当我们的程序一运行时,操作系统会为该程序分配相应的内存空间。但是我们的内存空间是有限的,且我们的程序在运行过程中不断产生数据,如果没有清除掉没用的数据,就有可能导致内存不够,最终发生内存溢出异常。 所以JVM提供了垃圾回收机制(GC),使运行在JVM上的程序将由JVM回收程序运行过程中产生的垃圾(不再使用的数据)。在面向对象的程序中内存的释放意味着对象的销毁,那JVM销毁哪些对象、并且又是如何销毁的呢?这就是下面要讲的内容。
一、如何判断哪些对象需要回收?
1. 引用计数法(JVM的实现一般不采用):
当一个对象没有任何引用时,该对象就无法被使用,也就是需要释放的垃圾。引用计数法就是在对象中记录该对象的引用值,当有地方引用到这个对象时,引用值就+1,当引用失效的时候,引用值就-1。当引用值变为0时,就会被回收。
// 此时p指向新new出来的对象(记为A),所以A的引用值为1,不是垃圾 Person p = new Person(); // 此时p对A的引用失效,所以A的引用值为0,是垃圾 p = null;
优点:
1. 实现简单,判定效率高。 1. 回收没有延迟性, 垃圾产生的同时就被立刻回收了。
缺点:
1. 每次对对象赋值时都需要维护引用计数器,需要额外的开销。 2. 无法回收循环引用的对象。因为循环引用的对象计数器值都是1,不能被判定为垃圾,也就无法一起回收。
循环引用:当存在两个对象(A,B),A和B中均存在一个属性指向对方,此时它们的引用计数器值都是1,但是我们却没办法使用它们,也就是实际是它们也是垃圾。
2. 可达性分析法:
通过一系列被称为GC Roots的根对象作为起始节点集,从这些节点开始,通过引用关系向下搜寻,搜寻走过的路径称为”引用链“,如果某个对象到GC Roots没有任何引用链相连,就说明该对象不可达,即可以被回收。
什么对象可作为GC Roots? ● 局部变量所引用的对象; ● 方法区中类静态属性引用的对象; ● 方法区中常量引用的对象; ● 本地方法栈中JNI(Native方法)引用的对象。
优点:
1. 可以解决引用计数器所不能解决的循环引用问题。
缺点:
1. 在进行可达性分析时,必须停止所有 Java 执行线程(也称"Stop The World")。因为是在标记阶段进行可达性分析时,如果分析过程中对象引用关系还在不断变化的情况,可能造成可达性分析结果不准确。
二、常见的垃圾回收算法
1. 标记-清除算法:
概述:顾名思义,该算法分为标记和清除两个阶段:
1. 标记阶段:使用可达性分析法,遍历所有GCRoot对象,标记所有可达对象。
-
清除阶段:遍历堆内存,清除所有没被标记的对象。
优点:算法简单,容易实现
缺点:
-
时间/效率上:
标记和清除这两个阶段都需要遍历内存中的所有对象,很多时候内存中的对象数量是非常庞大的,因而效率不高,而且 GC 时需要停止应用程序。应用程序会出现卡顿,使用户体验较差。
-
空间上:
产生了很多不连续的内存,使得内存碎片化,如果后续创建较大对象时,需要使用到一块连续的较大内存,可能会找不到,从而反复触发GC,甚至OOM。
2. 复制算法:
概述:将堆内存划分为两部分,每次只使用其中一部分,触发GC时,将该部分中不需要回收的对象复制到另外一片内存,然后在整个清除掉上一个内存半区。复制算法适合回收率高的区域 (如果回收率不高的话,就会有大量的对象需要频繁复制)。如 : 在年轻代 的 Survivor 中 , 使用的就是复制算法的垃圾回收机制
优点 :
-
算法简单;
-
解决了内存碎片问题 ;
缺点 :
-
只能使用 一半内存 ;
3. 标记-整理算法:
概述:标记-整理算法与标记-清除算法很像,事实上,标记-整理算法的标记过程仍然与标记-清除算法一样,但后续步骤不是直接对可回收对象进行回收,而是让所有存活的对象都向一端移动,然后直接清理掉端边线以外的内存。
优点:
-
标记-整理算法弥补了标记-清除算法存在内存碎片的问题;
-
消除了复制算法内存减半的高额代价;
缺点:
-
不仅要标记存活对象,还要整理所有存活对象的引用地址,在效率上不如复制算法。
4.分代回收算法:(重点)
在Java中每个对象的存活时间都不一样,可以分为两类:
1. 存活时间较短的对象:更有可能成为垃圾被回收,对象较少; 1. 存活时间较长的对象:需要相对较少的回收,但是对象较多;
因而,对于不同特征的对象,我们需要采取不同的算法对其进行回收。所以按对象的存活周期不同将内存划分为以下几块,这样就可以根据各个年代的特点采用最合适的收集算法。
1. 新生代:存活时间较短的对象,采用复制算法来收集;
-
新生代又分为Eden区和Survivor区(Survivor from、Survivor to),大小比例默认为8:1:1。
-
老年代:存活时间较长的对象,采用标记/清除算法或者标记/整理算法收集;
-
永久代(JDK6、JDK7):是 HotSpot 特有的实现,其他的虚拟机实现没有这一概念,永久代的收集效果很差,一般很少对永久代进行垃圾回收;
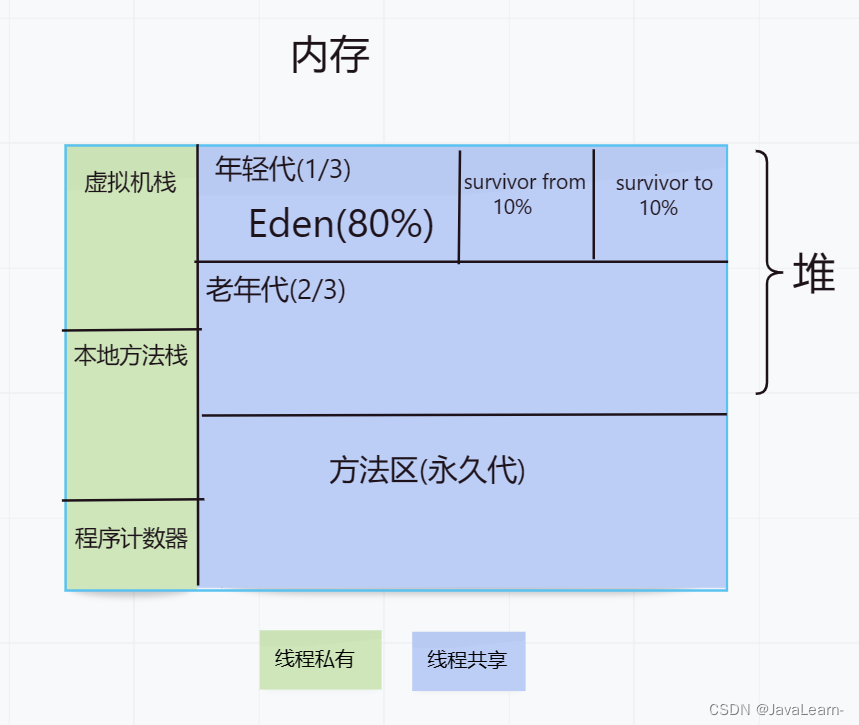
新创建的对象先存进Eden区(大对象除外),当Eden区满了之后再使用Survivor from,当Survivor from 也满了之后就进行Minor GC(新生代GC),使用复制算法将Eden和Survivor from中存活的对象复制进入Survivor to,然后清空Eden和Survivor from,同时将存活对象的age+1。这个时候原来的Survivor from成了新的Survivor to,原来的Survivor to成了新的Survivor from。
复制的时候,如果Survivor to 无法容纳全部存活的对象,就将无法容纳的对象放置在老年代中,如果老年代也无法容纳,则进行Full GC(整个堆的内存,包含老年代,新生代)。
大对象直接可以直接进入老年代:JVM中有个参数配置-XX:PretenureSizeThreshold,令大于这个设置值的对象直接进入老年代,目的是为了避免在Eden和Survivor区之间发生大量的内存复制。
长期存活的对象进入老年代:JVM给每个对象定义一个对象年龄计数器,如果对象在Eden出生并经过第一次Minor GC后仍然存活,并且能被Survivor容纳,将被移入Survivor to并且年龄设定为1。每熬过一次Minor GC,年龄就加1,当他的年龄到一定程度(默认为15岁,可以通过-XX:MaxTenuringThreshold来设定),就会移入老年代。但是JVM并不是永远要求年龄必须达到最大年龄才会晋升老年代,如果Survivor 空间中相同年龄(如年龄为x)所有对象大小的总和大于Survivor的一半,年龄大于等于x的所有对象直接进入老年代,无需等到最大年龄要求。
三、常见的垃圾收集器
-
Serial:最早的单线程串行垃圾回收器,用于回收年轻代。
-
Serial Old:Serial 垃圾回收器的老年版本,同样也是单线程的,可以作为 CMS 垃圾回收器的备选预 案,用于回收老年代。
-
ParNew:是 Serial 的多线程版本,用于回收年轻代。
-
Parallel :多线程垃圾回收器,使用的是复制的内存回收算法。是吞吐量优先的收集器,可以牺牲等待时间换取系统的吞吐量。
-
Parallel Old 是 Parallel 老生代版本,使用的是标记-整理的内存回收算法。
-
CMS:使用的是标记-清除的算法实现的,所以在 gc 的时候会产生大量的内存碎片,当剩余内存不能满足程序运行要求时,系统将会出现 Concurrent Mode Failure,临时 CMS 会采用 Serial Old 回收器进行 垃圾清除,此时的性能将会被降低。它是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器,用于回收老年代。
-
G1:一种兼顾吞吐量和停顿时间的 GC 实现,是 JDK 9 以后的默认 GC 选项,是整堆回收器。