本篇作为JDK 源码分析的第一篇,就先从简单的说起。本篇主要分析的就是Object、ArrayList 以及LinkedList 的源码,Object 主要就是简单介绍一下hashCode 的生成还有一些基本的概念,object 本身来说也并不是很复杂,面试的时候也不会问到太多,所以也就不多聊。剩下的ArrayList 和LinkedList 都是从数据结构、初始化、增删改查以及扩容流程来详谈。
Object的简单介绍
基本上所有刚刚接触java 的萌新第一个知道的就是万物皆对象,然后就是Object,这也说明了object 在java中的地位,它作为所有类的基类,当一个类没有继承某个类时,默认继承的就是object。
Object 类属于 java.lang 包,此包下的所有类在使用时无需手动导入,都是系统会在程序编译期间自动导入的。注意:JDK无论版本,都是由编译器在编译阶段就已经织入了Object。
我们这里也可以先看下object 的类结构图。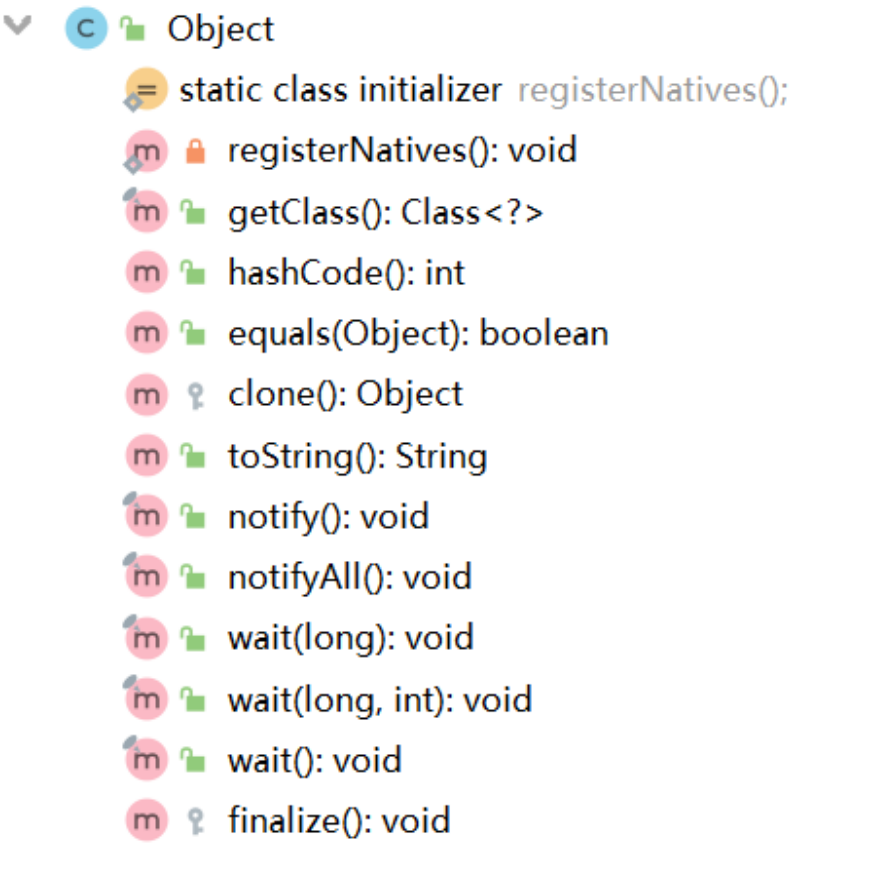
可以看到这里会有很多的方法,我们常用的就是getClass、toString、equals 之类的,甚至toString、equals 之类方法平时使用还是String 重写过的,我们这里就分别介绍一下getClass 和hashCode 方法,其余的有兴趣的话可以自己了解,至于String 重写就比较简单也可以自己去看,这我只在刚刚入行的时候有人问过,属于入门小知识。
获取运行时类的方法-getClass方法
这个方法我们在框架中看到的比较多,上次聊Spring 框架的时候有很多地方都有通过getClass 方法获取到类对象,然后可以获取到所有方法、属性,进而可以对这些方法、属性进行操作,比如Bean 初始化和填充属性的时候就有使用。
getClass 方法本身是被native 关键字修饰的常量方法,这里我们要知道用native 修饰的方法我们不用考虑,由操作系统帮我们实现,被native 修饰的方法表示告知JVM 调用,该方法在外部定义,我们可以用任何语言去实现它。简单地讲,一个native Method 就是一个Java 调用非Java 代码的接口。
public final native Class<?> getClass();
获取hash码的方法-hashCode方法
hashCode 方法同样也是一个由native 修饰的常量方法,作用是返回对象的散列码,是int 类型的数值。在后面我们要说的HashMap 的key 值就是需要转换为hashCode 的。hashCode 的本质就是用来在散列存储结构中确定对象的存储地址。
Java 的集合设计者就采用了哈希表来实现的。哈希算法也称为散列算法,是将数据依特定算法产生的结果直接指定到一个地址上。这个结果就是由hashCode 方法产生。这样一来,当集合要添加新的元素时,先调用这个元素的hashCode 方法,就一下子能定位到它应该放置的物理位置上。(这里提一句Redis 的设计同样也是这样,后面Redis 文章详谈)
关于hashCode 的生成和存储,这里涉及到很多关于锁的知识点,这点我们后面关于并发线程的文章再说,我们这里说hashCode 生成的结论。
- hashCode 不是直接使用的内存地址,而是采取一定的算法来生成
- hashCode 值的存储在mark word里,与锁共用一段bit位,这就造成了跟锁状态相关性,如果是偏向锁:一旦调用hashcode,偏向锁将被撤销,hashcode被保存占位mark word,对象被打回无锁状态,如果这个时候该对象一定要使用锁,那么对象再也回不到偏向锁状态而是升级为重量级锁。hashCode 跟随mark word 被移动到c 的object monitor,从那里取。
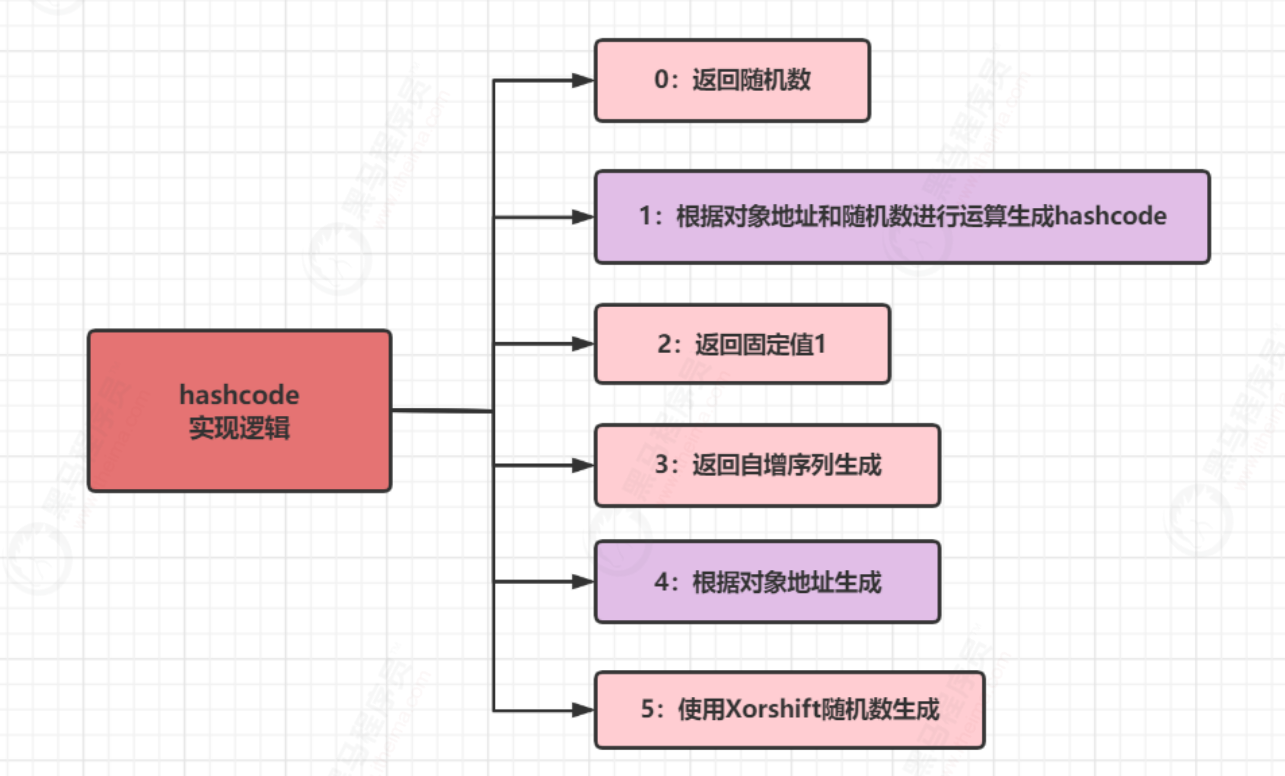
hashCode 的实现逻辑总结见下图,java 对hashCode 的生成可以通过参数 -XX: hashcode=1进行修改 (JDK8默认使用最后一种)
数组集合-ArrayList
萌新都知道的一点:ArrayList 就是List 接口的实现类。那为什么它又被叫做数组集合呢,其原因就是它的数据结构本质上就是一个数组,我们使用的增删改查都通过的下标索引来进行的。分析这类对象,我们就从其构造方法开始。
类构造器-无参构造防方法
在我们平常中使用集合中ArrayList 还是非常常见的,要了解它的构造,我们就可以先简单的创建一个ArrayList。
List<String> list = new ArrayList<>();
简单的无参构造new 出来就行,这里我们可以跟进无参构造的方法看看。
这里可以说是非常的简单,就是构建了一个空数组。注意:这里构造出的是空数组,也就说数组长度是0。
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {
};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
第一次添加元素和之后添加元素-add方法
看标题,我这里是将第一次调用添加和后面再调用添加是分开了的,为什么呢,因为我们上面调用的无参构造生成的数据没有长度,一个数组没有长度的情况下,是不可能可以添加元素的,所以我们第一次调用要先完整构建出数组,然后在添加元素,后面再添加时就无须操作了。
看代码,直接调用add 方法。
这里首先就是调用ensureCapacityInternal 方法,然后再往elementData 数组中添加传入元素,并累加数组长度。
private int size;
transient Object[] elementData;
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
我们再看下ensureCapacityInternal 方法。
这里要将两层方法调用都看下,先看calculateCapacity 方法。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
先判断传入数组是不是刚刚无参构造生成的数据,是则将当前长度(我们第一次添加,这里传入的是1)和10对比,取最大返回,否则返回当前长度。
private static final int DEFAULT_CAPACITY = 10;
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
继续看ensureExplicitCapacity 方法。
这里先是累加一个modCount 变量,然后判断当前长度是否大于集合长度,是则表示数组需要扩容,然后直接跳过,回到add 方法继续添加步骤。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
数组集合扩容方法-grow方法
继续看grow 扩容方法。
这里有一些算法,乍一看还是比较模糊,我们以数字带入看,
- 首先目前传入的是10,
- 然后获取当前数组长度并赋值给oldCapacity = 0,
- newCapacity = 0 + (0 >> 1) 这里是右移一位还是等于0,
- 0 - 10 < 0,所以这里进第一个判断newCapacity = 10,
- 第二个判断一般都是不会进的,这里是判断是否超过最大长度,
- 最后进入Arrays.copyOf 调用,这里就可以不用再跟了,这就是创建一个数组,并将原数组中的元素转移到新数组中。
这里右移不知道怎么算的,可以先将被右移数转为二进制码,然后左边添加一个0,删除最右边的数组,比如:4,二进制为100,右移一位是010,也就是10,再将二进制转为十进制就是2。至于上面的0右移一位,0的二进制就是,再怎么右移还是0。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
小结一下:arrayList 的元素添加就是需要先扩容再添加。扩容的算法是根据当前数组长度累加其右移一位后的数字,数组无参构造的初始长度是10,那么第一次扩容后的长度就是15,第二次扩容就是22,后面就是以此类推。
删除元素-remove方法
删除元素实现也同样简单,根据下标索引就能实现,直接传入一个下标索引即可。
list1.remove(3);
我们来跟一下具体的remove 方法。
首先是rangeCheck 方法用于判断当前下标是否存在,然后通过elementData 获取到具体的元素对象,判断当前删除元素的下标索引是否是最后一个,否则进判断将当前元素后面的所有元素前移,比如1-10元素中删除2元素,那么走完这步后数组的元素应该是1、3-10、10,也就是说数组长度不变,但是将2元素进行了替换,数组最后一个元素不变,其余元素前移,然后将数组最后一位置空。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
上面方法要看的其实就是一个如何获取元素对象,也就是查询,至于第一步的rangeCheck 方法,就是我们最常见的索引越界异常。
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
查询元素-get方法
其实这些增删改查的方法都没有什么说的,都是我们一些常用的使用,查询还是根据下标索引调用get 方法即可,我们看下具体代码。
首先就是判断索引是否越界,还是调用上面说的方法。然后就是上面没有说完的elementData 方法获取具体元素。
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
这个不用看都知道,这个就是一个数据,使用数组取值就行。
E elementData(int index) {
return (E) elementData[index];
}
修改方法-set方法
这个的具体调用就是传入一个索引下标和需要修改的值即可。
首先校验索引是否越界,然后通过获取到具体元素,再将元素替换即可。
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
链表集合-LinkedList
说完ArrayList,我们再说说LinkedList,它同样是list 接口的实现类,但是区别于ArrayList 的数据结构,LinkedList 使用的是双向链表结构。
那什么是双向链表呢,要知道双向链表,就要先了解链表,在zookeeper 系列的文章中有提到一个概念就是任务处理链,实现方式就是当前任务线程执行完成之后,就会往下个线程的查询队列中添加一个数据,当在队列中查询到数据时,下一个线程才会执行真正的任务处理,然后依次类推。
也就是说,链就是当先对象关联着下一个对象的说明。链表就是上一个元素中有一个next 属性指向下个元素。双向链表就是不光有next 属性指向下个元素,还有pre 属性指向上个元素,这样开头元素能向下检索,结尾元素也能向上检索,这样有利于二分查询。
类构造器-无参构造
还是跟ArrayList 的讲解顺序一样,先看下LinkedList 的无参构造方法,也就是正常的new 出来。不过有意思的是这里什么都没有做。
public LinkedList() {
}
既然什么都没有做,那么它又是怎么去存放元素的呢,这就要看下它存放的对象,node 节点对象。
这里的元素存放属性item 表示可以存放任意对象,next 属性存放下一个节点,prev 属性存放上一个节点。这个节点对象初始化的时候,这三个属性也是必填的,这里没有无参构造了。简单来说LinkedList 就是由这么一个一个的对象构建出来的,所以无参构造不需要做任何操作
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
添加元素-add方法
还是跟上面一样的方法名,但是内容差距还是蛮大的。
add 方法里面还是继续调用linkLast 方法。
public boolean add(E e) {
linkLast(e);
return true;
}
这个方法首先是获取头节点,然后在构建出node 节点对象,注意这里的构造我们上面可以看到,入参首先是上个节点,然后是元素,最后下个节点,那么如果是第一次写入,获取上个节点就是null,所以下面会进判断,将当前元素设置为头节点,然后增加集合长度,注意判断之前还有一个就是每一个节点linkedList 都将它当做最后一个节点,直到后一个节点进行覆盖。
那么add 再次被调用的时候,第二个元素写入,获取到的上个节点就有值了,再然后就是将上个节点的下个节点属性赋值为当前节点。
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
有点绕啊,我们可以看下结构图,这样就能清晰的看出linkedList 的数据结构了。因为就是这样的数据结构,所以就没有扩容的说法。

删除元素-remove方法
还是跟上面一个的方法名,看下具体代码。
首先checkElementIndex 方法的调用不用看,跟上面ArrayList 的rangeCheck 方法一样,都是判断是否索引是否越界异常,然后就是unlink 方法的调用,注意:这里还有一个node 方法,这个就是查询当前节点对象。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
先看node 方法是如何获取到当前元素的。
这里会有一个我们之前说到的二分查询的概念,我们可以看到这里首先是将当前数组大小右移一位,也就是如果当前大小为5,那么右移结果为2,入参下标索引为3,也就是删除第4个元素,那么这里就会根据尾结点,倒着查询出当前节点,如果入参为1,那么就会从头节点顺查到当前节点。这就是二分查询,从中剖开,分段查询。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
再看unlink 方法。
首先就是获取当前节点对象的所有属性信息,然后判断当前节点是不是头结点,或者尾结点,如果不是就将上一个节点的next 属性指向下一个节点,将下一个节点的prve 属性指向上个节点,也就是说将当前节点的上一个节点和下一个节点相互关联,将自身的关系剔除。
然后再将当前节点的item 的属性设置为空,然后集合大小减一即可。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
查询元素-next方法
这里的查询不再是根据下标索引查询了,当然使用get 方法一样能够查询,但是这里不建议用下标索引的方式来查询,而是用迭代的方式查询。
使用迭代的话,我们就简单看下。
首先就是获取迭代器,然后循环迭代,很正常的操作。
Iterator<Object> objectIterator = linkedList.descendingIterator();
while (objectIterator.hasNext()){
Object next = objectIterator.next();
System.out.println(next);
}
因为get 查询上面remove 方法已经讲过一次node 节点的获取了,这里就不再多聊了。其实不管是迭代器还是下表索引都是使用node 节点的next 属性和prev 属性来实现的,这个还是比较简单的。
修改方法-set方法
这个更简单,通过索引获取到当前节点,然后直接修改node 对象中的item 的属性即可,代码都不用看,就是上面代码的拼接。
总结
本篇还是内容有点多,讲了三个对象的大体方法和流程,对了,这个还要提一句ArrayList 查询的时候使用for 循环即可,因为使用下标索引数组查询较快,不要使用迭代和增强for,因为增强for 的本质还是使用迭代器,而linkedList 使用迭代器查询或增强for 更佳,因为可以直接根据节点对象的next 属性获取下个节点对象,不用再使用二分查询之类的,迭代器会更加快速。
那么jdk 源码分析的第一篇就结束了,后面会分析一下HashMap、Synchronized还有ConcurrentHashMap,这三个都比较复杂,都是单章,有需要的小伙伴可以根据下面的链接跳转。
附录JDK 源码分析系列文章
| 时间 | 文章 |
|---|---|
| 2022-04-25 | Object、ArrayList以及LinkedList源码分析 |
| 2022-04-27 | HsahMap的面试详解及源码分析 |