最近,我可爱的女朋友有一个新的任务,需要复制网页上的部分内容,多达1500多页,到word文档中,既有文字,又有图片,十分复杂。是不是可以使用爬虫的方法解决一下子呢?

首先分析网页:

每一页有30个新闻文章,首先爬取页面内的文章的链接

分析页面后,得到文章链接的样式,再利用正则表达式选出来。
#爬取每一页得链接
list2=[]
url='https://www'
for i in range(170,215):
url3=url+str(i)+'.htm'
r=requests.get(url3,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
pic_urll = re.findall('a href="../(.{5}\d{4}.*)"',demo)
m=pic_urll[0:46]
for j in m:
if j not in list2:
list2.append(j)#去重其中值得注意的是:
去重的方法list1=list(set(list1))会改变顺序不好用。
for j in m:
if j not in list2:
list2.append(j)#去重,这个方法好用。
正则表达式的使用(图片来自中国大学mook)
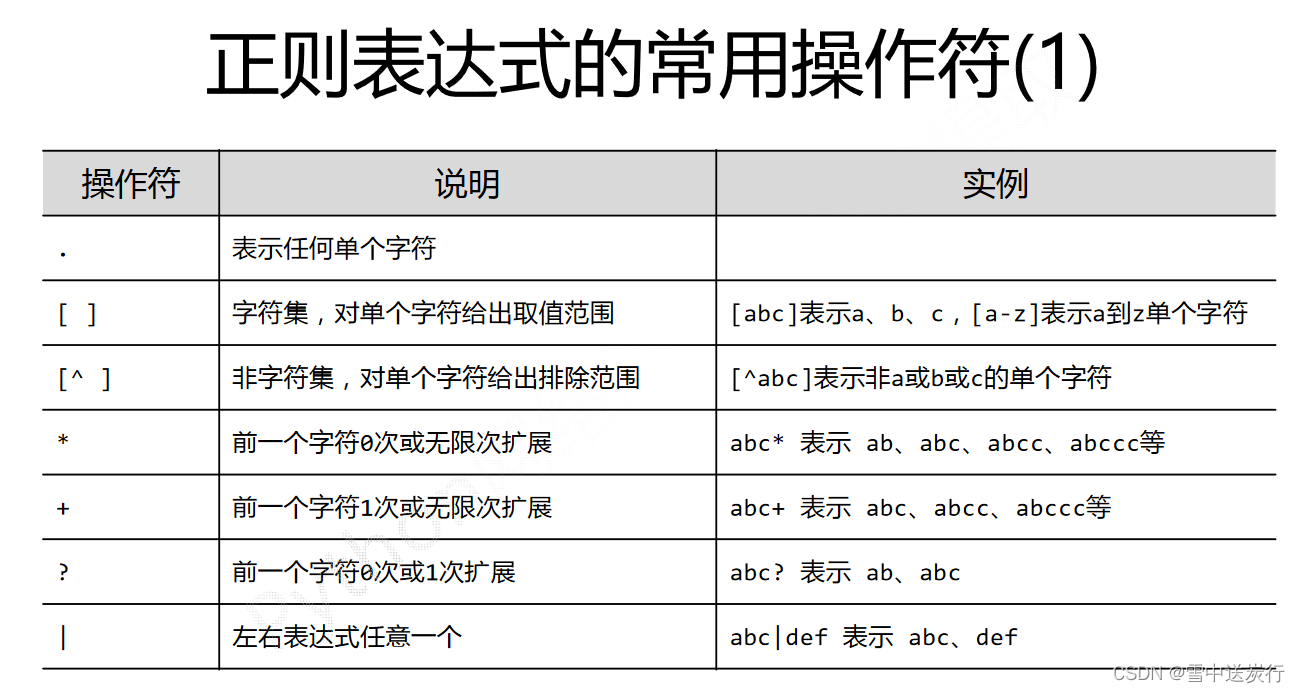
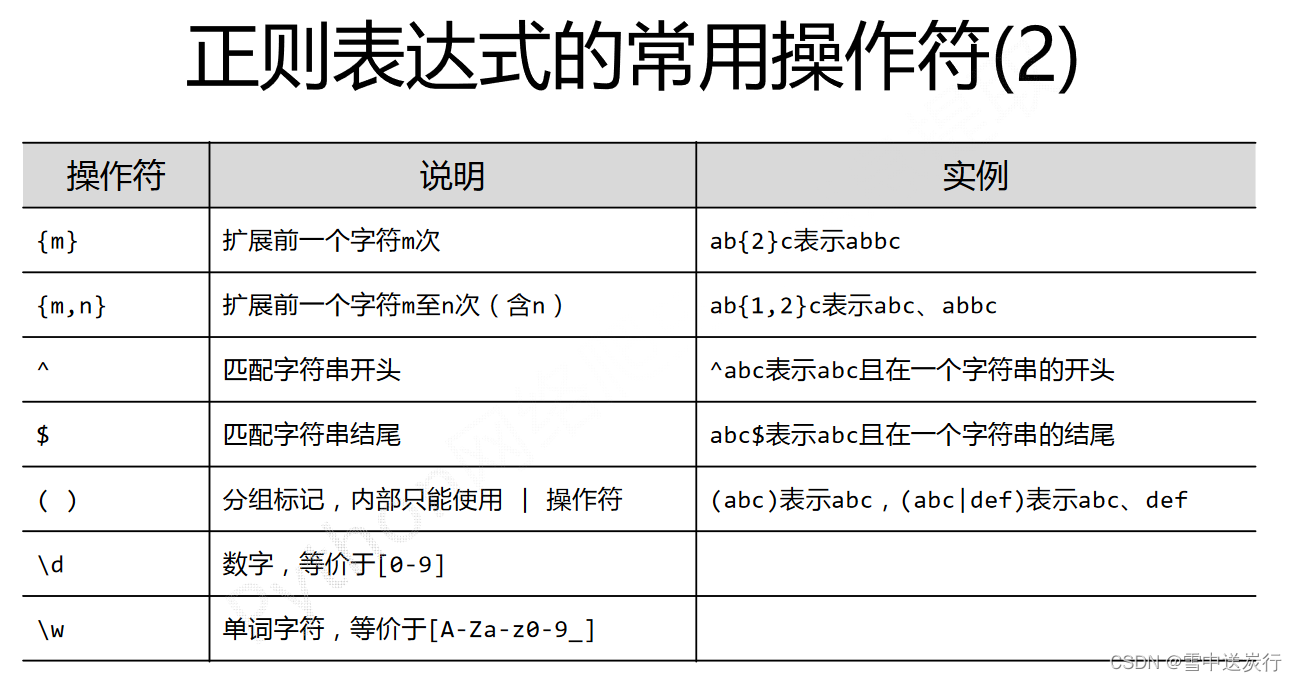
 得到所有文章的链接之后,开始分析每一篇文章页面的树形结构
得到所有文章的链接之后,开始分析每一篇文章页面的树形结构
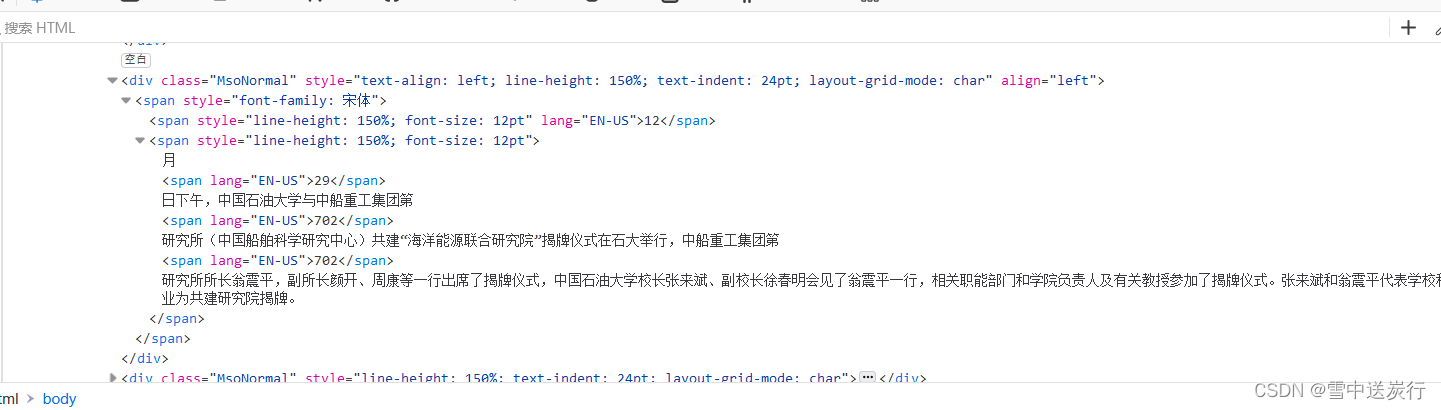
文字利用标签的方式查找,图片的链接利用正则表达式查找。注意图片和文字是分开爬取的并不能完全按照网页的新闻的内容进行下去,只能图片放在最前面。这里求大佬帮一帮怎么能按照原来的排版进行呢?
图片下载下来放到一个文件夹中,使用之后删除,再下载新的文章里的图片.值得注意的一个点是,使用
mm=os.listdir(root)
图片的地址会发生乱序,因此在写入word之前要记得排序
mm.sort(key=lambda x:int(x[:-4]))
写入word用的是python-docx库,对中文及其不友好。
生成word document = Document()
写入标题 head0 = document.add_heading(level=1)
head0.alignment = WD_ALIGN_PARAGRAPH.CENTER
title_run = head0.add_run(head)分页符 document.add_page_break()
写入段落 p = document.add_paragraph()
run = p.add_run(body)保存 document.save('171到215.docx')
整体来说就是爬取每一个文章的链接,然后对文章链接分别爬取文字和图片,再输出到word文档中就可以了。不足的地方特别多,代码就是想到啥功能就直接堆上去,没有任何逻辑可言,没有函数,几乎没有注释,真丑!然后爬取的效率特别慢,一个1500的任务得爬30分钟,不会分布式爬虫,爬虫框架也不会。还有的话,其实新手写爬虫就相当于网络攻击。
输出结果:

我一开始没想管浏览量,浏览量其实是一个动态的数据,我实在是不想写了,女朋友说要有,就搞了个随机数~
全代码:
"""
Created on Thu Aug 4 07:52:15 2022
@author: 18705
"""
import requests
import os
import re
from bs4 import BeautifulSoup
from docx import Document
from docx.shared import Cm, Pt
from docx.oxml.ns import qn # 设置中文格式
import random
from docx.enum.text import WD_ALIGN_PARAGRAPH
#爬取每一页得链接
list2=[]
url='页面链接一部分'
for i in range(170,215):
url3=url+str(i)+'.htm'
r=requests.get(url3,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
pic_urll = re.findall('a href="../(.{5}\d{4}.*)"',demo)
m=pic_urll
for j in m:
if j not in list2:
list2.append(j)
#生成一个word文档
document = Document()
url11='图片链接一部分'
#生成一个目录
p = document.add_paragraph('目录')
for j in range(0,len(list2)):
try:
url4='https://www.cup.edu.cn/news/'+list2[j]
r=requests.get(url4,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
head=soup.body.article.div.contents[3].div.div.div.contents[1].text
p=document.add_paragraph(style='List Number')
run = p.add_run(head)
run.font.name = '仿宋'
run.font.size = Pt(14)
run.font.element.rPr.rFonts.set(qn('w:eastAsia'),'仿宋')
except:
pass
#分页符
document.add_page_break()
root='D://work//pics//'
#生成文章内容
for j in range(0,len(list2)):
try:
url4='https://www.cup.edu.cn/news/'+list2[j]
r=requests.get(url4,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
head=soup.body.article.div.contents[3].div.div.div.contents[1].text
body=soup.body.article.div.contents[3].div.div.div.contents[5].text
data=soup.body.article.div.contents[3].div.div.div.contents[3].text
head0 = document.add_heading(level=1)
head0.alignment = WD_ALIGN_PARAGRAPH.CENTER
title_run = head0.add_run(head)
title_run.font.size = Pt(20)
# 标题中文字体
title_run.font.name = '微软雅黑'
title_run.font.element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑')
except:
pass
#爬取图片并且写入
try:
r=requests.get(url4,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
pic_urll = re.findall('src="/pub/news/images/content/(.*?)"',demo)
pic_urll = pic_urll[0:len(pic_urll)]
except :
pass
for pp in range(0,len(pic_urll)):
url5=(url11+pic_urll[pp])
path=root+str(pp)+'.jpg'
if not os.path.exists(path):
r=requests.get(url5)
with open(path,'wb') as f:
f.write(r.content)
f.close()
mm=os.listdir(root)
mm.sort(key=lambda x:int(x[:-4]))
try:
for l in range(0,len(mm)):
document.add_picture('D:/work/pics/'+mm[l], width=Cm(15))
except :
pass
#将文章得内容写入
try:
sj=random.randint(50,1000)
p = document.add_paragraph()
data=data.split('\n')[:4]
data.append(str(sj))
run = p.add_run(data)
run.font.name = '仿宋'
run.font.size = Pt(14)
run.font.element.rPr.rFonts.set(qn('w:eastAsia'),'仿宋')
run.underline = False
except AttributeError:
pass
p = document.add_paragraph()
run = p.add_run(body)
run.font.name = '仿宋'
run.font.size = Pt(14)
run.font.element.rPr.rFonts.set(qn('w:eastAsia'),'仿宋')
run.underline = False
document.add_page_break()
#每次爬取一次之后删除
for jj in mm :# os.listdir(path_data)#返回一个列表,里面是当前目录下面的所有东西的相对路径
file_data = root + jj#当前文件夹的下面的所有东西的绝对路径
os.remove(file_data)
#保存文件
document.save('171到215.docx')