1 感知机
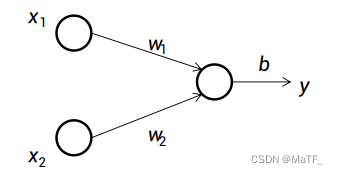
y = f ( ∑ i = 1 n w i x i − b ) y=f(\sum\limits_{i=1}^{n}w_ix_i-b) y=f(i=1∑nwixi−b)
其中, f f f 常常取阶跃函数或 Sigmoid 函数。
学习规则:
Δ w i = η ( y − y ^ ) x i w i ← w i + Δ w i \Delta w_i=\eta(y-\hat{y})x_i\\ w_i \leftarrow w_i+\Delta w_i Δwi=η(y−y^)xiwi←wi+Δwi
其中, y ^ \hat{y} y^ 为感知机的输出, η \eta η 为学习率。
单层感知机只能解决线性可分问题,要解决非线性可分问题(如异或),可考虑引入多层功能神经元。
2 反向传播(BackPropagation)
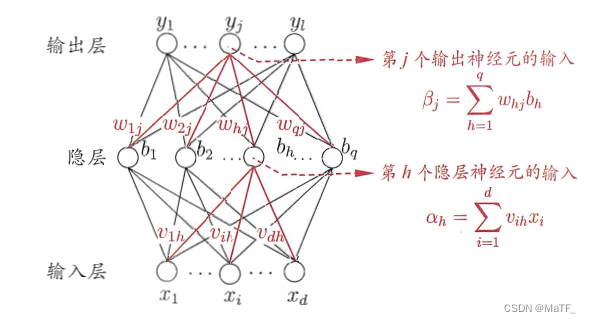
训练集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) ⋯ ( x m , y m ) , x ∈ R d , y ∈ R l D={(x_1,y_1),(x_2,y_2)\cdots(x_m,y_m)},x\in\mathbb{R}^d,y\in\mathbb{R^l} D=(x1,y1),(x2,y2)⋯(xm,ym),x∈Rd,y∈Rl ,隐层的阈值为 γ h \gamma_h γh,输出层的阈值为 θ j \theta_j θj,两个层的激活函数均为 Sigmoid 函数( S ′ ( x ) = S ( x ) [ 1 − S ( x ) ] S'(x)=S(x)[1-S(x)] S′(x)=S(x)[1−S(x)] )。对训练例 ( x k , y k ) (x_k,y_k) (xk,yk),输出为 y ^ k = ( y ^ 1 k , y ^ 2 k , ⋯ , y ^ l k ) {\hat y^k}=({\hat y_1^k},{\hat y_2^k},\cdots,{\hat y_l^k}) y^k=(y^1k,y^2k,⋯,y^lk),其中, y ^ j k = f ( β j − θ j ) {\hat y_j^k}=f(\beta_j-\theta_j) y^jk=f(βj−θj)。则整个网络对该训练例的均方误差为:
E k = 1 2 ∑ j = 1 l ( y ^ j k − y j k ) 2 E_k=\frac{1}{2}\sum\limits_{j=1}^{l}({\hat y_j^k}-y^k_j)^2 Ek=21j=1∑l(y^jk−yjk)2
我们需要确定的参数为:输入层到隐层的权值,共 d ⋅ q d\cdot q d⋅q 个;隐层的阈值,共 q q q 个;隐层到输出层的权值 q ⋅ l q\cdot l q⋅l 个;输出层的阈值,共 l l l 个。在每一轮迭代中,任意参数 v v v 的更新均可以表示为:
v ← v + Δ v , 其中 Δ v = − η ∂ E k ∂ v v\leftarrow v+\Delta v,\ 其中\Delta v = -\eta\frac{\partial E_k}{\partial v} v←v+Δv, 其中Δv=−η∂v∂Ek
例如,对隐层到输出层的权值 w h j w_{hj} whj,有:
∂ E k ∂ w h j = ∂ E k ∂ y ^ j k ⋅ ∂ y ^ j k ∂ β j ⋅ ∂ β j ∂ w h j (链式法则) = ( y ^ j k − y j k ) ⋅ y ^ j k ⋅ ( 1 − y ^ j k ) ⋅ b h \begin{align} \frac{\partial E_k}{\partial w_{hj}}&=\frac{\partial E_k}{\partial {\hat y^k_j}}\cdot\frac{\partial {\hat y^k_j}}{\partial \beta_j}\cdot\frac{\partial \beta_j}{\partial w_{hj}}(链式法则)\\ &=({\hat y^k_j}-y^k_j)\cdot{\hat y^k_j}\cdot(1-{\hat y^k_j})\cdot b_h \end{align} ∂whj∂Ek=∂y^jk∂Ek⋅∂βj∂y^jk⋅∂whj∂βj(链式法则)=(y^jk−yjk)⋅y^jk⋅(1−y^jk)⋅bh
记 g j = ( y j k − y ^ j k ) ⋅ y ^ j k ⋅ ( 1 − y ^ j k ) g_j=({y^k_j}-{\hat y^k_j})\cdot{\hat y^k_j}\cdot(1-{\hat y^k_j}) gj=(yjk−y^jk)⋅y^jk⋅(1−y^jk),于是有:
Δ w h j = η g j b h \Delta w_{hj}=\eta g_jb_h Δwhj=ηgjbh
同理得 Δ θ j = − η g j 、 Δ v i h = η e h x i 、 Δ γ h = − η e h \Delta\theta_j=-\eta g_j、\Delta v_{ih}=\eta e_hx_i、\Delta\gamma_h=-\eta e_h Δθj=−ηgj、Δvih=ηehxi、Δγh=−ηeh,其中:
e h = − ∂ E k ∂ b h ⋅ ∂ b h ∂ α h = − b h ⋅ ( 1 − b h ) ⋅ ∑ j = 1 l ∂ E k ∂ β j ⋅ ∂ β j ∂ b h = b h ⋅ ( 1 − b h ) ⋅ ∑ j = 1 l g j w h j \begin{align} e_h&=-\frac{\partial E_k}{\partial b_{h}}\cdot\frac{\partial b_h}{\partial \alpha_h}\\ &=-b_h\cdot(1-b_h)\cdot\sum\limits_{j=1}^{l}\frac{\partial E_k}{\partial \beta_{j}}\cdot\frac{\partial \beta_j}{\partial b_{h}}\\ &=b_h\cdot(1-b_h)\cdot\sum\limits_{j=1}^{l}g_jw_{hj} \end{align} eh=−∂bh∂Ek⋅∂αh∂bh=−bh⋅(1−bh)⋅j=1∑l∂βj∂Ek⋅∂bh∂βj=bh⋅(1−bh)⋅j=1∑lgjwhj
BP 算法的流程为:

BP 算法的目标是最小化累积误差 E = 1 m ∑ i = 1 k E k E = \frac{1}{m}\sum\limits_{i=1}^{k}E_k E=m1i=1∑kEk ;只要隐层有足够多的神经元,BP 神经网络能以任意精度逼近任意连续函数。
3 卷积神经网络
特点:
- 继承 BP 神经网络的优点
- 权值共享:卷积层、池化层的可训练参数仅与卷积窗的种类有关,每种卷积窗内部的神经元参数一致。(卷积层 or 池化层 → 卷积窗 → 神经元)
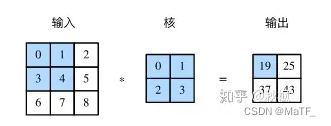
- 卷积层:
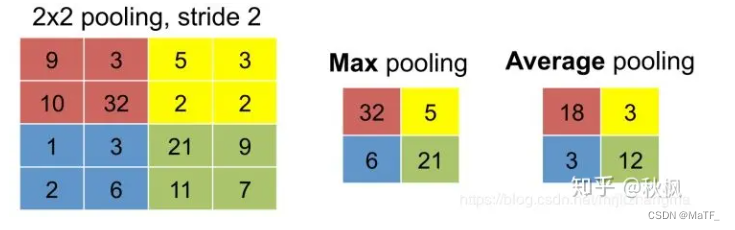
- 池化层:
以 LeNet-5 手写数字为例:
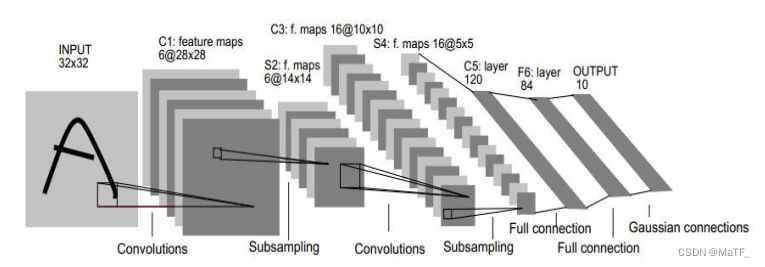
C1 层:
- 输入图片大小:32*32
- 卷积窗大小:5*5
- 卷积窗种类:6
- 输出特征图大小:28*28
- 可训练参数:(5*5+1)*6(每种卷积窗有 25 个权值和 1 个偏置常数)
- 神经元数量:28*28*6(每个输出特征图由 28*28 个神经元构成)
- 连接数:(5*5+1)*28*28*6(每个神经元需要与视野域内的 5*5 个输入连接,还要与本卷积窗的偏置常数连接)
S2 层:
- 输入图片大小:28*28
- 卷积窗大小:2*2
- 卷积窗种类:6(和输入的 6 个图片一一对应)
- 输出下采样图的大小:14*14(与卷积层不同的是,池化层的步长为 2)
- 可训练参数:(1+1)*6(池化层的神经元会先取其视野域内的4个输入的最大值(也可以是最小值、均值等),然后在乘以一个可训练权重 w ,再加上一个可训练偏置,故每种卷积窗的可训练参数为:1+1)
- 神经元数量:14*14*6
- 连接数:(2*2+1)*14*14*6
C3 层:
- 输入图片大小:14*14
- 卷积窗大小:5*5
- 卷积窗种类:16
- 输出特征图大小:10*10
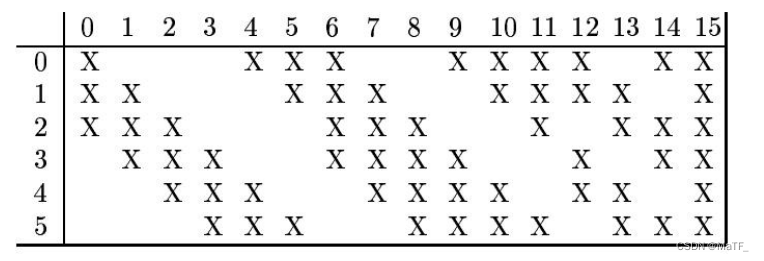
- 可训练参数:(3*6+4*9+6*1)*25+16(6 种卷积窗的每个神经元与 3 个输入图片有关;9 种卷积窗的每个神经元与 4 个输入图片有关;1 种卷积窗的每个神经元与 6 个输入图片有关;每个输入图片有 25 个输入;16 种卷积窗各有 1 个偏置常数)
- 神经元数量:10*10*6
- 连接数:((3*6+4*9+6*1)*25+16)*10*10*6
| 层 | 输入图片大小 | 卷积窗大小 | 卷积窗种类 | 输出特征图大小 | 可训练参数 | 神经元数量 | 连接数 |
|---|---|---|---|---|---|---|---|
| S4 | 10*10 | 2*2 | 16 | 5*5 | (1+1)*16 | 5*5*16 | (16*5*5+1)*120 |
| C5(全连接) | 5*5 | 5*5 | 120 | 1*1 | (16*5*5+1)*120 | 120 | (16*5*5+1)*120 |
| F6(全连接) | 1*1 | 1*1 | 84 | 1*1 | (120+1)*84 | 84 | (120+1)*84 |
OUTPUT层:
- 输入向量:1*84
- 输出向量:1*10