导读
Fine-tune 是一种能够以成本效益的方式调整预训练 LLM 的技巧。本文主要比较了用于最新的开源 LLM Falcon 的不同参数高效微调方法,并为大家介绍如何使用单个 GPU 并在一天内对开源的大语言模型 Falcon 进行微调。
为什么要进行微调?
众所周知,ChatGPT,很强!或者很多人都有个疑问,为什么我们还要大费周章去微调?
闭源,或者网上流行的一句话:OpenAI 并不 open。诸如 OpenAI 的 ChatGPT 和 Google 的 Bard,是不能被轻松定制的,这使它们在许多用例中变得不那么吸引人。然而,幸运的是,我们在最近几个月看到了大量的开源 LLM 涌现出来(当然这还得感谢 Meta 一不小心就把 LLaMA 泄露出来,这才有了后续一系列的羊驼家族!)。另外,尽管 ChatGPT 和 Bard 具备很强大的上下文学习能力,但微调模型在特定任务上的表现一般会优于通用模型,这可能就是私有数据集的魔力吧!
预训练并微调 LLMs
在我们深入了解 LLM 微调的细节之前,让我们简要回顾一下一般情况下如何训练 LLM。LLM 的训练分为两个阶段:
第一阶段是昂贵的预训练步骤,通过在一个包含数万亿个词的大规模无标签数据集上对模型进行训练。由此产生的模型通常被称为基础模型(foundation models),因为它们具有通用能力,并可以用于各种下游任务的适应。一个经典的预训练模型的例子是GPT-3。
第二阶段是对这样一个基础模型进行微调。这通常包括将预训练模型训练成遵循指令或执行其他特定目标任务(例如情感分类)。ChatGPT(最初是 GPT-3 基础模型的微调版本)就是一个被微调为遵循指令的典型例子。使用本文中介绍的参数高效微调方法,可以在单个 GPU 上用 1 小时而不是 6 个 GPU 上的一天内对 LLM 进行微调。
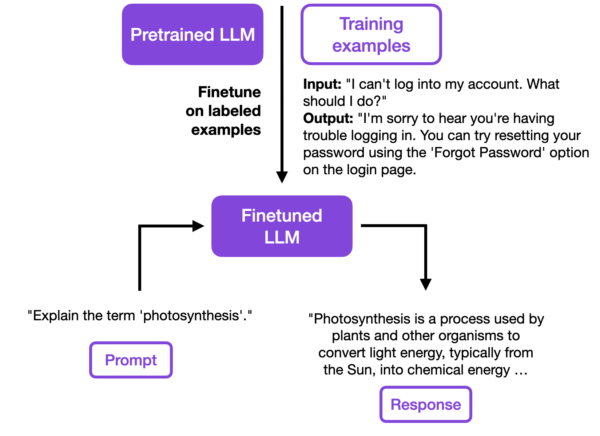
此外,微调还允许模型更好地适应原始训练数据中未充分代表的特定领域或文本类型。例如,如果我们希望模型理解和生成医学文本,可以对模型进行医学文献方面的微调。想必大家伙最近也见到过许多的中医问诊 LLM。
开源 LLMs 和 Falcon 架构
对开源 LLM 进行微调具有多个优势,例如更好的定制能力和任务性能。此外,开源 LLM 对于研究人员来说是一个优秀的测试平台,可以用来开发新技术。但是如果我们今天采用一个开源模型,应该选择哪个呢?
截至目前,由科技创新研究院开发的 Falcon 模型是当前表现最好的开源 LLM。在本文中,我们将学习如何高效地对其进行微调,例如在私有数据集上进行微调。
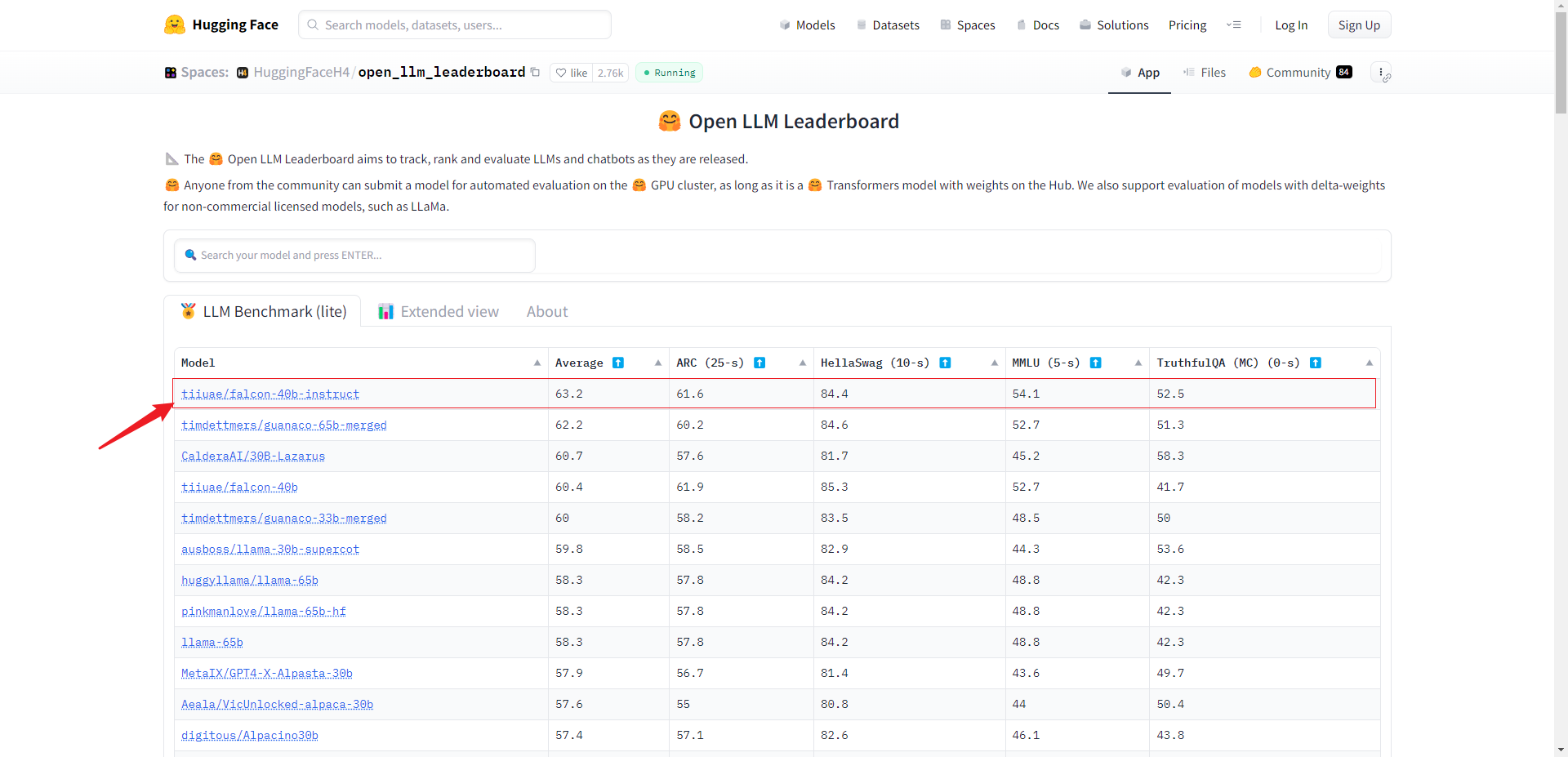
Falcon LLM 有不同规模的模型:截至目前,有一个70亿参数的变体(Falcon 7B)和一个400亿参数的变体(Falcon 40B)。此外,每个规模都有基础模型(Falcon 7B 和 Falcon 40B)和对应的指令微调模型(Falcon 7B-instruct和 Falcon 40B-instruct)。指令微调模型已经针对通用任务进行了微调(类似于ChatGPT),但如果需要的话,它们可以进一步在特定领域的数据上进行微调。(注:还有一个180B版本正在开发中)
值得高兴的是,
Falcon模型是完全开源的,并采用宽松的Apache许可证第 2.0 版发布,即允许无限制的商业使用,例如与PyTorch Lightning、TensorFlow和OpenOffice使用相同的许可证。
Falcon 与 GPT 或者 LLaMA 等 LLMs 的区别?
除了在 OpenLLM 排行榜上的更好性能之外,如上所述,Falcon、LLaMA 和 GPT 之间也存在一些细小的架构差异。LLaMA(Touvron等人,2023年)引入了以下架构改进,这很可能是 LLaMA 相对于 GPT-3(Brown等人,2020年)表现更好的原因:
-
类似于 GPT-3,LLaMA 将层归一化放置在自注意力块之前;然而,研究人员选择了最近的 RMSNorm(Zhang和Sennrich,2019年)变体,而不是像 GPT-3 中那样使用原始的 LayerNorm(Ba等人,2016年)。
-
LLaMA借鉴了PaLM(Chowdhery等人,2022年)中使用 SwiGLU(Shazeer,2020年)激活的思想,而非 GPT-3 中直接采用 ReLU。
-
最后,LLaMA 将 GPT-3 中使用的绝对位置嵌入替换为旋转位置嵌入(RoPE)(Su等人,2022年),类似于 GPTNeo(Black等人,2022年)。
因此,根据目前已知的信息,Falcon 中也采用了与 LLaMA(和GPTNeo)相同的 RoPE 嵌入,但在 Multiquery attention(Shazeer,2019年)上与 GPT-3 具有相同的架构。
Multiquery attention 是一个概念,通过共享相同的键和值张量,以提高效率,在不同的注意力头之间共享,如下所示的多头注意力块:
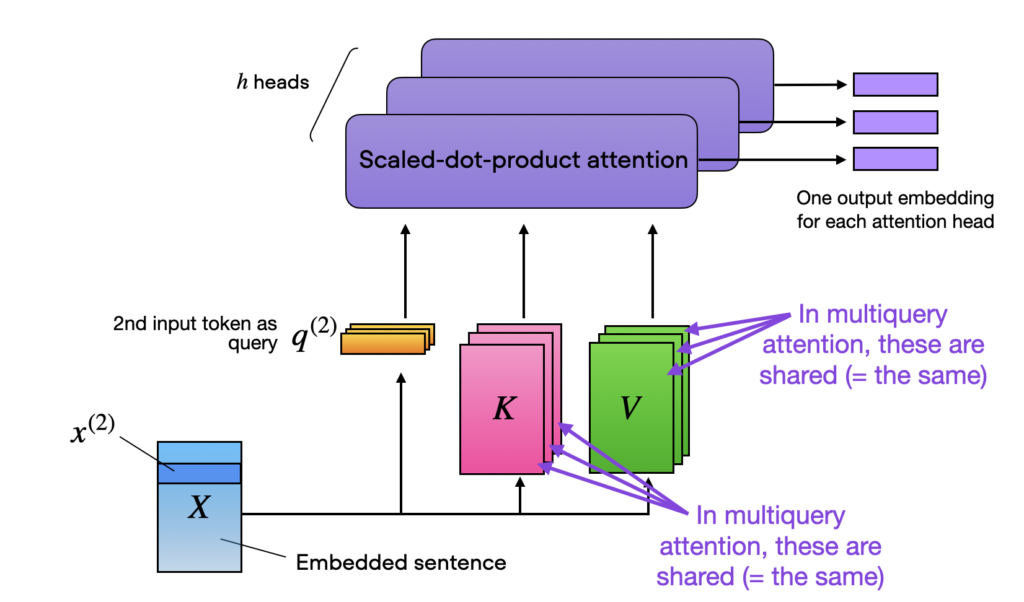
此外,根据披露的训练数据信息显示,Falcon 40-B 是在 1000B 个标记上进行训练的,其中82%的标记来自 RefinedWeb 语料库,其余的标记来自书籍、论文、对话(Reddit、StackOverflow和HackerNews)以及代码仓库如github。
虽然 Falcon 的官方论文尚未发布,但相关论文《The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only》中提供了证据,表明取得良好效果的关键还是在于构建高质量的数据集。
这一点与笔者的认知高度一致,就是大部分 LLMs 架构差异其实并不大,关键在于训练技巧和高质量的数据集,数据的质量远远大于数量。
参数高效的微调方法
本文的其余部分将主要关注 Falcon 7B,这使我们能够在单个 GPU 上对模型进行微调。Falcon 7B 是目前被认为是同等规模类别中最好的开源 LLM。(但其实本文其余部分提供的相同代码也适用于更大的40B变体)

此外,感兴趣的同学可以参考《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》这篇综述,论文里面提供了许多参数高效微调的范式。微调的方式有很多种,但更最重要的问题是,在实践中哪些方法最值得采用?让我们从性能基准开始,然后深入探讨这些不同方法的工作原理。
性能比较
为了在这个性能基准中使用一个常见的数据集,我们将考虑用于指令微调的流行数据集Alpaca,它包含 52,000 个指令微调示例。其结构如下:
指令: “给出三个保持健康的建议。”
输出: 1.均衡饮食,确保摄入足够的水果和蔬菜。2.定期锻炼,保持身体活跃和强壮。3.获得足够的睡眠并保持稳定的睡眠时间表。
目前有三种主流的方法:
-
低秩适应(Low-Rank Adaptation,LoRA)(Hu等,2021年);
-
LLaMA适配器(LLaMA Adapter)(Zhang等,2023年);
-
LLaMA适配器v2(LLaMA-Adapter v2)(Gao等,2023年)。
这里,我们可以使用 LLaMA-Adapter 方法进行微调。大家不要被它的名字误导,虽然叫 LLaMA 适配器,但这些适配器方法不仅适用于 LLaMA 架构,同样可以用于其他 LLMs 的微调。
准备模型和数据集
对于这个基准测试,我们建议使用Lit-Parrot开源库,因为它直接提供了各种 LLM 的高效实现来进行训练和便捷使用。
首先,我们将这个仓库 git 下来,然后下载对应的基础模型,这里整个小一点的:
python scripts/download.py --repo_id tiiuae/falcon-7b
这个模型大约需要预留 20 Gb 的空间。
其次,我们调整下模型权重格式:
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7b
紧接着,我们把数据集 download 下来,这里直接用 Alpaca 就行了:
python scripts/prepare_alpaca.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/
运行代码
Now,我们便可以直接运行 Falcon 7B 模型的微调脚本了。作为比较,我们展示四种不同的方法。目前,我们将专注于微调结果。稍后在本文中,我们将具体讨论这些方法的工作原理。
- Adapter
python finetune/adapter.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/
- Adapter v2
python finetune/adapter_v2.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/
- LoRA
python finetune/lora.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/
- Full finetuning
python finetune/full.py --checkpoint_dir checkpoints/tiiuae/falcon-7b/
现在让我们一起看下耗时:
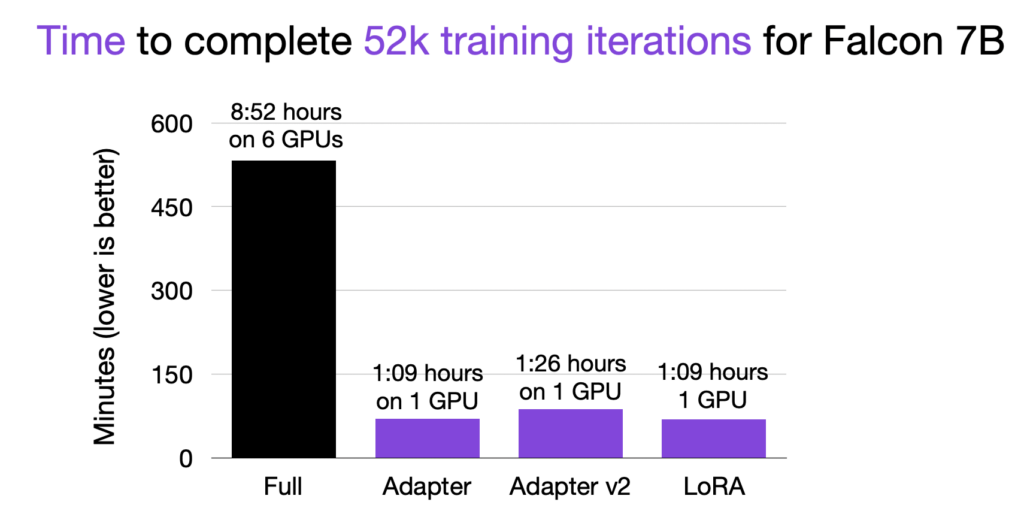
如上图所示,使用参数高效的微调方法比微调所有层(“full”)快约 9 倍!此外,由于内存限制,微调所有层需要 6 个GPU,而适配器方法和 LoRA 方法仅需要单个 GPU 。
因此,关于 GPU 内存要求,峰值内存要求如下图所示:

如上,对于 Falcon 7B 的全参数微调,每个 GPU 需要约 40 GB的内存(还是使用 DeepSpeed 进行张量分片之后的~~~)。因此实际总共需要 240 GB的内存。相比之下,参数高效的微调方法只需要约 16 GB的RAM,这使得用户甚至可以在单个消费级 GPU 上微调这些模型。
顺便提一下,需要更新的参数数量直接影响内存要求:
| 模型 | 参数数量 |
|---|---|
| 全参数微调 | 7,217,189,760 |
| Adapter | 1,365,330 |
| Adapter v2 | 3,839,186 |
| LoRA | 3,506,176 |
是的,你没看错,全参数微调(更新所有层)需要更新的参数数量是 Adapter v2 或 LoRA 方法的 2000 倍,而后者的建模性能却与全层微调相等(有时甚至更好)。
关于推理速度,我们可以简单看下如下的性能数据:
| 模型 | 每秒标记数量 | 内存使用 |
|---|---|---|
| LoRA | 21.33 | 14.59 GB |
| Adapter | 26.22 | 14.59 GB |
| Adapter v2 | 24.73 | 14.59 GB |
超参数设置
如果您想复现上述结果,以下是建议的超参数设置:
- 采用
bfloat16混合精度训练,以加快训练速度并减少内存需求; - 迭代 52,000 次,刚好与本次基准测试中使用的 Alpaca 数据集大小相对应;
- BatchSize 设置为 128,并采用梯度累积技术。(
gradient accumulation是一种可以在执行权重更新之前将梯度累积在多个较小的批次上。这有助于克服内存限制,并允许使用更大的批次大小进行训练。) - 对于 LoRA,使用了秩为 8,以大致匹配 Adapter v2 额外添加的参数数量。
最后,本文数据是在一张 A100 GPU 上进行训练的。同理, full.py 脚本则需要 6 张 A100 GPU 和 DeepSpeed 的张量分片技术来处理内存需求。大家可以在 GitHub 上找到具有上述设置的修改后的脚本。
附带下测试命令:
python generate/lora.py --checkpoint_dir checkpoints/tiiuae/falcon-7b --lora_path out/lora/alpaca/lit_model_lora_finetuned.pth
技术原理
Adapter
LLaMA-Adapter 方法简单来说,就是在现有的 LLM 中添加了一小部分可训练的张量(参数)。在这种方法中,只有新的参数被训练,原始参数保持不变。这样可以在反向传播过程中节省大量的计算和内存资源。
具体来说,LLaMA-Adapter 方法在嵌入的输入之前添加了可调整的提示张量(前缀)。在 LLaMA-Adapter方法中,这些前缀是在一个嵌入表中学习和维护的,而不是从外部提供。模型中的每个 Transformer 块都有自己独特的学习前缀,可以实现对不同模型层的更具针对性的适应。
此外,LLaMA-Adapter 引入了一个以零初始化的注意力机制,并与门控机制相结合。所谓的零初始化注意力和门控机制的动机是,适配器和前缀调整可能会通过整合随机初始化的张量(前缀提示或适配器层)来破坏预训练 LLM 的语言知识,导致在初始训练阶段出现不稳定的微调和较高的损失值。
LLaMA-Adapter 方法的主要概念如下图所示,在正常 Transformer 块的修改部分以紫色突出显示:
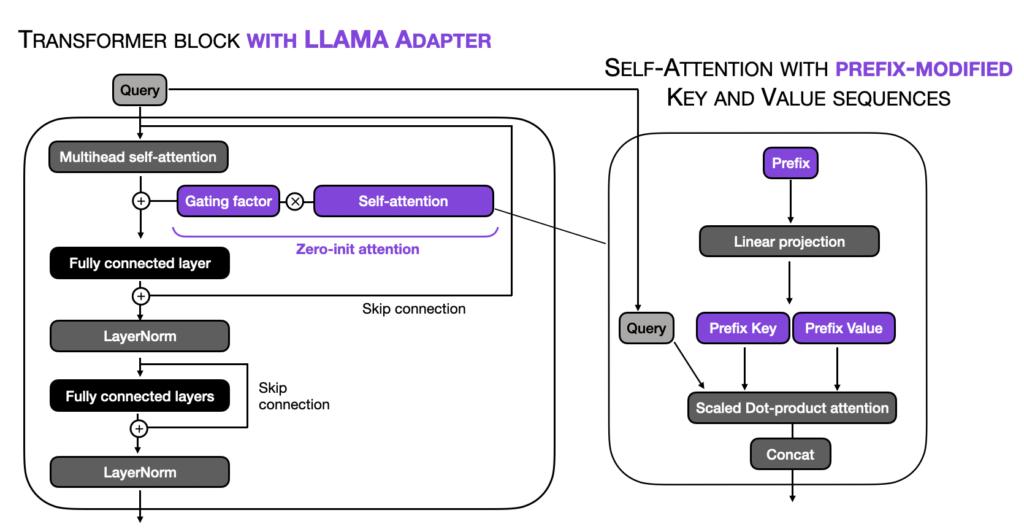
一个关键的想法是添加一小部分可训练的参数。另一个重要的事情要注意的是,这种方法并不限于LLaMA LLMs,这就是为什么我们可以将其用于finetune Falcon模型的原因。
对 LLaMA-Adapter 方法的更多细节感兴趣的同学,可以阅读这篇文章《Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters》。
Adapter v2
LLaMA-Adapter v2 是 LLaMA-Adapter 的进化版,在对 LLMs 进行文本和指令微调时,它增加了可调参数的数量。第一个区别是在全连接(线性)层中添加了偏置单元。由于它只是修改了现有的线性层,从输入权重变为输入权重+偏置,因此对微调和推理性能只有很小的影响。
第二个区别是使上述的 RMSNorm 层可训练。虽然这对训练性能有一定影响,因为需要更新额外的参数,但对推理速度没有影响,因为它并没有向网络中添加任何新的参数。
Low-Rank Adaptation
Low-Rank Adaptation (LoRA)方法与上述的 Adapter 方法其实是类似的,它也是在模型中添加了一小部分可训练的参数,同时保持原始模型参数不变。然而,其基本概念与 LLaMA-Adapter 方法在根本上有很大的区别。简而言之,LoRA 直接将一个权重矩阵分解为两个较小的权重矩阵,如下图所示:

更多技术细节可参考《Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)》
总结
在本文中,我们了解了如何使用 LLaMA-Adapter 方法和 LoRA 在单个 GPU 上对 Falcon 等最先进的开源 LLM 进行微调。通过本文,我们知道传统的全层微调需要耗费 9 个小时,并且至少需要 6 个 A100 GPU,每个 GPU 需要 40 GB 的 RAM。而本文介绍的参数高效微调方法可以在单个 GPU 上将同一模型的微调速度提高 9 倍,且所需 GPU 内存减少了 15 倍。
在实践中,大家可能会想知道如何将这些方法应用于自己的数据集。毕竟,开源 LLM 的优势在于我们可以对其进行微调和定制,以适应我们的目标数据和任务。
实际上,要在自己的数据集上使用任何这些 LLM 和技术,原理很简单,我们只需要确保数据集格式化为标准格式,更详细的说明可以参考 Aniket Maurya 的博文《如何在自定义数据集上像 Finetune GPT 一样微调大型语言模型》。