7月5日,CLUE社区发布首个中文通用大模型开放域多轮测评基准SuperCLUE-Open,A Multi-turn Open Domain Benchmark for Foundation Models in Chinese。在SuperCLUE-Opt(客观)、SuperCLUE-LYB琅琊榜(开放域众包匿名对战)两个基准之外,进一步丰富大模型评测维度,增加对开放域主观题、多轮能力的评测,形成相对完整的SuperCLUE通用大模型综合性三大基准。SuperCLUE 综合性三大基准榜单: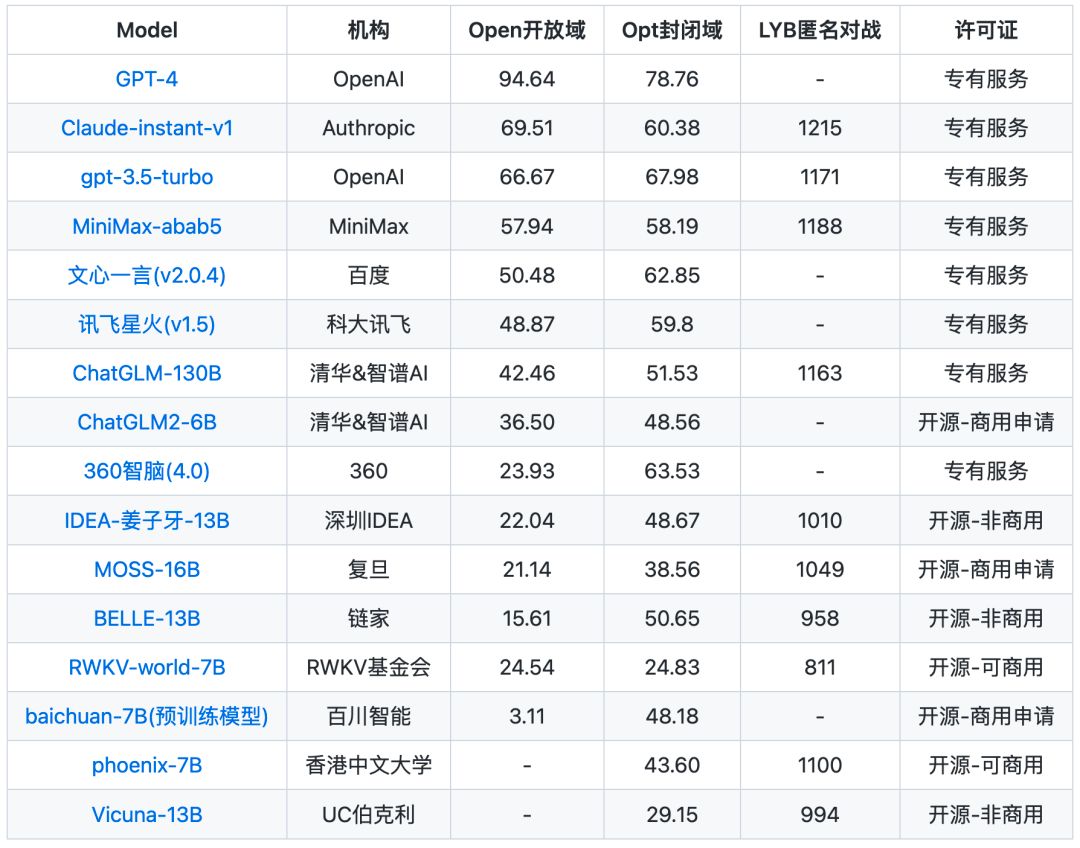 注:以上分数截至2023年7月5日
注:以上分数截至2023年7月5日

SuperCLUE-Open开放域多轮测评模型排行榜: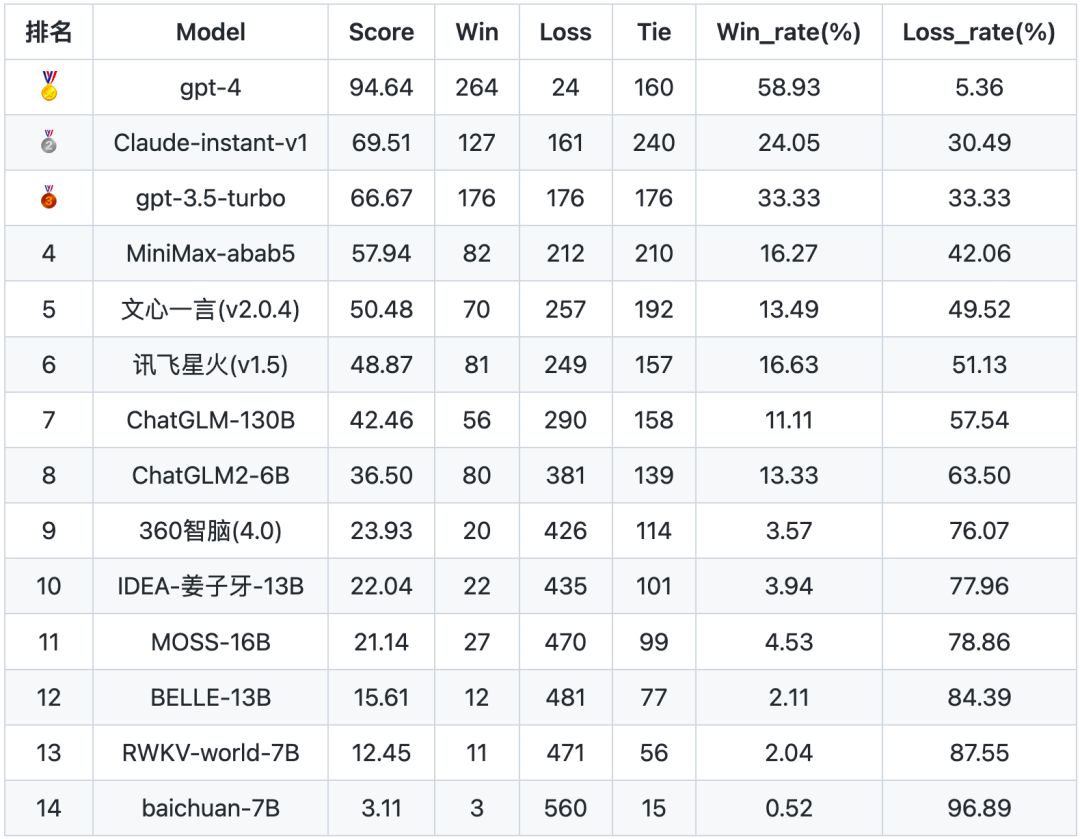
注:Score分数,是模型的胜率加上平局率之和,即(win+tie)/(win+tie+loss)*100。
SuperCLUE-Open各能力分数: 
注:胜和率,是模型的胜率加上平局率之和,即(win+tie)/(win+tie+loss)*100。
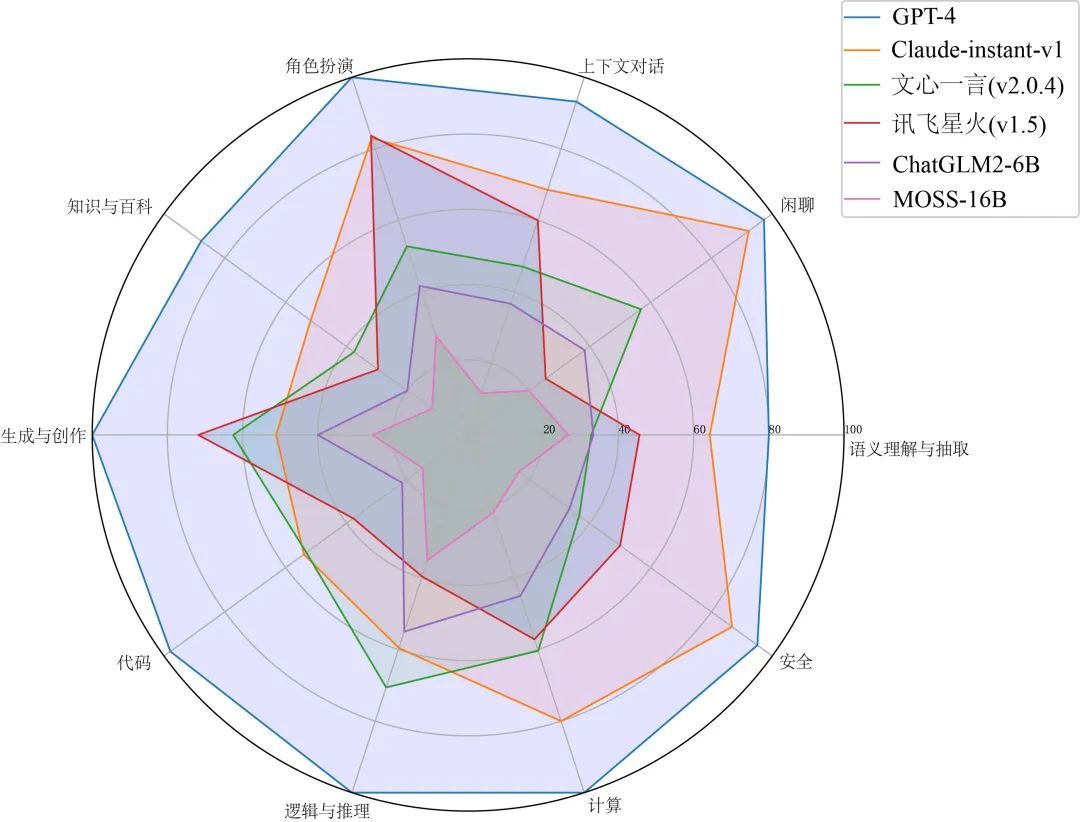
(代表性模型的各个能力分布视图)
SuperCLUE认为榜上有名的都是英雄。温馨提醒,此榜单仅用于学术研究,不作为投资建议。
排行榜会定期更新;

SuperCLUE-Open是什么?
中文通用大模型开放域多轮测评基准(SuperCLUE-Open),是一个多轮开放域的中文模型评测基准,包括1200个高质量多轮问题,用于评估中文大模型对话能力和遵循指令的能力。
SuperCLUE-Open包括一些常用的使用场景和一些挑战性的指令用于区分不同的模型。它考察了模型的十大能力,包括:语义理解与抽取,闲聊,上下文对话,角色扮演,知识与百科,生成与创作,代码,逻辑与推理,计算,代码和安全。每个子能力有六十道题目,每个题目包括两轮问题。
--样例
SuperCLUE-Open为什么发起?
当前已经有一些评价中文大模型的基准,如C-Eval, MMCU,但是这些基准通常不太擅长评估大模型的人类偏好。传统的基准通常以封闭式问题形式进行测试,要求模型输出简要的结论(如多项选择),但是它们不能很好的反映大模型的典型使用场景(如生成、创作和提供想法)。
当前也刚刚出现一些英文模型基准,如加州伯克利的MT-bench,斯坦福大学的Alpaca-Eval,可以用于评估开放域问题,但是这些基准通常测试英文模型,中文的代表性专有服务和开源模型总体上无法进行有效评估。
为了解决以上问题,丰富中文模型评估的准确性,我们发布了SuperCLUE-Open与SuperCLUE-LYB琅琊榜:
SuperCLUE-Open:是一个有挑战的多轮对话开放域测试集,用于评估中文大模型多轮对话、主观题和遵循指令的能力。
SuperCLUE-LYB:SuperCLUE琅琊榜是一个众包匿名对战平台,用户问自己感兴趣的问题,并且投票他们喜欢的答案。
这两个基准设计的首要度量标准是人类的偏好。

SuperCLUE-Open是如何评测模型的?
针对中文大模型的人类偏好能力,可以通过人工进行评估,但是它一般时间周期比较长、并且成本高。国际上已经开始有一些自动化模型评估的方式。
比如加州伯克利的MT-bench,斯坦福大学的Alpaca-Eval进行了比较系统的自动化评估。这里面存在对比模型时模型位置、生成答案的长度、模型对数学推理的评估能力有限的问题。借鉴上面两个工作的经验,我们也进行了针对性的处理,减少这些方面的问题。正如这两个工作提到的,GPT-4的评估可以实现和人类评估高达80-90%的一致性,这充分的说明了自动化评估的潜力。我们的评估通过使用超级模型作为评判官,使用一个待评估模型与一个基准模型进行对比,需要让模型选出哪个模型更好。答案可以是,A模型好,B模型好,或平局。评估的标准,是要求超级模型作为一个公证的评估者,评估模型的质量。回答的质量包括回答有针对性、准确和全面,并且可以对多轮能力进行评测。

多轮对话样例
因此,我们对14个模型,针对10项能力,进行了全面的评估。我们的基准可以清晰的区分模型在不同能力上的表现。特别是一些国际专有服务gpt-4、gpt-3.5和Claude, 相比国内开源模型ChatGM2-6B, MOSS-16B有明显的效果差异。并且从相关性分析中可以看到SuperCLUE-Open与SuperCLUE-Opt具有较高的一致性(Pearson/Spearman相关性系数0.78--0.82)
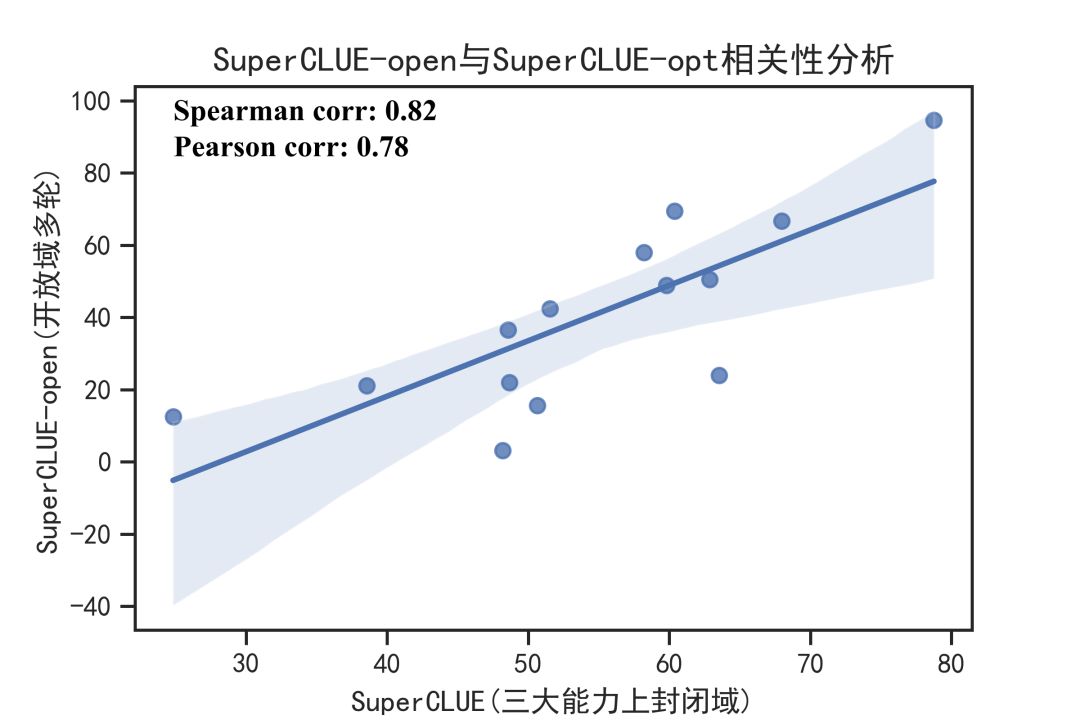
SuperCLUE-Open的下一步工作
- 添加SuperCLUE-open与人类测评的一致性分析
- 扩充测试集规模
加入更多中文大模型
与SuperCLUE相关的其他工作
- 论文:Judging LLM-as-a-judge with MT-Bench and Chatbot Arena;
文章:Chatbot Arena Leaderboard Week 8: Introducing MT-Bench and Vicuna-33B;
相关项目地址:Alpaca_Eval: A validated automatic evaluator for instruction-following language models. High-quality, cheap, and fast;
相关排行榜:AlpacaEval Leaderboard;
致谢
本基准的成功运行离不开FastChat项目在源代码方面的大力支持,在此十分感谢Large Model Systems Organization(LMSYS ORG)和FastChat。
说明
以上是转载SuperCLUE的专业文章,不定期分享行业资讯,关注、私信可以免费获取GPT学习资料和Midjourney AI绘画学习资料和GoGPT.VIP使用教程;
搜 AI创新工坊 GOGPT,拥抱AI、拥抱GPT、拥抱美好未来!

--