文章转载自:
http://blog.csdn.net/qwe6112071/article/details/50991563
https://blog.csdn.net/wenniuwuren/article/details/41483667
https://blog.csdn.net/qwe6112071/article/details/50989406
Quartz框架需求引入
在现实开发中,我们常常会遇到需要系统在特定时刻完成特定任务的需求,在《spring学习笔记(14)引介增强详解:定时器实例:无侵入式动态增强类功能》,我们通过引介增强来简单地模拟实现了一个定时器。它可能只需要我们自己维护一条线程就足以实现定时监控。但在实际开发中,我们遇到的需求会复杂很多,可能涉及多点任务调度,需要我们多线程并发协作、线程池的维护、对运行时间规则进行更细粒度的规划、运行线程现场的保持与恢复等等。如果我们选择自己来造轮子,可能会遇到许多难题。这时候,引入Quartz任务调度框架会是一个很好的选择,它:
1. 允许我们灵活而细粒度地设置任务触发时间,比如常见的每隔多长时间,或每天特定时刻、特定日子(如节假日),都能灵活地配置这些成相应时间点来触发我们的任务
2. 提供了调度环境的持久化机制,可以将任务内容保存到数据库中,在完成后删除记录,这样就能避免因系统故障而任务尚未执行且不再执行的问题。
3. 提供了组件式的侦听器、各种插件、线程池等。通过侦听器,我们可以引入我们的事件机制,配合上异步调用,既能为我们的业务处理类解耦,同时还可能提升用户体验,关于事件机制的基本概念、解耦特性及其异步调用可移步参考我的另一篇文章《spring学习笔记(15)趣谈spring 事件:实现业务逻辑解耦,异步调用提升用户体验 》
实例解析概念
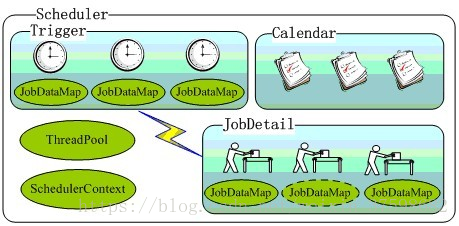
在quartz中,有几个核心类和接口:Job、JobDetail、Trigger、Calendar、Scheduler。
下面我们结合实例来分析这些类的角色定位。
现在我们有一个新闻网站,它有一张任务日志表,记录着我们的不同任务,比如每隔三十分钟要根据文章的阅读量和评论量来生成我们的最热文章列表。在每天早晚12点,定时从其他新闻网站扒取一定量新闻,在每周一晚上12点到3点进行论坛封闭维护,而如果遇到节假日则不维护等。在以上实例中:
- 生成最热文章,扒取新闻,论坛封闭维护都是我们的Job,它定义了我们的需要执行的任务,是一个抽象的接口.
- 如果我们要具体到每隔三十分钟生成最热文章,早晚12点扒取新闻等,在我们的具体任务执行时刻,我们就需要能够描述Job及其他相关静态信息的jobDetail,它相当于是我们的Job+具体实现细节
- 而Trigger则描述了Job执行的时间触发规则,比如每隔三十分钟、早晚12点等
- 而这里的Calendar可以看成是一些日历特定时间点的集合,比如我们这里遇到节假日则不维护,节假日如国庆节、愚人节等等,都是我们的日历特定时间点。
- 而Scheduler就是我们的任务日志表,它是一个容器,记载(容纳)了我们前面的工作、触发时间等内容。
具体用法详解
通过实例,我们对quartz的核心类有了较清晰的功能定位,根据Quratz的不同版本,这几个核心类有较大改动,具体的操作不太相同,但是思路是相同的;比如1.+版本jar包中,JobDetail是个类,直接通过构造方法与Job类关联。SimpleTrigger和CornTrigger是类;在2.+jar包中,JobDetail是个接口,SimpleTrigger和CornTrigger是接口。下面详细地分析它们的具体用法:
1. Job
Job是一个接口,只有一个void execute(JobExecutionContext jec)方法,JobExecutionContext提供了我们的任务调度上下文信息,比如,我们可以通过JobExecutionContext获取job相对应的JobDetail、Trigger等信息,我们在配置自己的内容时,需要实现此类,并在execute中重写我们的任务内容。下面是我们的扒取新闻工作实例:
public class pickNewsJob implements Job {
@Override
public void execute(JobExecutionContext jec) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
System.out.println("在"+sdf.format(new Date())+"扒取新闻");
}
}2. JobDetail
Quartz在每次执行任务时,都会创建一个Job实例,并为其配置上下文信息,jobDetail有一个成员属性JobDataMap,存放了我们Job运行时的具体信息,在后面我们会详细提到。
1. 在1.+版本中,它作为一个类,常用的构造方法有:JobDetail(String name, String group, Class jobClass),我们需要指定job的名称,组别和实现了Job接口的自定义任务类。实例如JobDetail jobDetail =new JobDetail("job1", "jgroup1", pickNewsJob.class);
2. 而在2.+版本中,我们则通过一下方法创建JobBuilder.newJob(自定义任务类).withIdentity(任务名称,组名).build();实例如JobDetail jobDetail = JobBuilder.newJob(pickNewsJob.class).withIdentity(“job1”,”group1”).build();`
3. Scheduler
先讲Scheduler,方便后讲解Trigger时测试。
Scheduler作为我们的“任务记录表”,里面(可以)配置大量的Trigger和JobDetail,两者在 Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler可以将Trigger绑定到某一JobDetail中,这样当Trigger触发时,对应的Job就被执行。一个Job可以对应多个Trigger,但一个Trigger只能对应一个Job。可以通过SchedulerFactory创建一个Scheduler实例。下面是使用Schduler的实例:
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
//将jobDetail和Trigger注册到一个scheduler里,建立起两者的关联关系
scheduler.scheduleJob(jobDetail,Trigger);
scheduler.start();//开始任务调度在一个scheduler被创建后,它处于”STAND-BY”模式,在触发任何job前需要使用它的start()方法来启动。同样的,如果我们想根据我们的业务逻辑来停止定时方案执行,可以使用scheduler.standby()方法
3. Trigger
Trigger描述了Job执行的时间触发规则,主要有SimpleTrigger和CronTrigger两个子类。
1. SimpleTrigger
如果嵌入事件机制只触发一次,或意图使Job以固定时间间隔触发,则使用SimpleTrigger较合适,它有多个构造函数,其中一个最复杂的构造函数为: SimpleTrigger(String name, String group, String jobName, String jobGroup, Date startTime, Date参数依次为触发器名称、触发器所在组名、工作名、工作所在组名、开始日期、结束日期、重复次数、重复间隔。
endTime, int repeatCount, long repeatInterval)
1. 如果我们不需同时设置这么多属性,可调用其他只有部分参数的构造方法,其他参数也可以通过set方法动态设置。
2. 这里需要注意的是,如果到了我们设置的endTime,即时重复次数repeatCount还没有达到我们预设置的次数。任务也不会再此执行。
下面是1.+版本的创建实例
//创建一个触发器,使任务从现在开始、每隔两秒执行一次,共执行10次
SimpleTrigger simpleTrigger = new SimpleTrigger("triiger1");//至少需要设置名字以标识当前触发器,否则在调用时会报错
simpleTrigger.setStartTime(new Date());
simpleTrigger.setRepeatInterval(2000);
simpleTrigger.setRepeatCount(10);下面是2.+版本的创建实例
SimpleTrigger simpleTrigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1")//配置触发器名称
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(10, 2))//配置重复次数和间隔时间
.startNow()//设置从当前开始
.build();//创建操作通过TriggerBuilder,我们可以通过方法方便地配置触发器的各种参数。
2. CronTrigger
通过Cron表达式定义复杂的时间调度方案,具体内容我们在下一篇详细提到
4. Calendar
在实际的开发中,我们可能需要根据节假日来调整我们的任务调度方案。实例如下:
//第一步:创建节假日类
// ②四一愚人节
Calendar foolDay = new GregorianCalendar(); //这里的Calendar是 java.util.Calendar。根据当前时间所在的默认时区创建一个“日子”
foolDay.add(Calendar.MONTH, 4);
foolDay.add(Calendar.DATE, 1);
// ③国庆节
Calendar nationalDay = new GregorianCalendar();
nationalDay.add(Calendar.MONTH, 10);
nationalDay.add(Calendar.DATE, 1);
//第二步:创建AnnualCalendar,它的作用是排除排除每一年中指定的一天或多天
AnnualCalendar holidays = new AnnualCalendar();
//设置排除日期有两种方法
// 第一种:排除的日期,如果设置为false则为包含(included)
holidays.setDayExcluded(foolDay, true);
holidays.setDayExcluded(nationalDay, true);
//第二种,创建一个数组。
ArrayList<Calendar> calendars = new ArrayList<Calendar>();
calendars.add(foolDay);
calendars.add(nationalDay);
holidays.setDaysExcluded(calendars);
//第三步:将holidays添加进我们的触发器
simpleTrigger.setCalendarName("holidays");
//第四步:设置好然后需要在我们的scheduler中注册
scheduler.addCalendar("holidays",holidays, false,false);,注意这里的第一个参数为calendarName,需要和触发器中添加的Calendar名字像对应。在这里,除了可以使用AnnualCalendar外,还有CronCalendar(表达式),DailyCalendar(指定的时间范围内的每一天),HolidayCalendar(排除节假日),MonthlyCalendar(排除月份中的数天),WeeklyCalendar(排除星期中的一天或多天)
至此,我们的核心类基本讲解完毕,下面附上我们的完整测试代码:
/*********************1.+版本*********************/
public class pickNewsJob implements Job {
@Override
public void execute(JobExecutionContext jec) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
System.out.println("在" + sdf.format(new Date()) + "扒取新闻");
}
public static void main(String args[]) throws SchedulerException {
JobDetail jobDetail =new JobDetail("job1", "jgroup1", pickNewsJob.class);
SimpleTrigger simpleTrigger = new SimpleTrigger("triiger1");
simpleTrigger.setStartTime(new Date());
simpleTrigger.setRepeatInterval(2000);
simpleTrigger.setRepeatCount(10);
simpleTrigger.setCalendarName("holidays");
//设置需排除的特殊假日
AnnualCalendar holidays = new AnnualCalendar();
// 四一愚人节
Calendar foolDay = new GregorianCalendar(); // 这里的Calendar是 ava.util.Calendar。根据当前时间所在的默认时区创建一个“日子”
foolDay.add(Calendar.MONTH, 4);
foolDay.add(Calendar.DATE, 1);
// 国庆节
Calendar nationalDay = new GregorianCalendar();
nationalDay.add(Calendar.MONTH, 10);
nationalDay.add(Calendar.DATE, 1);
//排除的日期,如果设置为false则为包含(included)
holidays.setDayExcluded(foolDay, true);
holidays.setDayExcluded(nationalDay, true);
/*方法2:通过数组设置
ArrayList<Calendar> calendars = new ArrayList<Calendar>();
calendars.add(foolDay);
calendars.add(nationalDay);
holidays.setDaysExcluded(calendars);*/
//创建scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
scheduler.addCalendar("holidays", holidays, false, false);
scheduler.scheduleJob(jobDetail, simpleTrigger);
scheduler.start();
}
}
/*******************2.+版本***************/
public class pickNewsJob implements Job {
@Override
public void execute(JobExecutionContext jec) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
System.out.println("在"+sdf.format(new Date())+"扒取新闻");
}
public static void main(String args[]) throws SchedulerException {
JobDetail jobDetail = JobBuilder.newJob(pickNewsJob.class)
.withIdentity("job1", "group1").build();
SimpleTrigger simpleTrigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1")
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(10, 2))
.startNow()
.build();
//设置需排除的特殊假日
AnnualCalendar holidays = new AnnualCalendar();
// 四一愚人节
Calendar foolDay = new GregorianCalendar(); // 这里的Calendar是 ava.util.Calendar。根据当前时间所在的默认时区创建一个“日子”
foolDay.add(Calendar.MONTH, 4);
foolDay.add(Calendar.DATE, 1);
// 国庆节
Calendar nationalDay = new GregorianCalendar();
nationalDay.add(Calendar.MONTH, 10);
nationalDay.add(Calendar.DATE, 1);
//排除的日期,如果设置为false则为包含(included)
holidays.setDayExcluded(foolDay, true);
holidays.setDayExcluded(nationalDay, true);
/*方法2:通过数组设置
ArrayList<Calendar> calendars = new ArrayList<Calendar>();
calendars.add(foolDay);
calendars.add(nationalDay);
holidays.setDaysExcluded(calendars);*/
//创建scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
scheduler.addCalendar("holidays", holidays, false, false);
scheduler.scheduleJob(jobDetail, simpleTrigger);
scheduler.start();//关闭调度器的时候调用 schedeler.shutdown(true)可见,两个不同版本的主要区别在于JobDetail和Triiger的配置。
此外,除了使用scheduler.scheduleJob(jobDetail, simpleTrigger)来建立jobDetail和simpleTrigger的关联外,在1.+版本中的配置还可以采用如下所示方式
simpleTrigger.setJobName("job1");//jobName和我们前面jobDetail的的名字一致
simpleTrigger.setJobGroup("jgroup1");//jobGroup和我们之前jobDetail的组名一致
scheduler.addJob(jobDetail, true);//注册jobDetail,此时jobDetail必须已指定job名和组名,否则会抛异常Trigger's related Job's name cannot be null
scheduler.scheduleJob(simpleTrigger);//注册triiger必须在注册jobDetail之后,否则会抛异常Trigger's related Job's name cannot be null这里还需要注意的是,如果我们使用scheduler.addCalendar("holidays", holidays, false, false)必须在向scheduler注册trigger之前scheduler.scheduleJob(simpleTrigger),否则会抛异常:Calendar not found: holidays
而在2.+版本中,我尝试在创建triiger时用forJob(“job1”, “jgroup1”)来绑定job名和组名
SimpleTrigger simpleTrigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1")
.forJob("job1", "jgroup1")//在这里绑定
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(10, 2))
.startNow()
.build();//后面是一样的
scheduler.addJob(jobDetail, true);
scheduler.scheduleJob(simpleTrigger);
在运行时,却会抛出异常: Jobs added with no trigger must be durable.
显然是绑定失败了,目前暂未找到解决方法,如果有找到解决方法的朋友,恳请告诉我一下,十分感谢!
第一部分的总结:
大概流程:
1.编写我们自己的定时任务类myJob实现job接口,并重写excute,这就是我们自己的任务
2.根据myjob创建jobDetail对象
3.创建时间出发规则对象:触发器Trigger,并指定触发任务的规则
4.创建调度器schedule,传入jobDetail和Trigger对象,启动调度器,即可按照指定的事件规则触发定时任务执行
核心概念:
Job有一个StatefulJob子接口,代表有状态的任务,该接口是一个没有方法的标签接口,其目的是让Quartz知道任务的类型,以便采用不同的执行方案,默认实现的job接口是无状态的任务,实现statefulJob接口的任务是有状态的任务
无状态任务在执行时拥有自己的JobDataMap拷贝,对JobDataMap的更改不会影响下次的执行。而有状态任务共享共享同一个JobDataMap实例,每次任务执行对JobDataMap所做的更改会保存下来,后面的执行可以看到这个更改,也即每次执行任务后都会对后面的执行发生影响。
正因为这个原因,无状态的Job可以并发执行,而有状态的StatefulJob不能并发执行,这意味着如果前次的StatefulJob还没有执行完毕,下一次的任务将阻塞等待,直到前次任务执行完毕。有状态任务比无状态任务需要考虑更多的因素,程序往往拥有更高的复杂度,因此除非必要,应该尽量使用无状态的Job。
如果Quartz使用了数据库持久化任务调度信息,无状态的JobDataMap仅会在Scheduler注册任务时保持一次,而有状态任务对应的JobDataMap在每次执行任务后都会进行保存。Trigger自身也可以拥有一个JobDataMap,其关联的Job可以通过JobExecutionContext.getTrigger().getJobDataMap()获取Trigger中的JobDataMap。不管是有状态还是无状态的任务,在任务执行期间对Trigger的JobDataMap所做的更改都不会进行持久,也即不会对下次的执行产生影响。
4. Calendar:org.quartz.Calendar和java.util.Calendar不同, 它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。 一个Trigger可以和多个Calendar关联, 以便排除或包含某些时间点;
假设,我们安排每周星期一早上10:00执行任务,但是如果碰到法定的节日,任务则不执行,这时就需要在Trigger触发机制的基础上使用Calendar进行定点排除。针对不同时间段类型,Quartz在org.quartz.impl.calendar包下提供了若干个Calendar的实现类,如AnnualCalendar、MonthlyCalendar、WeeklyCalendar分别针对每年、每月和每周进行定义;
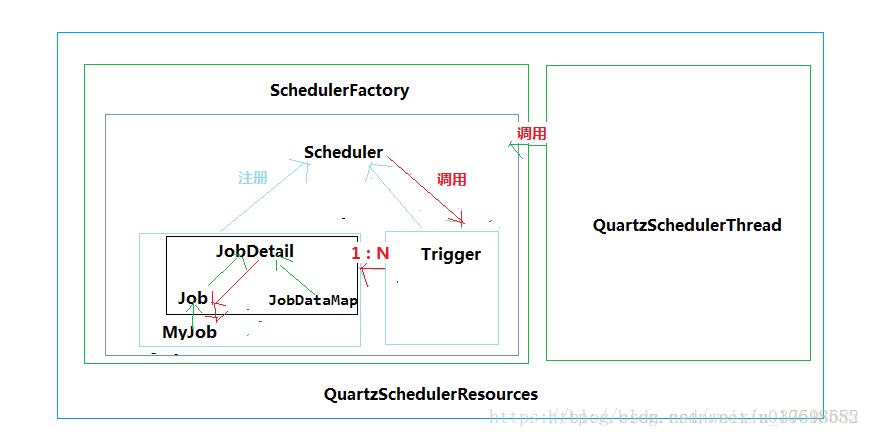
5. Scheduler: 代表一个Quartz的独立运行容器, Trigger和JobDetail可以注册到Scheduler中, 两者在Scheduler中拥有各自的组及名称, 组及名称是Scheduler查找定位容器中某一对象的依据, Trigger的组及名称必须唯一, JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义了多个接口方法, 允许外部通过组及名称访问和控制容器中Trigger和JobDetail;
Scheduler可以将Trigger绑定到某一JobDetail中, 这样当Trigger触发时, 对应的Job就被执行。一个Job可以对应多个Trigger, 但一个Trigger只能对应一个Job。可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内的信息。SchedulerContext内部通过一个Map,以键值对的方式维护这些上下文数据,SchedulerContext为保存和获取数据提供了多个put()和getXxx()的方法。可以通过Scheduler. getContext()获取对应的SchedulerContext实例;
6. ThreadPool: Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。
实现原理:
原理图:
内存存储RAMJobStore
Quartz默认使用RAMJobStore,它的优点是速度。因为所有的 Scheduler 信息都保存在计算机内存中,访问这些数据随着电脑而变快。而无须访问数据库或IO等操作,但它的缺点是将 Job 和 Trigger 信息存储在内存中的。因而我们每次重启程序,Scheduler 的状态,包括 Job 和 Trigger 信息都丢失了。
Quartz 的内存 Job 存储的能力是由一个叫做 org.quartz.simple.RAMJobStore 类提供。在我们的quartz-2.x.x.jar包下的org.quartz包下即存储了我们的默认配置quartz.properties。打开这个配置文件,我们会看到如下信息
# Default Properties file for use by StdSchedulerFactory
# to create a Quartz Scheduler Instance, if a different
# properties file is not explicitly specified.
#
org.quartz.scheduler.instanceName: DefaultQuartzScheduler
org.quartz.scheduler.rmi.export: false
org.quartz.scheduler.rmi.proxy: false
org.quartz.scheduler.wrapJobExecutionInUserTransaction: false
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount: 10
org.quartz.threadPool.threadPriority: 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
org.quartz.jobStore.misfireThreshold: 60000
org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore #这里默认使用RAMJobStore持久性JobStore
Quartz 提供了两种类型的持久性 JobStore,为JobStoreTX和JobStoreCMT,其中:
1. JobStoreTX为独立环境中的持久性存储,它设计为用于独立环境中。这里的 “独立”,我们是指这样一个环境,在其中不存在与应用容器的事物集成。这里并不意味着你不能在一个容器中使用 JobStoreTX,只不过,它不是设计来让它的事特受容器管理。区别就在于 Quartz 的事物是否要参与到容器的事物中去。
2. JobStoreCMT 为程序容器中的持久性存储,它设计为当你想要程序容器来为你的 JobStore 管理事物时,并且那些事物要参与到容器管理的事物边界时使用。它的名字明显是来源于容器管理的事物(Container Managed Transactions (CMT))。
持久化配置步骤
要将JobDetail等信息持久化我们的数据库中,我们可按一下步骤操作:
1. 配置数据库
在 /docs/dbTables 目录下存放了几乎所有数据库的的SQL脚本,这里的 是解压 Quartz 分发包后的目录。我们使用常用mysql数据库,下面是示例sql脚本代码
#
# Quartz seems to work best with the driver mm.mysql-2.0.7-bin.jar
#
# PLEASE consider using mysql with innodb tables to avoid locking issues
#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS
(
SCHED_NAME VARCHAR(80) NOT NULL,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_GROUP VARCHAR(100) NOT NULL,
DESCRIPTION VARCHAR(100) NULL,
JOB_CLASS_NAME VARCHAR(100) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_TRIGGERS
(
SCHED_NAME VARCHAR(80) NOT NULL,
TRIGGER_NAME VARCHAR(100) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_GROUP VARCHAR(100) NOT NULL,
DESCRIPTION VARCHAR(100) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(100) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_SIMPLE_TRIGGERS
(
SCHED_NAME VARCHAR(80) NOT NULL,
TRIGGER_NAME VARCHAR(100) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CRON_TRIGGERS
(
SCHED_NAME VARCHAR(80) NOT NULL,
TRIGGER_NAME VARCHAR(100) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
CRON_EXPRESSION VARCHAR(100) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(80) NOT NULL,
TRIGGER_NAME VARCHAR(100) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
STR_PROP_1 VARCHAR(120) NULL,
STR_PROP_2 VARCHAR(120) NULL,
STR_PROP_3 VARCHAR(120) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_BLOB_TRIGGERS
(
SCHED_NAME VARCHAR(80) NOT NULL,
TRIGGER_NAME VARCHAR(100) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CALENDARS
(
SCHED_NAME VARCHAR(80) NOT NULL,
CALENDAR_NAME VARCHAR(100) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
);
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS
(
SCHED_NAME VARCHAR(80) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_FIRED_TRIGGERS
(
SCHED_NAME VARCHAR(80) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(100) NOT NULL,
TRIGGER_GROUP VARCHAR(100) NOT NULL,
INSTANCE_NAME VARCHAR(100) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(100) NULL,
JOB_GROUP VARCHAR(100) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID)
);
CREATE TABLE QRTZ_SCHEDULER_STATE
(
SCHED_NAME VARCHAR(80) NOT NULL,
INSTANCE_NAME VARCHAR(100) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
);
CREATE TABLE QRTZ_LOCKS
(
SCHED_NAME VARCHAR(80) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME)
);
commit;其中各表的含义如下所示:
| 表名 | 描述 |
|---|---|
| QRTZ_CALENDARS | 以 Blob 类型存储 Quartz 的 Calendar 信息 |
| QRTZ_CRON_TRIGGERS | 存储 Cron Trigger,包括 Cron 表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的 Trigger 相关的状态信息,以及相联 Job 的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的 Trigger 组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler 实例(假如是用于一个集群中) |
| QRTZ_LOCKS | 存储程序的非观锁的信息(假如使用了悲观锁) |
| QRTZ_JOB_DETAILS | 存储每一个已配置的 Job 的详细信息 |
| QRTZ_JOB_LISTENERS | 存储有关已配置的 JobListener 的信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| QRTZ_BLOG_TRIGGERS Trigger | 作为 Blob 类型存储(用于 Quartz 用户用 JDBC 创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候) |
| QRTZ_TRIGGER_LISTENERS | 存储已配置的 TriggerListener 的信息 |
| QRTZ_TRIGGERS | 存储已配置的 Trigger 的信息 |
2. 使用JobStoreTX
- 首先,我们需要在我们的属性文件中表明使用JobStoreTX:
org.quartz.jobStore.class = org.quartz.ompl.jdbcjobstore.JobStoreTX - 然后我们需要配置能理解不同数据库系统中某一特定方言的驱动代理:
| 数据库平台 | Quartz 代理类 |
|---|---|
| Cloudscape/Derby | org.quartz.impl.jdbcjobstore.CloudscapeDelegate |
| DB2 (version 6.x) | org.quartz.impl.jdbcjobstore.DB2v6Delegate |
| DB2 (version 7.x) | org.quartz.impl.jdbcjobstore.DB2v7Delegate |
| DB2 (version 8.x) | org.quartz.impl.jdbcjobstore.DB2v8Delegate |
| HSQLDB | org.quartz.impl.jdbcjobstore.PostgreSQLDelegate |
| MS SQL Server | org.quartz.impl.jdbcjobstore.MSSQLDelegate |
| Pointbase | org.quartz.impl.jdbcjobstore.PointbaseDelegate |
| PostgreSQL | org.quartz.impl.jdbcjobstore.PostgreSQLDelegate |
| (WebLogic JDBC Driver) | org.quartz.impl.jdbcjobstore.WebLogicDelegate |
| (WebLogic 8.1 with Oracle) | org.quartz.impl.jdbcjobstore.oracle.weblogic.WebLogicOracleDelegate |
| Oracle | org.quartz.impl.jdbcjobstore.oracle.OracleDelegate |
如果我们的数据库平台没在上面列出,那么最好的选择就是,直接使用标准的 JDBC 代理 org.quartz.impl.jdbcjobstore.StdDriverDelegate 就能正常的工作。
- 以下是一些相关常用的配置属性及其说明:
| 属性 | 默认值 | 描述 |
|---|---|---|
| org.quartz.jobStore.dataSource | 无 | 用于 quartz.properties 中数据源的名称 |
| org.quartz.jobStore.tablePrefix | QRTZ_ | 指定用于 Scheduler 的一套数据库表名的前缀。假如有不同的前缀,Scheduler 就能在同一数据库中使用不同的表。 |
| org.quartz.jobStore.userProperties | False | “use properties” 标记指示着持久性 JobStore 所有在 JobDataMap 中的值都是字符串,因此能以 名-值 对的形式存储,而不用让更复杂的对象以序列化的形式存入 BLOB 列中。这样会更方便,因为让你避免了发生于序列化你的非字符串的类到 BLOB 时的有关类版本的问题。 |
| org.quartz.jobStore.misfireThreshold | 60000 | 在 Trigger 被认为是错过触发之前,Scheduler 还容许 Trigger 通过它的下次触发时间的毫秒数。默认值(假如你未在配置中存在这一属性条目) 是 60000(60 秒)。这个不仅限于 JDBC-JobStore;它也可作为 RAMJobStore 的参数 |
| org.quartz.jobStore.isClustered | False | 设置为 true 打开集群特性。如果你有多个 Quartz 实例在用同一套数据库时,这个属性就必须设置为 true。 |
| org.quartz.jobStore.clusterCheckinInterval | 15000 | 设置一个频度(毫秒),用于实例报告给集群中的其他实例。这会影响到侦测失败实例的敏捷度。它只用于设置了 isClustered 为 true 的时候。 |
| org.quartz.jobStore.maxMisfiresToHandleAtATime | 20 | 这是 JobStore 能处理的错过触发的 Trigger 的最大数量。处理太多(超过两打) 很快会导致数据库表被锁定够长的时间,这样就妨碍了触发别的(还未错过触发) trigger 执行的性能。 |
| org.quartz.jobStore.dontSetAutoCommitFalse | False | 设置这个参数为 true 会告诉 Quartz 从数据源获取的连接后不要调用它的 setAutoCommit(false) 方法。这在少些情况下是有帮助的,比如假如你有这样一个驱动,它会抱怨本来就是关闭的又来调用这个方法。这个属性默认值是 false,因为大多数的驱动都要求调用 setAutoCommit(false)。 |
| org.quartz.jobStore.selectWithLockSQL | SELECT * FROM {0}LOCKS WHERE LOCK_NAME = ? FOR UPDATE | 这必须是一个从 LOCKS 表查询一行并对这行记录加锁的 SQL 语句。假如未设置,默认值就是 SELECT * FROM {0}LOCKS WHERE LOCK_NAME = ? FOR UPDATE,这能在大部分数据库上工作。{0} 会在运行期间被前面你配置的 TABLE_PREFIX 所替换。 |
| org.quartz.jobStore.txIsolationLevelSerializable | False | 值为 true 时告知 Quartz(当使用 JobStoreTX 或 CMT) 调用 JDBC 连接的 setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE) 方法。这有助于阻止某些数据库在高负载和长时间事物时锁的超时。 |
4. 我们还需要配置Datasource 属性
| 属性 | 必须 | 说明 |
|---|---|---|
| org.quartz.dataSource.NAME.driver | 是 | JDBC 驱动类的全限名 |
| org.quartz.dataSource.NAME.URL | 是 | 连接到你的数据库的 URL(主机,端口等) |
| org.quartz.dataSource.NAME.user | 否 | 用于连接你的数据库的用户名 |
| org.quartz.dataSource.NAME.password | 否 | 用于连接你的数据库的密码 |
| org.quartz.dataSource.NAME.maxConnections | 否 | DataSource 在连接接中创建的最大连接数 |
| org.quartz.dataSource.NAME.validationQuary | 否 | 一个可选的 SQL 查询字串,DataSource 用它来侦测并替换失败/断开的连接。例如,Oracle 用户可选用 select table_name from user_tables,这个查询应当永远不会失败,除非直的就是连接不上了。 |
下面是我们的一个quartz.properties属性文件配置实例:
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.threadPool.threadCount = 3
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.dataSource = myDS
org.quartz.dataSource.myDS.driver = com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL = jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8
org.quartz.dataSource.myDS.user = root
org.quartz.dataSource.myDS.password = root
org.quartz.dataSource.myDS.maxConnections =5配置好quartz.properties属性文件后,我们只要**将它放在类路径下,然后运行我们的程序,即可覆盖在quartz.jar包中默认的配置文件
3. 测试
编写我们的测试文件,我们的测试环境是在quartz-2.2.2版本下进行的。下面的测试用例引用了上篇文章 ,关于Quartz的快速入门配置可移步参考这篇文章。
public class pickNewsJob implements Job {
@Override
public void execute(JobExecutionContext jec) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
System.out.println("在"+sdf.format(new Date())+"扒取新闻");
}
public static void main(String args[]) throws SchedulerException {
JobDetail jobDetail = JobBuilder.newJob(pickNewsJob.class)
.withIdentity("job1", "jgroup1").build();
SimpleTrigger simpleTrigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1")
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(10, 2))
.startNow()
.build();
//创建scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
scheduler.scheduleJob(jobDetail, simpleTrigger);
scheduler.start();
}
}执行测试方法,能看到控制台打印如下日志信息,关注红色部分,更注意其中的粗体部分,是我们quartz调用数据库的一些信息:
INFO : org.quartz.core.SchedulerSignalerImpl - Initialized Scheduler Signaller of type: class org.quartz.core.SchedulerSignalerImpl
INFO : org.quartz.core.QuartzScheduler - Quartz Scheduler v.2.2.2 created.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Using thread monitor-based data access locking (synchronization).
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - JobStoreTX initialized.
INFO : org.quartz.core.QuartzScheduler - Scheduler meta-data: Quartz Scheduler (v2.2.2) ‘MyScheduler’ with instanceId ‘NON_CLUSTERED’
Scheduler class: ‘org.quartz.core.QuartzScheduler’ - running locally.
NOT STARTED.
Currently in standby mode.
Number of jobs executed: 0
Using thread pool ‘org.quartz.simpl.SimpleThreadPool’ - with 3 threads.
Using job-store ‘org.quartz.impl.jdbcjobstore.JobStoreTX’ - which supports persistence. and is not clustered.
INFO : org.quartz.impl.StdSchedulerFactory - Quartz scheduler ‘MyScheduler’ initialized from default resource file in Quartz package: ‘quartz.properties’
INFO : org.quartz.impl.StdSchedulerFactory - Quartz scheduler version: 2.2.2
INFO : com.mchange.v2.c3p0.impl.AbstractPoolBackedDataSource - Initializing c3p0 pool…com.mchange.v2.c3p0.ComboPooledDataSource [ acquireIncrement -> 3, acquireRetryAttempts -> 30, acquireRetryDelay -> 1000, autoCommitOnClose -> false, automaticTestTable -> null, breakAfterAcquireFailure -> false, checkoutTimeout -> 0, connectionCustomizerClassName -> null, connectionTesterClassName -> com.mchange.v2.c3p0.impl.DefaultConnectionTester, dataSourceName -> z8kfsx9f1dp34iubvoy4d|7662953a, debugUnreturnedConnectionStackTraces -> false, description -> null, driverClass -> com.mysql.jdbc.Driver, factoryClassLocation -> null, forceIgnoreUnresolvedTransactions -> false, identityToken -> z8kfsx9f1dp34iubvoy4d|7662953a, idleConnectionTestPeriod -> 0, initialPoolSize -> 3, jdbcUrl -> jdbc:mysql://localhost:3306/quartz?characterEncoding=utf-8,lastAcquisitionFailureDefaultUser -> null, maxAdministrativeTaskTime -> 0, maxConnectionAge -> 0, maxIdleTime -> 0, maxIdleTimeExcessConnections -> 0, maxPoolSize -> 5, maxStatements -> 0, maxStatementsPerConnection -> 120, minPoolSize -> 1, numHelperThreads -> 3, numThreadsAwaitingCheckoutDefaultUser -> 0, preferredTestQuery -> null, properties ->{user=******, password=******}, propertyCycle -> 0, testConnectionOnCheckin -> false, testConnectionOnCheckout -> false, unreturnedConnectionTimeout -> 0, usesTraditionalReflectiveProxies -> false ]
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Freed 0 triggers from ‘acquired’ / ‘blocked’ state.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Recovering 0 jobs that were in-progress at the time of the last shut-down.这里代表在我们任务开始时,先从数据库查询旧记录,这些旧记录是之前由于程序中断等原因未能正常执行的,于是先Recovery回来并执行
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Recovery complete.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Removed 0 ‘complete’ triggers.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Removed 0 stale fired job entries.
INFO : org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED started.
在21:28:12扒取新闻
在21:28:13扒取新闻
在21:28:15扒取新闻
在21:28:17扒取新闻
….
4. 拓展测试
我们再次运行测试方法,然后马上中断程序,查询我们数据库,会看到如下内容:
SELECT * FROM QRTZ_SIMPLE_TRIGGERS;
+————-+————–+—————+————–+—————–+—————–+
| SCHED_NAME | TRIGGER_NAME | TRIGGER_GROUP | REPEAT_COUNT | REPEAT_INTERVAL | TIMES_TRIGGERED |
+————-+————–+—————+————–+—————–+—————–+
| MyScheduler | trigger1 | DEFAULT | 9 | 2000 | 1 |
+————-+————–+—————+————–+—————–+—————–+
1 row in set (0.00 sec)
然后我们再运行程序,发现报错了。
org.quartz.ObjectAlreadyExistsException: Unable to store Job : ‘jgroup1.job1’, because one already exists with this identification.
一般的,在我们的任务调度前,会先将相关的任务持久化到数据库中,然后调用完在删除记录,这里在程序开始试图将任务信息持久化到数据库时,显然和(因为我们之前中断操作导致)数据库中存在的记录起了冲突。
5. 恢复异常中断的任务
这个时候,我们可以选择修改我们的job名和组名和triiger名,然后再运行我们的程序。查看控制台打印的信息部分展示如下:
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Freed 1 triggers from ‘acquired’ / ‘blocked’ state.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Handling 1 trigger(s) that missed their scheduled fire-time.这里我们开始处理上一次异常未完成的存储在数据库中的任务记录
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Recovering 0 jobs that were in-progress at the time of the last shut-down.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Recovery complete.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Removed 0 ‘complete’ triggers.
INFO : org.quartz.impl.jdbcjobstore.JobStoreTX - Removed 1 stale fired job entries.
INFO : org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED started.
在21:42:13扒取新闻
在21:42:13扒取新闻
在21:42:14扒取新闻
在21:42:15扒取新闻
在21:42:16扒取新闻
在21:42:17扒取新闻
在21:42:18扒取新闻
在21:42:19扒取新闻
在21:42:20扒取新闻
在21:42:21扒取新闻
在21:42:22扒取新闻
在21:42:23扒取新闻
在21:42:24扒取新闻
在21:42:25扒取新闻
在21:42:26扒取新闻
在21:42:27扒取新闻
在21:42:28扒取新闻
在21:42:29扒取新闻
在21:42:30扒取新闻
我们会发现,“扒取新闻”一句的信息打印次数超过十次,但我们在任务调度中设置了打印十次,说明它恢复了上次的任务调度。
而如果我们不想执行新的任务,只想纯粹地恢复之前异常中断任务,我们可以采用如下方法:
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
// ①获取调度器中所有的触发器组
List<String> triggerGroups = scheduler.getTriggerGroupNames();
// ②重新恢复在tgroup1组中,名为trigger1触发器的运行
for (int i = 0; i < triggerGroups.size(); i++) {//这里使用了两次遍历,针对每一组触发器里的每一个触发器名,和每一个触发组名进行逐次匹配
List<String> triggers = scheduler.getTriggerGroupNames();
for (int j = 0; j < triggers.size(); j++) {
Trigger tg = scheduler.getTrigger(new TriggerKey(triggers
.get(j), triggerGroups.get(i)));
// ②-1:根据名称判断
if (tg instanceof SimpleTrigger
&& tg.getDescription().equals("jgroup1.DEFAULT")) {//由于我们之前测试没有设置触发器所在组,所以默认为DEFAULT
// ②-1:恢复运行
scheduler.resumeJob(new JobKey(triggers.get(j),
triggerGroups.get(i)));
}
}
}
scheduler.start();
}Quartz任务调度(3)CronTrigger定制个性化调度方案
Cron表达式
1. 时间字段与基本格式
Cron表达式有6或7个空格分割的时间字段组成:
| 位置 | 时间域名 | 允许值 | 允许的特殊字符 |
|---|---|---|---|
| 1 | 秒 | 0-59 | ,-*/ |
| 2 | 分支 | 0-59 | ,-*?/ |
| 3 | 小时 | 0-23 | ,-*/ |
| 4 | 日期 | 1-31 | ,-*/LWC |
| 5 | 月份 | 1-12或 JAN-DEC | ,-*/ |
| 6 | 星期 | 1-7 或 SUN-SAT | ,-*?/LC# |
| 7 | 年(可选) | 1970-2099 | ,-*/ |
在月份和星期中,我们也可以使用英文单词的缩写形式
2. 特殊字符
在Cron表达式的时间字段中,除允许设置数值外,还能你使用一些特殊的字符,提供列表、范围、通配符等功能
1. 星号(*)
可用在所有字段下,表示对应时间域名的每一个时刻,如*用在分钟字段,表示“每分钟”。
2. 问号(?)
只能用在日期和星期字段,代表无意义的值,比如使用L设定为当月的最后一天,则配置日期配置就没有意义了,可用?作占位符的作用。
3. 减号(-)
表示一个范围,如在日期字段5-10,表示从五号到10号,相当于使用逗号的5,6,7,8,9,10
4. 逗号(,)
表示一个并列有效值,比如在月份字段使用JAN,DEC表示1月和12月
5. 斜杠(/)
x/y表示一个等步长序列,x为起始值,y为增量步长值,如在小时使用1/3相当于1,4,7,10当时用*/y时,相当于0/y
6. L
L(Last)只能在日期和星期字段使用,但意思不同。在日期字段,表示当月最后一天,在星期字段,表示星期六(如果按星期天为一星期的第一天的概念,星期六就是最后一天。如果L在星期字段,且前面有一个整数值X,表示“这个月的最后一个星期X”,比如3L表示某个月的最后一个星期二
7. W
选择离给定日期最近的工作日(周一至周五)。例如你指定“15W”作为day of month字段的值,就意味着“每个月与15号最近的工作日”。所以,如果15号是周六,则触发器会在14号(周五)触发。如果15号是周日,则触发器会在16号(周一)触发。如果15号是周二,则触发器会在15号(周二)触发。但是,如果你指定“1W”作为day of month字段的值,且1号是周六,则触发器会在3号(周一)触发。quartz不会“跳出”月份的界限。
8. LW组合
在日期字段可以组合使用LW,表示当月最后一个工作日(周一至周五)
9. 井号(#)
只能在星期字段中使用指定每月第几个星期X。例如day of week字段的“6#3”,就意味着“每月第3个星期五”(day3=星期五,#3=第三个);“2#1”就意味着“每月第1个星期一”;“4#5”就意味着“每月第5个星期3。需要注意的是“#5”,如果在当月没有第5个星期三,则触发器不会触发。
10. C
只能在日期和星期字段中使用,表示计划所关联的诶其,如果日期没有被关联,相当于日历中的所有日期,如5C在日期字段相当于5号之后的第一天,1C在日期字段使用相当于星期填后的第一天
3. 一些实例
Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。如MON和mon是一样的
| cron表达式 | 含义 |
|---|---|
| 0 0 12 * * ? | 每天12点整触发一次 |
| 0 15 10 ? * * | 每天10点15分触发一次 |
| 0 15 10 * * ? | 每天10点15分触发一次 |
| 0 15 10 * * ? * | 每天10点15分触发一次 |
| 0 15 10 * * ? 2005 | 2005年内每天10点15分触发一次 |
| 0 * 14 * * ? | 每天的2点整至2点59分,每分钟触发一次 |
| 0 0/5 14 * * ? | 每天的2点整至2点55分,每5分钟触发一次 |
| 0 0/5 14,18 * * ? | 每天的2点整至2点55分以及18点整至18点55分,每5分钟触发一次 |
| 0 0-5 14 * * ? | 每天的2点整至2点5分,每分钟触发一次 |
| 0 10,44 14 ? 3 WED | 每年3月的每个星期三的2点10分以及2点44分触发一次 |
| 0 15 10 ? * MON-FRI | 每月周一、周二、周三、周四、周五的10点15分触发一次 |
| 0 15 10 15 * ? | 每月15的10点15分触发一次 |
| 0 15 10 L * ? | 每月最后一天的10点15分触发一次 |
| 0 15 10 ? * 6L | 每月最后一个周五的10点15分触发一次 |
| 0 15 10 ? * 6L | 每月最后一个周五的10点15分触发一次 |
| 0 15 10 ? * 6L 2002-2005 | 2002年至2005年间,每月最后一个周五的10点15分触发一次 |
| 0 15 10 ? * 6#3 | 每月第三个周五的10点15触发一次 |
| 0 0 12 1/5 * ? | 每月1号开始,每5天的12点整触发一次 |
| 0 11 11 11 11 ? | 每年11月11日11点11分触发一次 |
使用示例
在quartz1.+版本中,我们通过如下方法创建CronTrigger
//定义调度触发规则,每天上午10:15执行
CronTrigger cornTrigger=new CronTrigger("cronTrigger","triggerGroup");
//执行规则表达式
cornTrigger.setCronExpression("0 15 10 * * ? *");而在2.+版本中,则通过如下方式创建
//使用cornTrigger规则 每天10点42分
Trigger trigger=TriggerBuilder.newTrigger().withIdentity("simpleTrigger", "triggerGroup")
.withSchedule(CronScheduleBuilder.cronSchedule("0 42 10 * * ? *"))
.startNow().build();