1、获取思路
浏览器的这些数据是保存在我们本地的磁盘中,所以我们需要先获取他们对应的位置
import socket
# chrome data path
hostname = socket.gethostname()
CHROME_PATH = f"C:/Users/{
hostname}/AppData/Local/Google/Chrome/User Data/Default"
EDGE_PATH = f"C:/Users/{
hostname}/AppData/Local/Microsoft/Edge/User Data/Default"
EDGE_KILL = "taskkill /f /t /im msedge.exe"
CHROME_KILL = "taskkill /f /t /im chrome.exe"
所以我们定义了两组全局变量(浏览器数据存放位置,浏览器进程关闭命令)
hostname就是我们对应的用户名称了,默认没有修改过的话大多数会是Administrator。
接下来去做各个内容的解析,就进入到上述文件路径中的文件中进一步分析。
2、获取书签收藏夹
在Default目录的Bookmarks文件中就是我们的书签内容
打开可以看到如下内容
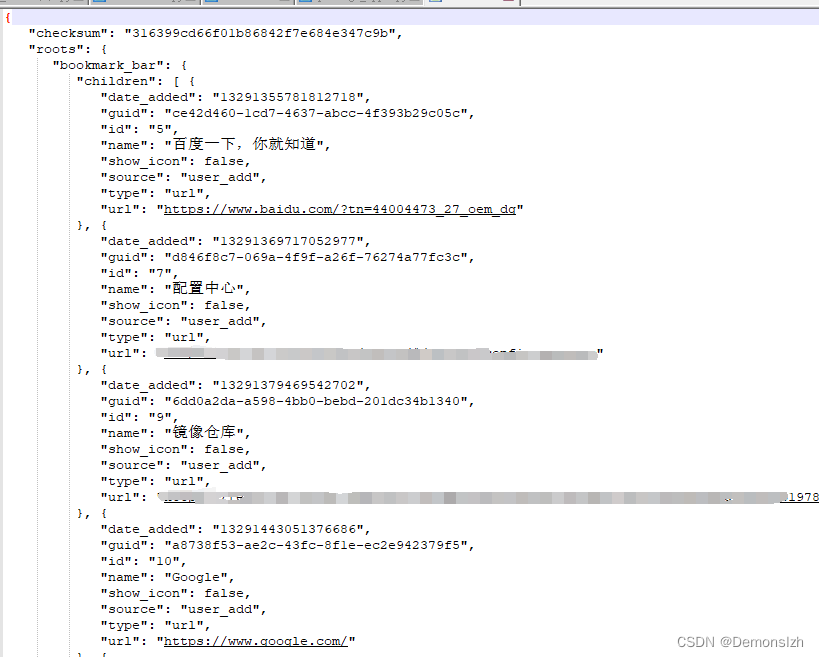
所以很容易地 我们读取这个json文件就可以了。
class BookMark:
def __init__(self, chromePath=CHROME_PATH):
# chromepath
self.chromePath = chromePath
# refresh bookmarks
self.bookmarks = self.get_bookmarks()
def get_folder_data(self):
"""获取收藏夹所有的文件夹内容,合并后保存"""
df = []
for mark_name, item in self.bookmarks["roots"].items():
try:
data = pd.DataFrame(item["children"])
data["folder_name"] =item["name"]
df.append(data)
except Exception:
traceback.print_exc()
print(mark_name)
pd.concat(df).to_csv("results.csv",encoding="gbk")
def get_bookmarks(self):
'update chrome data from chrome path'
# parse bookmarks
assert os.path.exists(
os.path.join(self.chromePath,
'Bookmarks')), "can't found ‘Bookmarks’ file,or path isn't a chrome browser cache path!"
with open(os.path.join(self.chromePath, 'Bookmarks'), encoding='utf-8') as f:
return json.loads(f.read())
3、获取历史记录
同样的,我们还是在上述的目录,找到名称为History的文件。右键点击发现这是一个sqlite3数据库文件。

那么我们直接读取这个文件就行,打开看到里面存放的一些表数据。
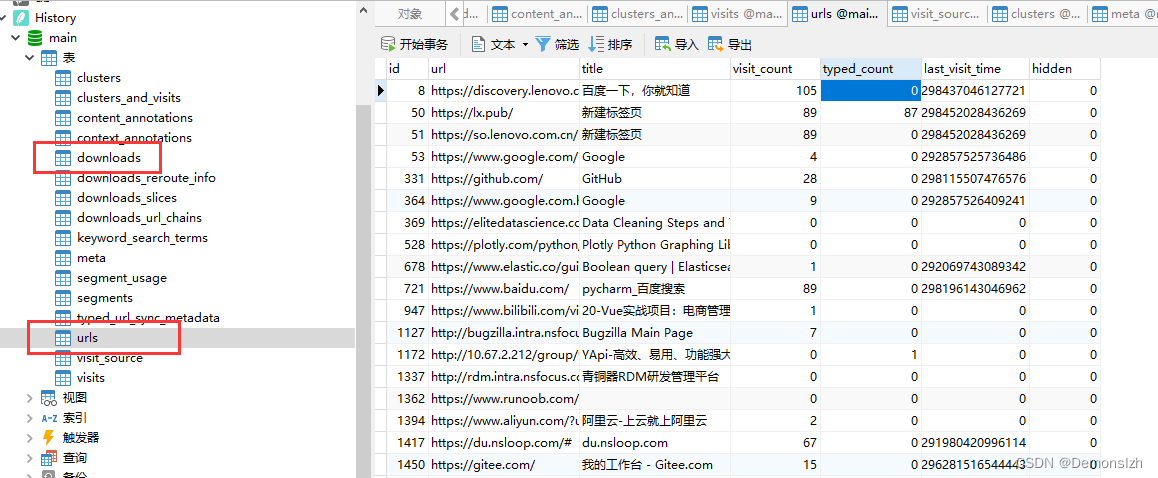
可以看到搜索记录以及对应的访问次数的表在urls中,下载记录表存放在downloads中,接着去编写对应的读取逻辑即可。
同时,有一点需要注意,当我们浏览器在运行过程中数据库会被加锁无法打开,所以我们在脚本运行前需要去kill掉浏览器的进程,也就是我们一开始定义的全局变量,分别对应edge和chrome的命令taskkill /f /t /im msedge.exe
taskkill /f /t /im chrome.exe"
class History:
def __init__(self, kill_exe, chromePath=CHROME_PATH,):
os.system(kill_exe)
self.chromePath = chromePath
self.connect()
def connect(self):
assert os.path.exists(
os.path.join(self.chromePath,
'History')), "can't found ‘History’ file,or path isn't a chrome browser cache path!"
self.conn = sqlite3.connect(os.path.join(self.chromePath, "History"))
self.cousor = self.conn.cursor()
def close(self):
self.conn.close()
def set_chrome_path(self, chromePath):
self.close()
self.chromePath = chromePath
self.connect()
def get_history(self):
cursor = self.conn.execute("SELECT id,url,title,visit_count,last_visit_time from urls")
rows = []
for _id, url, title, visit_count, last_visit_time in cursor:
row = {
}
row['id'] = _id
row['url'] = url
row['title'] = title
row['visit_count'] = visit_count
row['last_visit_time'] = get_chrome_datetime(last_visit_time)
rows.append(row)
pd.DataFrame(rows).to_csv("browse_history.csv", encoding="utf-8")
return rows
def get_downloads(self):
cursor = self.conn.execute("SELECT start_time,target_path,tab_url from downloads")
rows = []
for start_time,target_path,tab_url in cursor:
row = {
}
row['start_time'] = start_time
row['tab_url'] = tab_url
row['target_path'] = target_path
rows.append(row)
pd.DataFrame(rows).to_csv("download_history.csv", encoding="utf-8")
return rows
3、获取浏览器保存的密码数据
获取密码数据的过程会相对复杂一些。
3.1 读取数据库文件Login Data
打开数据库文件,找到存储密码的表。
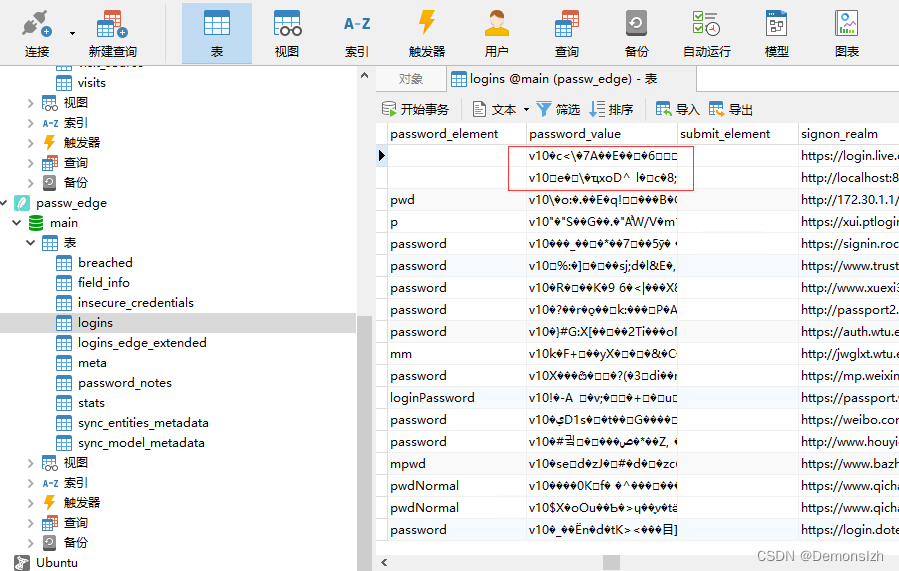
我们这里看到密码是被加密的,那么接下来就是去编写解密的逻辑。
3.2 获取密钥
首先我们需要获取密钥文件,密钥文件的存储路径为
C:/Users/{hostname}/AppData/Local/Google/Chrome/User Data/Local State
同样的,这也是一个json文件,我们需要拿到对应的密钥
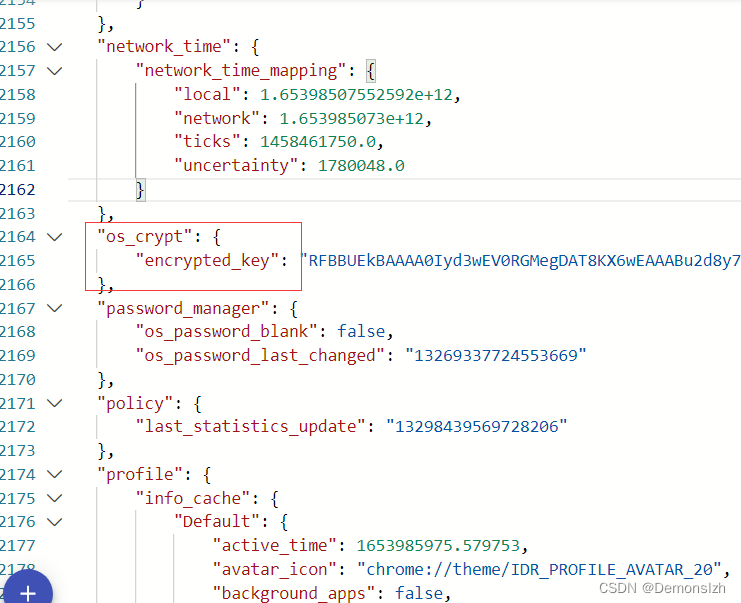
完整的解密获取逻辑如下
class Password:
def __init__(self, path=EDGE_PATH):
"""
self.path: User Data的路径
"""
self.path = path
def get_encryption_key(self):
local_state_path = os.path.join(os.path.split(self.path)[0], "Local State")
with open(local_state_path, "r", encoding="utf-8") as f:
local_state = f.read()
local_state = json.loads(local_state)
key = base64.b64decode(local_state["os_crypt"]["encrypted_key"])
key = key[5:]
return win32crypt.CryptUnprotectData(key, None, None, None, 0)[1]
def decrypt_password(self, password, key):
try:
iv = password[3:15]
password = password[15:]
cipher = AES.new(key, AES.MODE_GCM, iv)
return cipher.decrypt(password)[:-16].decode()
except:
try:
return str(win32crypt.CryptUnprotectData(password, None, None, None, 0)[1])
except:
import traceback
traceback.print_exc()
return ""
def parse_password(self):
key = self.get_encryption_key()
db_path = os.path.join(EDGE_PATH, "Login Data")
# 复制一份数据库文件出来
filename = "ChromeData.db"
shutil.copyfile(db_path, filename)
db = sqlite3.connect(filename)
cursor = db.cursor()
cursor.execute(
"select origin_url, action_url, username_value, password_value, date_created, date_last_used from logins order by date_created")
rows = []
for row in cursor.fetchall():
origin_url = row[0]
action_url = row[1]
username = row[2]
password = self.decrypt_password(row[3], key)
date_created = row[4]
date_last_used = row[5]
item = {
}
if username or password:
item["origin_url"] = origin_url
item["action_url"] = action_url
item["username"] = username
item["password"] = password
if date_created != 86400000000 and date_created:
item["creation_date"] = str(get_chrome_datetime(date_created))
if date_last_used != 86400000000 and date_last_used:
item["last_used"] = str(get_chrome_datetime(date_last_used))
rows.append(item)
cursor.close()
db.close()
try:
# try to remove the copied db file
os.remove(filename)
pd.DataFrame(rows).to_csv("passwords.csv")
except:
import traceback
traceback.print_exc()
4、完整代码获取
接着去写主函数就很容易了
def main():
for kill_cmd,path in zip([EDGE_KILL, CHROME_KILL],[EDGE_PATH, CHROME_PATH]):
if os.path.exists(path):
# 获取收藏夹数据
try:
BookMark(path).get_bookmarks()
# 获取历史记录
History(kill_cmd, path).get_history()
History(kill_cmd, path).get_downloads()
# 获取密码
Password(kill_cmd, path).parse_password()
except Exception as e:
traceback.print_exc()
上述便是所有的获取过程了。如果需要完整代码的,可以关注wexin公众号"一颗程序树"回复0090获取源码