在2019年的亚马逊云科技re:Invent上,亚马逊云科技发布了新的基础设施Inferentia芯片和Inf1实例。Inferentia是一种高性能机器学习推理芯片,由亚马逊云科技定制设计,其目的是提供具有成本效益的大规模低延迟预测。时隔四年,2023年4月亚马逊云科技发布了Inferentia2芯片和Inf2实例,旨在为大型模型推理提供技术保障。
Inf2实例提供高达2.3 petaflops的DL性能和高达384 GB的总加速器内存以及9.8 TB/s的带宽。亚马逊云科技Neuron SDK与PyTorch和TensorFlow等流行的机器学习框架原生集成。因此,用户可以继续使用现有框架和应用程序代码在Inf2上进行部署。开发人员可以在AWS Deep Learning AMI、AWS Deep Learning容器或Amazon ECS、Amazon EKS和Amazon SageMaker等托管服务中使用Inf2实例。
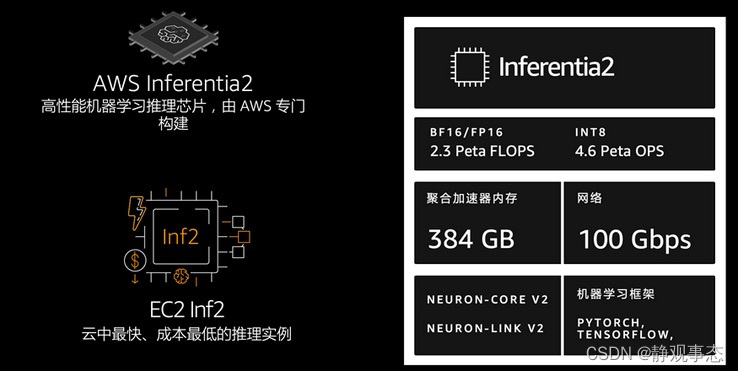
Amazon EC2 Inf2实例的核心是亚马逊云科技Inferentia2设备,每个设备包含两个NeuronCores-v2。每个NeuronCore-v2都是一个独立的异构计算单元,具有四个主要引擎:张量(Tensor)、向量(Vector)、标量(Scalar)和GPSIMD引擎。张量引擎针对矩阵运算进行了优化。标量引擎针对ReLU(整流线性单元)函数等元素运算进行了优化。向量引擎针对非元素向量操作进行了优化,包括批量归一化或池化。
亚马逊云科技Inferentia2支持多种数据类型,包括FP32、TF32、BF16、FP16和UINT8,因此用户可以根据工作负载选择最合适的数据类型。它还支持新的可配置FP8(cFP8)数据类型,这与大型模型特别相关,因为它减少了模型的内存占用和I/O要求。
亚马逊云科技Inferentia2嵌入了支持动态执行的通用数字信号处理器(DSP),因此无需在主机上展开或执行控制流运算符。亚马逊云科技Inferentia2还支持动态输入形状,这对于输入张量大小未知的模型(例如处理文本的模型)来说非常关键。
亚马逊云科技Inferentia2支持用C++编写的自定义运算符。Neuron Custom C++Operators使用户能够编写在NeuronCores上本机运行的C++自定义运算符。使用标准PyTorch自定义运算符编程接口将CPU自定义运算符迁移到Neuron并实现新的实验运算符,所有这些都不需要对NeuronCore硬件有深入了解。
Inf2实例是Amazon EC2上的第一个推理优化实例,可通过芯片之间的直接超高速连接(NeuronLink v2)支持分布式推理。NeuronLink v2使用集体通信(Collective Communications)运算符(例如all-reduce)在所有芯片上运行高性能推理管道。
Neuron SDK
亚马逊云科技Neuron是一种SDK,可优化在亚马逊云科技Inferentia和Trainium上执行的复杂神经网络模型的性能。亚马逊云科技Neuron包括深度学习编译器、运行时和工具,这些工具与TensorFlow和PyTorch等流行框架原生集成,它预装在亚马逊云科技Deep Learning AMI和Deep Learning Containers中,供客户快速开始运行高性能且经济高效的推理。
Neuron编译器接受多种格式(TensorFlow、PyTorch、XLA HLO)的机器学习模型,并优化它们以在Neuron设备上的运行。Neuron编译器在机器学习框架内调用,其中模型由Neuron Framework插件发送到编译器。生成的编译器工件称为NEFF文件(Neuron可执行文件格式),该文件又由Neuron运行时加载到Neuron设备。
Neuron运行时由内核驱动程序和C/C++库组成,后者提供API来访问Inferentia和Trainium Neuron设备。TensorFlow和PyTorch的Neuron ML框架插件使用Neuron运行时在NeuronCores上加载和运行模型。Neuron运行时将编译的深度学习模型(也称为Neuron 可执行文件格式(NEFF))加载到Neuron设备,并针对高吞吐量和低延迟进行了优化。