The language used for inline assembly in Solidity is called Yul. 在solidity中,用于写内联汇编的语言是Yul.
Inline assembly is a way to access the Ethereum Virtual Machine at a low level. This bypasses several important safety features and checks of Solidity. You should only use it for tasks that need it, and only if you are confident with using it.
内联汇编是一个底层方式访问EVM的方式。 它会绕过一些重要的solidity的安全特性和安全检查。你只有在必须使用,并且有把握使用它的时候,再使用它.
为了实现更细粒度的控制,尤其是为了通过编写库lib来增强语言,可以利用接近虚拟机的语言将内联汇编与 Solidity 语句结合在一起使用。 由于 EVM 是基于栈的虚拟机,因此通常很难准确地定位栈内插槽(存储位置)的地址,并为操作码提供正确的栈内位置来获取参数。
An inline assembly block is marked by assembly { ... }
The inline assembly code can access local Solidity variables. 内联汇编代码可以访问本地的变量。Different inline assembly blocks share no namespace, i.e. it is not possible to call a Yul function or access a Yul variable defined in a different inline assembly block. 不通的内联汇编块没有命名空间区分, 所以, 跨块访问一个Yul的函数或变量是不可能的。
Access to External Variables, Functions and Libraries
EVM的运行原理
像 Solidity 这样的智能合约语言不能由 EVM 直接执行。 相反,它们需要被编译为低级别的指令(称为操作码)。
操作码
在底层,EVM 使用一组指令(称为操作码)来执行特定任务。 在撰写本文时,有 140 个唯一操作码。 这些操作码一起使 EVM 成为图灵完备的环境。 这意味着在有足够资源的情况下,EVM 能够(几乎)计算任何东西。 因为操作码是 1 个字节,所以最多只能有 256 (16²) 个操作码。 简单起见,我们可以将所有操作码分为以下几类:
- 堆栈操作操作码(POP、PUSH、DUP、SWAP)
- 算术/比较/按位操作码(ADD、SUB、GT、LT、AND、OR)
- 环境操作码(CALLER、CALLVALUE、NUMBER)
- 内存操作操作码(MLOAD、MSTORE、MSTORE8、MSIZE)
- 存储操作操作码(SLOAD、SSTORE)
- 程序计数器相关操作码(JUMP、JUMPI、PC、JUMPDEST)
- 停止操作码(STOP、RETURN、REVERT、INVALID、SELFDESTRUCT)
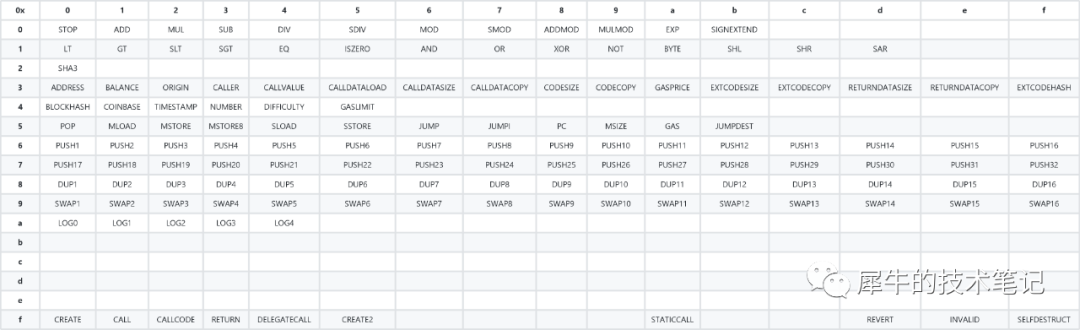
字节码
为了有效地存储操作码,它们被编码为字节码。 每个操作码都分配有一个字节(例如;STOP 是 0x00)。 我们来看看下面的字节码:0x6001600101
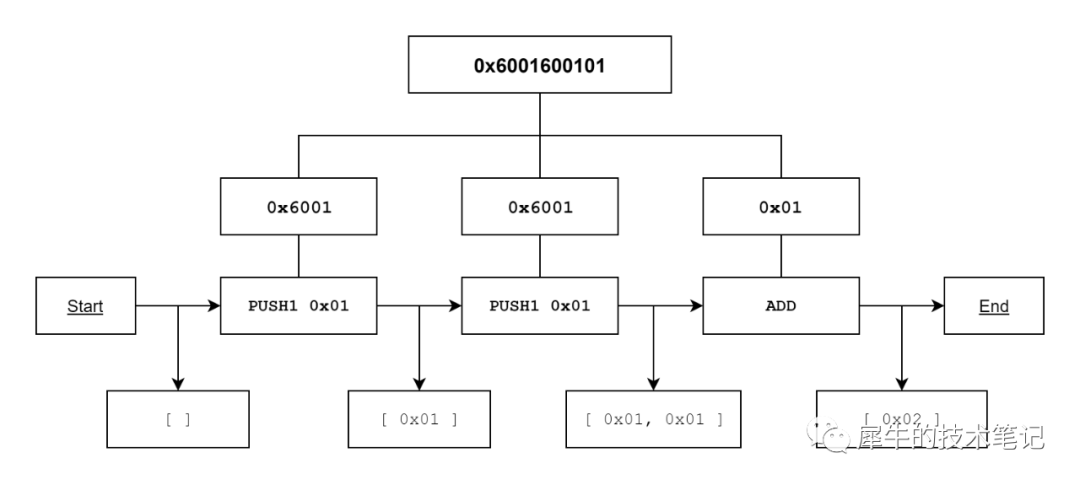
在执行过程中,字节码被分成它的字节(1 个字节等于 2 个十六进制字符)。 0x60–0x7f (PUSH1-PUSH32) 范围内的字节处理方式不同,因为它们包含推送数据(需要附加到操作码,而不是被视为单独的操作码)。
第一条指令是 0x60,它转换为 PUSH1。 因此,我们知道推送数据是 1 个字节长,我们将下一个字节添加到堆栈中。 堆栈现在包含 1 个项,我们可以移动到下一条指令。 由于我们知道 0x01 是 PUSH 指令的一部分,因此我们需要执行的下一条指令是另一个 0x60 (PUSH1) 以及相同的数据。 堆栈现在包含 2 个相同的项。 最后一条指令是 0x01,翻译为 ADD。 该指令将从堆栈中取出 2 个项,并将这些项目的总和压入堆栈。 堆栈现在包含一项:0x02
Solidity优化-减少合约gas消耗
Solidity优化-减少合约gas消耗 - 简书 (必读)
内联汇编的例子
The following example provides library code to access the code of another contract and load it into a bytes variable. This is possible with “plain Solidity” too, by using <address>.code. But the point here is that reusable assembly libraries can enhance the Solidity language without a compiler change.
接下来的例子中提供了一个库代码,去访问另外一个合约的代码,并且将它们加载到bytes变量中.
当然, 纯solidity语言也能实现,通过<address>.code 实现, 但是在这里, 可重用的汇编库代码可以在不改变编译器的版本情况下,增加solidity代码的最大可重用性。
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.4.16 <0.9.0;
library GetCode {
function at(address addr) public view returns (bytes memory code) {
assembly {
// retrieve the size of the code, this needs assembly 根据地址获取代码尺寸.
let size := extcodesize(addr)
// allocate output byte array - this could also be done without assembly
// by using code = new bytes(size)
code := mload(0x40) // 以太坊在0x40地址保存了下一个可用的指针(free pointer 空闲指针).
// 更新0x40位置的下一个空闲数据指针位置,防止之前的存储数据被覆盖. // 余留数据长度存储空间add(size, 0x20)
mstore(0x40, add(code, and(add(add(size, 0x20), 0x1f), not(0x1f))))
// store length in memory
mstore(code, size) // code代表数据的存储起始位置, mstore(p,v) 表示m[p..p+32] :=v (p+32代表的是一个存储槽位.) 一般数据存储的起始位置的第一个槽位,存储的是数据的长度.
// actually retrieve the code, this needs assembly
extcodecopy(addr, add(code, 0x20), 0, size) // add(code, 0x20) 代表code数据存储位置的下一个槽位, 一个槽位32个字节.
}
}
}
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.4.16 <0.9.0;
library VectorSum {
// This function is less efficient because the optimizer currently fails to
// remove the bounds checks in array access.
function sumSolidity(uint[] memory data) public pure returns (uint sum) {
for (uint i = 0; i < data.length; ++i)
sum += data[i];
}
// We know that we only access the array in bounds, so we can avoid the check.
// 0x20 needs to be added to an array because the first slot contains the
// array length.
function sumAsm(uint[] memory data) public pure returns (uint sum) {
for (uint i = 0; i < data.length; ++i) {
assembly {
sum := add(sum, mload(add(add(data, 0x20), mul(i, 0x20))))
}
}
}
// Same as above, but accomplish the entire code within inline assembly.
function sumPureAsm(uint[] memory data) public pure returns (uint sum) {
assembly {
// Load the length (first 32 bytes)
let len := mload(data) // data在汇编里面并不代表数组值本身, 而只是数组的值数据存储的起始位置, 是整数. mload(p), 即为m(p,p+32). 加载从p位置到p+32的位置的数据, 因为合约的存储操作最小单位是槽,存储槽,是一个32个字节的数组. 数组的第一个存储槽是存储的数组的长度.
// Skip over the length field.
//
// Keep temporary variable so it can be incremented in place.
//
// NOTE: incrementing data would result in an unusable
// data variable after this assembly block
let dataElementLocation := add(data, 0x20); //0x20是一个存储槽的长度,32个字节。 读或写,也是按照一个槽位一个槽位的读或写.
// Iterate until the bound is not met.
for
{ let end := add(dataElementLocation, mul(len, 0x20)) }
lt(dataElementLocation, end)
{ dataElementLocation := add(dataElementLocation, 0x20) }
{
sum := add(sum, mload(dataElementLocation))
}
}
}
}
mload 参数代表都是即将操作的数据内存存储位置, 返回的是,一个内存槽32个字节,所代表真实的数据.
mstore(p,v), p 代表的是数据将要存储的内存地址, v代表的是具体要存储的数据. 位置一般是p+32个字节,一个存储的内存槽,32个字节的尺寸. 虚拟机在读和写的时候,都是一个卡槽一个卡槽的读或写, 一个卡槽是32个字节.
sload, sstore 没有自增p..p+32的逻辑.
【无标题】solidity的内存分配(mload 0x40)_mload solidity_h_sn999的博客-CSDN博客(必读)
【无标题】solidity的内存分配(mload 0x40)_mload solidity_h_sn999的博客-CSDN博客 (必读)
以太坊合约语言开发简单介绍_跨链技术践行者的博客-CSDN博客
堆和栈的区别?
指令风格:
3 0x80 mload add 0x80 mstore
函数风格:
mstore(0x80, add(mload(0x80), 3)) 把内存地址080地方的数据load进内存和3相加,存储到内存地址为0x80上.
在函数风格写法中参数的顺序与指令风格相反。如果使用函数风格写法,第一个参数将会位于栈顶。
Access to External Variables, Functions and Libraries
Local variables that refer to memory evaluate to the address of the variable in memory, not the value itself. Such variables can also be assigned to, but note that an assignment will only change the pointer and not the data and that it is your responsibility to respect Solidity’s memory management. See Conventions in Solidity. 本地变量都指向的是值在内存中的地址, 而不是值本身. 因此变量可以被赋值,但这个赋值仅只改变变量引用的地址而不是数据本身, 遵守solidity的内存管理是你的责任。
Similarly, local variables that refer to statically-sized calldata arrays or calldata structs evaluate to the address of the variable in calldata, not the value itself. The variable can also be assigned a new offset, but note that no validation is performed to ensure that the variable will not point beyond calldatasize(). 相似的, 本地变量指向静态尺寸的数组或结构,本质上也是引用的数据存储地址而不是数据本身。变量可以被赋予新的偏移量offset, 但没有相应的校验去保证这个offset已经超出边界.
For local storage variables or state variables, a single Yul identifier is not sufficient, since they do not necessarily occupy a single full storage slot. Therefore, their “address” is composed of a slot and a byte-offset inside that slot. To retrieve the slot pointed to by the variable x, you use x.slot, and to retrieve the byte-offset you use x.offset. Using x itself will result in an error.
对于一个本地变量或状态变量, 一个单独的Yul标识符是不满足的,因为他们不一定单独单满一个存储槽. 因此他们的存储地址有一个slot和 slot里面的字节偏移组成。 为了获去变量x指向的卡槽,可以用x.slot, 为了获取存储偏移量: x.offset 存储地址就是:x.slot+x.offset
Things to Avoid
Inline assembly might have a quite high-level look, but it actually is extremely low-level. Function calls, loops, ifs and switches are converted by simple rewriting rules and after that, the only thing the assembler does for you is re-arranging functional-style opcodes, counting stack height for variable access and removing stack slots for assembly-local variables when the end of their block is reached.
内联程序集可能具有相当高级的外观,但实际上是非常低级的。函数调用、循环、if和开关通过简单的重写规则进行转换,之后,汇编程序为您做的唯一事情就是重新排列函数式操作码,计算变量访问的堆栈高度,并在到达块末尾时移除汇编局部变量的堆栈槽。
Memory Safety
Without the use of inline assembly, the compiler can rely on memory to remain in a well-defined state at all times. This is especially relevant for the new code generation pipeline via Yul IR: this code generation path can move local variables from stack to memory to avoid stack-too-deep errors and perform additional memory optimizations, if it can rely on certain assumptions about memory use.
在不使用内联汇编的情况下, 编译器可以总是依赖内存去维护一个良好的状态. 这个跟新代码生成管道Yul IR相关。 solidity生成内联汇编代码,两种方式,一种命令行模式, 一种使用IR. 这种代码生成路径可以将变量从stack中移动到内存,去避免stock-too-deep错误并且如果它依赖一个确定的内存消费使用情况,会执行一个额外的内存优化。
While we recommend to always respect Solidity’s memory model, inline assembly allows you to use memory in an incompatible way. Therefore, moving stack variables to memory and additional memory optimizations are, by default, globally disabled in the presence of any inline assembly block that contains a memory operation or assigns to Solidity variables in memory.
虽然我们建议总是遵守solidity的内存模型, 但是内联汇编总是允许你以一种非兼容的方法使用内存。因此,在任何含有内存操作或赋值给solidity的变量的内联汇编模块面前,移动stack变量到内存或额外的内存优化,默认会被禁用。
However, you can specifically annotate an assembly block to indicate that it in fact respects Solidity’s memory model as follows:
assembly ("memory-safe") {
...
}