10.1 从生物到人工神经元(From Biological to Artificial Neurons)
人工神经网络经历了70年的跌宕起伏:深度学习与神经网络:浅谈人工神经网络跌宕起伏七十年。
作者相信这次神经网络浪潮是与众不同的,理由如下:
- 现如今有海量数据用于训练,并且ANNs在处理大规模复杂问题时频繁由于其他ML技术。
- 硬件的性能有了明显的提升,使得训练ANNs的时间可以接受。
- 训练算法有所改进。虽然与1990s相比只是轻微的不同,但却得到了巨大提升。
- ANNs的一些理论上的缺陷,在实践中情况要好得多。例如ANN的损失函数是非凸的,使用梯度下降训练时有可能陷入局部最优解。但这一缺陷在实践中很少见,即使出现,也与全局最优解很接近。
- ANNs似乎进入了“投资——进步”的良性循环。
10.1.1 生物神经元(Biological Neurons)
这需要回忆一下高中生物。https://en.wikipedia.org/wiki/Neuron
神经元通过细长的轴突(Axon)与其它神经元进行联系。轴突的长度可能是细胞体的几倍,也可能是成千上万倍。
虽然单个神经元很简单,但每个神经元都会与数以千计的神经元相联系。数十亿的神经元结合在一起形成巨大的网络,就能进行高度复杂的计算。
10.1.2 逻辑运算神经元(Logical Computations with Neurons)
使用神经元进行或、与、非等运算。
10.1.3 感知机(The Perceptron)
感知机是最简单的ANN架构,由Frank Rosenblatt于1957年发明。它基于被称作linear threshold unit (LTU)的人工神经元。LTU首先计算输入值的加权和($z = w_1x_1 + w_2x_2 + \cdots + w_nx_n = W^T \cdot X$),然后对$z$应用一个阶梯函数(step function):
$h_W(x) = step(z) = step(W^T \cdot X)$。
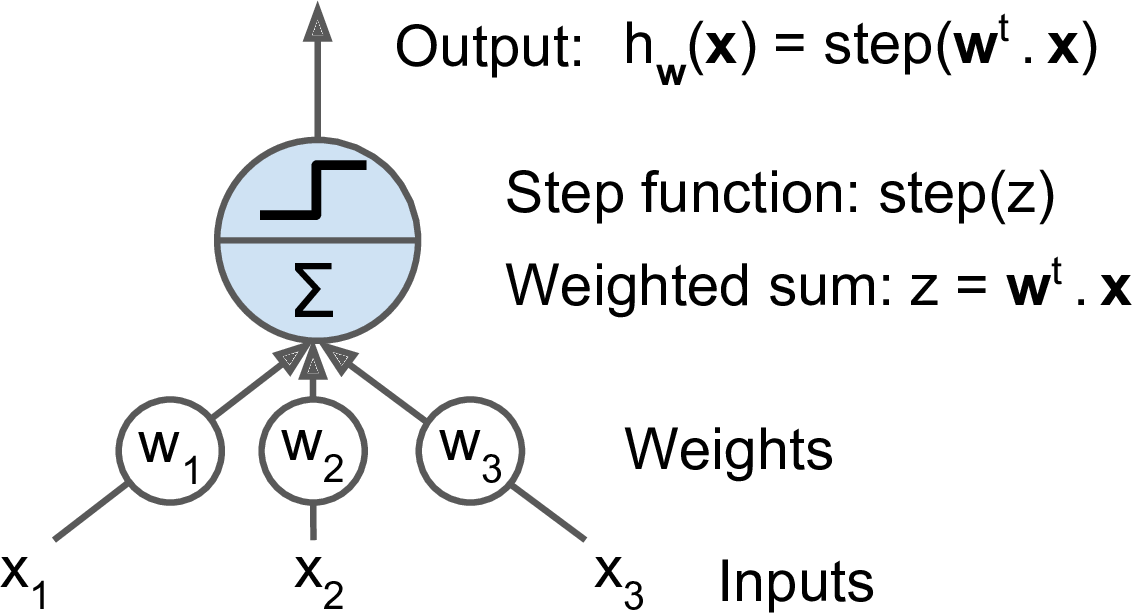
图10-4. LTU
感知机常用阶梯函数:
\begin{align*}
\mbox{heaviside}(z) = \left\{\begin{matrix}
0 \quad \mbox{if} \quad z < 0 \\
1 \quad \mbox{if} \quad z \geq 0
\end{matrix}\right.
\end{align*}
\begin{align*}
\mbox{sgn}(z) = \left\{\begin{matrix}
-1 &\quad \mbox{if} \quad z < 0 \\
0 &\quad \mbox{if} \quad z = 0 \\
+1 &\quad \mbox{if} \quad z < 0
\end{matrix}\right.
\end{align*}
感知机学习规则:
$w_{i,j}^{\mbox{(next step)}} = w_{i,j} + \eta(y_j - \hat{y}_j)x_i$
(书中在括号里面写的是$\hat{y}_j - y_j$,这是不对的,可参考https://en.wikipedia.org/wiki/Perceptron里面的算法步骤)
其中:
- $w_{i,j}$是第i个输入神经元到第j个输出神经元的权重。
- $x_i$是当前训练样本的第i个值。
- $\hat{y}_j$是当前训练样本的第j个输出。