# 2020-09-21更新:目前该网站已实现此功能:

为什么爬虫?
由于没有筛选功能,导致获取相关想要的信息费时费力。
目标网站: 广州市高校毕业生就业指导中心的某个现场招聘会
以“2019年全国人力资源市场高校毕业生就业服务周广州市人才招聘大会 (华南理工大学专场)”为例
URL为http://gzbys.job168.com:8080/companyOfTheMeetingListWeb.action?page=2&meetingNo=4302
分析URL,可知该招聘会的标识码为meetingNo=4302,页码变化为page=2
其中有500+个企业,包含:编号、企业名称、招聘岗位

从而我们爬虫的目的是:爬取招聘岗位(包含某些关键词,类似于筛选)的相关信息
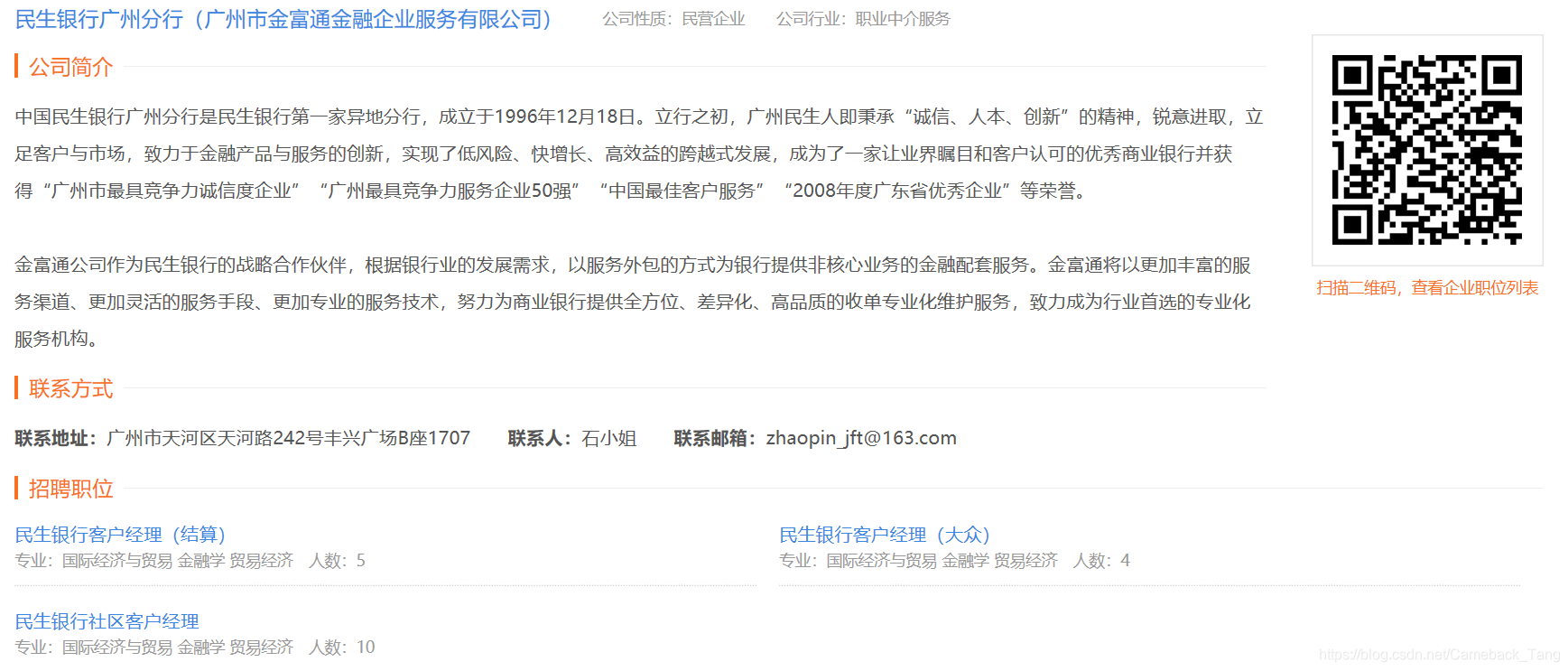
点击进入某个企业,可以得到如下信息:企业名称、公司性质、公司简介、招聘职位等
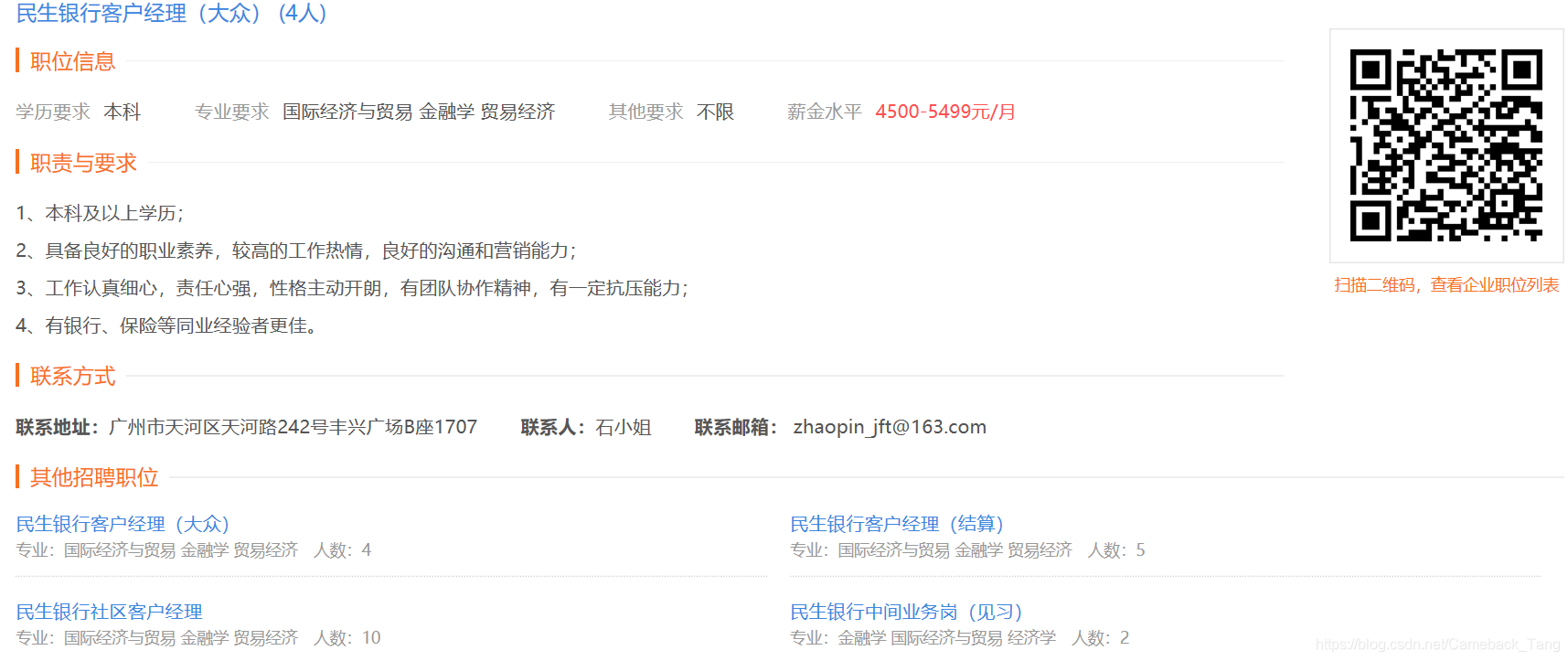
点击进入某个职位,可以得到如下信息:职位名称(包含招聘人数)、职位信息、职位要求等
从而,爬取的内容可以包含:
dic = {'所在页码':page_list,
'企业编号':cno_list,
'企业名称': cname_list,
'企业链接': chref_list,
'企业类型': c_type_info_list,
'企业简介': c_brief_info_list,
'职位名称': jname_list,
'职位链接': jhref_list,
'职位信息': j_type_info_list,
'职位简介': j_brief_info_list,
}
通过python书写简单爬虫程序
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 用于筛选的一些关键词
keywords = ['数据', '机器学习', '算法工程师', 'AI']
# 初始化要爬取的信息列列表,最后通过pandas输出为excel文件
page_list = []
cno_list = []
cname_list = []
chref_list = []
jname_list = []
jhref_list = []
c_type_info_list = []
c_brief_info_list =[]
j_type_info_list = []
j_brief_info_list =[]
meetingNo = str(4302) # 招聘会代号,也可以弄个列表,爬取多个招聘会
urlhead = 'http://gzbys.job168.com:8080'因为不能直接获取该招聘会的总页数,于是通过while 1死循环,直到获取页面为空。
分析下面的网页源码,

于是可以获取所有的 class属性为row的div标签
rows = soup.find_all('div',attrs={'class':'row'}) 在每一个row里面,可以从class为jobs的div标签里,获取所有的a标签,即职位列表
jobs = row.find('div',attrs={'class':'jobs'}) # type(jobs): bs4.element.Tag
jobs = jobs.find_all('a')从而可以从每个job里面的职位url进一步获取职位相关信息
爬取过程的代码如下:
meetingNo = str(4302) # 也可以弄个列表,爬取多个招聘会
urlhead = 'http://gzbys.job168.com:8080'
page = 0
while 1:
page = page +1
url = urlhead + '/companyOfTheMeetingListWeb.action?page='+ \
str(page) + '&meetingNo=' + meetingNo
html = requests.get(url).text
soup = BeautifulSoup(html,'lxml') # type(soup): bs4.BeautifulSoup
rows = soup.find_all('div',attrs={'class':'row'}) # type(rows): bs4.element.ResultSet
if rows == []: break
for row in rows: # type(rows): bs4.element.Tag
com = row.find('div',attrs={'class':'company eps'})
cno = com.span.text # 企业编号
cname = com.a.text # 企业名称
chref = urlhead + com.a['href'] # 企业链接
jobs = row.find('div',attrs={'class':'jobs'}) # type(jobs): bs4.element.Tag
jobs = jobs.find_all('a')
for job in jobs:
jhref = urlhead + job.get('href') # 职位链接
jname = job.text # 职位名称
for keyword in keywords:
if keyword in jname:
page_list.append(page)
cno_list.append(cno)
cname_list.append(cname)
chref_list.append(chref)
# jname_list.append(jname)
jhref_list.append(jhref)
# 进入chref以获取企业类型、企业简介、[联系方式、招聘职位列表]
html = requests.get(chref).text
soup = BeautifulSoup(html,'lxml')
c_type_info = soup.find('div', attrs={'class':'info'}).string
c_brief_info = soup.find('div', attrs={'class':'cont'}).text.replace(' ','')
c_type_info_list.append(c_type_info)
c_brief_info_list.append(c_brief_info)
# 进入jhref以获取职位名称(含有人数)、职位信息、职位要求、[联系方式、其他招聘职位列表]
html = requests.get(jhref).text
soup = BeautifulSoup(html,'lxml')
jname = soup.find('div', attrs={'class':'name'}).text
jname_list.append(jname) #
conts = soup.find_all('div', attrs={'class':'cont'})
j_type_info = conts[0].text.replace(' ','').replace('\n','').replace('\r','')
j_brief_info = conts[1].text.replace(' ','').replace('\r\n','')
j_type_info_list.append(j_type_info)
j_brief_info_list.append(j_brief_info)
break
最后通过字典转换成pandas的dataframe数据框类型,并以excel文件输出
dic = {'所在页码':page_list,
'企业编号':cno_list,
'企业名称': cname_list,
'企业链接': chref_list,
'企业类型': c_type_info_list,
'企业简介': c_brief_info_list,
'职位名称': jname_list,
'职位链接': jhref_list,
'职位信息': j_type_info_list,
'职位简介': j_brief_info_list,
}
df = pd.DataFrame(dic)
df.to_excel("招聘信息汇总.xls")结果如下:
