链接:https://www.zhihu.com/question/519588362
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
作者:徐海洋-mPLUG
https://www.zhihu.com/question/519588362/answer/3075372547
现在进入Multimodal LLM时代,融合方式基本就是VIT+Only Decoder Transformer的结构了,这和之前多模态融合方式还是不同的,并且一般会做降序列操作,要不对于高分辨率图片,视频序列长度扛不住,但是现在LLM支持的序列长度越来越大,后面可能就不需要降序列的操作。
对于之前的多模态融合方式,主要就是图文拼接Self-attention,图文Cross-attention,效果好坏也因任务而异,但是效率还是有差别的,对于19,20年的两阶段基于检测特征的做法来说,由于输入的视觉token比较少,所以两种融合方式速度差不多;但是进入21年之后的端到端的方法,以及backbone进入VIT时代,图文Cross-attention就成为主流了,因为视觉token非常长,代表就是ALBEF,BLIP,Flamingo!!
代表性工作
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections. EMNLP2022.
mPLUG-2: A modularized multi-modal foundation model across text, image and video. ICML2023.
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality.
Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks.
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning. ACL2021 Oral.
Achieving Human Parity on Visual Question Answering. TOIS.
StructuralLM: Structural Pre-training for Form Understanding. ACL2021.
HiTeA: Hierarchical Temporal-Aware Video-Language Pre-training.
Vision Language Pre-training by Contrastive Learning with Cross-Modal Similarity Regulation. ACL2023 Oral.
TRIPS: Efficient Vision-and-Language Pre-training with Text-Relevant Image Patch Selection. EMNLP2022.
Learning Trajectory-Word Alignments for Video-Language Tasks.
EMScore: Evaluating Video Captioning via Coarse-Grained and Fine-Grained Embedding Matching. CVPR2022.
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels.
X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. MM2022.
作者:模术狮 https://www.zhihu.com/question/519588362/answer/2768359672
多模态领域必读论文合集
1.---2014,问题提出,创造性地将CNN和RNN结合起来Deep Visual-Semantic Alignments for Generating Image
2.---CVPR 2015,深度学习image caption开山之作
Show and Tell: A Neural lmage Caption Generator 2015
3.---PMLR 2015第一篇多模态信息区域交互
Show, Attend and Tell: Neural Image Caption Generationwith Visual Attention 2016
4.---CVPR 2016第一篇考虑语义信息,深度理解多模态隐式信息
lmage Captioning with Semantic Attention
5.---CVPR 2016 Dense caption领域lifeifei老师领域2作oralDenseCap: Fully Convolutional Localization Networks forDenseCaptioning
6.---CVPR 2017第一篇加入推理
Knowing When to Look: Adaptive Attention via A Visual
7.---CVPR 2017,重研CNN,在多模态融合中改造CNN+Attention
SCA-CNN: Spatial and Channel-Wise Attention in
ConvolutionalNetworks for Image Captioning(cVPR2017)
8.---CVPR 2018第一篇提出从上到下,从生成到VQA,开始多任务
Bottom-Up and Top-Down Attention for image Caption-ing and VisualQuestion Answering 2018
9.---CVPR2018现在caption领域的metric指标基石Learning to Evaluate lmage Captioning (CVPR2018)
10.---2018 CVPR第一篇提出两阶段生成(一阶段和两阶段是现代两大范式)
作者:走遍山水路
https://www.zhihu.com/question/519588362/answer/2491677317
论文标题:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation来源:NIPS 2021
 解决问题:首先CLIP、ALIGN这类模型更着重于学习不同模态之间特征的匹配或者说是alignment,所以这类方法在图文检索任务上效果很好,但是无法胜任生成式的任务(VQA);但是对于OSCAR、UNITER等模型着重于学习模态特征之间的交互(interaction)或者说是融合(fusion),所以这类方法更适合做生成式的任务。如何实现生成、理解的统一?由于图像特征和文本特征均在各自的语义空间中,仅由一个multimodal encoder进行融合是不够的,效果往往也是不好的。借助于detection的VLP工作是annotation- expensive和compute-expensive的。现阶段基于web-collection的text2image数据集存在noisy,比如图像中出现的实体,文本没有进行描述或者文本中描述的内容与图像中的内容不符,如何从含有噪声的数据集中学习?
解决问题:首先CLIP、ALIGN这类模型更着重于学习不同模态之间特征的匹配或者说是alignment,所以这类方法在图文检索任务上效果很好,但是无法胜任生成式的任务(VQA);但是对于OSCAR、UNITER等模型着重于学习模态特征之间的交互(interaction)或者说是融合(fusion),所以这类方法更适合做生成式的任务。如何实现生成、理解的统一?由于图像特征和文本特征均在各自的语义空间中,仅由一个multimodal encoder进行融合是不够的,效果往往也是不好的。借助于detection的VLP工作是annotation- expensive和compute-expensive的。现阶段基于web-collection的text2image数据集存在noisy,比如图像中出现的实体,文本没有进行描述或者文本中描述的内容与图像中的内容不符,如何从含有噪声的数据集中学习?
主要贡献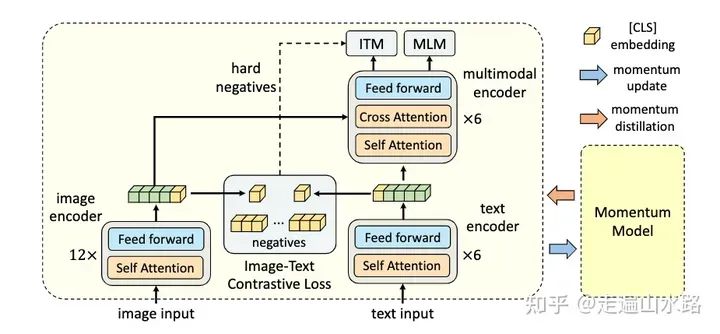 首先利用Image-Text Contrastive-Loss对两个编码器输出的特征头[cls]进行学习,实际上就是对文本和图像的特征进行对齐操作(在我看过的文章中,很多对齐操作都是利用对比学习进行的,比如CVPR22的 Vision-Language Pre-Training with Triple Contrastive Learning),可以将对比学习作为cross-modality alignment的标配
首先利用Image-Text Contrastive-Loss对两个编码器输出的特征头[cls]进行学习,实际上就是对文本和图像的特征进行对齐操作(在我看过的文章中,很多对齐操作都是利用对比学习进行的,比如CVPR22的 Vision-Language Pre-Training with Triple Contrastive Learning),可以将对比学习作为cross-modality alignment的标配
Image-Text Matching利用经过multi-modal encoder之后输出的[cls]来判别是否对应的图像文本对,Mask Language Modeling则利用图像和文本joint feature来预测mask的token,其实上述这两个任务也是VLP的标配了,主要的作用是实现vision feature和language feature的interaction和fusion
利用Momentum Model进行Knowledge Distillation,消除noisy label的影响。(这一点之前看的比较少,可能需要看一些其他论文补充基础)实验结果: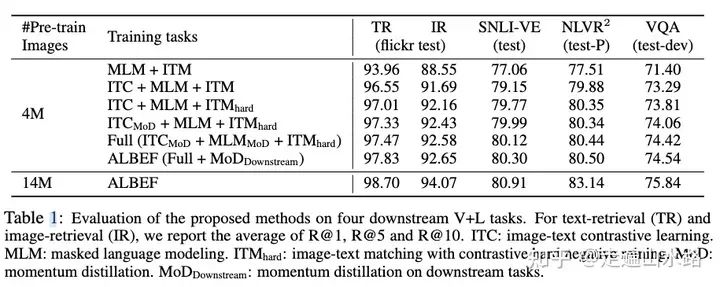
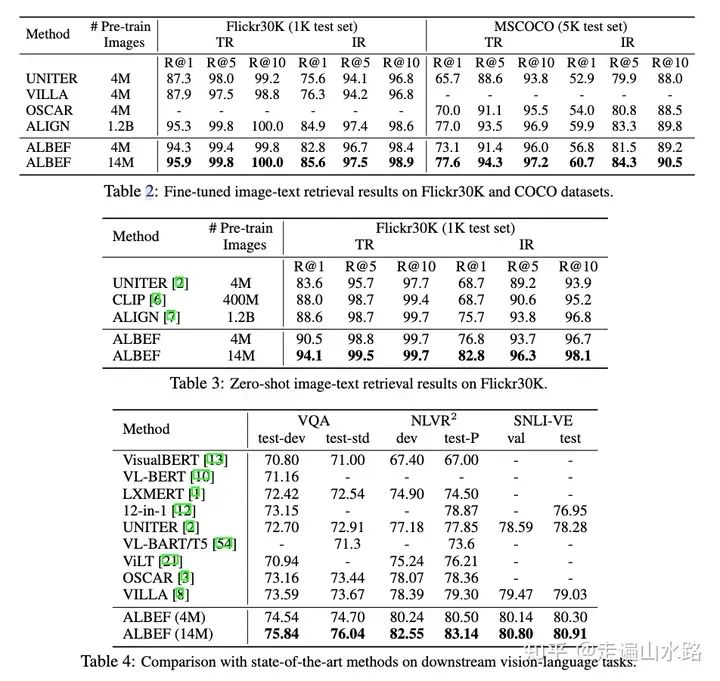 在理解和生成任务上都要好于sota方法,尤其是高于CLIP好多
在理解和生成任务上都要好于sota方法,尤其是高于CLIP好多
我的思考:
对于VLP任务来说,在fusion之前利用对比学习进行多模态特征的alignment,目前来看是很有必要的,而且很提点。并且以后的VLP任务应该也会按照此篇paper趋势,底层是双塔结构做特征的提取和对齐操作,上游利用multi modal encoder 进行特征的fusion和interaction在我的项目之中,首先是否可以尝试在CLIP特征输出的基础上进行对比学习式的对齐操作,然后在进行融合操作,使得效果更好 (实际上,CLIP-CAM做了融合但没有对齐)。其次就是我的自建数据肯定也是有noisy info的,是否也可以利用知识蒸馏的方式降低噪音的影响呢?需要好好思考!这篇工作其实可以作为任意两种不同模态的数据进行joint learning的范式!可以套用!
不足:
这篇工作还是没有考虑intra-modality之间的对应关系也没有考虑local和global之间的对应关系实际上上述不足,在CVPR22中的Vision-Language Pre-Training with Triple Contrastive Learning工作中已经解决。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
