现在测试工程师面试难度越来越大,关于技术方面考察,很多面试官经常会问你是否了解过Redis缓存中间件,这道题一方面是考察你是否对后端技术有一定了解,另一方面也考察你测试工作的深浅。
所以本文将由浅到深、由易到难列举Redis相关面试题,为你弥补缓存中间件的知识盲点,帮助大家在面试中,缓存中间件这块满分通过。
1、Redis是什么?为啥性能好?
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis是现在最受欢迎的NoSQL数据库之一。
首先,采用了多路复用io阻塞机制;
然后,数据结构简单,操作节省时间;
最后,运行在内存中,自然速度快。

2、数据类型?常见的命令?
有多种数据类型,最常用的就是以下几种
String 字符串类型
set name junchow
get name
set age 20
get age
incr age
decr ageHash 数据类型
//设置值
hset userinfo name junchow
//解析
hset : cmd
key: userinfo
value: name junchow
//等价于
$userinfo = array('name'=>'junchow')
//获取值
hget userinfo nameList 链表数据
链表类型类似于队列或栈的数据结构,链表可视为存储数据的容器。链表的左侧被称为头部,右侧被称为尾部。
链表可模拟出队列(先进先出),也可以模拟栈(先进后出)。
//从左侧装入 lpush
lpush link1 A
lpush link1 B
//从右侧转入 rpush
rpush link2 A
rpush link2 BSet 无序集合类型
//向集合setvar添加元素
sadd setvar 1
sadd setvar 2
sadd setvar 3
//从集合setvar中获取元素
smembers setvar
//判断元素1是否在集合setvar中,成功返回1,失败返回0
sismember setvar 1
//从集合中移除元素,成功返回1,失败返回0
srem setvar 1
//从集合中随机弹出元素
spop setvar
//使用sunion求集合并集
sunion setvar mysetZset 有序集合类型
//添加集合元素
zadd class:php 1 asion
zadd class:php 2 mark
zadd class:php 3 lily
zadd class:php 4 jack
//获取集合元素
zrange class:php 0 -1
//获取集合内容时显示权重信息
zrange class:php 0 -1 withscores3、有几种持久化方式?优缺点?
RDB (Redis DataBase): redis按一定周期将内存中的数据同步到磁盘文件中。
RDB优点就是恢复大的数据集的时候,RDB方式会更快些,但是可能会造成数据丢失,因为周期内redis宕机以后,不会记录数据。
AOF (Append Only File): redis会把数据造成更改的命令追加到日志文件中,再下次重启时执行日志文件中的命令,达到数据的还原。
AOF 优点就是可以更好的保护数据不丢失,AOF开启后支持写的QPS会比RDB支持的写的QPS低,因为AOF一般会配置成每秒fsync(同步磁盘)操作,每秒的fsync操作还是很高的,目前很多项目都是混合使用。
4、数据库和缓存的处理流程?
如截图:
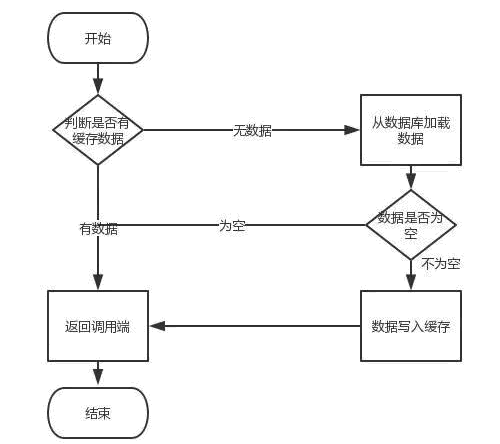
5、缓存雪崩、缓存击穿、缓存穿透?
老掉牙的面试题了,感觉只要说到redis,面试官几乎都会提这三个概念,重点理解概念和应对措施。
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
解决方案:即使数据库和缓存都查询不到,也要在redis缓存一份数据;另外一种布隆过滤器。
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:热点数据毕竟只有少数,可以设置成永不过期。
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
解决方案:一过期时间加个随机数,保证热点数据不会同时过期。
6、你的项目哪些功能用到了?
一般项目的登录的Token、修改频率较低的数据放进缓存、分布式锁、幂等性校验等等。
下面介绍一些高级的Redis面试题,帮助你在面试中能够一举征服面试官。
1、项目中哪些地方用了?
学Redis 得融入到项目中,结合项目去聊Redis技术,这样才能说服面试官,告诉他我真的懂Redis,而不是纸上谈兵式的自学过。下面列举的只是常见的几种:
会话缓存(Session Cache)
Token作为鉴权的凭证,大部分情况都会存到redis中。
冷数据一般存到Redis中
冷数据是指那些不经常修改的数据,一般都放到Redis中,但要做好数据库和redis之间的数据一致性。
分布式锁
这个是个大专题,限于文章篇幅后面我会详细去聊。
幂等性校验
可以参考文章
计数器
int类型,incr方法,例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库。
2、过期策略?内存淘汰策略?
Redis的数据可以设置过期时间,不是过期就已经删除了吗?为什么还存在所谓的淘汰策略呢?这个原因我们需要从redis的过期策略聊起。
过期策略分为定期删除和惰性删除
定期删除
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
Redis 默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载。
惰性删除
所谓惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除可能会导致很多过期key到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,即当你主动去查过期的key时,如果发现key过期了,就立即进行删除,不返回任何东西。
总结:定期删除是集中处理,惰性删除是零散处理。
有了以上过期策略的说明后,就很容易理解为什么需要淘汰策略了,因为不管是定期采样删除还是惰性删除都不是一种完全精准的删除,就还是会存在key没有被删除掉的场景,所以就需要内存淘汰策略进行补充。
内存淘汰策略
主要有以下几种:
allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的。
volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键。
allkeys-random:加入键的时候如果过限,从所有key随机删除。
volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐。
volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键。
3、支持事务吗?
redis事务就是一个命令执行的队列,将一系列预定义命令包装成一个整体(一个队列)。当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰。
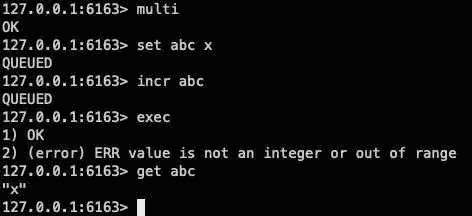
如图示一组操作,如果中间有命令执行失败,不会影响其他命令,也不会回滚,不满足最基本的事务原子性,你觉得redis支持事务吗?
可以发现,就算中间出现了失败,set abc x 这个操作也已经被执行了,并没有进行回滚,从严格的意义上来说 Redis 并不具备原子性。
4、怎么保证DB和Redis的数据一致性?
这个问题产生的背景就是,假如你的数据在缓存redis和mysql中都保留了一份,那么我要修改这份数据,是先修改缓存,再去修改数据库,还是修改数据库,之后再去修改缓存的数据呢?
没有最完美答案,只能说根据项目去决定使用哪种方式,下面我列举几种方案,各有优缺点,大家理解性的去记忆
缓存延时双删

删除缓存重试机制
延时双删,如果第二步的删除缓存失败呢?删除失败会导致脏数据哦~
删除失败就多删除几次呀,保证删除缓存成功呀~ 所以可以引入删除缓存重试机制
同步biglog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。
其实,还可以通过数据库的binlog来异步淘汰key,但是分析binlog又得引入其他组件。维护成本较高。
5、Redis和MYSQL、MongoDB区别?
目前,主流数据库包括关系型(SQL)和非关系型(NoSQL:Not Only SQL)两种。
MYSQL:关系型数据库里应用最广泛的数据库,支持事务。
MongoDB:NOSQL类数据库。特点:按照文档格式来存储,在NOSQL中应用比较广泛。适用于存储相当大的数据量。不支持事务。单表存储量比mysql大。
Redis:也属于NOSQL类数据库。特点:数据存储在内存里,所以读写速度非常快。有持久化过程,会把存在内存里的数据刷到硬盘上。
正在做测试的朋友可以进来交流,群里给大家整理了大量学习资料和面试题项目简历等等....