复习函数的基本知识
要使用C++函数,必须完成如下工作:
- 提供函数定义
- 提供函数原型
- 调用函数
库函数是已经定义和编译好的函数,同时可以使用标准库头文件提供其原型,因此只需要正确地调用这种函数即可。但是创建自己的函数时,必须自行处理上面提到的3个方面。例如
#include<iostream>
using namespace std;
void hello(); //函数的声明
int main()
{
cout << "主函数将调用自己编写的hello这个函数:" << endl;
hello(); //函数的调用
cout << "调用自编函数hello结束" << endl;
return 0;
}
//函数的声明
void hello()
{
cout << "我向大家问好!"<<endl;
}
程序按行顺序执行。执行函数hello()时,将暂停main()中的代码;等函数hello()执行完毕之后,继续执行main()中的代码。
定义函数
可以将函数分为两类:没有返回值的和有返回值的函数。
没有返回值的函数称为void函数,通用格式如下:
void functionName(parameterList)
{
statement(s)
return;
}其中,parameterList指定了传递给函数的参数类型和数量。
有返回值的函数将生成一个值,并将它返回给调用函数。这种函数的返回类型被声明为返回值的类型。通用格式如下:
typeName functionName(parameterList)
{
statement(s)
return value;
}对于有返回值的函数,必须使用返回语句,以便将值返回给调用函数。注意返回值的类型不能是数组,但可以是其他任何类型——整数、浮点数、指针、结构、对象

函数在执行返回语句后结束。如果函数包含多条返回语句,则函数在执行遇到的第一条返回语句后结束。例如
int bigger(int a,int b)
{
if(a > b)
return a;
else
return b;
}函数原型和函数调用
看下面一个例子
#include<iostream>
using namespace std;
void cheers(int); //prototype, no return value
double cube(double x); //prototype, return a double
int main()
{
cheers(5); //function call
cout << "Give me a number: ";
double side;
cin >> side;
double volume = cube(side); //function call
cout << "A " << side << "-foot cube has a volume of ";
cout << volume << " cubic feet" << endl;
cheers(cube(2));
return 0;
}
void cheers(int n)
{
for (int i = 0; i < n; i++)
{
cout << "Cheers! ";
}
cout << endl;
}
double cube(double x)
{
return x * x * x;
}
1.为什么需要原型?
原型描述了函数到编译器的接口,也就是说它将函数返回值的类型(如果有的话)以及参数的类型和参数的数量告诉编译器。
函数原型是怎样影响下面这条语句的?
double volume = cube(side);对于上面这条语句,函数原型告诉编译器,cube()有一个double参数。如果程序没有提供这样的参数,原型将让编译器能够捕获这种错误;其次,cube()函数完成计算后,将把返回值放在指定的位置,然后调用函数(这里是main()函数)将从这个指定位置取得返回值。由于原型指出了cube()的返回类型是double,因此编译器知道应该检索多少字节以及如何解释它们。如果没有这些信息,编译器将只能进行猜测,而编译器是不会这样做的。
2.原型的语法
函数的原型是一条语句,因此必须以分号结束。最简单的方法就是 复制函数定义中的函数头并添加分号。(函数原型不要求提供变量名,有类型列表就行了;下面这两种都是正确的)
void hell(int);
void hell(int x);3.原型的功能
原型确保以下几点:
- 编译器正确处理函数返回值
- 编译器检查使用的参数数目是否正确
- 编译器检查使用的参数类型是否正确;如果不正确,则在能力范围内转换为正确的类型
函数参数和按值传递
C++通常按值传递参数,这意味着将数值参数传递给函数,而后者将其赋给一个新的变量。
用于接收传递值的变量被称为形参,传递给函数的值被称为实参。

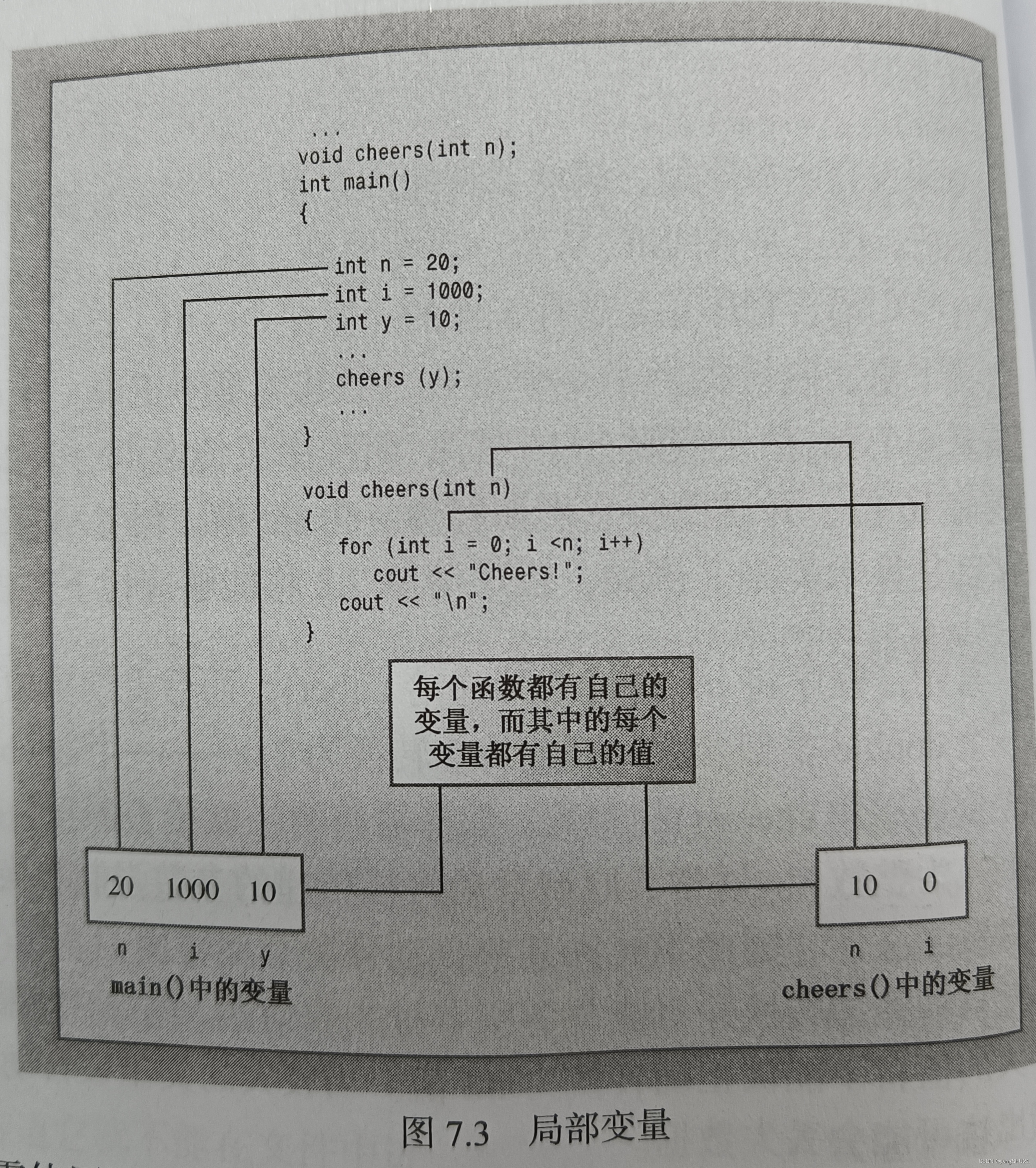
在函数中声名的变量(包括参数)是该函数私有的。在函数被调用时,计算机将为这些变量分配内存,在函数结束时,计算机将释放这些变量使用的内存,这样的变量被称为局部变量。
如果在main()中声明了一个名为x的变量,同时在另一个函数中也声明了一个名为x的变量,则它们将是两个完全不同的、毫无联系的变量
多个参数
函数可以有多个参数,在调用函数时,只需使用逗号将这些参数分开即可:
n_chars('R',50);上述函数调用将两个参数传递给函数n_chars()
同样,在定义函数时,也在函数头中使用由逗号分隔的参数声名列表
void n_chars(char c,int n) //two arguments该函数头指出,函数n_chars()接受一个char参数和一个int参数,必须分别指定每个参数的类型,不能像声明常规变量那样,将声明组合在一起。
函数和数组
函数是处理复杂类型(如数组、结构)的关键,下面学习如何将数组和函数结合在一起
假设现在要计算一个数组中所有元素的和,我们可以使用for循环逐个遍历相加即可,这样没换一个数字都要进行相应的修改。这里我们写出一个统一的接口,让对于不同的数组修改的尽可能少,不必每次都编写新的循环。
#include<iostream>
using namespace std;
const int ArSize = 8;
int sum_arr(int arr[], int n);
int main()
{
int cookies[ArSize] = { 1,2,4,8,16,32,64,128 };
int sum = sum_arr(cookies, ArSize);
cout << "Total cookies: " << sum << endl;
return 0;
}
int sum_arr(int arr[], int n)
{
int total = 0;
for (int i = 0; i < n; i++)
{
total = total + arr[i];
}
return total;
}
我们看函数头
int sum_arr(int arr[], int n)方括号指出arr是一个数组,方括号为空则表示可以将任何长度的数组传递给该函数。但实际情况并不是这样:arr实际上并不是数组,而是一个指针。(在编写函数的其余部分时,可以将arr看作是数组)
函数如何使用指针来处理数组
前面介绍过,C++将数组名解释为其第一个元素的地址
cookies == &cookies[0]数组声明使用数组名来标记存储位置,对数组名使用sizeof将得到整个数组的长度(以字节为单位),将取地址运算符&用于数组名时,将返回整个数组的地址
在函数调用:
int sum = sum_arr(cookies, ArSize);其中cookies是数组名,而根据C++规则,cookies是其第一个元素的地址,因此函数传递的是地址。由于数组的元素的类型为int,因此cookies的类型必须是int指针,即int*。这表明正确的函数头应该是这样的:
int sum_arr(int *arr,int n)这证明 int *arr和int arr[ ]这两个函数头都是正确的。因为在C++中,当且仅当用于函数头或函数原型中,它们两者的含义才是相同的,都意味着arr是一个int指针。在其他的上下文中, int * arr和int arr[ ]的含义是不同的。
我们可以看到,上述程序并没有将数组内容传递给函数,而是将数组的位置(地址)、包含的元素种类(类型)以及元素数目(变量n)传递给函数,有了这些信息后,函数便可以使用原来的数组。
传递常规变量时,函数将使用该变量的拷贝;但传递数组时,函数将使用原来的数组。
将数组地址作为参数可以节省复制整个数组所需的时间和内存。
指针和const
可以用两种不同的方式将const关键字用于指针。
第一种方法是让指针指向一个常量对象,这样可以防止使用该指针来修改所指向的值;
int age = 39;
const int* pt = &age;该声明指出,pt指向一个const int(39),因此不能使用pt来修改这个值
*pt += 1; //INVALID
cin >> *pt; //INVALIDpt的声明并不意味着它指向的值实际上就是一个常量,而只意味着对pt而言,这个值是常量。(例如pt指向age,而age不是const,可以直接通过age变量来修改age的值,但是不能使用pt指针来修改它)
*pt = 20; //INVALID
age = 20;在这里注意又有两种情况,以前我们总是将常规变量的地址赋给常规指针,而这里将常规变量的地址赋给指向const的指针(因此还有两种情况:将const变量的地址赋给指向const的指针、将const变量的地址赋给常规指针。其实只有第一种可行,第二种是不可行的)
const float g_earth = 9.8;
const float *pe = &g_earth; //VALID对于这一种情况,既不能使用g_earth来修改值9.8,也不能使用指针pe来修改。
尽可能使用const
将指针参数声明为指向常量数据的指针有两条理由:
1)这样可以避免由于无意间修改数据而导致的编程错误
2)使用const使得函数能够处理const和非const实参,否则只能接受非const参数
第二种方法是将指针本身声明为常量,这样可以防止改变指针指向的位置。
int sloth = 3;
int *const finger = &sloth;这种声明结构使得finger只能指向sloth,但允许使用finger来修改sloth的值
递归
C++函数有一种有趣的特点——可以自己调用自己(与C语言不同的是,C++不允许main()调用自己),这种功能被称为递归。
如果递归函数调用自己,则被调用的函数也将调用自己,这将无限循环下去,除非代码中包含终止调用链的内容。通常的方法将递归调用放在if语句中,如下面的一个递归函数
void recurs(argumentlist)
{
statements1
if(test)
recurs(arguments2)
statements2
}