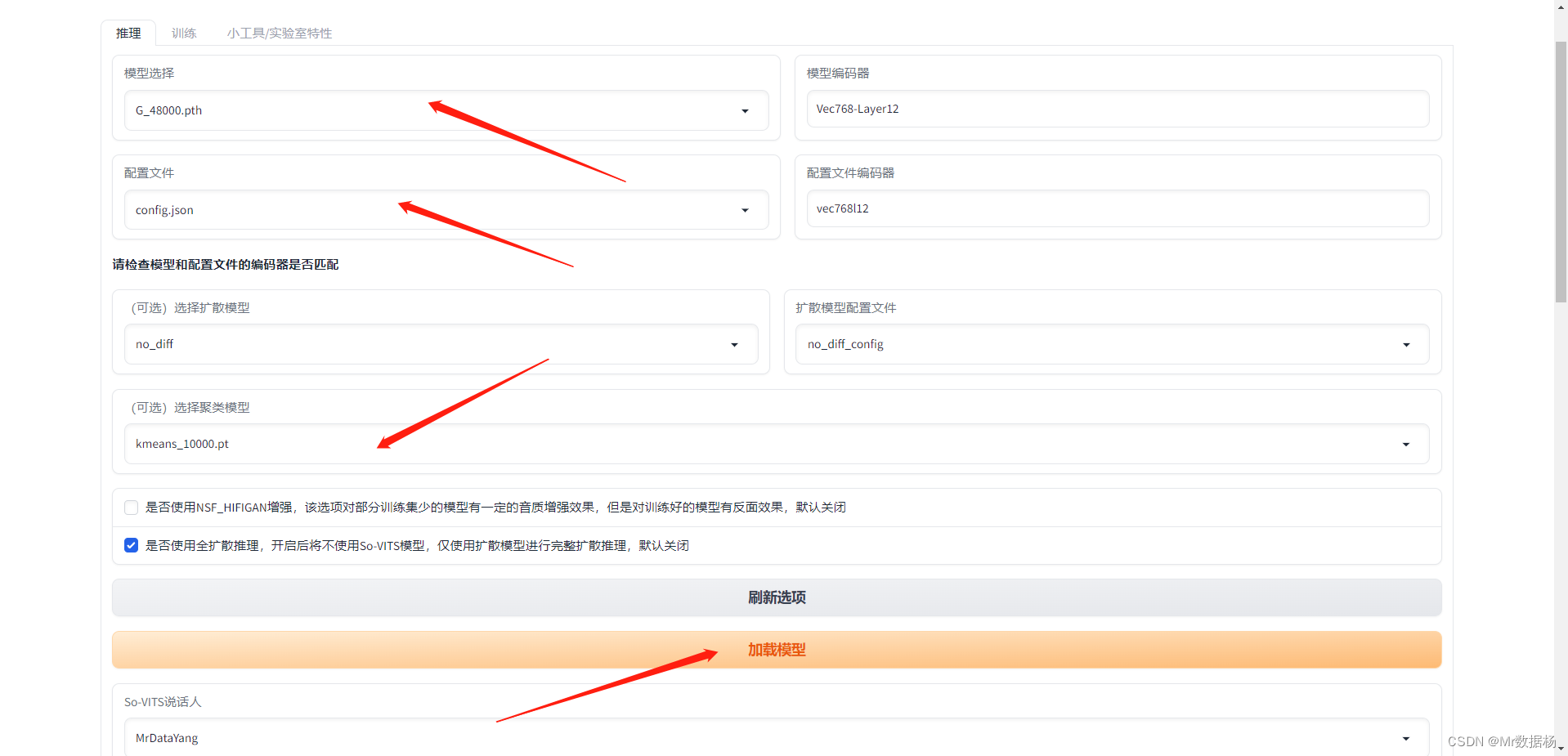
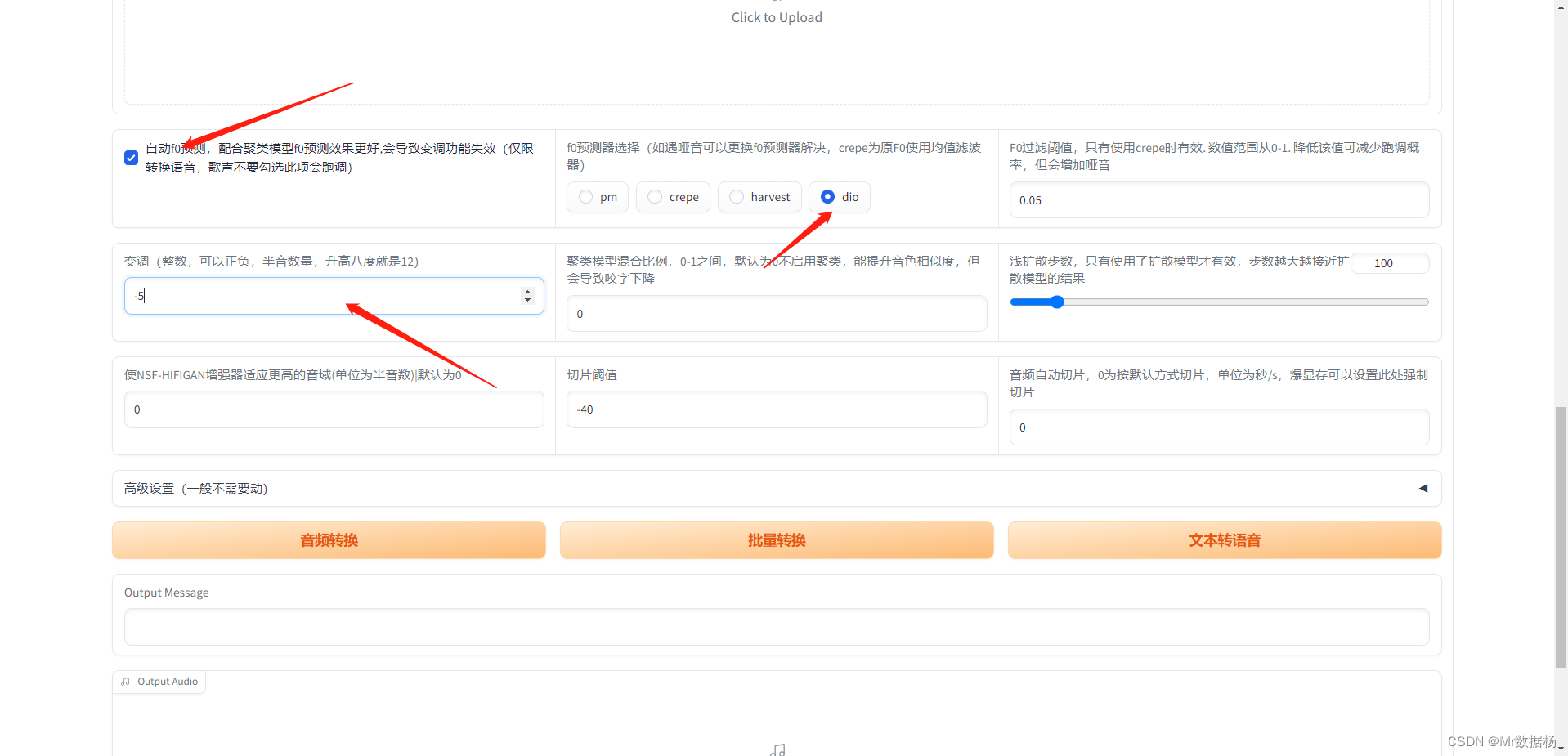
基于So-VITS-SVC4.1声音克隆音频异常的解决办法
猜你喜欢
转载自blog.csdn.net/qq_20288327/article/details/131409228
今日推荐
周排行