文章目录
前言
Pandas 是一种用于数据分析的 Python 库,它提供了两个基本的数据结构——Series 和 DataFrame。
1.Series
Series 是一种一维数组,可以存储任意类型的数据 (整数、浮点数、字符串、Python 对象等),并且每个值都有一个索引。索引在 Pandas 中非常重要,它是用来对数据进行标识和访问数据的。Series 对象可以通过传递一个列表或数组创建。例如:
import pandas as pd
data = [1, 2, 3, 4]
s = pd.Series(data)
print(s)
输出结果:
0 1
1 2
2 3
3 4
dtype: int64
Index 对象是 Pandas 中另一个重要的数据结构,它可以用来表示 Series 或 DataFrame 中的行或列的标签。Index 对象是不可变的,因此可以用作字典中的键。Index 对象可以通过传递一个列表或数组创建。例如:
import pandas as pd
data = [1, 2, 3, 4]
index = ['a', 'b', 'c', 'd']
s = pd.Series(data, index=index)
print(s)
输出结果:
a 1
b 2
c 3
d 4
dtype: int64
在上面的例子中,我们使用了一个列表来创建 Series,并将 Index 对象设置为 [‘a’, ‘b’, ‘c’, ‘d’]。这样,我们可以通过这些标签来访问 Series 中的值,例如 s[‘a’] 返回 1。
2.DataFrame
Pandas中的DataFrame是一种二维数组对象,可以存储多种类型的数据,并且可以在每个轴上指定标签。以下是DataFrame 的基本使用:
- 创建DataFrame
可以通过传入一个字典、列表、二维数组或其他数据类型来创建DataFrame。
例如,创建一个包含三个列和四个行的DataFrame:
import pandas as pd
data = {
'name': ['Tom', 'Jack', 'Steve', 'Ricky'],
'age': [28, 34, 29, 42],
'gender': ['M', 'M', 'M', 'F']}
df = pd.DataFrame(data)
print(df)
输出:
name age gender
0 Tom 28 M
1 Jack 34 M
2 Steve 29 M
3 Ricky 42 F
- 查看DataFrame
可以使用head()和tail()方法查看DataFrame的前几行和后几行。
例如,查看DataFrame的前两行:
print(df.head(2))
输出:
name age gender
0 Tom 28 M
1 Jack 34 M
可以使用shape属性查看DataFrame的维度大小:
print(df.shape)
输出:
(4, 3)
- 索引和选择
可以使用列名称进行列的选择,并且可以使用切片来选择行。
例如,选择name列:
print(df['name'])
输出:
0 Tom
1 Jack
2 Steve
3 Ricky
Name: name, dtype: object
选择前两行:
print(df[:2])
输出:
name age gender
0 Tom 28 M
1 Jack 34 M
- 修改DataFrame
可以通过赋值的方式修改DataFrame中的值。
例如,将第一行的年龄改为30:
df.loc[0, 'age'] = 30
print(df)
输出:
name age gender
0 Tom 30 M
1 Jack 34 M
2 Steve 29 M
3 Ricky 42 F
- 删除DataFrame
可以使用drop()方法删除DataFrame中的行或列。
例如,删除gender列:
df = df.drop('gender', axis=1)
print(df)
输出:
name age
0 Tom 30
1 Jack 34
2 Steve 29
3 Ricky 42
以上是Pandas中DataFrame的基本使用,很多高级用法和技巧需要结合实际业务场景来使用。
一、Pandas 数据分析DataFrames
1.DataFrames原理分析
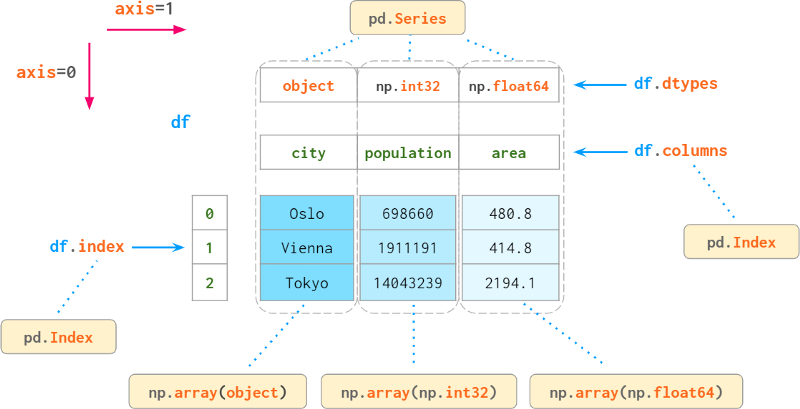
Pandas的主要数据结构是DataFrame。它将一个二维数组与它的行和列的标签捆绑在一起。它由一系列对象组成(具有共享索引),每个对象表示一列,可能具有不同的dtype。
2.读写CSV文件

因为CSV没有严格的规范,所以有时需要一些试错才能正确地阅读它。read_csv最酷的地方在于它会自动检测很多东西:
-
列名和类型
-
布尔值的表示
-
缺失值的表示等。
与其他自动化一样,你最好确保它做了正确的事情。如果在Jupyter单元中简单地编写df的结果碰巧太长(或太不完整),您可以尝试以下操作:
-
df.head(5)或df[:5]显示前5行
-
df.dtypes返回列的类型
-
df.shape返回行数和列数
-
Df.info()汇总所有相关信息
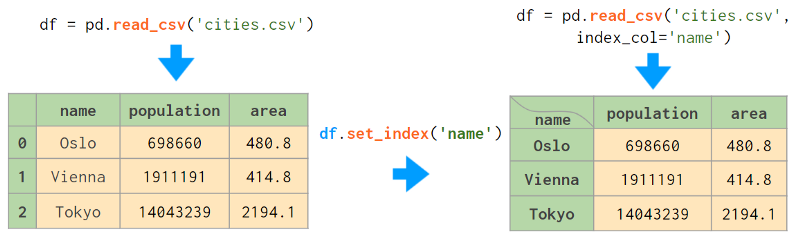
将一列或几列设置为索引是一个好主意。下图展示了这个过程:
Index在Pandas中有很多用途:
-
算术运算按索引对齐
-
它使按该列进行的查找更快,等等。
所有这些都是以较高的内存消耗和不太明显的语法为代价的。
3.构建DataFrame
另一种选择是从内存中已经存储的数据中构建一个dataframe。它的构造函数非常全能,可以转换(或包装)任何类型的数据:

在第一种情况下,在没有行标签的情况下,Pandas用连续的整数标记行。在第二种情况下,它对行和列都进行了相同的操作。为Pandas提供列的名称总是一个好主意,而不是整数标签(使用columns参数),有时也可以提供行(使用index参数,尽管rows听起来可能更直观)。这张图片会有帮助:

不幸的是,无法在DataFrame构造函数中为索引列设置名称,所以唯一的选择是手动指定,例如,df.index.name = ‘城市名称’
下一种方法是使用NumPy向量组成的字典或二维NumPy数组构造一个DataFrame:
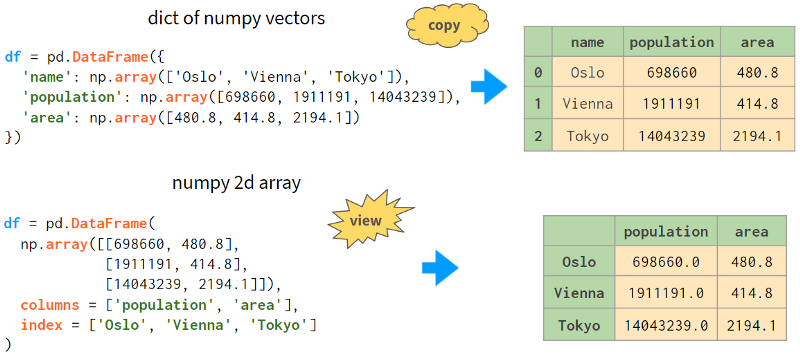
请注意,在第二种情况下,人口数量的值被转换为浮点数。实际上,它在之前的构建NumPy数组时就发生过。这里需要注意的另一件事是,从2D NumPy数组构建dataframe默认是视图。这意味着改变原始数组中的值会改变dataframe,反之亦然。另外,它节省了内存。
第一种情况(NumPy向量组成的字典)也可以启用这种模式,设置copy=False即可。不过,它非常脆弱。简单的操作就可以把它变成副本而不需要通知。
另外两个(不太有用的)创建DataFrame的选项是:
-
从一个dict列表(其中每个dict表示一行,其键是列名,其值是相应的单元格值)
-
来自由Series组成的dict(其中每个Series表示一列;默认情况下,可以让它返回一个copy=False的视图)。
如果你“动态”注册流数据,最好的选择是使用列表的dict或列表的列表,因为Python会透明地在列表末尾预分配空间,以便快速追加。NumPy数组和Pandas dataframes都不能做到这一点。另一种可能性(如果你事先知道行数)是用DataFrame(np.zeros)之类的东西手动预分配内存。
4.DataFrames的基本操作
DataFrame最好的地方(在我看来)是你可以:
轻松访问其列,如d.area返回列值(或者df[’ Area ']——适用于包含空格的列名)
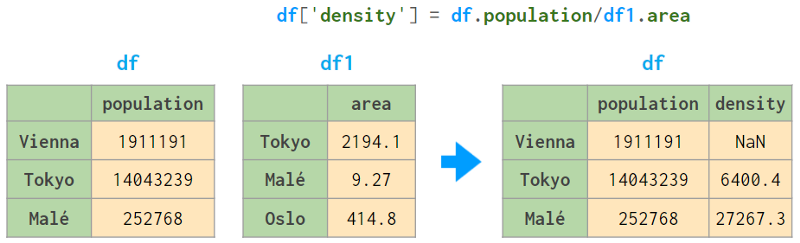
将列作为自变量进行操作,例如使用afterdf. population /= 10**6人口以百万计存储,下面的命令根据现有列中的值创建一个名为density的新列。更多信息见下图:

注意,创建新列时,即使列名中不包含空格,也必须使用方括号。
此外,你可以对不同dataframe中的列使用算术操作,只要它们的行具有有意义的标签,如下所示:
5.索引DataFrames
正如我们在本系列中已经看到的,普通的方括号不足以满足索引的所有需求。你不能通过名称访问行,不能通过位置索引访问不相交的行,你甚至不能引用单个单元格,因为df[‘x’, ‘y’]是为多索引保留的!
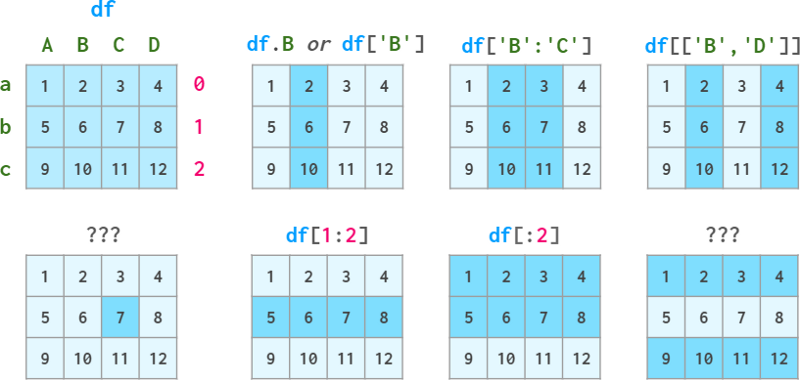
为了满足这些需求,dataframes,就像series一样,有两种可选的索引模式:按标签索引的loc和按位置索引的iloc。
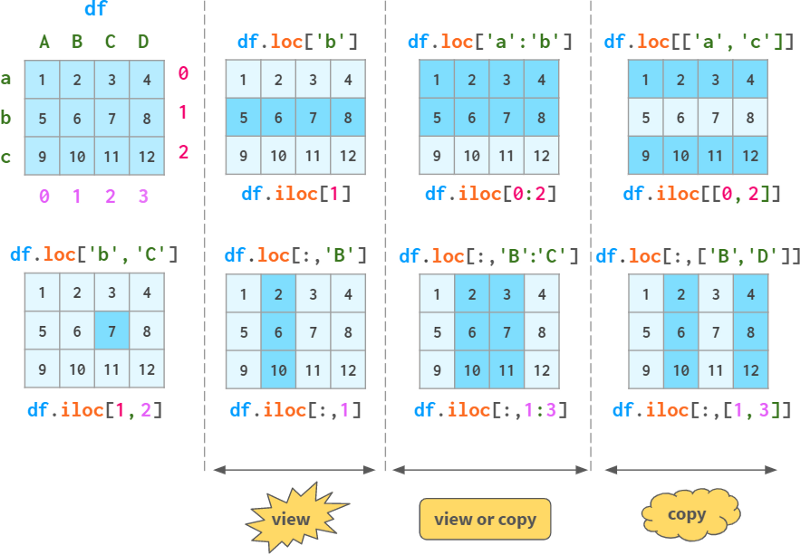
在Pandas中,引用多行/多列是一个副本,而不是视图。但它是一种特殊的复制,允许赋值作为一个整体:
-
df.loc[‘a’]=10 works (一行作为一个整体是一个可写的)
-
df.loc[‘a’][‘A’]=10 works (元素访问传播到原始df)
-
df.loc[‘a’:’b’] = 10 works (assigning to a subar将整个作品赋值给一个子数组)
-
df.loc[‘a’:’b’][‘A’] = 10 doesn’t (对其元素赋值不会).
在最后一种情况下,该值只会被设置在切片的副本上,而不会反映在原始df上(会相应地显示一个警告)。
根据不同的背景,有不同的解决方案:
- 你想要改变原始的df。然后使用df。loc[’ a’: ’ b ‘, ’ a’] = 10
- 你故意创建了一个副本,然后想要处理这个副本:df1 = df.loc[’ a ': ’ b ‘];df1[’ A ‘]=10 #
SettingWithCopy warning要在这种情况下消除警告,请使其成为一个真正的副本:df1 = df.loc[’ A ':
’ b '].copy();df1 [A] = 10
Pandas还支持一种方便的NumPy语法来进行布尔索引。

当使用多个条件时,必须将它们括起来,如下所示:

当你期望返回一个值时,需要特别注意。

因为可能有多行匹配条件,所以loc返回一个序列。要从中得到标量值,你可以使用:
- float(s)或更通用的s.e item(),除非序列中只有一个值,否则都会引发ValueError
S.iloc[0],仅在没有找到时引发异常;此外,它是唯一支持赋值的函数:df[…].Iloc[0] = 100,但当你想修改所有匹配时,肯定不需要它:df[…]= 100。
或者,你可以使用基于字符串的查询:
- df.query (’ name = =“Vienna”)
df.query(‘population>1e6 and area<1000’)它们更短,适合多索引,并且逻辑操作符优先于比较操作符(=需要更少的括号),但它们只能按行过滤,并且不能通过它们修改Dataframe。
几个第三方库允许你使用SQL语法直接查询dataframe (duckdb),或者通过将dataframe复制到SQLite并将结果包装回Pandas objects (pandasql)来间接查询dataframe。不出所料,直接法更快。
6.DataFrame算术
你可以对dataframes、series和它们的组合应用普通操作,如加、减、乘、除、求模、幂等。
所有的算术运算都是根据行标签和列标签对齐的:
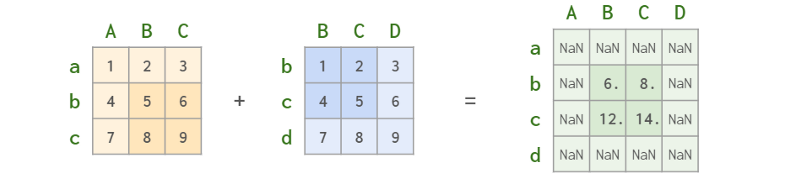
在dataframe和Series之间的混合操作中,Series(天知道为什么)表现得(和广播)像一个行向量,并相应地对齐:

可能是为了与列表和一维NumPy向量保持一致(它们不按标签对齐,并被认为是一个简单的二维NumPy数组的DataFrame):

因此,在不太幸运(也是最常见的!)的情况下,将一个dataframe除以列向量序列,你必须使用方法而不是操作符,如下所示:

由于这个有问题的决定,每当你需要在dataframe和列式序列之间执行混合操作时,你必须在文档中查找它(或记住它):

7.结合DataFrames
Pandas有三个函数,concat、merge和join,它们做同样的事情:将来自多个dataframe的信息合并为一个。但是每个工具的实现方式都略有不同,因为它们是为不同的用例量身定制的。
7.1 垂直叠加
这可能是将两个或多个dataframe合并为一个的最简单方法:您获取第一个dataframe中的行,并将第二个dataframe中的行追加到底部。为了使其工作,这两个dataframe需要(大致)具有相同的列。这类似于NumPy中的vstack,正如你在图像中所看到的:
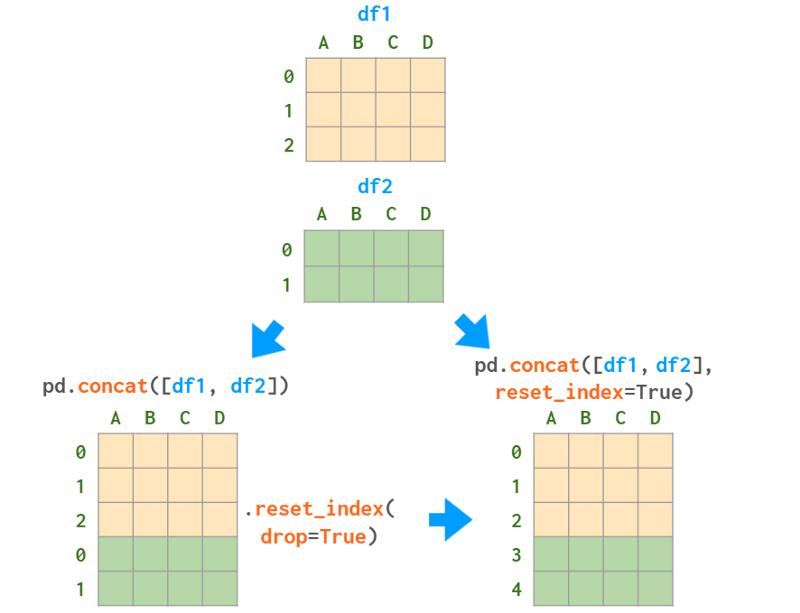
索引中有重复的值是不好的。你可能会遇到各种各样的问题(参见下面的drop示例)。即使你不关心索引,也要尽量避免出现重复的值:
-
要么使用reset_index=True参数
-
调用df.reset_index(drop=True)将行从0重新索引到len(df)-1,
-
使用keys参数可以解决MultiIndex的二义性(见下文)。
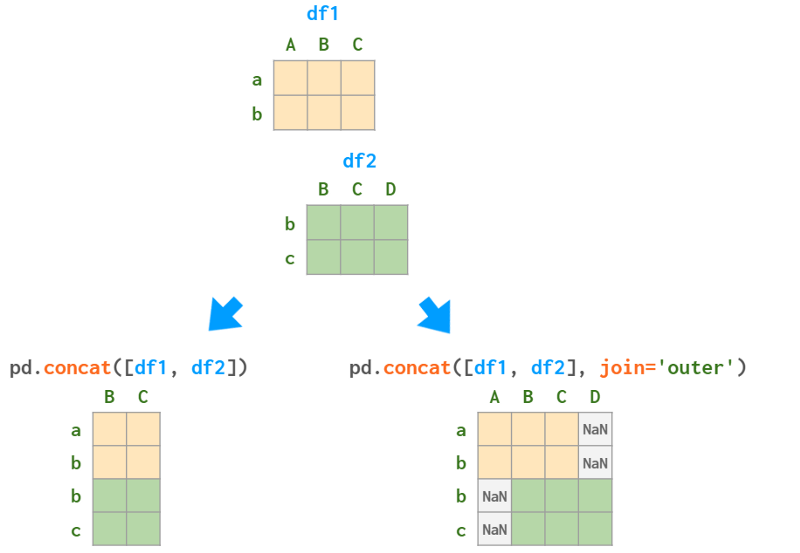
如果dataframe的列不能完美匹配(不同的顺序在这里不计算在内),Pandas可以取列的交集(默认值kind='inner ')或插入nan来标记缺失值(kind=‘outer’):
7.2 水平叠加
concat也可以执行“水平”堆叠(类似于NumPy中的hstack):
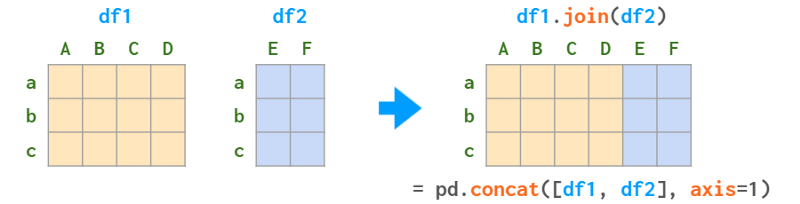
join比concat更可配置:特别是,它有五种连接模式,而concat只有两种。详情请参阅下面的“1:1关系连接”部分。
7.3 基于多指数的数据叠加
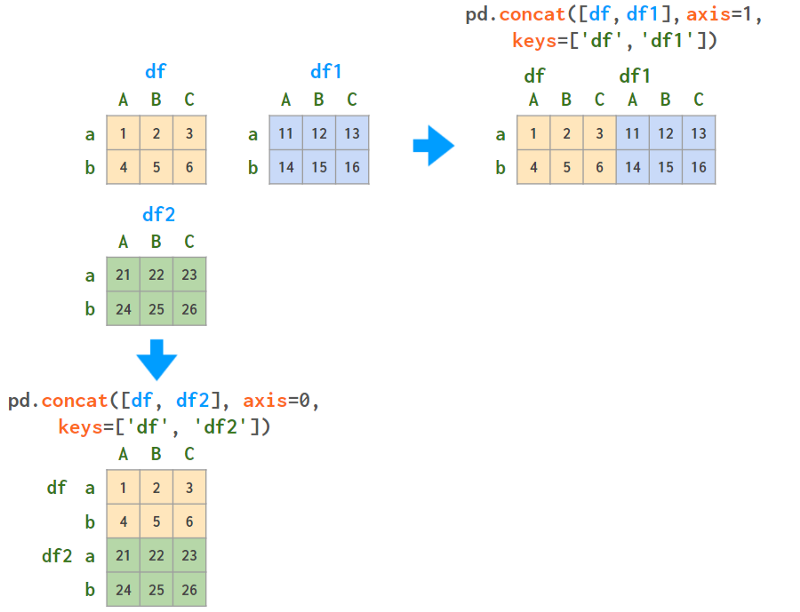
如果行标签和列标签一致,concat可以执行与垂直堆叠类似的多索引(就像NumPy中的dstack):
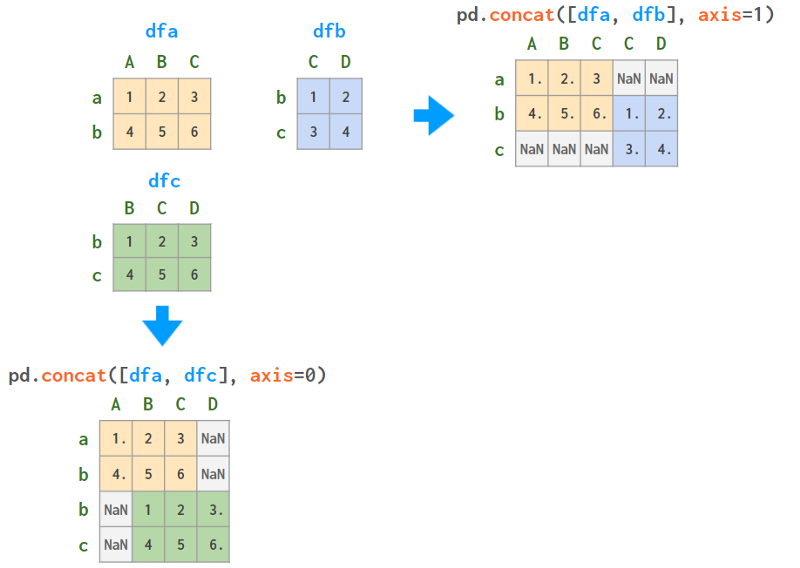
如果行和/或列部分重叠,Pandas将相应地对齐名称,这很可能不是你想要的。下面的图表可以帮助你将这个过程可视化:
一般来说,如果标签重叠,这意味着dataframe在某种程度上彼此相关,实体之间的关系最好使用关系数据库的术语来描述。
7.4 连接查询
1、1:1 连接的关系

当同一组对象的信息存储在几个不同的DataFrame中时,你希望将它们合并为一个DataFrame。
如果要合并的列不在索引中,则使用merge。
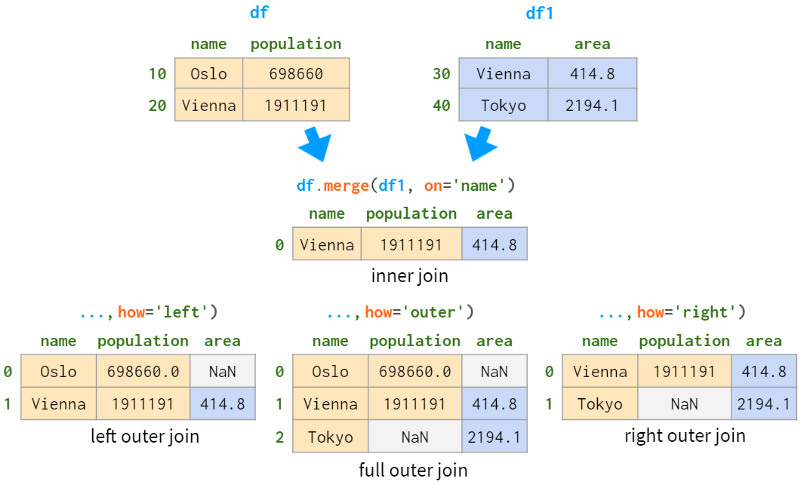
它所做的第一件事是丢弃索引中的任何内容。然后执行联结操作。最后,将结果从0重新编号为n-1。
如果列已经在索引中,则可以使用join(这只是merge的别名,将left_index或right_index设置为True,并设置不同的默认值)。

从这个简化的例子中可以看出(参见上面的全外连接),与关系型数据库相比,Pandas对行顺序的处理相当轻松。左外联结和右外联结比内外联结更容易预测(至少在需要合并的列中有重复值之前是这样)。因此,如果你想保证行顺序,就必须显式地对结果进行排序。
2、1:n 连接的关系

这是数据库设计中使用最广泛的关系,表A中的一行(例如“State”)可以与表B中的几行(例如城市)相关联,但表B中的每一行只能与表A中的一行相关联(即一个城市只能处于一种状态,但一个状态由多个城市组成)。
就像1:1关系一样,在Pandas中连接一对1:n相关的表,你有两种选择。如果要合并的列或者不在索引中,并且可以丢弃碰巧在两张表的索引中都存在的列,则使用merge。下面的例子会有所帮助:
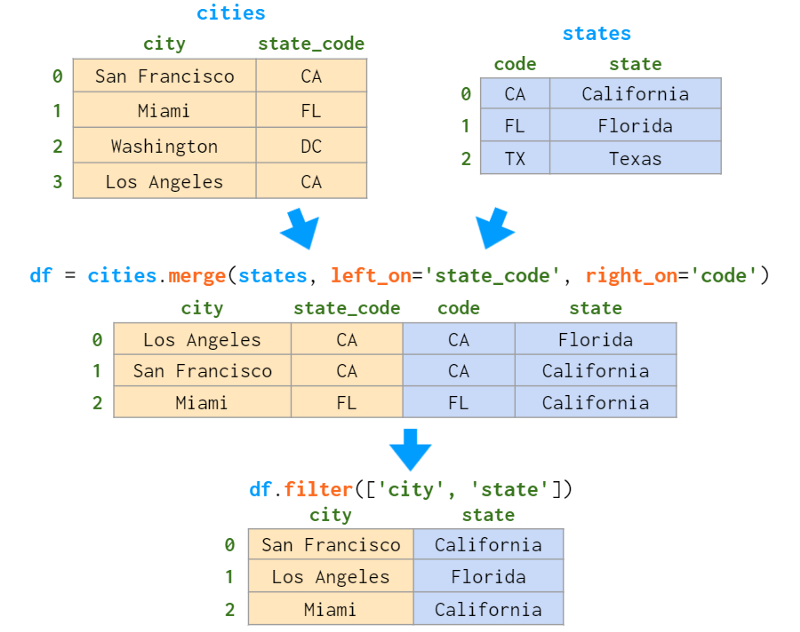
正如我们已经看到的,merge对行顺序的处理没有Postgres严格:所有声明的语句,保留的键顺序只适用于left_index=True和/或right_index=True(这就是join的别名),并且只在要合并的列中没有重复值的情况下。这就是为什么join有一个sort参数。
现在,如果要合并的列已经在右侧DataFrame的索引中,可以使用join(或者merge with right_index=True,这是完全相同的事情):
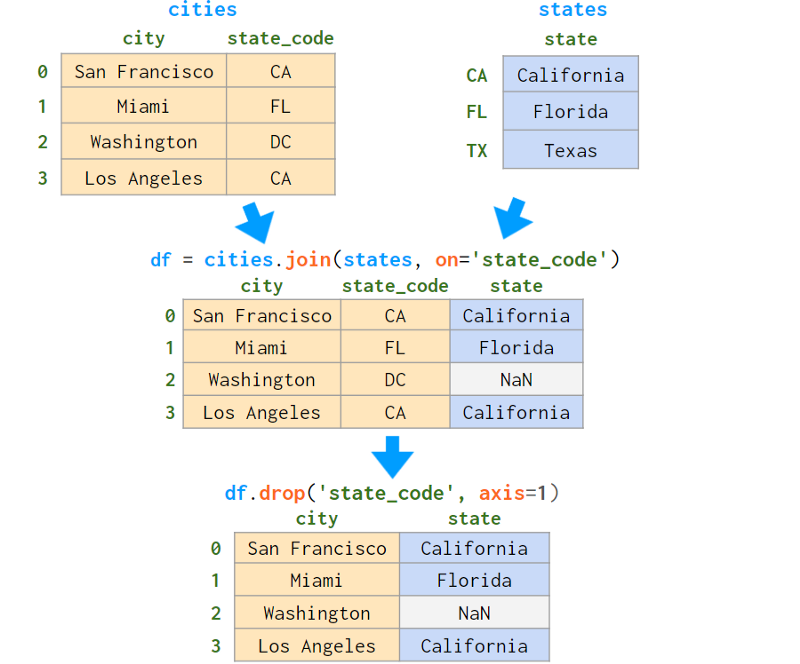
这次Pandas保留了左DataFrame的索引值和行顺序。
注意:注意,如果第二个表有重复的索引值,你最终将在结果中得到重复的索引值,即使左表索引是唯一的!
有时,合并的dataframe具有同名的列。merge和join都有解决二义性的方法,但语法略有不同(默认情况下merge会用_x, _y来解决,而join会抛出异常),如下图所示:
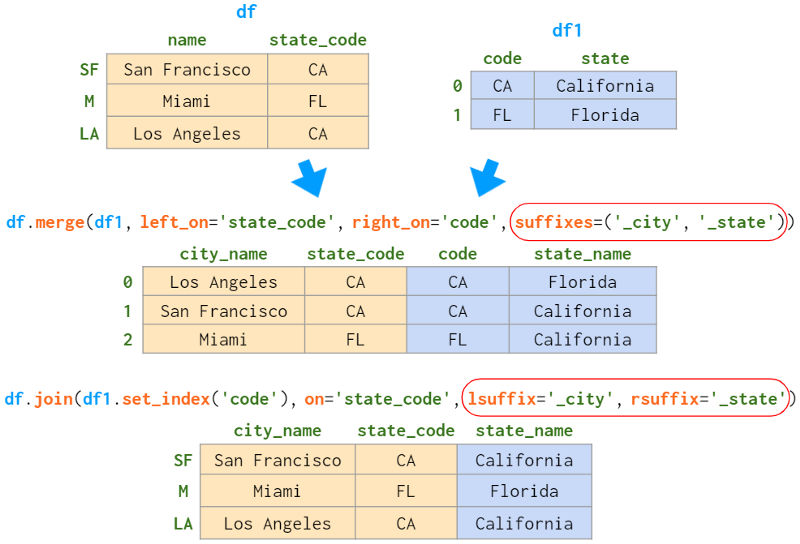
总结:
-
合并非索引列上的连接,连接要求列被索引
-
merge丢弃左DataFrame的索引,join保留它
-
默认情况下,merge执行内联结,join执行左外联结
-
合并不保持行顺序
-
Join可以保留它们(有一些限制)
-
join是合并的别名,left_index=True和/或right_index=True
3、多个连接
如上所述,当对两个dataframe(如df.join(df1))运行join时,它充当了合并的别名。但是join也有一个multiple join模式,它只是concat(axis=1)的别名。
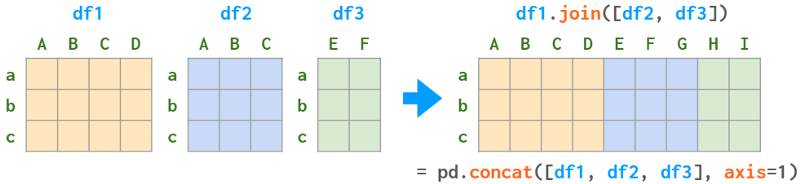
与普通模式相比,该模式有一些限制:
- 它没有提供解析重复列的方法
- 它只适用于1:1关系(索引到索引连接)。
因此,多个1:n关系应该一个接一个地连接。仓库panda -illustrated也提供了一个辅助方法,如下所示:

pdi.join是Join的一个简单包装器,它接受on、how和后缀参数,以便您可以在一个命令中进行多个联结。与原始的关联操作一样,关联的是属于第一个DataFrame的列,其他DataFrame根据它们的索引进行关联操作。
7.5 插入和删除
由于DataFrame是列的集合,因此将这些操作应用到行上比应用到列上更容易。例如,插入一列总是在原地完成,而插入一行总是会生成一个新的DataFrame,如下所示:
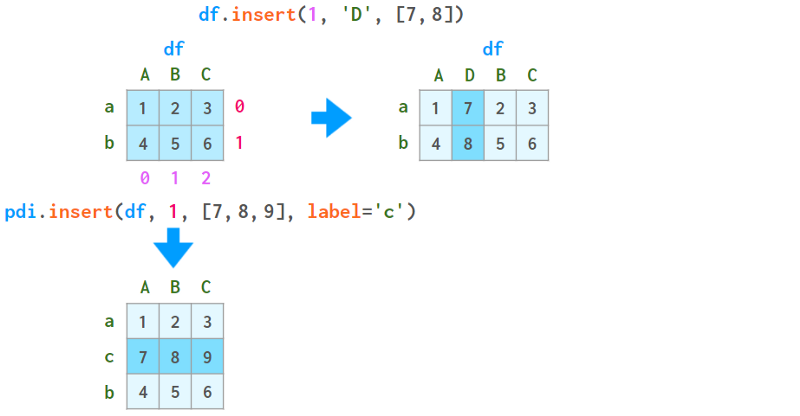
删除列通常不用担心,除了del df[‘D’]和del df。D则没有(Python级别的限制)。

使用drop删除行非常慢,如果原始标签不是唯一的,可能会导致复杂的bug。下图将帮助解释这个概念:

一种解决方案是使用ignore_index=True,它告诉concat在连接后重置行名称:
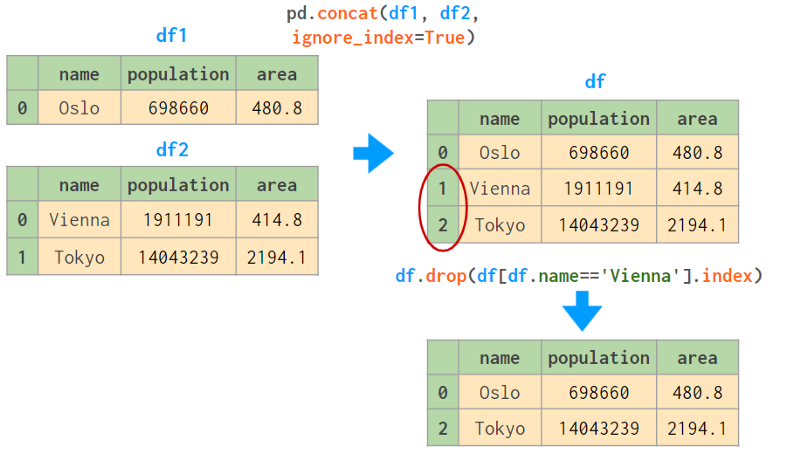
在这种情况下,将name列设置为索引将有所帮助。但对于更复杂的滤波器,它不会。
另一种快速、通用、甚至可以处理重复行名的解决方案是索引而不是删除。为了避免显式地否定条件,我写了一个(只有一行代码的)自动化程序。

7.6 分组
这个操作已经在Series部分详细描述过了。但是DataFrame的groupby在此基础上有一些特定的技巧。
首先,你可以使用一个名称来指定要分组的列,如下图所示:
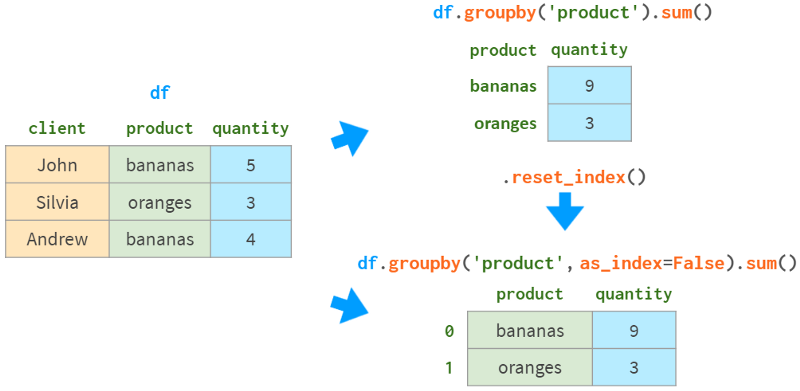
如果没有as_index=False, Pandas将进行分组的列指定为索引。如果这不是我们想要的,可以使用reset_index()或指定as_index=False。
通常,数据框中的列比你想在结果中看到的多。默认情况下,Pandas会对所有远端可求和的东西进行求和,因此你需要缩小选择范围,如下所示:

注意,当对单个列求和时,你将得到一个Series而不是DataFrame。如果出于某种原因,你想要一个DataFrame,你可以:
- 使用双括号:df.groupby(‘product’)[[‘quantity’]].sum()
- 显式转换:df.groupby(‘product’)[‘quantity’].sum().to_frame()
切换到数值索引也会创建一个DataFrame:
- df.groupby(‘product’, as_index=False)[‘quantity’].sum()
- df.groupby(‘product’)[‘quantity’].sum().reset_index()
但是,尽管外观不寻常,Series的行为就像DataFrames一样,所以可能对pdi.patch_series_repr()进行“整容”就足够了。
显然,不同的列在分组时表现不同。例如,对数量求和完全没问题,但对价格求和就没有意义了。使用。agg可以为不同的列指定不同的聚合函数,如下图所示:

或者,你可以为一列创建多个聚合函数:

或者,为了避免繁琐的列重命名,你可以这样做:

有时,预定义的函数不足以产生所需的结果。例如,在平均价格时使用权重会更好。你可以为此提供一个自定义函数。与Series不同的是,该函数可以访问组中的多个列(它以子dataframe作为参数),如下所示:

不幸的是,你不能把预定义的聚合和几个列级的自定义函数结合在一起,比如上面的那个,因为agg只接受单列级的用户函数。单列范围的用户函数唯一可以访问的是索引,这在某些情况下很方便。例如,那天香蕉以5折的价格出售,如下图所示:

为了从自定义函数中访问group by列的值,它事先已经包含在索引中。
通常,定制最少的函数可以获得最好的性能。为了提高速度:
-
通过g.apply()实现多列范围的自定义函数
-
通过g.agg()实现单列范围的自定义函数(支持使用Cython或Numba进行加速)
-
预定义函数(Pandas或NumPy函数对象,或其字符串名称)。
-
预定义函数(Pandas或NumPy函数对象,或其字符串名称)。
数据透视表(pivot table)是一种有用的工具,通常与分组一起使用,从不同的角度查看数据。
7.6 旋转和反旋转
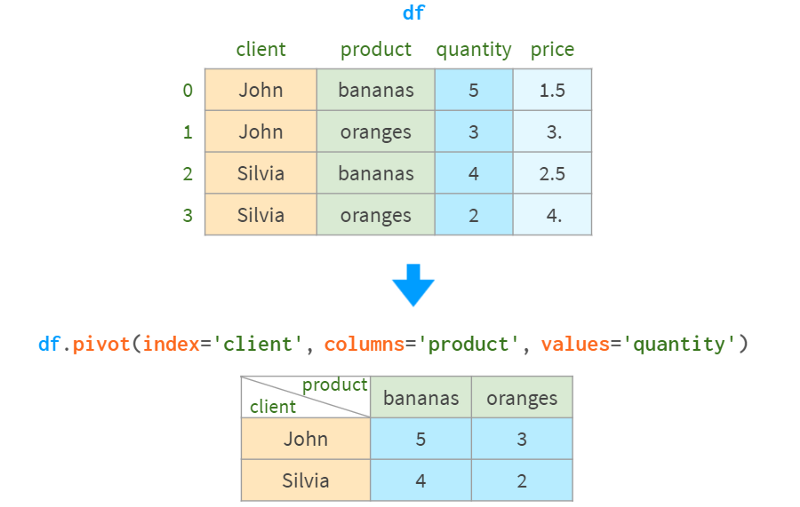
该命令丢弃了与操作无关的任何信息(索引、价格),并将来自三个请求列的信息转换为长格式,将客户名称放入结果的索引中,将产品名称放入列中,将销售数量放入DataFrame的body中。
至于相反的操作,你可以使用stack。它将索引和列合并到MultiIndex中:
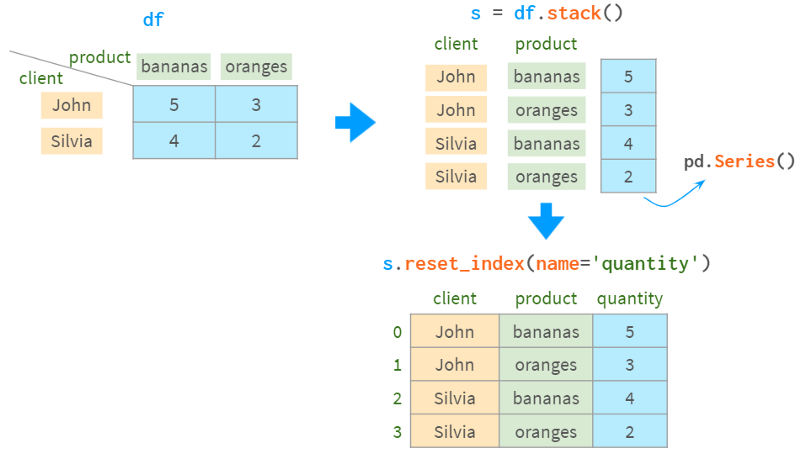
另一种选择是使用melt:
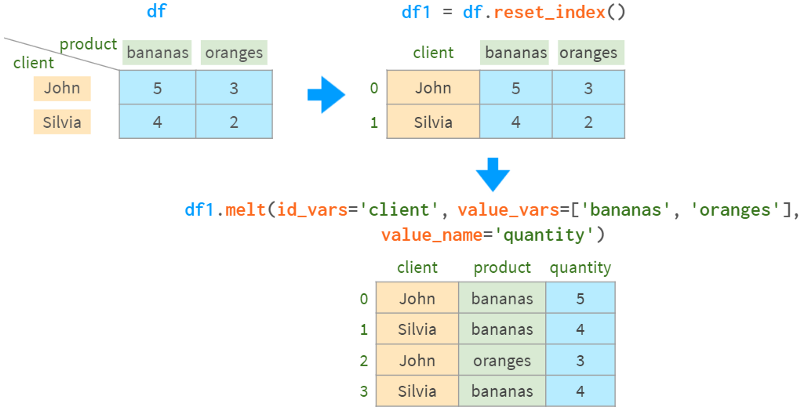
注意,melt以不同的方式对结果行进行排序。
Pivot丢失了结果的body的名称信息,因此无论是stack还是melt,我们都必须提醒pandas quantity列的名称。
在上面的例子中,所有的值都存在,但这不是必须的:
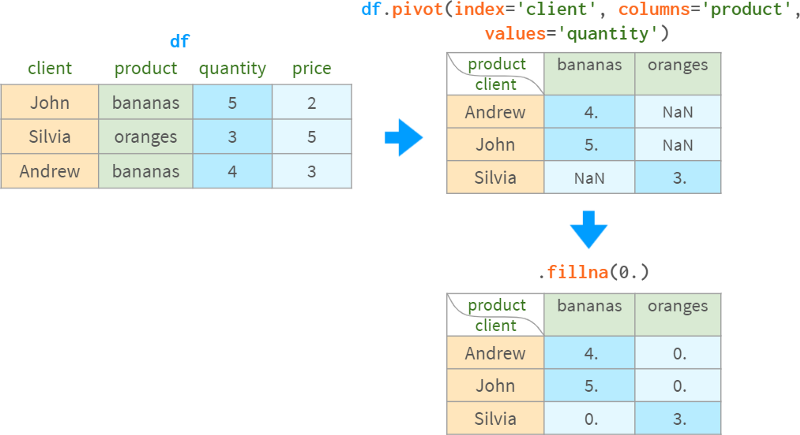
分组值然后旋转结果的做法是如此常见,以至于groupby和pivot被捆绑在一个专用的函数(以及相应的DataFrame方法)数据透视表中:
-
如果没有columns参数,它的行为与groupby类似
-
当没有重复的行进行分组时,它的工作原理与pivot类似
-
否则,它会进行分组和旋转
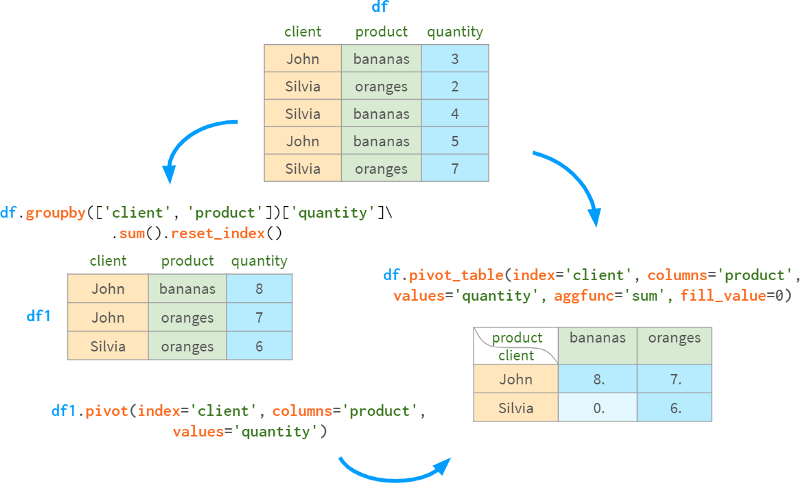
aggfunc参数控制哪一个聚合函数应该用于分组行(默认为均值)。
为了方便,pivot_table可以计算小计和合计:
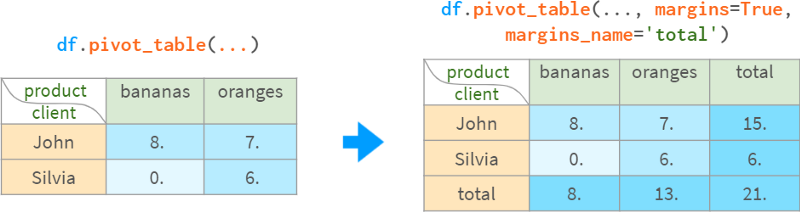
一旦创建,pivot表就变成了一个普通的DataFrame,因此可以使用前面描述的标准方法查询它。
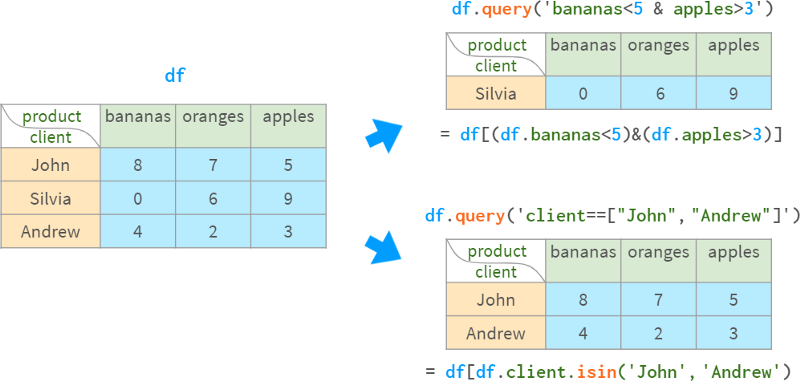
当使用多索引时,透视表特别方便。