(d)
- 作用:返回日期d中的月份名称,如January,Febuary
- 参数:日期字符串
SELECT MONTHNAME('2018-06-05'); #结果:June
----------
DAYNAME(d)
- 作用:返回日期d是星期几,如Monday,Tuesday
- 参数:日期字符串
SELECT DAYNAME('2018-06-05'); #结果:Tuesday
----------
DAYOFWEEK(d)
- 作用:返回日期d是星期几,从星期天开始算。1是星期天,2是星期一等
- 参数:日期字符串
SELECT DAYOFWEEK('2018-06-05'); #结果:3
----------
WEEKDAY(d)
- 作用:返回日期d是星期几,如0是星期一,1是星期二等
- 参数:日期字符串
SELECT WEEKDAY('2018-06-05'); #结果:1
----------
WEEK(d)
- 作用:计算日期d是本年的第几周,范围0~53
- 参数:日期字符串
SELECT WEEK('2018-06-05'); #结果:22
----------
WEEKOFYEAR(d)
- 作用:计算日期d是本年的第几周,范围1~54
- 参数:日期字符串
SELECT WEEKOFYEAR('2018-06-05'); #结果:23
----------
DAYOFYEAR(d)
- 作用:计算日期d是本年的第几天
- 参数:日期字符串
SELECT DAYOFYEAR('2018-06-05'); #结果:156
----------
DAYOFMONTH(d)
- 作用:计算日期d是本月的第几天
- 参数:日期字符串
SELECT DAYOFMONTH('2018-06-05'); #结果:5
----------
YEAR(d)
- 作用:返回日期d的年份值
- 参数:日期字符串
SELECT YEAR('2018-06-05'); #结果:2018
----------
QUARTER(d)
- 作用:返回日期d是第几个季度,范围1~4
- 参数:日期字符串
SELECT QUARTER('2018-06-05'); #结果:2
----------
HOUR(t)
- 作用:返回时间t中的小时值
- 参数:时间字符串
SELECT HOUR('2018-06-05 17:10:00'); #结果:17
----------
MINUTE(t)
- 作用:返回时间t中的分钟值
- 参数:时间字符串
SELECT MINUTE('2018-06-05 17:10:00'); #结果:10
----------
SECOND(t)
- 作用:返回时间t中的秒钟值
- 参数:时间字符串
SELECT SECOND('2018-06-05 17:10:20'); #结果:20
----------
EXTRACT(type FROM d)
- 作用:从日期d中获取指定值,type指定返回的值,如YEAR,MONTH等
- 参数:日期字符串(d)、关键字(type)
SELECT EXTRACT(YEAR FROM '2018-06-05 17:10:20'); #结果:2018
----------
TIME_TO_SEC(t)
- 作用:将时间t转换为秒
- 参数:时间字符串
SELECT TIME_TO_SEC('17:10:20'); #结果:61820
----------
============
条件判断函数
| 函数 | 作用 |
|---|---|
IF(expr, v1, v2) |
如果expr成立,返回值为v1,否则返回v2 |
IFNULL(v1, v2) |
如果v1不为空,就显示v1,否则就显示v2的值 |
| CASE WHEN |
多条件判断 |
示例:
IF(expr, v1, v2)
- 作用:如果expr成立,返回值为v1,否则返回v2
- 参数:expr整体表示TRUE或FALSE,可以是一个表达式。v1、v1可以为任何值,具体看需求。
SELECT IF(1=1,'aaa','bbb'); #结果:aaa
----------
IFNULL(v1, v2)
- 作用:如果v1不为NULL,就显示v1,否则就显示v2的值
- 参数:任意值
SELECT IFNULL(NULL,'bbb'); #结果:bbb
v1必须为NULL,才会显示v2, '' 和 ' ' 都不可以
----------
CASE WHEN
- 作用:多条件判断语句
- 参数:无
格式#1:
CASE [col_name] WHEN [value1] THEN[result1]…ELSE [default] END
枚举这个字段所有可能的值
SELECT NAME AS '英雄',
CASE NAME
WHEN '德莱文' THEN '斧子'
WHEN '盖伦' THEN '大宝剑'
ELSE '其他'
END AS '装备'
FROM user_info;
结果:
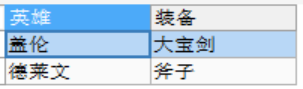
格式#2:
CASE WHEN [expr] THEN [result1]…ELSE[default] END
多条件
SELECT NAME,
CASE
WHEN grade >= 80 THEN '优秀'
WHEN grade >= 60 AND grade <80 THEN '及格'
ELSE '不及格'
END AS 'grade'
FROM
student;
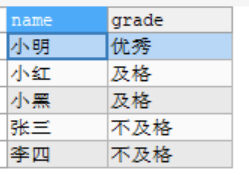
----------
============
系统信息函数
| 函数 | 作用 |
|---|---|
| VERSION() | 返回数据库的版本号 |
| CONNECTION_ID() | 返回服务器的连接数 |
| DATABASE(),SCHEMA() | 返回当前数据库名 |
USER(),SYSTEM_USER(), SESSION_USER(),CURRENT_USER() |
返回当前用户 |
| CHARSET(str) | 返回字符串str的字符集 |
| LAST_INSERT_ID() | 返回最近生成的AUTO_INCREMENET值 |
示例:
VERSION()
- 作用:返回数据库的版本号
- 参数:无
SELECT VERSION(); #结果:5.1.49-community
----------
CONNECTION_ID()
- 作用:返回服务器的连接数
- 参数:无
SELECT CONNECTION_ID(); #结果:1
----------
DATABASE() 和 SCHEMA()
- 作用:返回当前数据库名
- 参数:无
SELECT DATABASE(); #结果:myemployees
----------
USER() 、SYSTEM_USER()、CURRENT_USER() 和 SESSION_USER()
- 作用:返回当前用户
- 参数:无
SELECT USER(); #结果:root@localhost
----------
CHARSET(str)
- 作用:返回字符串str的字符集
- 参数:字符串
SELECT CHARSET(''); #结果:utf8
----------
LAST_INSERT_ID()
- 作用:返回最近生成的AUTO_INCREMENET值
- 参数:无
SELECT LAST_INSERT_ID(); #结果:6
----------
=============
加密函数
| 函数 | 作用 |
|---|---|
| PASSWORD(str) | 主要是用来给用户的密码加密的 |
| MD5加密 | 主要对普通的数据进行加密 |
| ENCODE(str,key)和DECODE(str,key) | 使用key作为密钥加密解密字符串str |
| SHA(str)和SHA1(str) | SHA加密 |
PASSWORD(str)
- 作用:PASSWORD(str)函数主要是用来给用户的密码加密的
- 参数:字符串
SELECT PASSWORD('123456'); #结果:*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
----------
MD5(str)
- 作用:MD5加密
- 参数:字符串
SELECT MD5('123456'); #结果:e10adc3949ba59abbe56e057f20f883e
----------
ENCODE(str,key)和DECODE(str,key)
- 作用:使用key作为密钥加密解密字符串str
- 参数:字符串
SELECT DECODE(ENCODE('123456','password'),'password'); #结果:123456
----------
SHA(str)和SHA1(str)
- 作用:SHA加密
- 参数:字符串
SELECT SHA('123456'); #结果:7c4a8d09ca3762af61e59520943dc26494f8941b
----------
==========
格式化函数
| 函数 | 作用 |
|---|---|
| FORMAT(n,d) | 数字格式化,格式化后得到结果:###,###.##### |
示例:
FORMAT(n,d)
- 作用:数字格式化,指定保留的小数位,多余的四舍五入。格式化后得到结果:###,###.#####
- 参数:数值
SELECT FORMAT(100000.125 , 2 ); #结果:100,000.13
保留两位小数,并四舍五入
----------
============
聚合函数
| 函数 | 作用 |
|---|---|
| AVG(col) | 返回指定列的平均值 |
| COUNT(col) | 返回指定列中非NULL值的个数 |
| COUNT(1)、COUNT(*) | 返回有多少条数据 |
MIN(col) |
返回指定列的最小值 |
MAX(col) |
返回指定列的最大值 |
SUM(col) |
返回指定列的所有值之和 |
GROUP_CONCAT(col) |
返回由属于一组的列值连接组合而成的结果 |
| GROUP BY col1,col2... [HAVING] | 将查询结果按 col1,col2...组合就进行分组,组合数据相同的为一组 |
示例:
student表数据

AVG([DISTINCT] col)
- 作用:返回指定列的平均值
- 参数:查询列(数值)
SELECT AVG(grade) FROM student; #结果:72
先去重再计算:
SELECT AVG(DISTINCT grade) FROM student; #结果:70
- 说明:
- 结果视具体的表数据而定。
- NULL值不参与计算。
- 先进行去重,再计算
----------
COUNT([DISTINCT] col)
- 作用:返回指定列中非NULL值的个数
- 参数:查询列
SELECT COUNT(grade) FROM student; #结果:7
先去重再计算:
SELECT COUNT(DISTINCT grade) FROM student; #结果:5
- 说明:
- 结果视具体的表数据而定。
- NULL值不参与计算。
- 先进行去重,再计算
----------
COUNT(1) 和 COUNT(*)
- 作用:返回有多少条数据
- 参数:任意字符或数值
SELECT COUNT(*) FROM student; #结果:7
- 说明:
- 结果视具体的表数据而定。
- 这里计算的是数据条数,跟是否NULL值没有关系。
----------
MIN([DISTINCT] col)
- 作用:返回指定列的最小值
- 参数:查询列(数值、字符串、时间...)
SELECT MIN(grade) FROM student; #结果:45
- 说明:
- 结果视具体的表数据而定。
----------
MAX([DISTINCT] col)
- 作用:返回指定列的最大值
- 参数:查询列(数值、字符串、时间...)
SELECT MAX(grade) FROM student; #结果:80
- 说明:
- 结果视具体的表数据而定。
----------
SUM([DISTINCT] col)
- 作用:返回指定列的所有值之和
- 参数:查询列(数值)
SELECT SUM(grade) FROM student; #结果:510
先去重再计算:
SELECT SUM(DISTINCT grade) FROM student; #结果:305
- 说明:
- 结果视具体的表数据而定
- 先进行去重,再计算
----------
GROUP_CONCAT(col)
- 作用:返回由属于一组的列值连接组合而成的结果
- 参数:查询列
案例详解:
原表数据:
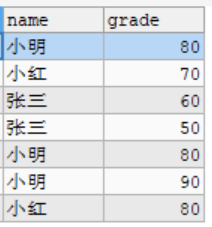
1. 使用GROUP_CONCAT(col)可以将每个学生的成绩组合到一列中,并且默认用逗号分割:
SELECT NAME,GROUP_CONCAT(grade) FROM student GROUP BY NAME;

2. 去重处理 GROUP_CONCAT( DISTINCT col) :
SELECT NAME,GROUP_CONCAT(DISTINCT grade) FROM student GROUP BY NAME;
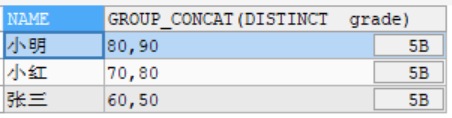
3. 排序 GROUP_CONCAT( col ORDER BY col [DESC,ASC]) :
SELECT NAME,GROUP_CONCAT( grade ORDER BY grade DESC) FROM student GROUP BY NAME;

4. 设置分隔符 GROUP_CONCAT( col SEPARATOR str) :
SELECT NAME,GROUP_CONCAT(grade SEPARATOR ';') FROM student GROUP BY NAME;

说明: 上面几个都可以同时使用
----------
GROUP BY col1,col2... [HAVING]
- 作用:将查询结果按 col1,col2...组合就进行分组,组合数据相同的为一组.使用HAVING进行分组后的筛选
- 参数:查询列
SELECT NAME,SUM(grade) FROM student GROUP BY NAME;
#结果:
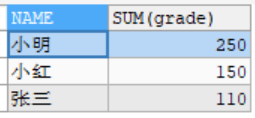
分组后的筛选:
SELECT NAME,SUM(grade) FROM student GROUP BY NAME HAVING SUM(grade)>200;
#结果:
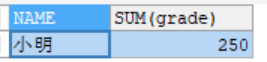
- 说明:
- 通过 GROUP BY 后面的NAME列进行分组,然后再每个分组中计算总数。这时候可以列出NAME列。
- GROUP BY后面可以使用多个列进行分组,这时候可以列出这些分组列数据。
- GROUP BY可以使用再所有聚合函数中。
----------