什么是Ziya?
Ziya是一个基于LLaMa的130亿参数的中英双语预训练语言模型,它由IDEA研究院认知计算与自然语言研究中心(CCNL)推出,是开源通用大模型系列的一员。Ziya具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力,可以处理多种自然语言任务。
- Ziya-Visual模型开源地址:https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1
- Demo体验地址:https://huggingface.co/spaces/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1-Demo
- Ziya开源模型:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
- 封神榜项目主页:https://github.com/IDEA-CCNL/Fe
什么是IDEA研究院CCNL?
IDEA研究院(International Digital Economy Academy)是一家致力于人工智能和数字经济领域的前沿研究与产业落地的国际化创新型机构,由微软亚洲研究院前执行副总裁沈向洋博士创立。IDEA研究院力求从技术出发,孵化优质企业、培养杰出人才、构建合作生态。
CCNL(Cognitive Computing and Natural Language)是IDEA研究院下属的一个研究中心,由张家兴博士领导。CCNL致力于在预训练大模型时代,建设认知智能的基础设施,推动AI学术和产业发展。CCNL在预训练模型生产、少样本/零样本学习、受控文本生成、自动化机器学习等技术领域,都达到了领先水平。CCNL的总部位于深圳市南山区科技园北区科苑路9号科兴科学园B2栋6楼。
Ziya和其他大语言模型有什么区别?
大语言模型(LLM)是指具有超过10亿参数的预训练语言模型,它们通常可以处理多种自然语言任务,如文本生成、问答、摘要等。Ziya和其他大语言模型有以下几个区别:
- Ziya是一个自回归的模型,也就是说它只能从左到右生成文本,而不能同时使用上下文信息。这和一些自编码或编码-解码的模型不同,如T5、mT5、UL2等。
- Ziya是一个双语的模型,也就是说它同时支持中文和英文,并且在两种语言上都有较高的精度。这和一些只支持单语或者多语的模型不同,如GPT-3、GPT-4、mT0等。
- Ziya是一个开源的模型,也就是说它的权重文件和代码都可以免费下载和使用。这和一些只提供API或者商用的模型不同,如GPT-3、GPT-4、PaLM、LaMDA等。
- Ziya是一个多功能的模型,也就是说它可以处理多种任务,如翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等。这和一些只专注于某一领域或者任务的模型不同,如ChatGLM、InstructGPT、Alpaca等。
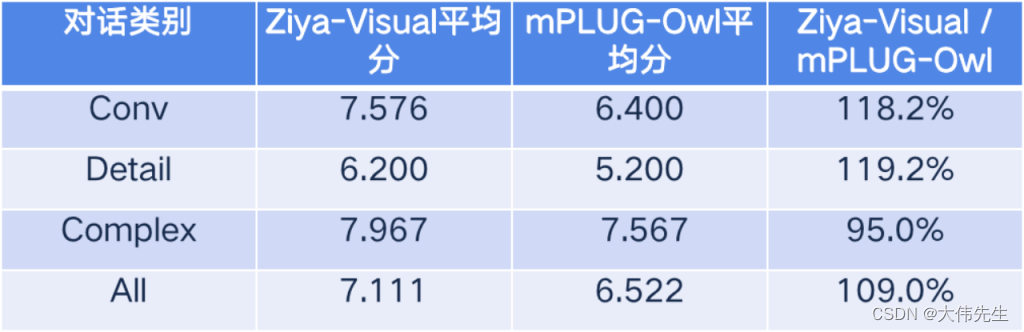
Ziya的使用方法是什么?
Ziya的使用方法可以参考其GitHub上的说明文档和示例代码。简单来说,用户需要先下载LLaMa-13B和Ziya-LLaMA-13B-v1的权重文件,并使用转换脚本合并成一个完整的模型文件。然后用户可以使用transformers库中的LlamaTokenizer和LlamaForCausalLM类来加载模型,并使用generate方法来生成文本。用户也可以根据自己的需求对模型进行微调或部署
Ziya有哪些优势和局限?
Ziya的优势在于它使用了大量的中英双语数据进行预训练,并在原生的LLaMa-13B模型基础上增量训练了110B tokens的数据。它还使用了监督微调、反馈自助、人类反馈强化学习等技术,使模型初具理解人类指令意图的能力。它还支持INT4量化,使得用户可以在消费级的显卡上进行本地部署。
Ziya的局限在于它的参数规模较小,不能处理复杂的逻辑问题;它的词表较小,不能覆盖所有的中英文字符;它的序列长度较短,不能生成很长的文本等。
Ziya有哪些应用场景和案例?
Ziya可以应用于多种场景,如:
- 翻译:Ziya可以实现中英文互译,支持不同领域和风格的翻译,如文学、科技、口语等。
- 编程:Ziya可以根据用户的需求生成代码,支持不同语言和框架,如Python、Java、C++等。
- 文本分类:Ziya可以根据用户的标签对文本进行分类,支持不同主题和类型,如新闻、评论、情感等。
- 信息抽取:Ziya可以从文本中抽取出关键信息,支持不同格式和结构,如表格、列表、图表等。
- 摘要:Ziya可以对文本进行摘要,支持不同长度和粒度,如标题、摘要、概要等。
- 文案生成:Ziya可以根据用户的目的生成文案,支持不同场景和风格,如广告、营销、故事等。
- 常识问答:Ziya可以回答用户的常识性问题,支持不同领域和难度,如历史、地理、科学等。
- 数学计算:Ziya可以进行数学计算,支持不同运算和表达式,如加减乘除、分数、方程等。
总结
Ziya是一个具有自回归、双语、开源和多功能特点的大语言模型,它在中英文上都有较好的表现,并且可以应用于多种场景。如果您对Ziya感兴趣,欢迎访问其官方网站 https://fengshenbang.cc/ ,或者在Hugging Face平台 https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1 下载和使用它。也欢迎您在评论区留下您的问题或建议。谢谢您的阅读!
信息源
(1) 粤港澳大湾区数字经济研究院(IDEA研究院). https://www.idea.edu.cn/.
(2) 认知计算与自然语言研究中心-IDEA研究院. https://www.idea.edu.cn/research/ccnl.html.
(3) IDEA-CCNL (Fengshenbang-LM) – Hugging Face. https://huggingface.co/IDEA-CCNL.