
过去,软件开发团队和 SRE 团队的工作一直都是各自为政,有着不同的文化视角和优先处理事项。DevOps 的目标是在软件开发和运营团队之间建立一些具有通用性和互补性的实践。但是,对于一些组织而言,真正的协作少之又少;为了构建有效的 DevOps 合作伙伴关系,我们还有很长的路要走。
除了文化方面的挑战之外,造成这种脱节最常见的原因之一就是:使用不同的工具来实现相似的目标 — 我们以端到端 (e2e) 测试与合成监测为例,就很能说明这种情况。
在这篇博文中,我们会对这些技术进行概要介绍。使用示例存储库 carlyrichmond/synthetics-replicator 的同时,我们还会介绍 Playwright、@elastic/synthetics 和 GitHub Actions 如何与 Elastic Synthetics 及 Recorder 实现强强结合,以让开发团队和 SRE 团队联合起来,共同验证和监测提供商(如 Netlify)平台上托管的简单 Web 应用程序的用户体验。
Elastic 最近引入了合成监测,正如我们在之前博文中所强调的,它可以完全取代端到端测试。通过合并使用单一工具来早期验证用户工作流,便可提供一种通用的语言来重现用户问题,以验证修复的结果。
合成监测与端到端测试
如果开发团队和运营团队的工具不统一,就很难将他们不同的文化进行融合。就这些方法的定义而言,可以看出实际上都是为了实现相同的目标。
端到端测试是一套重现用户路径的测试,包括点击情况、用户文本输入和导览。尽管许多人认为这是有关测试软件应用程序各层集成的问题,但端到端测试所模拟的是用户工作流。同时,合成监测(具体指监测范围内的一个子集,称为“浏览器监测”)是一种应用程序性能监测实践,用于模拟用户在应用程序中的整个活动路径。
这两种技术都是模拟用户路径的。如果我们使用工具搭起开发人员和运营部门之间的协作桥梁,那么我们不仅可以共同构建测试,而且还可以在我们的 Web 应用程序中提供生产监测。
创建用户旅程
当我们的应用程序中正在开发新的用户工作流或一组完成关键目标的功能时,开发人员可以使用 @elastic/synthetics 来创建用户旅程。初始项目支架可以在安装 init 实用工具后通过该工具生成,如下例所示。请注意,在使用这个实用工具之前,必须先安装 Node.js。

npm install -g @elastic/synthetics
npx @elastic/synthetics init synthetics-replicator-tests在开始向导之前,请确保您在集群上设置了 Elastic 集群信息和 Elastic Synthetics 集成。您将需要:
- 根据入门文档中的先决条件,必须在 Elastic Synthetics 应用中启用“Monitor Management”(监测管理)。
- 如果使用的是 Elastic Cloud,则需要输入 Elastic Cloud 集群云 ID。或者,如果您使用的是本地部署主机,则需要输入您的 Kibana 终端。
- 从您的集群生成的 API 密钥。Synthetics 应用程序的 “Settings”(设置)中有一个快捷方式,可以在 “Project API Keys”(项目 API 密钥)选项卡下生成这个密钥,如本文档所示。
这个向导会引导您完成整个操作过程,并生成一个包含配置和示例监测旅程的示例项目,其结构类似于下图中所示:
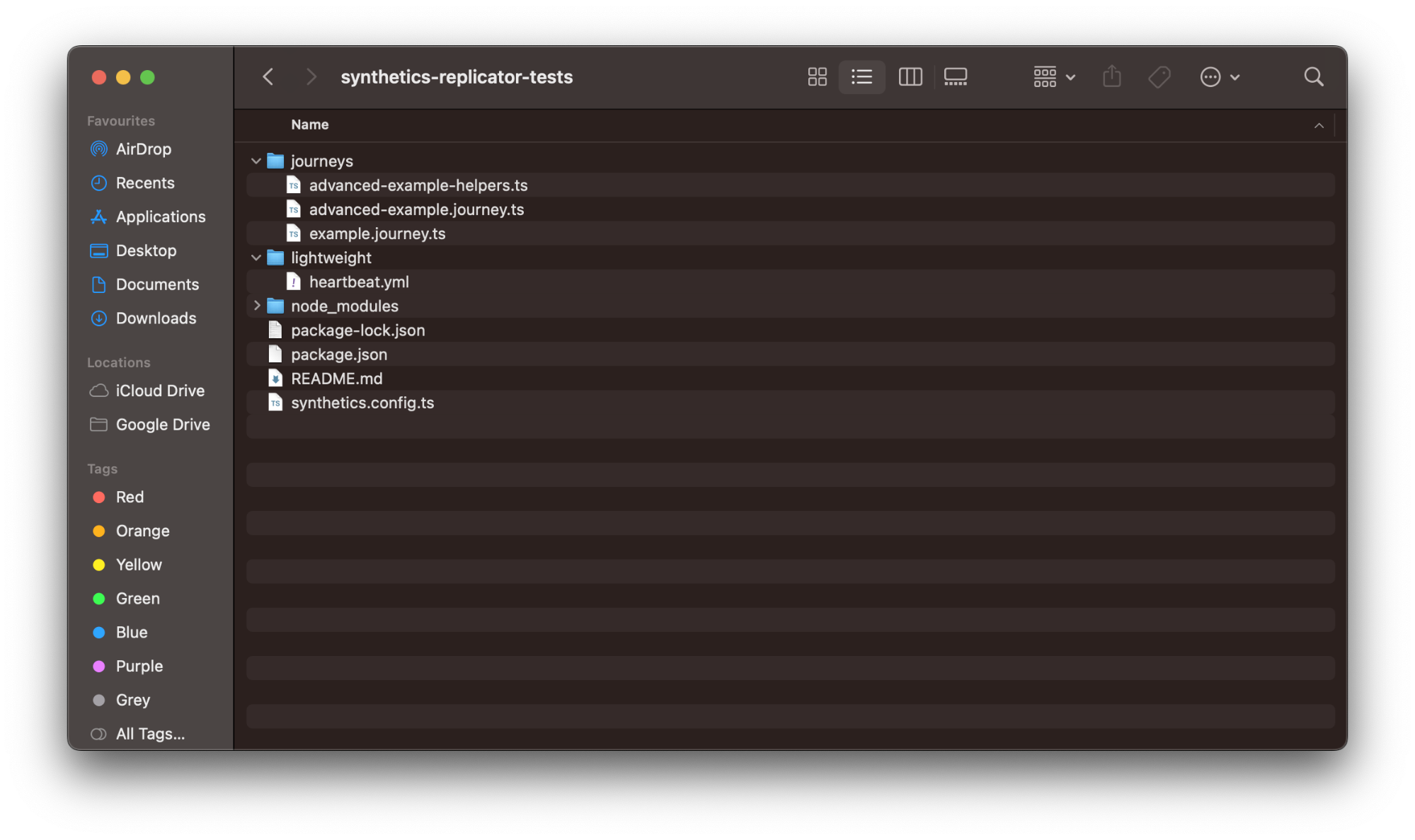 对于 Web 开发人员来说,他们对 README、package.json 和锁文件等大多数元素都会很熟悉。监测器的主要配置可在 synthetics.config.ts 中找到,如下文所示。这项配置可以进行修改,以包括特定于生产和开发的配置。这对于合并各工具和重复使用相同的监测器进行端到端测试,以及允许任何旅程用作端到端测试和生产监测器,都是至关重要的。虽然这个示例中并未包括私有位置的详细信息,但如果您希望从自己的专用 Elastic 实例(而不是从 Elastic 基础架构)进行监测,也可以将这些信息包含进来。
对于 Web 开发人员来说,他们对 README、package.json 和锁文件等大多数元素都会很熟悉。监测器的主要配置可在 synthetics.config.ts 中找到,如下文所示。这项配置可以进行修改,以包括特定于生产和开发的配置。这对于合并各工具和重复使用相同的监测器进行端到端测试,以及允许任何旅程用作端到端测试和生产监测器,都是至关重要的。虽然这个示例中并未包括私有位置的详细信息,但如果您希望从自己的专用 Elastic 实例(而不是从 Elastic 基础架构)进行监测,也可以将这些信息包含进来。
import type { SyntheticsConfig } from '@elastic/synthetics';
export default env => {
const config: SyntheticsConfig = {
params: {
url: 'http://localhost:5173',
},
playwrightOptions: {
ignoreHTTPSErrors: false,
},
/**
* Configure global monitor settings
*/
monitor: {
schedule: 10,
locations: ['united_kingdom'],
privateLocations: [],
},
/**
* Project monitors settings
*/
project: {
id: 'synthetics-replicator-tests',
url: 'https://elastic-deployment:port',
space: 'default',
},
};
if (env === 'production') {
config.params = { url: 'https://synthetics-replicator.netlify.app/' }
}
return config;
};
编写您的第一个旅程
尽管上述配置适用于项目中的所有监测器,但也可以针对给定测试进行更改。
import { journey, step, monitor, expect, before } from '@elastic/synthetics';
journey('Replicator Order Journey', ({ page, params }) => {
// Only relevant for the push command to create
// monitors in Kibana
monitor.use({
id: 'synthetics-replicator-monitor',
schedule: 10,
});
// journey steps go here
});@elastic/synthetics 包装器公开了许多标准测试方法,例如可在测试中设置和拆解典型属性的 before 和 after 构造,以及对许多常见断言帮助器方法的支持。本文档中列出了所支持的预期方法的完整列表。此外,还公开了 Playwright page 对象,这可让我们执行 API 中提供的所有预期活动,例如定位页面元素和模拟用户事件(如下面示例中描述的点击情况)。
import { journey, step, monitor, expect, before } from '@elastic/synthetics';
journey('Replicator Order Journey', ({ page, params }) => {
// monitor configuration goes here
before(async ()=> {
await page.goto(params.url);
});
step('assert home page loads', async () => {
const header = await page.locator('h1');
expect(await header.textContent()).toBe('Replicatr');
});
step('assert move to order page', async () => {
const orderButton = await page.locator('data-testid=order-button');
await orderButton.click();
const url = page.url();
expect(url).toContain('/order');
const menuTiles = await page.locator('data-testid=menu-item-card');
expect(await menuTiles.count()).toBeGreaterThan(2);
});
// other steps go here
});正如您在上面示例中看到的那样,它还公开了 journey 和 step 构造。这种构造反映了行为驱动开发 (BDD) 的实践,也就是在测试中展示用户在应用程序中的整个旅程。
作为功能开发的一部分,开发人员可以针对本地运行的应用程序执行测试,以查看用户工作流中成功和失败的步骤。在下面的示例中,在顶部用蓝色框标出的部分是本地服务器的启动命令。在下方用红色框标出的部分是监测器的执行命令。
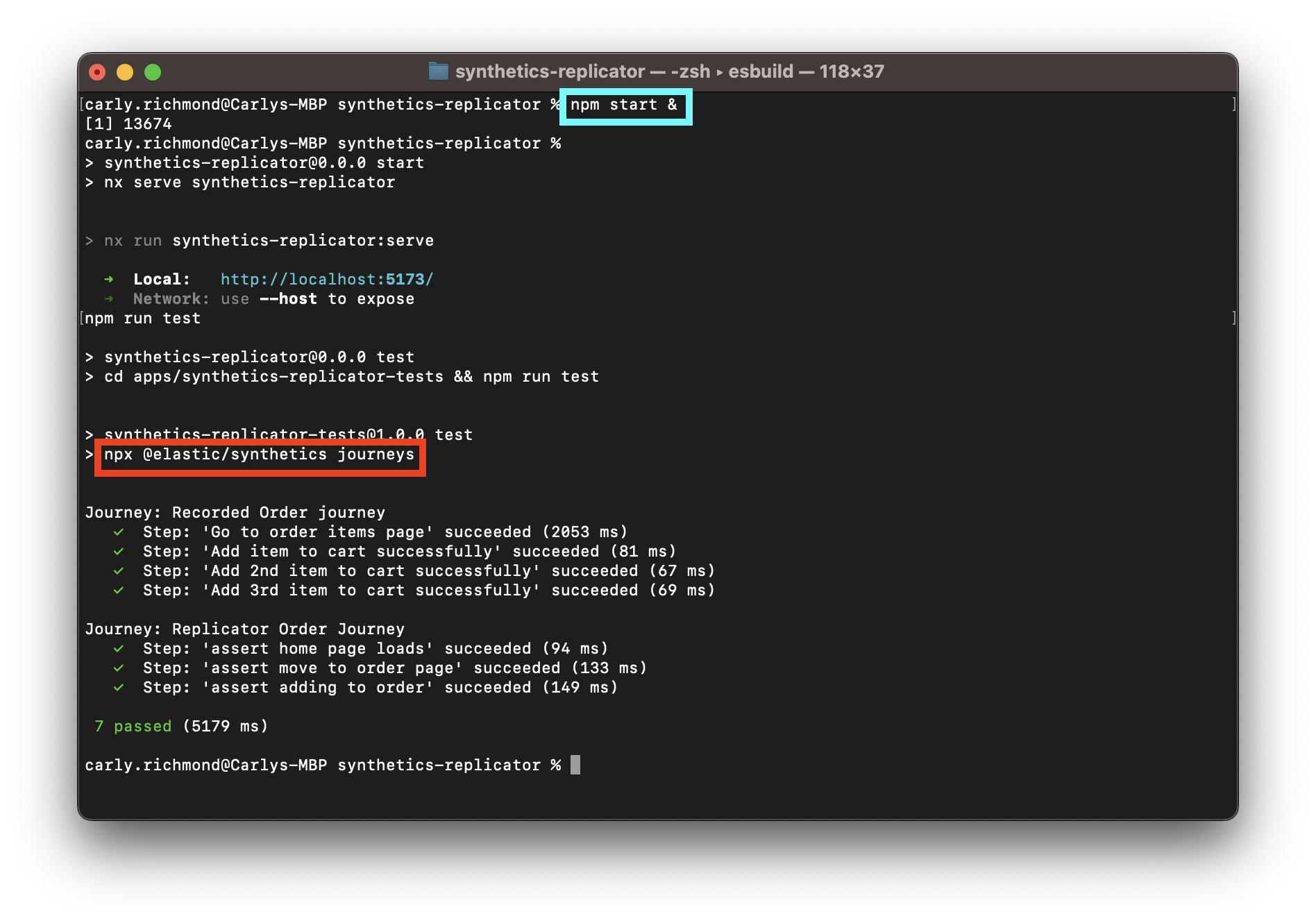 正如您可以在上图中看到的,每个旅程步骤旁边都标记了绿色勾号,我们的每项测试都通过了。不错哦!
正如您可以在上图中看到的,每个旅程步骤旁边都标记了绿色勾号,我们的每项测试都通过了。不错哦!
为 CI 管道设置门控
在您的 CI 管道中将监测器的执行用作合并代码更改和上传新版本监测器的门控是非常有必要的。在这一部分及后续部分中,我们将讨论 GitHub Actions 工作流中的每项作业。
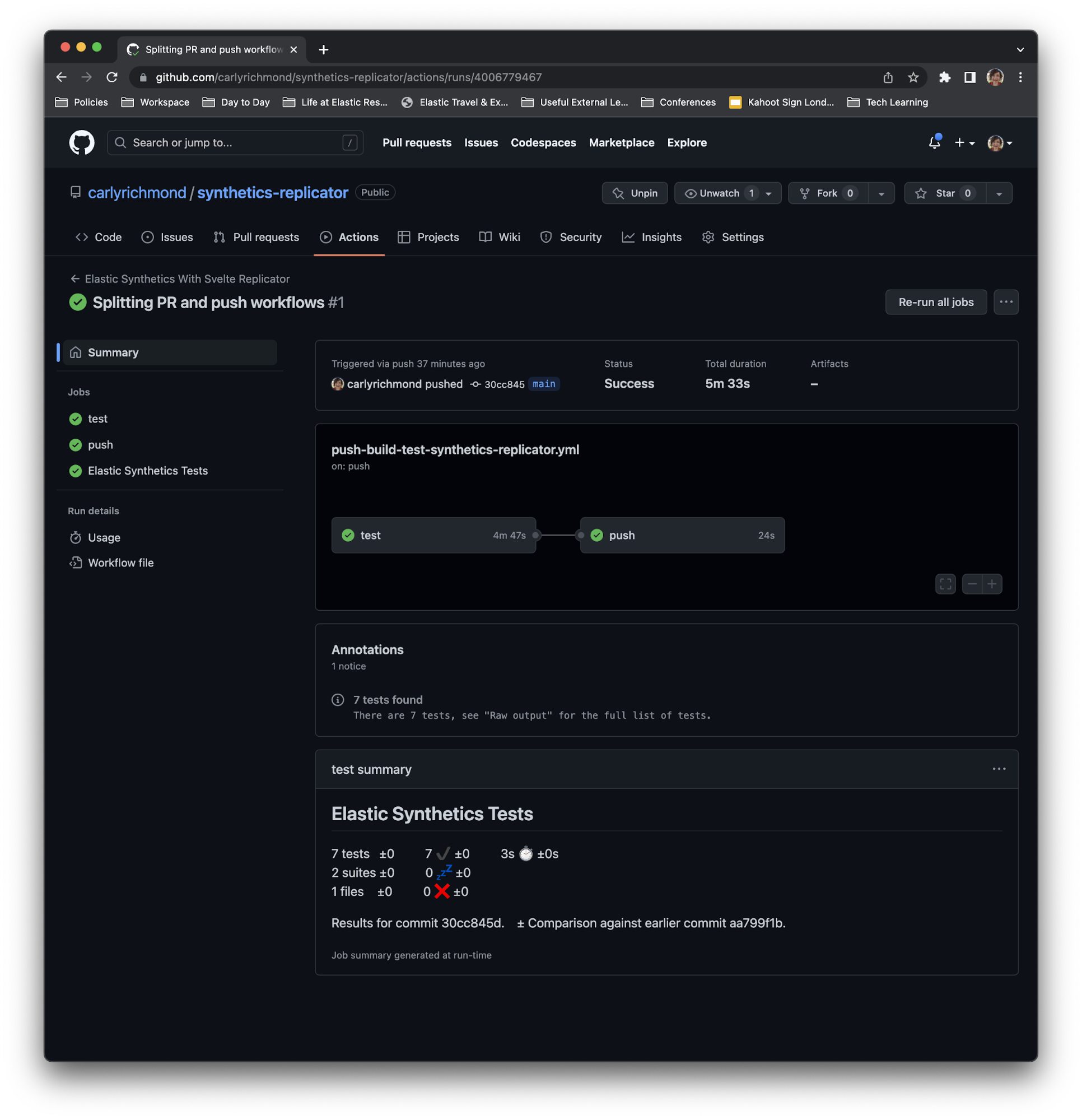
如下图所示,测试作业启动了一个测试实例,并运行了我们的用户旅程来验证各项更改。这一步骤应针对拉取请求运行,以验证开发人员进行的更改,对于推送请求也应如此。
jobs:
test:
env:
NODE_ENV: development
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-node@v3
with:
node-version: 18
- run: npm install
- run: npm start &
- run: "npm install @elastic/synthetics && SYNTHETICS_JUNIT_FILE='junit-synthetics.xml' npx @elastic/synthetics . --reporter=junit"
working-directory: ./apps/synthetics-replicator-tests/journeys
- name: Publish Unit Test Results
uses: EnricoMi/publish-unit-test-result-action@v2
if: always()
with:
junit_files: '**/junit-*.xml'
check_name: Elastic Synthetics Tests请注意,与本地机器上执行的旅程不同,我们在执行 npx @elastic/synthetics 时使用了 --reporter=junit 选项,以提供 CI 作业中用户旅程通过验证(或未能通过 - 很遗憾,有时就会发生这种情况)的可见性。
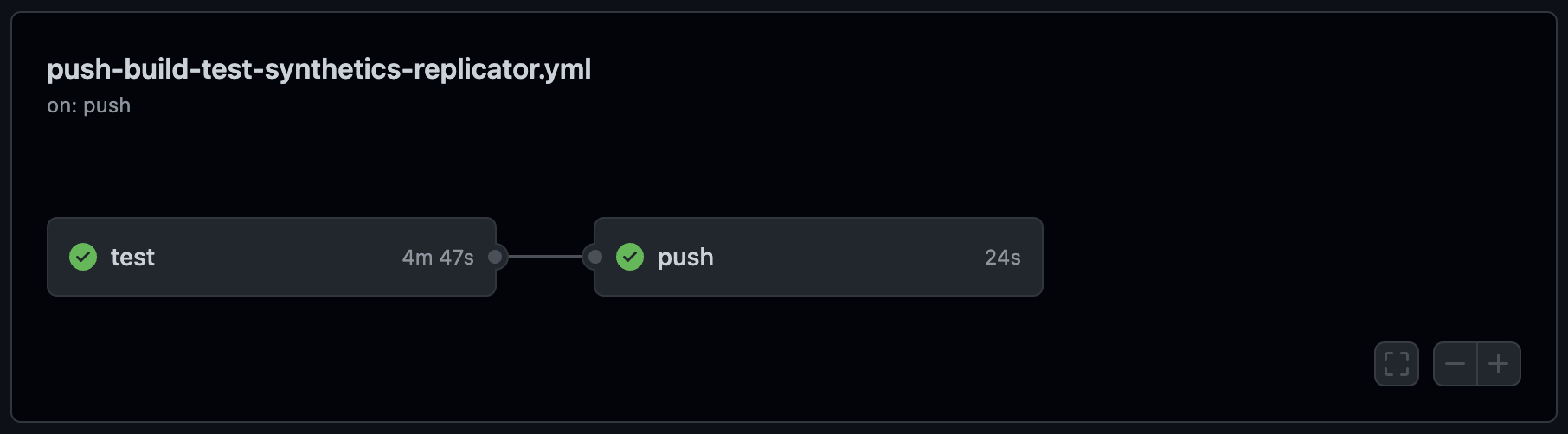
自动上传监测器
为了确保在 Elastic 运行状态监测中提供最新的监测器,建议将监测器作为 CI 工作流的一部分以编程方式进行推送,如下面的示例任务所做的那样。我们的工作流有第二个作业 push(如下图所示),这取决于我们成功执行了将监测器上传到集群的 test 作业。请注意,在我们的工作流中,这个作业被配置为在推送时运行,以确保更改得到验证,而不仅仅是在拉取请求中引发。
jobs:
test: …
push:
env:
NODE_ENV: production
SYNTHETICS_API_KEY: ${
{ secrets.SYNTHETICS_API_KEY }}
needs: test
defaults:
run:
working-directory: ./apps/synthetics-replicator-tests
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-node@v3
with:
node-version: 18
- run: npm install
- run: npm run push当您创建可以从项目文件夹触发的项目时,@elastic/synthetics init 向导会为您生成一个推送命令。下面通过 steps 和 working_directory 的配置来说明这一点。这个推送命令需要使用您的 Elastic 集群的 API 密钥,该密钥作为机密应存储在受信任的保管库中,并通过工作流环境变量引用。同样至关重要的是,在将更新的监测器配置推送到 Elastic Synthetics 实例之前,必须先成功运行监测器,以防止破坏生产监测。与针对测试环境运行的端到端测试不同,损坏的监测器会影响 SRE 活动,因此任何更改都需要进行验证。出于这个原因,建议通过 needs 选项将依赖项应用于测试步骤。
使用 Elastic Synthetics 进行监测
监测器一旦上传完毕,它们就可为 SRE 团队提供一个定期检查点,以了解用户工作流是否按预期运行 — 这不仅是因为它们将按照之前为项目和各个测试配置的定期时间表运行,还因为它们能够检查所有监测器运行的状态并按需执行。
通过 “Monitors”(监测器)的 “Overview”(概览)选项卡,我们可以立即查看所有配置好的监测器的状态,并能够通过卡片省略号菜单手动运行监测器。
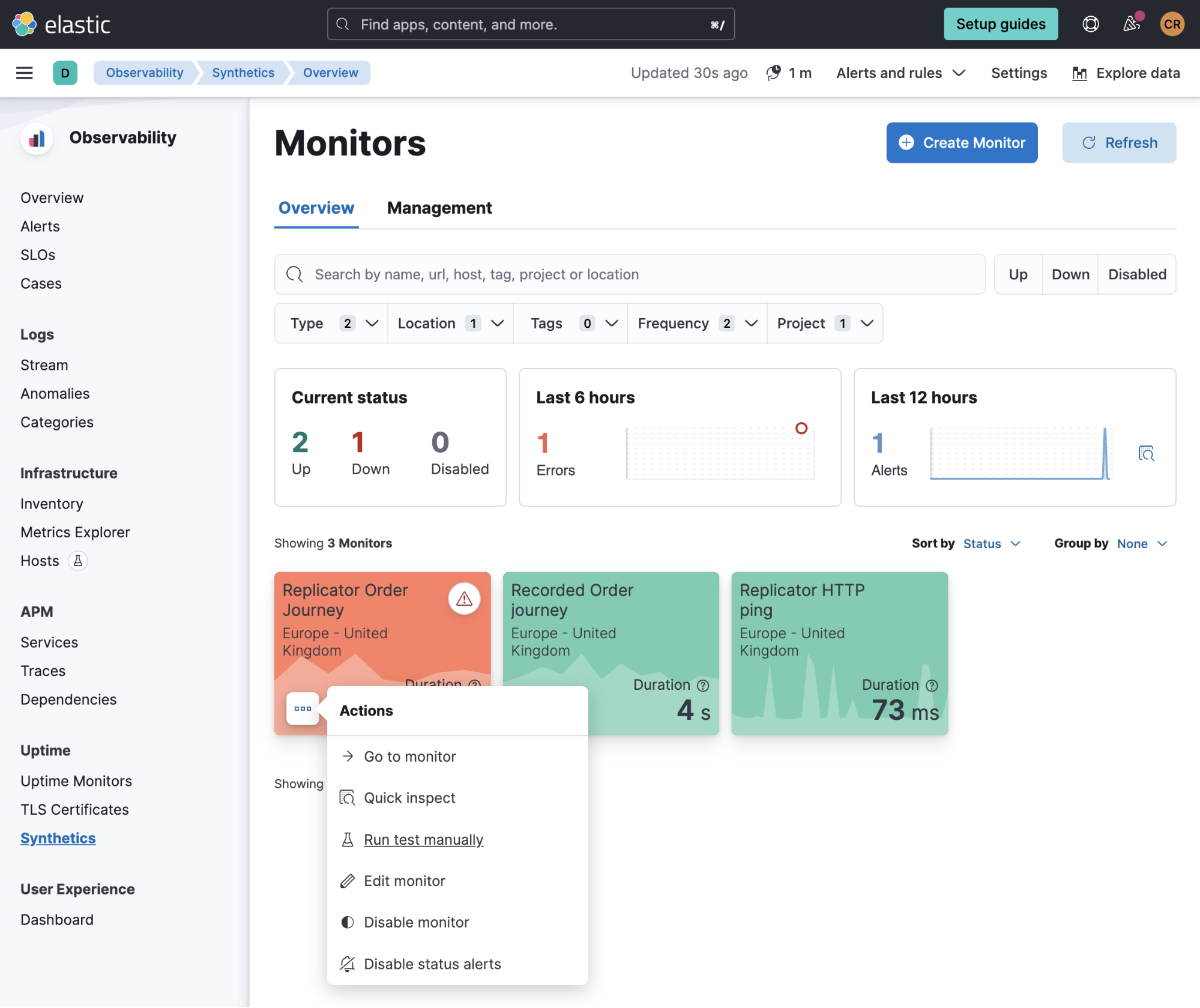
在 “Monitor”(监测器)屏幕中,我们还可以进行导航,以概览单个监测器的执行情况,对故障情况进行调查。
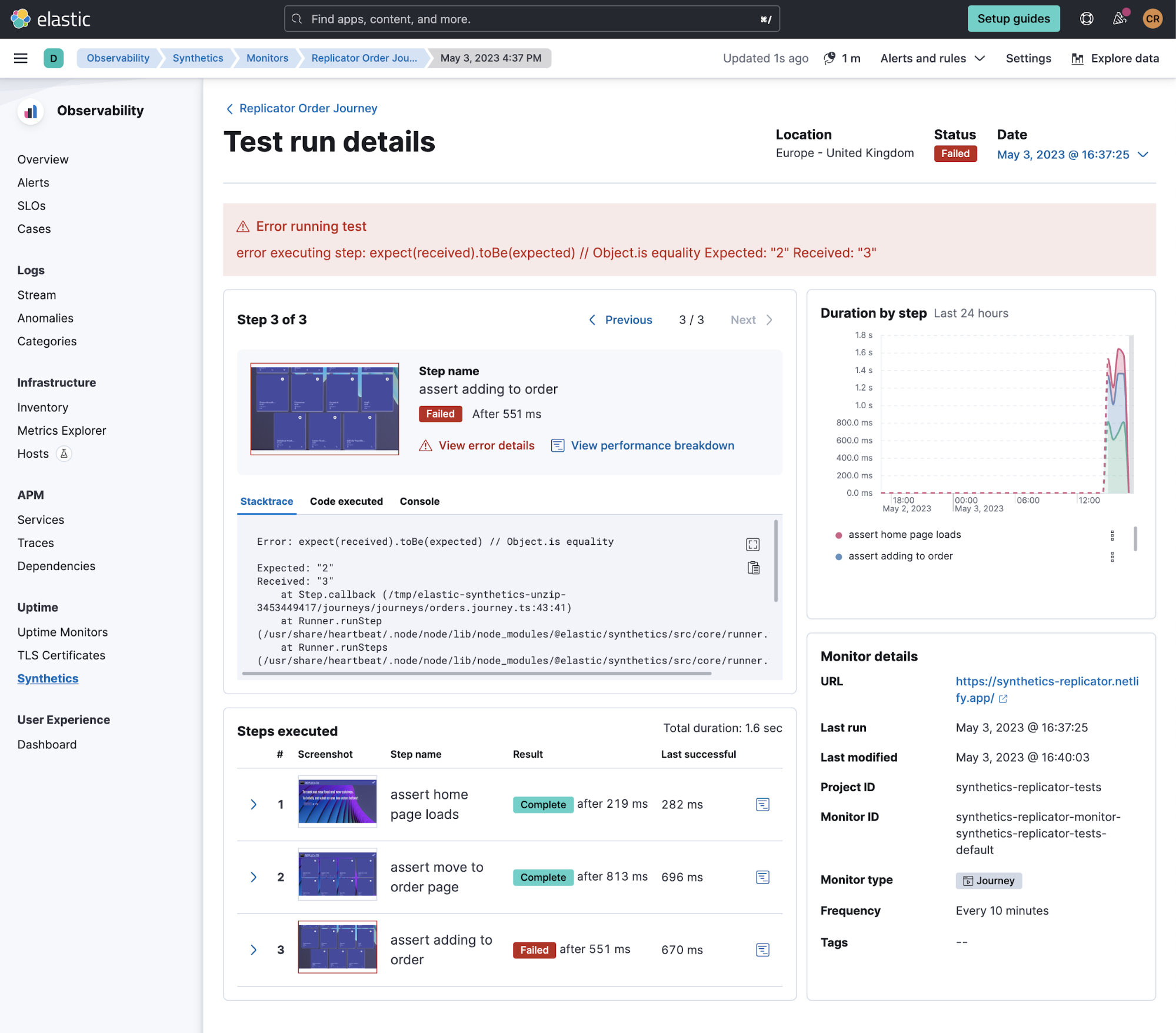
现在,SRE 拥有的另一种超强监测能力是将这些监测器与 SRE 在仔细检查 APM、指标和日志等应用程序性能和可用性时已经使用的熟悉工具进行集成。当 SRE 对潜在故障或瓶颈进行调查时,可以使用相应地名为 Investigate(调查)的菜单轻松进行导览。
在发现问题和自动获知潜在问题之间也存在一个平衡。对问题通知的规则及阈值设置都已经很熟悉的 SRE 来说,他们会很高兴地得知,这同样也适用于浏览器监测器。下图显示了一个编辑规则的示例。
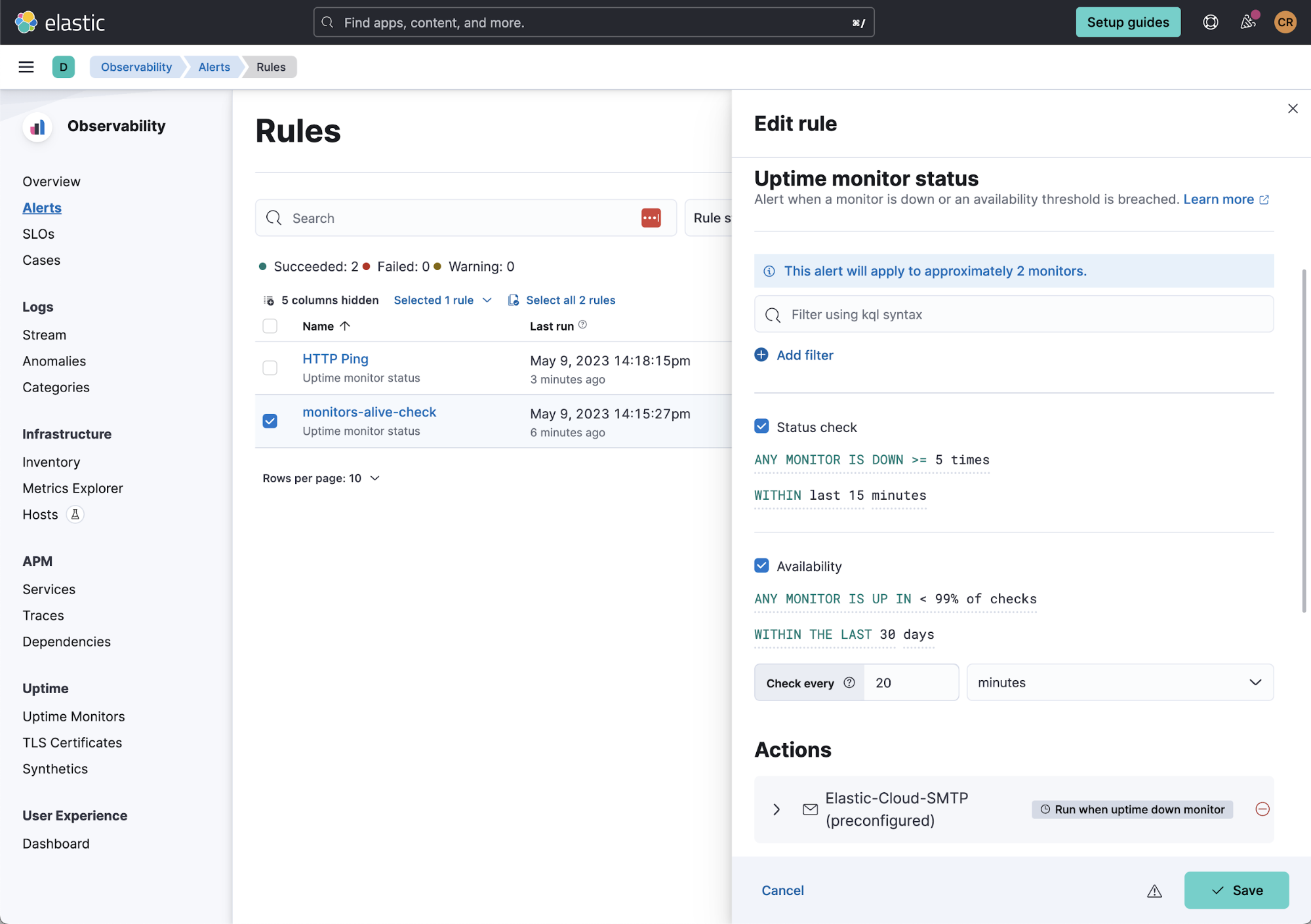
浏览器监测器的状态可以配置为不仅考虑是否有任何单个或集体监测器已被关闭多次(如在上面的状态检查中),而且还可以通过查看给定时间段内通过检查的百分比来衡量总体可用性。SRE 不仅对以传统的生产管理方式应对问题感兴趣,而且他们还希望提高应用程序的可用性。
记录用户工作流
在整个开发生命周期中生成端到端测试的局限性在于,有时团队会错过一些信息,而且之前的工具集都是面向开发团队构建的。尽管利用多学科团队设计直观产品的初衷是好的,但用户可能会以意想不到的方式使用应用程序。此外,开发人员编写的监测器只会涵盖那些预期的工作流,并在这些监测器在生产中出现故障时,亦或在对它们进行异常检测的情况下开始出现不同行为时发出警报。
当出现用户问题时,采用与监测器相同的格式重现问题是很有用的。在生成用户旅程时,利用 SRE 的经验也很重要,因为他们会凭直觉考虑开发人员可能会遇到困难的失败案例,并重点关注满意的案例。然而,并非所有 SRE 都有经验或信心使用 Playwright 和 @elastic/synthetics 来编写这些旅程。
Elastic 合成监测记录器演示
进入 Elastic Synthetics Recorder!上面的视频演示了如何使用它来记录用户旅程中的步骤,并相应导出到一个 JavaScript 文件中,以包含在监测器项目中。这对于反馈到开发阶段和测试所开发的修复程序来解决问题是非常有用的。除非我们大家联合起来,共同使用这些监测器,否则这种方法是无法实现的。
立即试用!
从 8.8 版本开始,已正式推出 @elastic/synthetics 和 Elastic Synthetics 应用,可信赖的记录器仍处于公测版阶段。通过 “社区讨论” 论坛中的 Uptime category(运行时间类别)或通过 Slack,分享您使用合成监测弥合开发人员和运营团队分歧的经验。
监测愉快!