一、前言

GaussDB 是华为2023年6月7日发布新一代分布式数据库,采用share-nothing架构,数据自动分片,通过GTM-Lite技术实现事务强一致,无中心节点性能瓶颈,是华为基于openGauss自主创新研发的一款分布式关系型数据库,它也被称为全球首个人工智能原生(AI-Native)数据库。该产品支持分布式事务,同城跨AZ部署,数据0丢失,支持1000+节点的扩展能力,PB级海 量存储。同时拥有云上高可用,高可靠,高安全,弹性伸缩,一键部署,快速备份恢复,监控告警等关键能力,能为企业提供功能全面,稳定可靠,扩展性强,性能优越的企业级数据库服务。GaussDB实例的默认端口为8000;更多参看产品官网、产品文档;其中,GaussDB为华为的商用云原生数据库(没有开源),OpenGaussDB是在2019年9 月 19 日华为宣布将开源其 GaussDB 数据库,开源后的产品被命名为 openGauss,2020年6月30日最终正式开源发布,10月12日发布第一个正式公开版本——openGauss 1.0.1版本,满足企业级用户对数据库的高性能、高可用、高安全要求,与鲲鹏协同性能优化上,基于2路鲲鹏服务器,1000wh数据量可跑到150万tmpC,相对业界主流产品的性能超过50%,在主备模式下60%满负载故障切换时间10秒以内。openGauss内核源自PostgreSQL,opengauss支持单机和一主多备部署方式,但不支持分布式集群部署;另外提一嘴, 我们还有一款国产数据库TiDB;

GSDB可用于多种场景,目前,GaussDB已在华为内部IT系统和多个行业核心业务系统得到应用。未来,GaussDB将深耕金融场景,并从金融行业走向其他对数据库有高要求的行业。

产品优势:
❥ 高安全:GaussDB拥有TOP级的商业数据库安全特性:数据动态脱敏,TDE透明加密,行级访问控制,密态计算,数据库审计,加密认证。能够满足政企&金融级客户的核心安全诉求。支持跨机房、同城、异地、多活高可用,支持分布式强一致,数据0丢失(RPO=0,RTO<10s)。
❥ 健全的工具与服务化能力
GaussDB已经拥有华为云,商用服务化部署能力,同时支持DAS、DRS等生态工具。有效保障用户开发、运维、优化、监控、迁移等日常工作需要。
❥ 全栈自研
GaussDB基于鲲鹏生态,是当前国内唯一能够做到全栈自主可控的国产品牌。同时GaussDB能够基于硬件优势在底层不断进行优化,提升产品综合性能。
❥ 开源生态
GaussDB已经支持开源社区,并提供主备版版本下载。
❥ 高性能:性能强劲,服务端连接池,支持万级并发,32节点规模下提供高达1500万tpmC(衡量计算机系统的事务处理能力,即每分钟内系统处理的新订单个数")的事务处理能力。3节点TPCH标准性能压测,500GB<200s,1000GB<500s,单集群最大数据量超过4PB。
❥ 高扩展性:通过分布式全局事务一致性优化,打破传统分布式性能瓶颈,实现计算与存储的自由水平扩展能力,同时支持新增分片的数据在线重分布能力(业务不中断在线扩容)。
❥ 复合应用场景:行存储,支持业务数据频繁更新场景。列存储,支持业务数据追加和分析场景。内存表,支持高吞吐,低时延,极高性能场景。
☛ 相关资源:openGauss社区官网、openGauss代码托管平台、openGauss 3.0.0版本官方文档、知识图谱
国产数据库Top3:

二、架构
2.1、华为GaussDB分布式形态整体架构

GaussDB的最小管理单元是实例,一个实例代表了一个独立运行的数据库。用户可以在控制台创建和管理GaussDB实例。GaussDB支持分布式版和主备版实例。分布式形态能够支撑较大的数据量,且提供了横向扩展的能力,可以通过扩容的方式提高实例的数据容量和并发能力。主备版适用于数据量较小,且长期来看数据不会大幅度增长,但是对数据的可靠性,以及业务的可用性有一定诉求的场景。
CN(Coordinator Node调度节点):负责数据库系统元数据存储、查询任务的分解和部分执行,以及将DN中查询结果汇聚在一起。
DN(Data Node):负责实际执行表数据的存储、查询操作。

2.2、逻辑结构图

上图中,绿色部分属于openGauss数据库的内核部分,该部分总代码量在95万行左右。更多参看:https://www.modb.pro/db/41842
2.3、openGauss体系架构图

OpenGauss数据库源于PostgreSQL-XC项目,内核源于Postgres 9.2.4,总代码量约120W行,其中内核代码约95W行。华为结合企业级场景需求,深度融合其在数据库领域多年的经验,新增或修改了内核代码约70W行,内核代码修改比例约占总内核代码量的74%,近似于已经完全重构。保留了原先PostgreSQL的接口和公共函数代码(约25W行),仅对这些代码做了适当优化,这样也使得openGauss与现有的PG生态兼容性较好。openGauss属于单进程多线程模型的数据库,客户端可以使用JDBC/ODBC/Libpq/Psycopg等驱动程序,向openGauss的后端管理线程GaussMaster发起连接请求。华为主导的openGauss开源项目更着重在数据库架构、事务管理、存储引擎、SQL优化器、以及鲲鹏芯片做了大量优化,实现了企业级关键价值特性:高性能、高安全、易运维、全开放。所以,openGauss也可理解为是PostgreSQL的增强版。
当 GaussMaster 线程接收到客户端程序发送过来的服务请求后,会根据收到的信息会立即fork()一个子线程,这个子线程对请求进行身份验证成功后成为对应的后端业务处理子线程( gaussdb )。之后该客户端发送的请求将由此业务处理子线程(gaussdb)负责处理。当业务处理子线程(gaussdb)接收到客户端发送过来的查询(SQL)后,会调用openGauss的SQL引擎对SQL语句进行词法解析、语法解析、语义解析、查询重写等处理操作,然后使用查询优化器生成最小代价的查询路径计划。之后,SQL执行器会按照已制定的最优执行计划对SQL语句进行执行,并将执行结果反馈给客户端。
在SQL执行器的执行过程中通常会先访问内存的共享缓冲区(如:shared buffer、cstore buffer、MOT等),内存共享缓冲区缓存数据库常被访问的索引、表数据、执行计划等内容, 共享缓冲区的高速RAM硬件,为SQL的执行提供了高效的运行环境,大幅减少了磁盘IO,极大地提升了数据库性能,是数据库非常重要的组件之一。
shared buffer 是行存引擎默认使用的缓冲区,openGauss的行存引擎是将表按行存储到硬盘分区上,采用MVCC多版本并发控制,事务之间读写互不冲突,有着很好的并发性能,适合于OLTP场景。
cstore buffers 是列存引擎默认使用的缓冲区,列存引擎将整个表按照不同列划分为若干个CU(Compression Unit,压缩单元),以CU为单位进行管理,适合于OLAP场景。
MOT 是内存引擎默认使用的缓冲区,openGauss的MOT内存引擎的索引结构以及整体的数据组织都是基于Masstree模型实现的,其乐观并发控制和高效的缓存块利用率使得openGauss可以充分发挥内存的性能,同时,在确保高性能的前提下,内存引擎有着与openGauss原有机制相兼容的并行持久化和检查点能力(CALC逻辑一致性异步检查点),确保数据的永久存储,适合于高吞吐低时延的业务处理场景。
SQL执行器在共享缓冲区中对数据页的操作会被记录到 WAL buffer 中,当客户端发起事务的commit请求时,WAL buffer的内容将被WalWriter线程刷新到磁盘并保存在WAL日志文件中,确保那些已提交的事务都被永久记录,不会丢失。 但需要注意的是,当wal writer的写操作跟不上数据库实际的需求时,常规后端线程仍然有权进行WAL日志的刷盘动作。这意味着WALWriter不是一个必要的进程,可以在请求时快速关闭。
maintenance_work_mem 一般是在openGauss执行维护性操作时使用,如:VACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY等操作,maintenance_work_mem内存区域的大小决定了维护操作的执行效率。
temp_buffer 是每个数据库会话使用的LOCAL临时缓冲区,主要缓存会话所访问的临时表数据。需要注意的是,openGauss支持全局临时表和会话级临时表,全局临时表的表定义是全局的,而临时表的数据是各个会话私有的。
work_mem 是事务执行内部排序或Hash表写入临时文件之前使用的内存缓冲区。

三、部署
3.1、资源
资源利用率尽量控制在40%-70%间,低40%建议缩容,高于70%建议扩容。
3.2、数据库使用规范
参见华为推荐。
3.3、部署方式
1)集中式部署
集中式部署又包括单机和主备两种类型。
以主备为例,支持1+2(最大保护)主备,基于数据库日志复制的热备,在单机性能可满足需求的情况下,提供高可用。
其中,1+1(最大可用)指的是,数据会同步写往备机。但如果出现网络等影响,无法完成同步操作,会转为异步。后续网络恢复,会自动追上。在数据不同步期间,切换会有数据丢失。
1+2(最大保护)则意味着数据会同步写往备机,且要求必须有一个确认,才向客户端返回。可靠性高。
集中式版本拥有开源生态,用户可以通过开源网站直接下载,作为国内唯一开源数据库,也是华为开源、开放、不LOCKIN单一厂商的最佳证明。
2)分布式部署:
分布式部署方面,数据按shard划分,读写负载准线性扩展,满足大规模业务量场景,支持两地三中心高可用部署。另外,分布式版本承载华为云自研分布式组件体系,是传统企业拥抱互联网,面向未来海量事务型场景挑战的有力保障,适用于华为云部署。
3.4、部署过程
参看:https://opengauss.org/zh/blogs/jiajunfeng/openGauss2-0-0%E4%B8%BB%E5%A4%87%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2.html
3.5、目录说明
| 目录名称 | 说明 |
|---|---|
| base | openGauss数据库对象默认存储在该目录,如默认的数据库postgres、用户创建的数据库及关联的表等对象 |
| global | 存储openGauss共享的系统表或者说是共享的数据字典表 |
| pg_tblspc | 即openGauss的表空间目录,里面存储openGauss定义的表空间的目录软链接,这些软链接指向openGauss数据库表空间文件的实际存储目录 |
| pg_xlog | 存储openGauss数据库的WAL日志文件 |
| pg_clog | 存储openGauss数据库事务提交状态信息 |
| pg_csnlog | 存储openGauss数据库的快照信息,openGauss事务启动时会创建一个CSN快照,在MVCC机制下,CSN作为openGauss的逻辑时间戳,模拟数据库内部的时序,用来判断其他事务对于当前事务是否可见 |
| pg_twophase | 存储两阶段事务提交信息,用来确保数据一致性 |
| pg_serial | 存储已提交的可序列化事务信息 |
| pg_multixact | 存储多事务状态信息,一般用于共享行级锁(shared row locks) |
| Archived WAL | openGauss数据库WAL日志的归档目录,保存openGauss的历史WAL日志 |
| pg_audit | 存储openGauss数据库的审计日志文件 |
| pg_replslot | 存储openGauss数据库的复制事务槽数据 |
| pg_llog | 保存逻辑复制时的状态数据 |
| 文件名称 | 说明 |
|---|---|
| postgresql.conf | openGauss的配置文件,在gaussmaster线程启动时会读取该文件,获取监听地址、服务端口、内存分配、功能设置等配置信息,并且根据该文件,在openGauss启动时创建共享内存和信号量池等 |
| pg_hba.conf | 基于主机的接入认证配置文件,主要保存鉴权信息(如:允许访问的数据库、用户、IP段、加密方式等) |
| pg_ident.conf | 客户端认证的配置文件,主要保存用户映射信息,将主机操作系统的用户与openGauss数据库用户做映射 |
| gaussdb.state | 主要保存数据库当前的状态信息(如:主备HA的角色、rebuild进度及原因、sync状态、LSN信息等) |
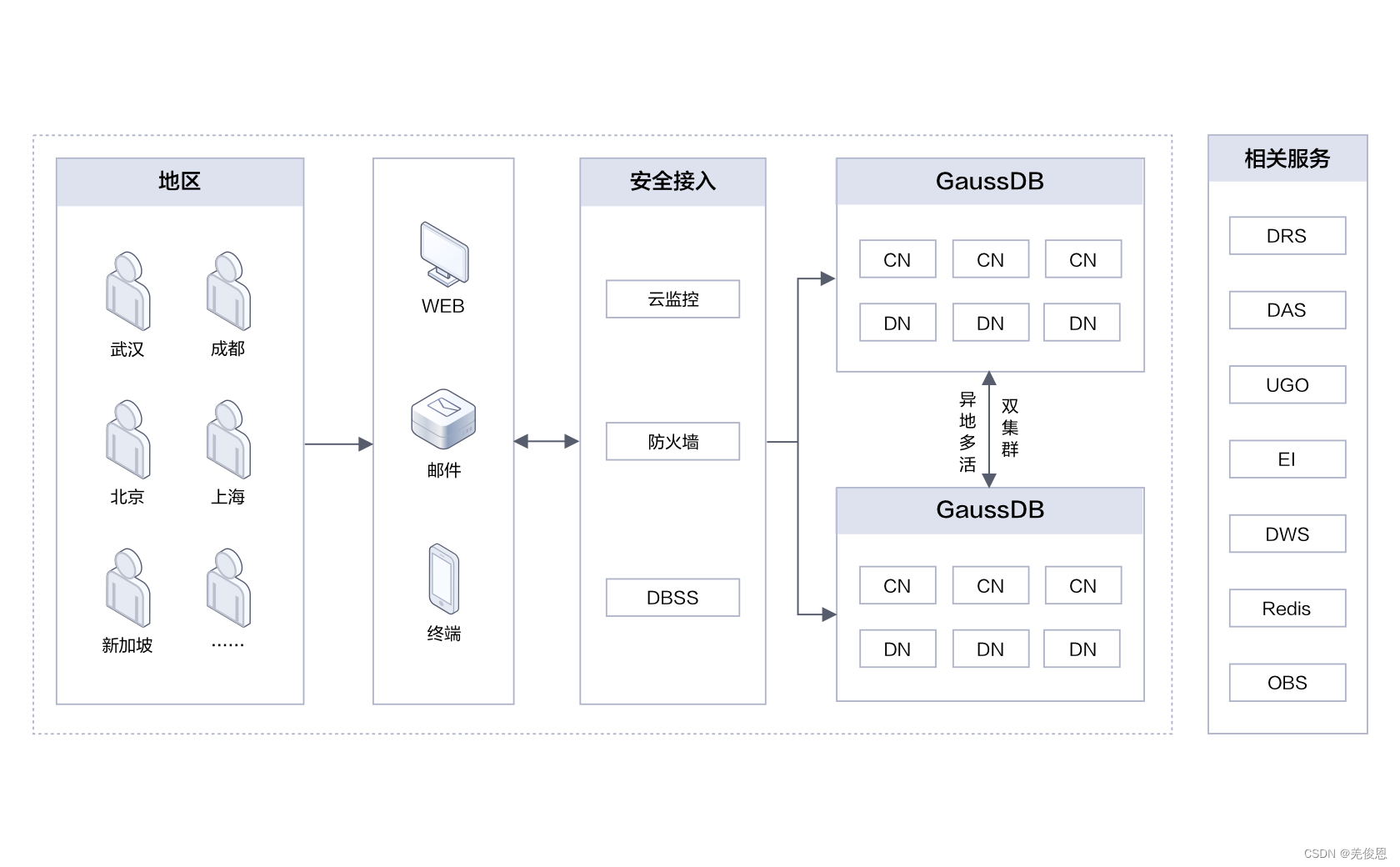
四、场景应用
4.1、金融交易系统场景:大容量,高可用,并发高性能

4.2、企业ERP/CRM集成
其长事务、超复杂SQL等场景下的性能卓越表现,可很好的满足ERP/CRM复杂的业务模型。

4.3、政企办公场景:多租户资源管理
五、附录:
5.1、云平台区域和AZ
区域(Region):从地理位置和网络时延维度划分,同一个Region内共享弹性计算、块存储、对象存储、VPC网络、弹性公网IP、镜像等公共服务。Region分为通用Region和专属Region,通用Region指面向公共租户提供通用云服务的Region;专属Region指只承载同一类业务或只面向特定租户提供业务服务的专用Region。
可用区(AZ,Availability Zone):一个AZ是一个或多个物理数据中心的集合,有独立的风火水电,AZ内逻辑上再将计算、网络、存储等资源划分成多个实例。一个Region中的多个AZ间通过高速光纤相连,以满足用户跨AZ构建高可用性系统的需求。
5.2、需满足的能力
openGaussDB产品的部署、实施;
openGaussDB产品相关项目实施和维护;
openGaussDB产品客户技术问题答疑,产品培训,故障处理;
openGaussDB产品周边运维工具开发;
5.3、数据库驱动
JDBC:JDBC(Java Database Connectivity,Java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问接口,应用程序可基于它操作数据。openGauss库提供了对JDBC 4.0特性的支持,需要使用JDK1.8版本编译程序代码,不支持JDBC桥接ODBC方式。
ODBC:ODBC(Open Database Connectivity,开放数据库互连)是由Microsoft公司基于X/OPEN CLI提出的用于访问数据库的应用程序编程接口。应用程序通过ODBC提供的API与数据库进行交互,增强了应用程序的可移植性、扩展性和可维护性。openGauss目前提供对ODBC 3.5的支持。但需要注意的是,当前数据库ODBC驱动基于开源版本,对于tinyint、smalldatetime、nvarchar2类型,在获取数据类型的时候,可能会出现不兼容。
Libpq:Libpq是openGauss的C语言程序接口。 客户端应用程序可以通过Libpq向openGauss后端服务进程发送查询请求并且获得返回的结果。需要注意的是,在官方文档中提到,openGauss没有对这个接口在应用程序开发场景下的使用做验证,不推荐用户使用这个接口做应用程序开发,建议用户使用ODBC或JDBC接口来替代。
Psycopg:Psycopg可以为openGauss数据库提供统一的Python访问接口,用于执行SQL语句。openGauss数据库支持Psycopg2特性,Psycopg2是对libpq的封装,主要使用C语言实现,既高效又安全。它具有客户端游标和服务器端游标、异步通信和通知、支持“COPY TO/COPY FROM”功能。支持多种类型Python开箱即用,适配PostgreSQL数据类型;通过灵活的对象适配系统,可以扩展和定制适配。Psycopg2兼容Unicode和Python 3。