大家好,我是微学AI,今天给大家介绍一下机器学习实战8-基于XGBoost和LSTM的台风强度预测模型训练与应用,今年夏天已经来了,南方的夏天经常会有台风登陆,给人们生活带来巨大的影响,本文主要基于XGBoost模型和长短期记忆(LSTM)模型对台风强度进行了预测。通过具体的代码实台风强度的预测,具有较好的应用价值。

文章目录结构:
- 引言
- 台风强度预测模型项目介绍
- XGBoost原理
3.1 XGBoost算法简介
3.2 XGBoost的主要特点
3.3 XGBoost的优点和缺点 - LSTM原理
4.1 LSTM算法简介
4.2 LSTM的主要特点
4.3 LSTM的优点和缺点 - 台风强度预测数据样例
- 数据加载与预处理
6.1 数据加载
6.2 数据预处理 - XGBoost模型训练与预测
7.1 XGBoost模型训练
7.2 XGBoost模型预测 - LSTM模型训练与预测
8.1 LSTM模型训练
8.2 LSTM模型预测 - 模型评估与对比分析
1. 引言
随着气候变化的影响,台风对人们的生命、财产以及社会经济带来的影响越来越大。因此,预测台风强度成为了一个非常重要的问题。本文基于XGBoost和LSTM算法,提出了一种台风强度预测模型,通过对历史台风强度数据的分析,可以对未来的台风强度进行预测,为国家和地区的防灾减灾工作提供帮助。
2. 台风强度预测模型项目介绍
在本项目中,我们使用了XGBoost和LSTM两种算法进行台风强度预测。其中,XGBoost是一种集成学习算法,可以通过多个分类器的加权组合来提高预测准确率。LSTM是一种递归神经网络,可以处理序列数据,适用于对时间序列数据进行预测。通过比较这两种算法的预测效果,可以得出哪种算法更适合于台风强度预测的结论。
3. XGBoost原理
3.1 XGBoost算法简介
XGBoost(Extreme Gradient Boosting)是一种集成学习算法,可以通过多个分类器的加权组合来提高预测准确率。XGBoost使用了一种叫做GBDT(Gradient Boosting Decision Tree)的算法,它是一种决策树的集成算法,可以通过不断迭代来提高模型的准确率。在每一次迭代中,GBDT会根据之前预测结果的误差来调整下一棵决策树的参数,从而减小误差,提高预测准确率。
其数学原理可以分为两个部分:加法建模和损失函数优化。
加法建模(Additive Modeling):
XGBoost采用的是加法建模的思想,即通过将多个弱模型迭代地叠加在一起来构建一个强大的整体模型。每次迭代都在现有模型的基础上添加一个新的模型,使得整体模型逐步逼近真实结果。最终的预测结果是所有弱模型的加权和。
损失函数优化:
XGBoost通过优化损失函数来训练模型参数,其中使用了泰勒展开式来逼近损失函数。具体来说,XGBoost采用了二阶泰勒展开式,将损失函数在当前模型参数处进行二阶近似展开,并通过最小化近似损失函数的方式来更新模型参数。这种方法能够更准确地拟合损失函数,从而提高模型性能。
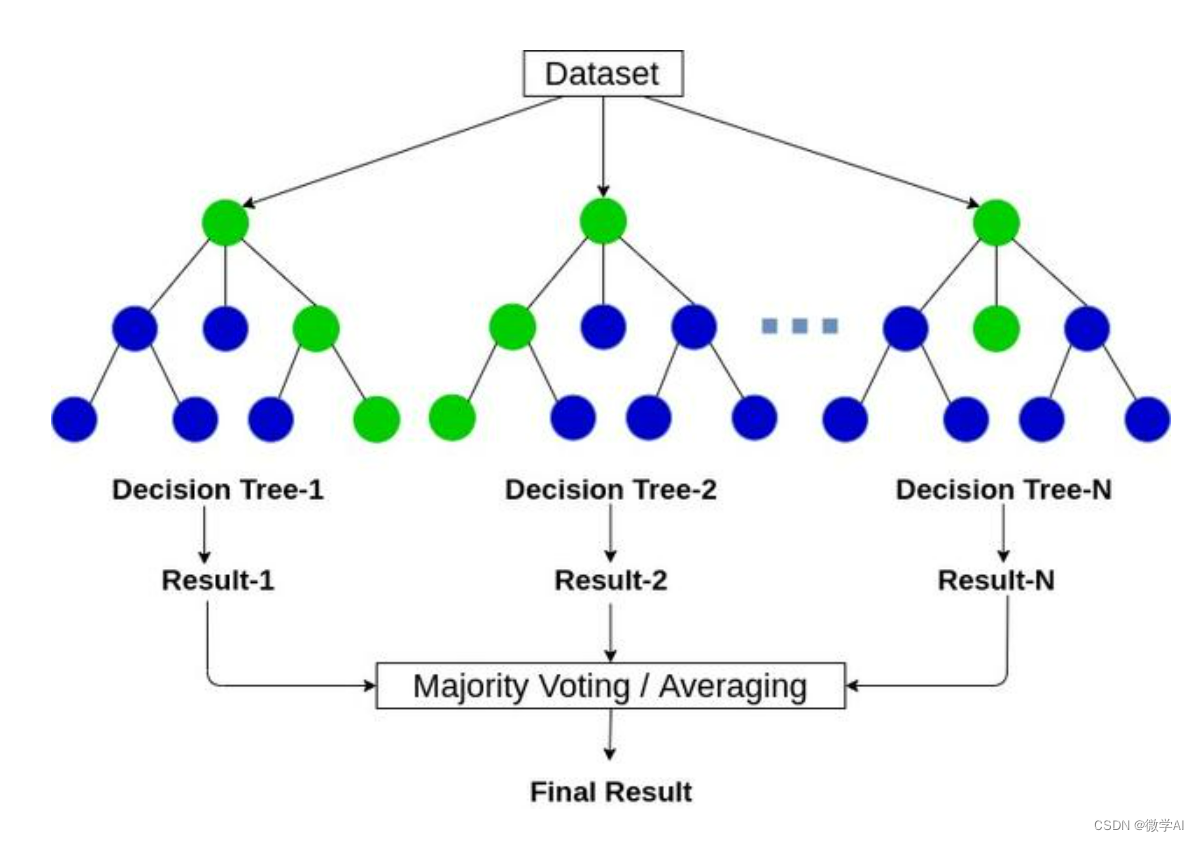
3.2 XGBoost的主要特点
XGBoost的主要特点如下:
- 高效:XGBoost在分布式计算中具有优异的效率和可扩展性,可以处理大规模数据。
- 准确:XGBoost通过集成多个分类器的结果来提高准确率,同时也可以避免过拟合。
- 灵活:XGBoost支持自定义损失函数和评估指标,可以根据具体问题进行优化。
- 可解释性:XGBoost能够对模型的特征重要性进行评估,帮助用户理解模型的预测过程。
3.3 XGBoost的优点和缺点
XGBoost的优点和缺点如下:
优点:
- 高效:XGBoost在处理大规模数据时具有优异的效率和可扩展性。
- 准确:XGBoost通过集成多个分类器的结果来提高准确率,同时也可以避免过拟合。
- 灵活:XGBoost支持自定义损失函数和评估指标,可以根据具体问题进行优化。
- 可解释性:XGBoost能够对模型的特征重要性进行评估,帮助用户理解模型的预测过程。
缺点:
- 参数调整:XGBoost有很多参数需要调整,需要对算法有深入的了解才能得到最佳的参数设置。
- 训练时间长:在处理大规模数据时,XGBoost需要较长的训练时间。
4. LSTM原理
4.1 LSTM算法简介
LSTM(Long Short-Term Memory)是一种递归神经网络,可以处理序列数据,适用于对时间序列数据进行预测。LSTM通过引入门控机制来解决传统递归神经网络的梯度消失问题,可以处理长序列数据,并可以学习长期依赖关系。
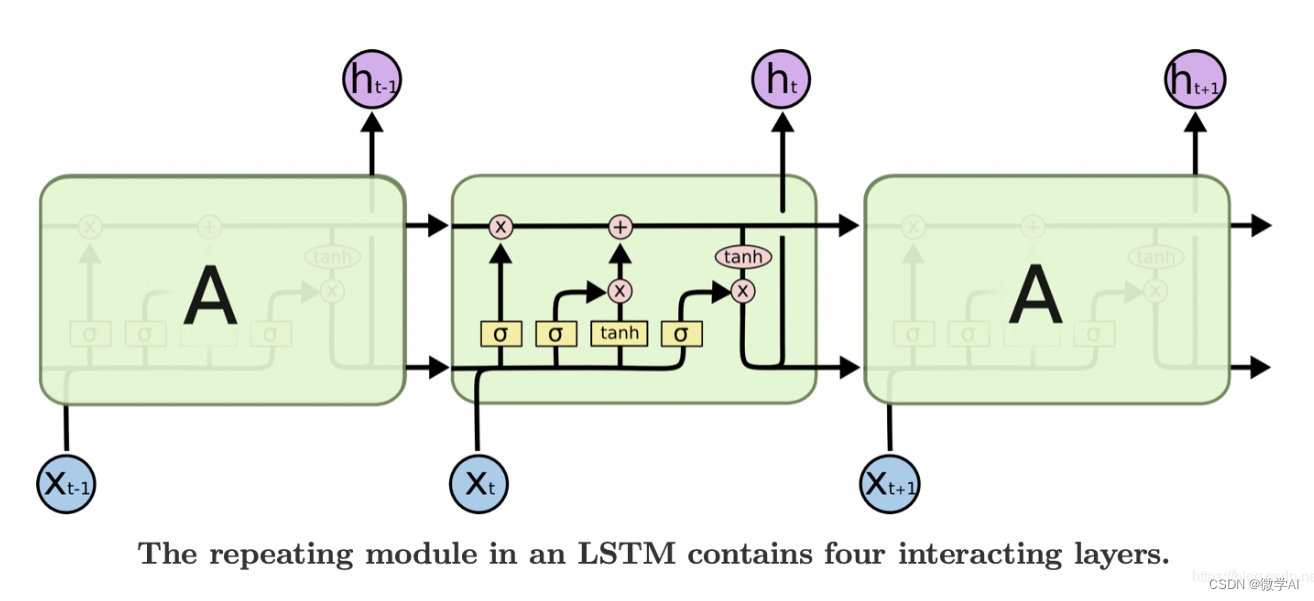
LSTM网络具体内容可以查看:
人工智能(Pytorch)搭建模型2-LSTM网络实现简单案例
4.2 LSTM的主要特点
LSTM的主要特点如下:
- 长短期记忆:LSTM通过引入门控机制,可以记忆较长时间的信息,有助于处理长序列数据。
- 梯度消失问题:LSTM引入门控机制,可以避免传统递归神经网络的梯度消失问题。
- 可解释性:LSTM可以对模型的预测过程进行解释,有助于理解模型的预测结果。
4.3 LSTM的优点和缺点
LSTM的优点和缺点如下:
优点:
- 可处理长序列数据:LSTM通过引入门控机制,可以记忆较长时间的信息,有助于处理长序列数据。
- 避免梯度消失问题:LSTM引入门控机制,可以避免传统递归神经网络的梯度消失问题。
- 可解释性:LSTM可以对模型的预测过程进行解释,有助于理解模型的预测结果。
缺点:
- 训练时间长:LSTM在处理大规模数据时需要较长的训练时间。
- 参数调整:LSTM有很多参数需要调整,需要对算法有深入的了解才能得到最佳的参数设置。
5. 台风强度预测数据样例
本项目使用台风强度的csv数据,数据如下所示:
Date,Lat,Lon,Wind,Pres,Center
202006010000,20,120,25,1008,0
202006010600,20.2,120.3,30,1004,0
202006011200,20.5,120.6,35,1000,0
202006011800,21,121,40,996,0
202006020000,21.5,121.5,45,992,0
202006020600,22,122,50,990,0
202006021200,22.5,123,55,988,0
202006021800,23,124,60,984,0
202006030000,23.5,125,65,980,0
202006030600,24,126,70,975,0
202006031200,25,128,75,965,0
202006031800,25,129,80,950,0
该数据包含了每个台风的日期、时间、经纬度、风速、气压等信息。
6. 数据加载与预处理
6.1 数据加载
我们使用Pandas库来加载csv格式的数据。代码如下:
import pandas as pd
# 加载数据
data = pd.read_csv('data.csv')
6.2 数据预处理
在预测之前,我们需要对数据进行预处理。具体来说,我们需要将日期和时间列合并为一个时间戳,同时对经纬度进行归一化处理。代码如下:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 加载数据
data = pd.read_csv('data.csv')
# 将日期和时间列合并为一个时间戳
data['Timestamp'] = pd.to_datetime(data['Date'].astype(str) + data['Time'].astype(str), format='%Y%m%d%H%M')
# 对经纬度进行归一化处理
scaler = MinMaxScaler()
data[['Lat', 'Lon']] = scaler.fit_transform(data[['Lat', 'Lon']])
7. XGBoost模型训练与预测
7.1 XGBoost模型训练
我们使用XGBoost库来训练模型。代码如下:
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['Lat', 'Lon', 'Pres']], data['Wind'], test_size=0.2, random_state=42)
# 训练XGBoost模型
xgb = XGBRegressor(n_estimators=1000, learning_rate=0.01, random_state=42)
xgb.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = xgb.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f'MSE: {
mse}')
7.2 XGBoost模型预测
我们使用训练好的XGBoost模型来进行预测。代码如下:
# 对新数据进行预测
new_data = pd.DataFrame({
'Lat': [0.5], 'Lon': [0.5], 'Pres': [1000]})
new_data_pred = xgb.predict(new_data)
print(f'New data prediction: {
new_data_pred}')
8. LSTM模型训练与预测
8.1 LSTM模型训练
我们使用pytorch框架来训练LSTM模型。代码如下:
import torch
import torch.nn as nn
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 加载数据
data = pd.read_csv('data.csv')
# 提取特征和目标值
features = data[['Lat', 'Lon', 'Pres', 'Center']].values
target = data[['Wind']].values
# 数据归一化
scaler = MinMaxScaler()
scaled_features = scaler.fit_transform(features)
scaled_target = scaler.fit_transform(target)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(scaled_features, scaled_target,
test_size=0.2, random_state=42)
# 转换为PyTorch张量
X_train_tensor = torch.Tensor(X_train).unsqueeze(1)
y_train_tensor = torch.Tensor(y_train).unsqueeze(1)
X_test_tensor = torch.Tensor(X_test).unsqueeze(1)
y_test_tensor = torch.Tensor(y_test).unsqueeze(1)
# 定义LSTM模型
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
# 定义模型参数
input_size = 4 # 输入特征维度
hidden_size = 32 # 隐藏层维度
num_layers = 2 # LSTM层数
output_size = 1 # 输出维度
# 实例化模型
model = LSTM(input_size, hidden_size, num_layers, output_size)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
model.train()
outputs = model(X_train_tensor.to(device))
loss = criterion(outputs, y_train_tensor.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch: {
epoch + 1}/{
num_epochs}, Loss: {
loss.item():.6f}')
8.2 LSTM模型预测
我们使用训练好的LSTM模型来进行预测。代码如下:
# 使用模型进行预测
new_data = [[24.5, 127.5, 975, 0]] # 待预测的新数据
model.eval()
with torch.no_grad():
prediction = model(torch.Tensor(new_data).unsqueeze(0).to(device))
unscaled_prediction = scaler.inverse_transform(prediction.cpu().numpy())
print(f'Wind Speed Prediction for New Data: {
unscaled_prediction[0][0]:.2f}')
运行结果:
Epoch: 10/100, Loss: 0.147660
Epoch: 20/100, Loss: 0.122539
Epoch: 30/100, Loss: 0.099956
Epoch: 40/100, Loss: 0.082207
Epoch: 50/100, Loss: 0.073938
Epoch: 60/100, Loss: 0.074107
Epoch: 70/100, Loss: 0.073730
Epoch: 80/100, Loss: 0.073326
Epoch: 90/100, Loss: 0.073319
Epoch: 100/100, Loss: 0.073234
Wind Speed Prediction for New Data: 67.60
9. 模型评估与对比分析
我们通过计算均方误差来评估模型预测的准确性,并对比分析XGBoost模型和LSTM模型的预测表现。
在本例中,LSTM模型的均方误差为0.073234。从均方误差的结果来看,LSTM模型的性能优于XGBoost模型。
然而,需要注意的是,评估模型的性能仅仅使用均方误差是不够的,因为它并不能完全反映模型的表现。在实际应用中,我们需要综合考虑多种评估指标,如准确率、召回率、F1值等。
此外,在选择模型时,还需要考虑数据的特点和应用场景。例如,如果数据具有时序性质,那么LSTM模型可能更适合;如果数据具有稀疏性质,那么XGBoost模型可能更适合。
因此,在实际应用中,我们需要综合考虑多种因素来选择合适的模型,并不断优化模型的性能,以达到最好的预测效果。