1、数据库开发
1.1 数据与数据管理
什么是信息?
信息是指对现实世界存在方式或运动状态的反应。
什么是数据?
数据是指存储在某一媒体上,能够被识别的物理符号;
数据的概念在数据处理领域已经被大为拓宽,不仅包括字符组成的文本形式的数据,而且还包括其他类型的数据(如音频、视频等)
信息与数据的关系:
信息与数据是相互依赖存在的,数据是信息的载体,信息是数据的内涵;
数据处理是指数据及信息相互转换的过程;
从数据处理的角度而言,信息是一种被加工成特定形式的数据。
数据处理
数据处理的核心是数据管理技术,其中数据管理技术是指对数据的分类、组织、编码、存储、检索和维护的技术。
数据管理技术的发展经历了几个阶段:人工管理阶段、文件系统阶段、数据库系统阶段。
1.2 数据库系统
定义:数据库系统(DBS)是指计算机中引入数据库后的系统构成。
组成:数据库、操作系统、数据库管理系统、数据库管理应用系统、数据库管理员(DBA)、用户
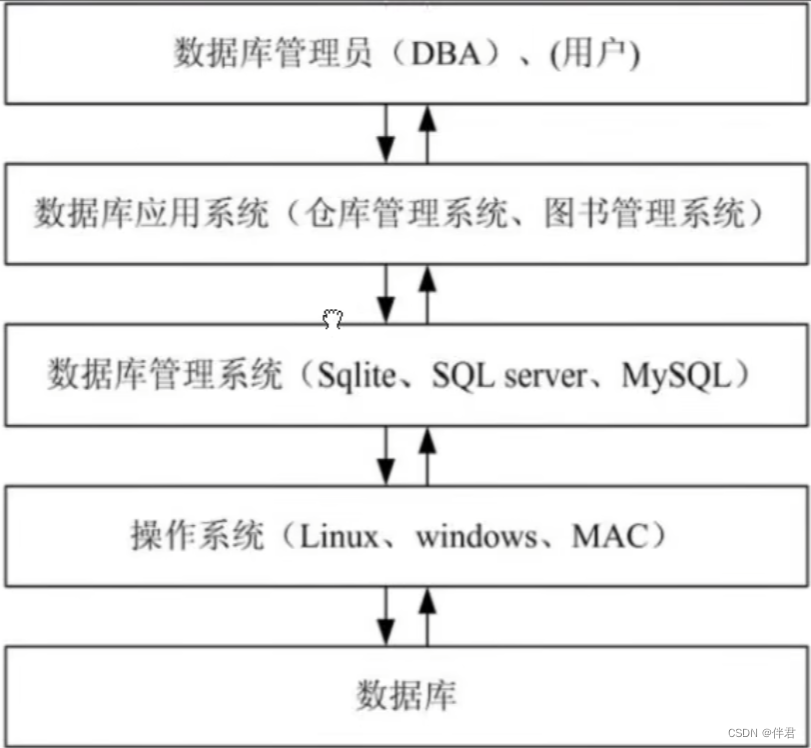
1.3 数据库系模型
数据库管理系统根据数据模型对数据进行存储和管理
数据模型应满足三方面的要求:
一是能比较真实地模拟现实世界;
二是容易为人理解;
三是便于在计算机上实现。
数据结构、数据操作和完整性约束是构成数据模型地三要素。其中数据地完整性约束指的是为了放置不符合规范地数据进入数据库。
在用户对数据进行插入、修改、删除等操作时,DBMS自动按照一定的约束条件对数据进行监测,使不符合规范的数据不能进入数据库,以确保数据库中存储的数据正确、有效、相容。
数据库管理系统数据模型:
数据库管理系统采用的数据模型主要有:层次模型、网状模型和关系模型。
层次模型是种典型的树形结构,其特点是:
1、有且仅有一个节点无父节点,这个节点被称为根节点;
2、其他节点有且仅有一个父节点;
3、同一父节点的子节点被称为兄弟节点;
4、没有子节点的节点称为叶节点。
网状模型构成了比层次结构模型更加复杂的网状结构,其特点是:
1、允许一个以上的节点无父节点;
2、一个节点可以有多个的父节点;
关系模型数据的逻辑结构是一张二维表,一行为一个对象成员,每一列为对象的一个属性。其特点为:
1、每一列中的分量可以是类型相同的数据
2、列的顺序可以是任意的;
3、行的顺序可以是任意的;
4、表中的分量是不可在分割的最小数据项,即表中不允许有子表。
关系数据库采用关系模型作为数据的组织方式。关系数据库因其严格的数学理论、使用简单灵活、数据独立性强等特点,而被公认为最有前途的一种数据库管理系统,它目前已成为占据主导地位的数据库管理系统。
1.4 常见的数据库
常见的数据库有:
ORACLE、MySQL、SQL server、Access、Sybase、SQLite
1、ORACLE:
ORACLE是甲骨文公司开发的一款数据库,是一种适用于大型、中型和微型计算机的关系数据库管理系统,它使用SQL语言作为它的数据库语言。
2、MySQL
MySQL是一个开放源码的小型关系型数据库管理系统,开发者为瑞典MySQL AB公司,目前MySQL被广泛地应用在Internet上的中小型网站,具有体积小、速度快、成本低、开发源码的特点。
3、SQL server
真正的客户机/服务器体系结构,微软Microsoft出品的一款数据库软件,图形化界面,使系统管理和数据库管理更加直观/简单;具有很好的伸缩性,可跨越从运行Windows 95/98型电脑到运行Windows 2000的大型多处理器等多种平台使用。
4、Access
Access是由微软发布的关系数据库管理系统。它结合了MicrosoftJet Database Engine和图形用户界面两项特点,是Microsoft Office的系统程序之一。它是一种桌面数据库,只适合数据量少的应用,在处理少量数据和单机访问的数据库时是很好的,效率也高,但是它的同时访问客户端不能多于4个。Access数据库有一定的极限,如果数据达到100M左右,很容易造成服务器iis假死,或者消耗掉服务器的内存导致服务器崩溃。
5、Sybase
Sybase数据库产品主要有三种版本,一是UNIX操作系统下运行的版本,二是Novell Netware环境下运行的版本,三是Windows NT环境下运行的版本。Sybase数据库特点:
1、基于客户/服务器体系结构的数据库
2、它是真正开放的数据库,容易移植;
3、它是一种高性能的数据库。
1.5 SQLite数据库
1.5.1 SQLite数据库简介
SQLite是一个开源的、内嵌式的关系型数据库,第一个版本诞生于2000年5月,目前最高版本为SQLite3。
下载地址:https://www.sqlite.org/download.html
安装方法(Ubuntu下)
sudo apt-get install sqlite3
安装方法(windows下与C++联用)
下载sqlite-amalgamation-3410200.zip(解压后为头文件)、sqlite-dll-win64-x64-3410200.zip以及sqlite-dll-win64-x64-3410200.zip这三个文件,然后解压放到同一个文件夹Sqlite3下,具体见下图(我这里没有包含第一个文件解压出的头文件)

然后是将sqlite3.def文件生成sqlite.lib文件,主要过程是:首先打开"VS20xx 开发人员命令提示",然后在依次在命令行中输入:
cd D:/Sqlite3
LIB /DEF:sqlite3.def /MACHINE:X64
即可得到sqlite.lib文件,然后就可以按照配库的方式按步就班进行操作。
SQLite特性:
1、零配置;
2、可移植;
3、紧凑;
4、简单;
5、灵活;
6、可靠
7、易用。
1.5.2 SQL语句基础
SQL是一种结构化查询语言(Structured Query Language)的缩写,SQL是一种专门用来与数据库通信的语言。目前SQL已成为应用最广的数据库语言。SQL已经被众多商用数据库管理系统产品所采用,不同的数据库管理系统在其实践过程中都对SQL规范做了某些改编和扩充。故不同数据库管理系统之间的SQL语言不能完全相互通用。
SQLite数据类型:
一般数据采用固定的静态数据类型,而SQLite采用的是动态数据类型,会根据存入值自动判断。SQLite具有以下五种基本数据类型:
1、interger: 带符号的整型(最多64位);
2、real: 8字节表示的浮点类型;
3、text: 字符类型,支持多种编码(如UTF-8、UTF-16),大小无限制;
4、blob: 任意类型的数据,大小无限制。BLOB(binary large object)二进制大对象,使用二进制保存数据。
5、null: 表示空值。
对数据库文件SQL语句:
1、创建、打开数据库:
sqlite3 .db
提示:
当.db文件不存在时,sqlite会创建并打开数据库文件
当.db文件存在时,sqlite会打开数据库文件
2、退出数据库命令:
.quit或.exit
SQL的语句格式:
所有的SQL语句都是以分号结尾的,SQL语句不区分大小写。两个减号"–"则代表注释。关系数据的核心操作主要有:一、创建、修改删除表;二、添加、修改、删除行;三、查表。
一、创建表:create语句
//语法:create table 表名称(列名称1 数据类型,列名称2 数据类型,列名称3 数据类型,...);
//例子:创建一表格,该表包含3列,列名分别是:"id"、"name"、"addr"
//在终端下输入:
sqlite> create tabel persons(id integer, name text, addr text);
二、创建表:create语句(设置主键)
在用sqlite设计表时,每个表都可以通过primary key手动设置主键,每个表只能有一个主键,设置为主键的列数据不可以重复。
//语法:create table 表名称(
列名称1 数据类型 primary key,
列名称2 数据类型,
列名称3 数据类型,...);
//例子:创建一表格,该表包含3列,列名分别是:"id"、"name"、"addr"
//在终端下输入:
sqlite> create tabel persons(id integer primary key, name text, addr text);
三、修改表
在已有的表中添加列以及修改表名。
//语法: alter table 表名 add 列名 数据类型
sqlite> alter table persons add sex text;
//语法: alter table 表名 rename 表名
sqlite> alter table persons rename stu;
四、删除表
用于删除表(表的结构、属性以及表的索引也会被删除)
//语法: drop table 表名;
sqlite> drop table persons;
五、插入新行:insert into语句(全部赋值)
给一行中的所有列赋值。
//语法:insert into 表名 values(列值1,列值2,列值3,列值4,...);
//注意,当列值为字符串时要加上' '号
sqlite> create table persons (id integer, name text, addr text);
sqlite> insert into persons values(1,'lucky','beijing');
六、修改表中的数据:update语句
使用where根据匹配条件,查找一行或多行,根据查找的结果修改表中相应行的列数(修改哪一列由列名指定)。
//语法:update 表名 set 列1 = 值1 [,列2 = 值2,...][匹配条件]
//匹配:where子句
// where子句用于规定匹配的条件。
//操作符 描述
// = 等于
// <> 不等于
// > 大于
// < 小于
// >= 大于等于
// <= 小于等于
//匹配条件语法: where 列名 操作符 列值
sqlite> update persons set id=2, addr = 'tianjin' where name = 'peter';
七、删除表中的数据:delete语句
使用where根据匹配条件,查找一行或多行,根据查找的结果删除表中查找到的行
//语法:delete from 表名 [匹配条件]
//注意:当表中由多列、多行符合匹配条件时会删除相应的多行
sqlite> delete from person where name = 'peter';
八、查询:select语句(基础)
用于从表中选取数据,结果被存储在一个结果表中(称为结果集)
//语法1:select * from 表名 [匹配条件];
//语法2:select 列名1[,列名2,...] from 表名 [匹配条件];
//提示:星号(*)是选取所有列的通配符
sqlite> select * from persons;
sqlite> select name from person where id = 1;
八、匹配条件语法:(提高)
数据库提供了丰富的操作符配合where子句实现了多种多样的匹配方法。
如:
(1)in操作符
(2)and操作符
(3)or操作符
(4)between and操作符
(5)like操作符
(6)not操作符
// in允许我们在where子句中规定多个值
// 匹配条件语法:where 列名 in (列值1,列值2,...)
// 例:1、select * from 表名 where 列名 in (值1,值2,...);
// 2、select 列名1[,列名2,...] from 表名 where 列名 in(列值1,列值2,...);
sqlite> select * from persons where id in (1,2);
sqlite> select name from persons where id in (1,2);
// and 可在where子语句中把两个或多个条件结合起来(多个条件之间是与的关系)
// 匹配条件语法:where 列1 = 值1 [and 列2 = 值2 and...]
// 例: 1、select * from 表名 where 列1 = 值1 [and 列2 = 值2 and ...];
// 2、select 列名1[,列名2,...] from 表名 where 列1 = 值1 [and 列2 = 值2 and ...];
sqlite> select * from persons where id = 1 and addr = 'beijing';
sqlite> select name from persons where id = 1 and addr = 'beijing';
//or可在where子语句中把两个或多个条件结合起来(多个条件之间是或的关系)
// 匹配条件语法:where 列1 = 值1 [or 列2 = 值2 or...]
// 例: 1、select * from 表名 where 列1 = 值1 [or 列2 = 值2 or ...];
// 2、select 列名1[,列名2,...] from 表名 where 列1 = 值1 [or 列2 = 值2 or ...];
sqlite> select * from persons where id = 1 or addr = 'beijing';
sqlite> select name from persons where id = 1 or addr = 'beijing';
//操作符between A and B会选介于A、B之间的数据范围。这些值可以是数值、文本或日期
//注意:不同的数据库对between A and B操作符的处理方式是有差异的(有的包含A,B,有的不包含A,B,有的只包含一边)
// 匹配条件语法:where 列名 between A and B
// 例: 1、select * from 表名 where 列名 between A and B;
// 2、select 列名1[,列名2,...] from 表名 where 列名 between A and B;
// 注:匹配字符串时会以ascii顺序匹配
sqlite> select * from persons where id between 1 and 3;
sqlite> select name from persons where id between 1 and 3;
//like 用于模糊查找
// 匹配条件语法:where 列名 like 列值
// 若列值为数字,相当于列名=列值
// 若列值为字符串,可以用通配符“%”代表缺少的字符(一个或多个)
sqlite> select * from persons where id like 3;
sqlite> select * from persons where addr like "%jing%";
//not 可取出原结果集的补集
//匹配条件语法:where 列名 not in 列值 等
//例: 1、where 列名 not in (列值1,列值2,...);
// 2、where not(列1 = 值1 [and 列2 = 值2 and...])
// 3、where not(列1 = 值1 [or 列2 = 值2 or...])
// 4、where 列名 not between A and B
// 5、where 列名 not like 列值
// order by 语句根据指定的列对结果集进行排序(默认按照升序对结果集进行排序,可使用desc关键字按照降序对结果集进行排序)
// 例:升序
// select * from 表名 order by 列名
// 降序
// select * from 表名
九、复制表以及修改表结构
//1、复制一张表
create table tbl2 as select * from tbl1;
//2、复制一张表的部分内容
create table tbl2 as select * from tbl1 where id =104;
//3、修改表的结构
//第一步:创建新表
create table ntbl(id interger,name text,addr text);
//第二步:导入数据(如果有主键,要注意数据不要重复)
insert into ntbl(id,name,addr) select id,name,addr from tbl1;
//第三步:修改表名
alter table ntbl rename tbl1;
十、事务
事务可以使用BEGIN TRANSACTION命令或简单的BEGIN命令来启动。此类事务通常会持续执行下去,直到遇到下一个COMMIT或ROLLBACK命令。不过在数据库关闭或发生错误时,事务处理也会回滚。以下是启动一个事务的简单语法:
在SQLite中,默认情况下,每条SQL语句自成事务。
begin:开始一个事务,之后的所有操作都可以取消
commit:使begin后的所有命令得到确认
rollback:取消begin后的所有操作
例:
sqlite->begin;
sqlite->delete from persons
1.5.3 SQL语句进阶
一、函数和聚合
函数:SQL语句支持利用函数来处理数据,函数一般是在数据上执行的,它给数据的转换和处理提供了方便。
常用的文本处理函数有:
length() 返回字符串的长度
lower() 将字符串转换为小写
upper() 将字符串转换为大写
语法:select 函数名(列名) from 表名;
常用的聚集函数:使用聚集函数,用于检索数据,以便分析和报表生成
avg() 返回某列的平均值
count() 返回某列的行数
max() 返回某列的最大值
min() 返回某列的最小值
sum() 返回某列值之和
二、数据分组group by
分组数据,以便能汇总表内容的子集,常和聚合函数搭配使用。例如查询每个班级中的人数、平均数等等。
使用:select 列名1[,列名2,…]from 表名 group by 列名
sqlite>select class,count(*) from persons group by class;
三、过滤分组 having
除了能用group by分组数据外,还能通过having实现包括哪些分组,排除那些分组。
使用:select 函数名(列名1[),列名2,…]from 表名 group by 列名 having 函数名 限制值
//查看班级平均分大于90的班级
sqlite>select class,avg(score) from persons group by class having avg(score) >= 90
四、约束
管理如何插入或处理数据库数据的规则
常见约束分类:
主键、唯一约束、检查约束
主键:
唯一的标识一行(一张表中只能有一个主键)
主键应当是对用户没有意义的(常用于索引)
永远不要更新主键,否则违反用户没有意义原则
主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等
主键应当由计算机自动生成(保证唯一性)
语法:
create table 表名称 (
列名称1 数据类型 primary key, 列名称2 数据类型, 列名称3 数据类型,…);
唯一约束:
用来保证一个列(或一组列)中数据唯一,类似于主键,但跟主键有区别
表可包含多个唯一约束,但只允许一个主键
唯一约束列可修改或更新
创建表时,通过unique来设置
语法:
create table 表名(列名称1 数据类型 unique[, 列名称2 数据类型 unique,…]);
检查约束:
用来保证一个列(或一组列)中的数据满足一组指定的条件。
指定范围,检查最大或最小范围,通过check实现
create table 表名 (列名 数据类型 check(判断语句));
五、联结表(多表操作)
概念:在保存数据时往往不会将所有数据保存在一个表中,而是在多个表中存储,联结表就是从多个表中查询数据。在一个表中不利于分解数据,也容易使相同数据出现多次,浪费存储空间;使用联结表查看各个数据更直观,这使得在处理数据时更简单。
例如,学生每年的考试成绩,学生个人信息基本固定(包括学号、姓名、地址等);把所有信息放在同一个表中必然会造成学生的学号等基本信息重复。
分表优点:
将学生信息和成绩分开存储,节省空间,处理简单,效率更高,在处理大量数据时尤为明显;
使用关系型数据库存储数据,各个表的设计是非常重要的,良好的表设计,能够简化数据的处理,高效率,提高数据库的健壮性。
使用联结:
通过select语句将要联结的所有表以及它们如何关键
常用语句:
select 列名1, 列名2, …from 表1, 表2… where 判断语句;
select * from tbl1, tbl2 where tbl1.id = tbl2.id
sqlite> select name, addr, score, year from persons, grade where persons.id = grade.id and name = 'lucy';
六、视图(虚拟表)
重用SQL语句;
简化复杂的SQL操作(如前面的多表查询)
sqlite> select name, addr, score, year from persons, grade where persons.id = grade.id and name = 'lucy';
使用视图,将整个查询包装成一个名为PersonGrade的虚拟表,简化了查询的SQL语句:
sqlite> create view PersonGrade as select name, addr, score, year from persons, grade where persons.id = grade.id and name = 'lucy';
sqlite> select * from PersonGrade;
删除视图:
语法:drop view 视图名;
总结:
1、视图不包含数据,因此在每次使用视图时,实际上都必须执行查询语句;
2、视图相当于创建视图的时候as后面SQL语句查询得到的结果集合;
3、从返回结果信息(视图)中再检索视图与表一样
七、触发器
概念:SQLite的触发器是数据库的回调函数,它会在指定的数据库事件发生时自动执行调用;
1、只有每当执行delete、insert或update操作时,才会触发,并执行指定的一条或多条SQL语句。(例如,可以设置触发器,当删除persons表中lucy的信息时,自动删除grade表中与lucy相关的信息)
2、触发器常用于保证数据一致,以及每当更新或删除表时,将记录写入日志表
创建触发器:
语法:
create trigger 触发器名 [before/after] [insert|update|delete] on 表名 begin 语句; end;
例如:create trigger tg_delete after delete on persons begin delete from grade where id = old.id;
说明:当执行:delete from persons where id = 1;语句时,事件触发,执行begin与end之间的SQL语句(即回调函数)
注意:old.id 等价于persons.id,但此处不能写persons.id,old.id代表删除行的id(id代表两个表的关联列)
八、SQLite日志操作和提升查询效率的索引操作
写入日志:sqlite> create table log (time text, data text);
这里要注意,在插入时用到两个函数time(‘now’),date(‘now’)
例如:sqlite> insert into log values(time('now'),date('now'));
常与触发器连用,用来记录操作改变时间。
查询优化-索引:数据库中往往存储了大量的数据,普通查询的默认方法时调用顺序扫描。例如这样一个查询:select * from table where id =10000;如果没有索引,必须遍历整个表,直到ID等于10000的这个行被找到为止。为了提高查询的效率,可以使用索引;
什么是索引?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据表中的特定信息;
索引就是恰当的排序,经过某种算法优化,使查找次数要少的多得多;
缺点:
索引数据可能要占用大量的存储空间,因此并非所有数据都适合索引;
索引改善检索操作的性能,但降低了数据插入、修改和删除的性能;
创建索引:
语法:create index 索引名 on 表名(列名);
查看索引:.indices
删除索引:drop index 索引名;
在终端下输入(id列创建索引,并排序):create index id_index on persons(id);
创建索引注意:
1、在作为主键的列上;
2、在经常需要排序的列上创建索引;
3、在经常使用WHERE子句中的列上面创建索引,加快条件的判断速度。
索引避免使用情况:
1、表的数据量不大;
2、表的大部分操作不是查询;
3、大量出现NULL的情况
1.6 SQLite C 编程
1.6.1 打开、关闭数据库函数
int sqlite3_open(char *db_name, sqlite3 **db);
功能:
打开数据库
参数:
db_name: 数据库文件名,若文件名包含ASCII码表范围之外的字符,则其必须是utf-8编码
sqlite3: 数据库标识,此结构体为数据库操作句柄。通过此句柄可对数据库文件进行相应操作。
返回值:
成功返回SQLITE_OK,失败返回非SQLITE_OK
int sqlite3_close(sqlite3 *db);
功能:
关闭数据库、释放打开数据库时申请的资源
参数:
db: 数据库的标识
返回值:
成功返回SQLITE_OK
失败返回非SQLITE_OK
注意:
sqlite3使用了两个库:pthread、dl,故链接时应加上-lpthread和-ldl
1.6.2 sqlite3中执行SQL语句的方法(回调方法)
sqlite3_exec函数:
int sqlite3_exec(sqlite3 *db,const char *sql,exechandller_t callback,void *arg,char **errmsg);
功能:
执行sql执向的SQL语句,若结果集不为空,函数会调用函数指针callback所指向的函数。
参数:
db: 数据库的标识
sql: SQL语句(一条或多条),以‘;’结尾
callback: 是回调函数指针,当这条语句执行之后,sqlite3会去调用你提供的这个函数
arg: 当执行sqlite_exec的时候传递给回调函数的参数;
errmsg: 存放错误信息的地址,执行失败后可以查阅这个指针;
打印错误信息方法:printf("%s\n",errmsg);
返回:
回调函数指针:
typedef int (*exechandller_t)(void *para,int n_column,char ** column_value,char **column_name);
功能:
此函数由用户定义,当sqlite3_exec函数执行sql语句后,结果集不为空时,sqlite3_exec函数会自动调用此函数,每次调用此函数时会把结果集的一行信息传递给此函数。
参数:
para: sqlite3_exec传给此函数的参数,para为任意数据类型的地址;
n_column: 结果集的列数;
column_value: 指针数据的地址,其存放一行信息中各个列值的首地址;
column_name:指针数据的地址,其存放一行信息中各个列值对应列名的首地址
返回值:
若为非0值,则通知sqlite3_exec终止回调
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "sqlite3.h"
int loadinfo(void *data,int col, char **col_val,char **name){
static int row = 1;
printf("row= %d\n",row++);
for(int i = 0; i < col; i++)
{
printf("%s = %s \n",name[i], val[i]);
}i
return SQLITE_OK;
}
int main(int argc, char ** argv){
sqlite3 *db = NULL;
int ret;
char *err = NULL;
char *sql;
int arg = 33;
ret = sqlite3_open("stu.db", &db);
if(ret != SQLITE_OK){
printf("open error\n");
return -1;
}
sql = "insert into info values(120,'zz','ts')";
sqlite3_exec(db, sql, loadinfo,&arg,&err);
if(err){
printf("err:%s\n",err);
}
sqlite3_close(db);
return 0;
}
1.6.3 sqlite3中执行SQL语句的方法(非回调方法)
sqlite3_get_table函数
int sqlite3_get_table(sqlite3 *db,const char *sql,char ***resultp,int *nrow,int *ncolumn,char **errmsg);
功能:
执行sql指向的sql语句,函数将结果集相关的数据的地址保存在函数的参数中。
参数:
db: 数据库的标识;
sql: SQL语句(一条或多条),以’;‘结尾;
resultp: 指针数据的地址,其记录了结果集的数据。内存布局:先依次存放各列的列名,然后是每一行各列的值
nrow: 结果集的行数(不包含列名)
ncolumn: 结果集的列数
errmsg: 错误信息
sqlite3_free_table函数:
void sqlite3_free_table(char (** resultp);
功能:
释放sqlite3_get_table分配的内容
参数:
结果集数据的首地址
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "sqlite3.h"
int main(int argc, char ** argv){
sqlite3 *db = NULL;
int ret;
char *err = NULL;
char *sql;
char **result;
int row,col;
ret = sqlite3_open("stu.db", &db);
if(ret != SQLITE_OK){
printf("open error\n");
return -1;
}
sql = "insert into info values(120,'zz','ts')";
sqlite3_get_table(db, sql, &result,&row,&col,&err);
if(err){
printf("err:%s\n",err);
sqlite3_close(db);
return -1;
}
//处理读取到的数据
for(int i = 0; i < row * col; i++){
printf("result[%d] = %s\n", i , result[i]);
}
sqlite3_free_table(result);
sqlite3_close(db);
return 0;
}