@Autowired注解是由Spring提供的,它可以用来对构造方法、成员变量及方法参数进行标注,它能够根据对象类型完成自动注入,代码如下。
public class Service {
// 构造方法注入
@Autowired
public Service(Service service) {
this.service = service;
}
// 成员变量注入
@Autowired
private Service service;
// 方法参数注入
@Autowired
public void setService(Service service) {
this.service = service;
}
}再来看@Resource注解,代码如下。
public class Service {
@Resource(name = "service1")
private Service service1;
@Resource(name = "service2")
private Service service2;
@Reource
private Service service3;
@Reource
private Service service4;
}它是由JDK提供的,遵循JSR-250规范,是JDK 1.6及以上加入的新特性。作为Java的标准,它的作用和@Autowired无区别。与@Autowired不同的是,它适用于所有的Java框架,而@Autowired只适用于Spring。读者可以简单地理解为,@Resource能够支持对象类型注入,也能够支持对象名称注入。
@Resource和@Autowired之间具体有哪些区别呢?
可以从以下5个方面来分析。
1.注解内部定义的参数不同
@Autowired只包含一个required参数,默认为true,表示开启自动注入。
public @interface Autowired {
// 是否开启自动注入,在不开启自动装配时,可设为false
boolean required() default true;
}@Resource 包含7个参数,其中最重要的两个是name和type。
public @interface Resource {
// Bean的名称
String name() default "";
String lookup() default "";
// Java类,被解析为Bean的类型
Class<?> type() default java.lang.Object.class;
enum AuthenticationType {
CONTAINER,
APPLICATION
}
// 身份验证类型
AuthenticationType authenticationType() default AuthenticationType.CONTAINER;
// 组件是否可以与其他组件共享
boolean shareable() default true;
String mappedName() default "";
// 描述
String description() default "";
}2.装配方式的默认值不同
@Autowired默认按type自动装配,而@Resource默认按name自动装配。@Resource注解可以自定义选择装配方式,如果指定name,则按name自动装配。如果指定type,则按type自动装配。
3.注解应用的范围不同
@Autowired能够用在构造方法、成员变量、方法参数及注解上,而@Resource能用在类、成员变量和方法参数上,源码如下。
@Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Autowired { ... }
@Target({TYPE, FIELD, METHOD})
@Retention(RUNTIME)
public @interface Resource { ... }4.出处不同
@Autowired是Spring定义的注解,而@Resource遵循JSR-250的规范,定义在JDK中。所以@Autowired只能在Spring框架下使用,而@Resource则可以与其他框架一起使用。
5.装配顺序不同
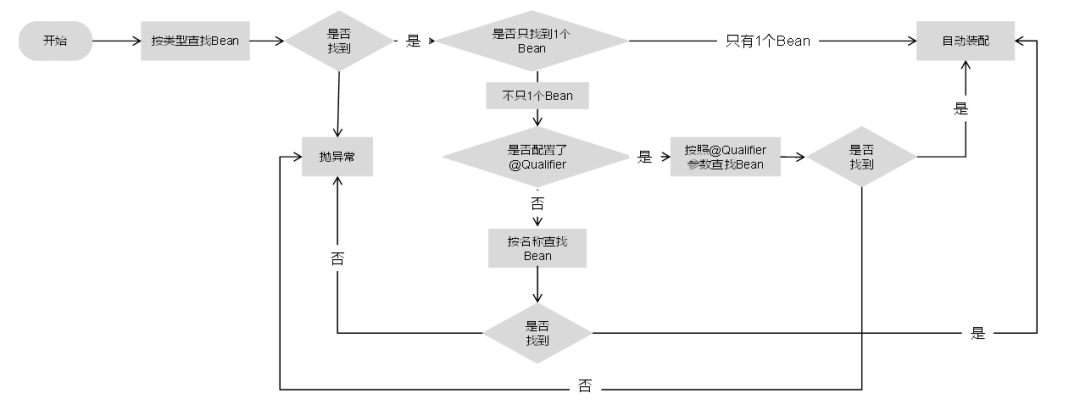
@Autowired默认先与byType进行匹配,如果发现找到多个Bean,则又按照byName方式进行匹配,如果还有多个Bean,则报出异常。装配顺序如下图所示。
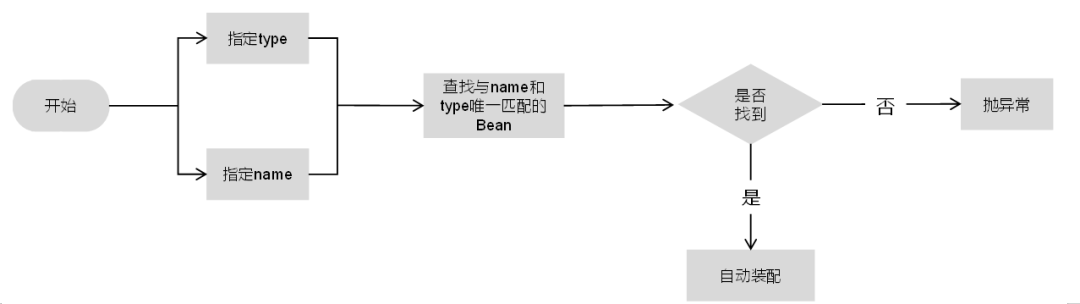
而@Resource的装载顺序分为如下4种情况。
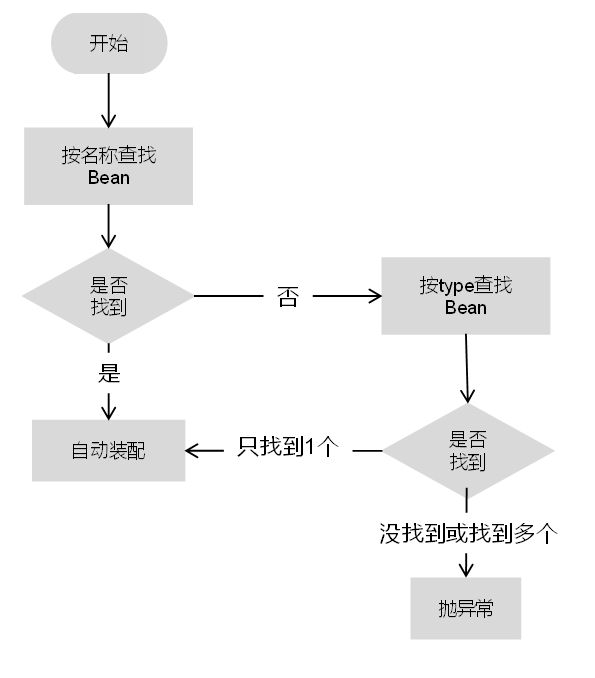
1)如果同时指定name和type,则从Spring上下文中找到与它们唯一匹配的Bean进行装配,如果找不到则抛出异常,具体流程如下图所示。
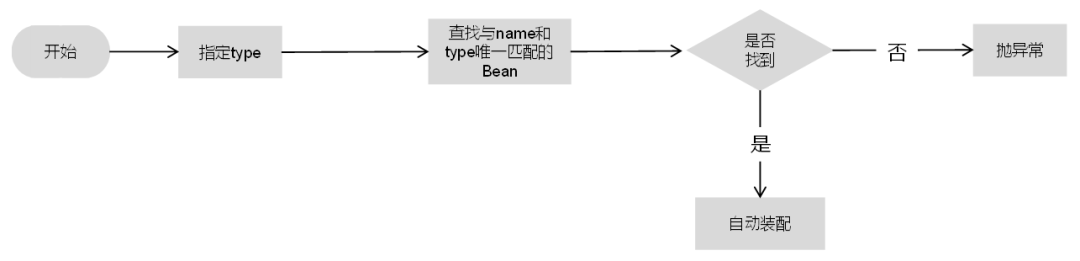
2)如果指定name,则从上下文中查找与名称(ID)匹配的Bean进行装配,如果找不到则抛出异常,具体流程如下图所示。
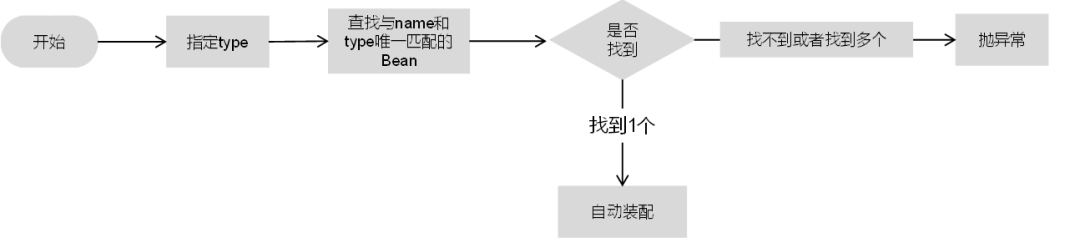
3)如果指定type,则从上下文中找到与类型匹配的唯一Bean进行装配,如果找不到或者找到多个就会抛出异常,具体流程如下图所示。
4)如果既没有指定name,也没有指定type,则自动按byName方式进行装配。如果没有匹配成功,则仍按照type进行匹配,具体流程如下图所示。
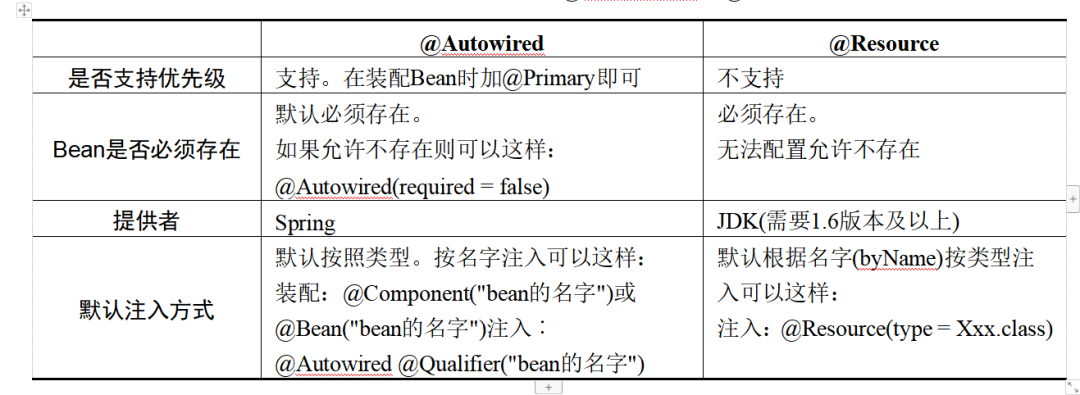
下面这张表可以帮助大家更好地理解和区分@Autowired和@Resource。
总结一下,两者在功能上差别不大,使用起来也差不多。但是,在日常开发中建议使用@Autowired,有以下3个理由。
第1:@Autowired功能略强大。支持优先注入、可以配置允许Bean不存在。
第2:若使用Spring框架,则使用其特有的注解更好一点。
第3:有人认为@Resource更加通用,因为它是一个规范,其他框架也会支持。目前后端都在用Spring,没有必要考虑其他框架。
面试点评:我们可以直接告诉面试官这两个注解的差异,同时基于两个注解的特性解释更多的差异,这样可以更好地体现自己对这方面知识的理解深度。面试官想考查求职者对Spring依赖注入方式的理解,以及对@Autowired和@Resource两个注解底层实现方面的区别的理解。求职者在理解了底层实现的差异后,回答这个问题会比较容易。
亲爱的程序员求职者们,相信你们一定深有体会,求职面试这条路有多难走。
Java基础知识,多线程,并发编程,集合原理,JVM原理……啊!别跟我提这些!面试官一下子拿着这些知识点就冲你扔过来,还有那魔幻的Java框架,你要是不懂Spring全家桶、Dubbo、Netty、MyBatis等,就别想踏进这个行业的大门。没错,Java领域可是卷得一塌糊涂啊。
现在有了一本强大的新书空降,在这炽热的夏日带来一股清凉的Java知识。这本名叫《Java面试八股文:高频面试题与求职攻略一本通》,简直是Java求职者的救星。

书中囊括了Java面试的方方面面近200道高频面试题,从Java基础知识、并发编程、集合原理,到JVM原理、I/O与网络编程,再到设计模式、分布式与微服务,MySQL数据库、缓存与NoSQL,消息中间件……应有尽有,想不掌握都难!而且书中还提供了大量实战场景与面试简历实操技巧。近20个经典高频实战场景解决方案,从服务器反应慢到秒杀设计,从架构设计到常见解决方案,无一不是伤害求职者心脏的“锋芒之剑”。同时,更有10多个面试简历实操技巧,包括简历编写与投递技巧、面试谈薪技巧、求职决策技巧等,一次性解决你的求职难题!

你可以去翻阅一下书中详细目录:
向上滑动阅览
第1篇 Java核心知识点 1
第1章 Java基础知识 2
1.1 数据类型 2
1.1.1 为什么要设计封装类,Integer和int有什么区别 2
1.1.2 为什么“1000==1000”为false,“100==100”为true 3
1.1.3 new String("hello")之后,到底创建了几个对象 6
1.1.4 String、StringBuffer、StringBuilder的区别是什么 8
1.2 Object对象 9
1.2.1 如何理解Java对象的创建过程 9
1.2.2 什么是深克隆和浅克隆 10
1.2.3 强引用、软引用、弱引用、虚引用有什么区别 12
1.2.4 一个空的Object对象到底占多大内存 14
1.2.5 为什么重写equals()方法就一定要重写hashCode()方法 15
1.3 其他特性 17
1.3.1 请对比一下Java和JavaScript的区别 17
1.3.2 什么是受检异常和非受检异常 18
1.3.3 fail-fast机制与fail-safe机制分别有什么作用 20
1.3.4 如何理解序列化和反序列化 21
1.3.5 什么是SPI,它有什么用 22
1.3.6 finally语句块一定会执行吗 24
1.3.7 什么是内存溢出,什么是内存泄漏 25
第2章 并发编程与多线程 27
2.1 J.U.C和锁 27
2.1.1 什么是AQS 27
2.1.2 如何理解AQS的实现原理 28
2.1.3 AQS为什么要使用双向链表 29
2.1.4 什么是CAS 31
2.1.5 什么是乐观锁,什么是悲观锁 32
2.1.6 什么条件下会产生死锁,如何避免死锁 33
2.1.7 synchronized和Lock的区别是什么 35
2.1.8 什么是可重入锁,它的作用是什么 37
2.1.9 ReentrantLock的实现原理是什么 38
2.1.10 ReentrantLock是如何实现锁的公平性和非公平性的 39
2.1.11 说说你对行锁、间隙锁、临键锁的理解 40
2.1.12 如何理解Java中令人眼花缭乱的各种并发锁 42
2.1.13 阻塞队列被异步消费,怎么保持顺序 51
2.1.14 基于数组的阻塞队列ArrayBlockingQueue的实现原理是什么 52
2.2 多线程与线程池 53
2.2.1 Thread和Runnable的区别是什么 53
2.2.2 什么是守护线程,它有什么特点 54
2.2.3 BLOCKED和WAITING两种线程状态有什么区别 55
2.2.4 为什么启动线程不能直接调用run()方法,调用两次start()方法会
有什么后果 56
2.2.5 谈谈你对Java线程5种状态流转原理的理解 58
2.2.6 谈谈你对线程池的理解 60
2.2.7 Java有哪些实现线程池的方式 62
2.2.8 线程池是如何回收线程的 63
2.2.9 线程池是如何实现线程复用的 64
2.2.10 线程池如何知道一个线程的任务已经执行完成 65
2.2.11 当任务数超过线程池的核心线程数时,如何让任务不进入队列 66
2.2.12 什么是伪共享,如何避免伪共享 67
2.2.13 wait和notify为什么要写在synchronized代码块中 69
2.2.14 wait和sleep是否会触发锁的释放及CPU资源的释放 70
2.2.15 volatile关键字有什么用,它的实现原理是什么 71
2.2.16 说说你对CompletableFuture的理解 73
2.2.17 谈谈你对ThreadLocal实现原理的理解 75
2.2.18 CountDownLatch和CyclicBarrier有什么区别 77
2.2.19 谈谈你对Happens-Before的理解 79
2.3 线程安全 81
2.3.1 谈谈你对线程安全的理解 81
2.3.2 Java保证线程安全的方式有哪些 82
2.3.3 如何安全中断一个正在运行的线程 83
2.3.4 SimpleDateFormat是线程安全的吗 84
2.3.5 并发场景中,ThreadLocal会造成内存泄漏吗 85
第3章 集合原理 89
3.1 ArrayList 89
3.1.1 ArrayList是如何实现自动扩容的 89
3.1.2 谈谈ArrayList、Vector和LinkedList的存储性能及特性 91
3.2 HashMap 92
3.2.1 单线程下的HashMap工作原理是什么 92
3.2.2 HashMap是如何解决Hash冲突的 97
3.2.3 HashMap什么时候扩容,如何自动扩容 99
3.2.4 为什么HashMap会产生死循环 101
3.2.5 HashMap和TreeMap的区别是什么 104
3.2.6 为什么ConcurrentHashMap的key不允许为null 106
3.2.7 谈谈你对ConcurrentHashMap底层实现原理的理解 108
3.2.8 ConcurrentHashMap是如何保证线程安全的 111
第4章 JVM原理 115
4.1 JVM介绍 115
4.1.1 如何理解Java虚拟机,它的结构是如何设计的 115
4.1.2 什么是双亲委派机制 119
4.2 内存管理 121
4.2.1 JVM如何判断一个对象可以被回收 121
4.2.2 谈谈你对JVM中主要GC算法的理解 123
4.2.3 JVM分代年龄为什么是15次 125
4.2.4 JVM为什么使用元空间替换永久代 126
第5章 I/O与网络编程 129
5.1 I/O基础 129
5.1.1 Java有几种文件拷贝方式,哪一种效率最高 129
5.1.2 I/O和NIO的区别是什么 130
5.1.3 谈谈你对I/O多路复用机制的理解 131
5.2 网络编程 135
5.2.1 什么是网络四元组 135
5.2.2 TCP为什么要设计3次握手 137
5.2.3 Cookie和Session有什么区别 138
第6章 设计模式 140
6.1 单例模式 140
6.1.1 在Java中实现单例模式有哪些方法 140
6.1.2 哪些情况下的单例对象可能会被破坏 143
6.1.3 在DCL单例写法中,为什么主要做两次检查 147
6.1.4 哪些场景不适合使用单例模式 150
6.2 代理模式 151
6.2.1 什么是代理,为什么要用动态代理 151
6.2.2 JDK动态代理为什么只能代理有接口的类 153
6.3 责任链模式 155
第2篇 框架源码与原理 159
第7章 Spring全家桶 160
7.1 Spring框架 160
7.1.1 为什么要使用Spring框架 160
7.1.2 Spring IoC的工作流程是怎样的 162
7.1.3 Spring中BeanFactory和FactoryBean的区别是什么 164
7.1.4 谈谈你对Spring Bean的理解 165
7.1.5 Spring Bean的定义包含哪些内容 169
7.1.6 Spring中Bean的作用域有哪些 172
7.1.7 如何叙述Spring Bean的生命周期 174
7.1.8 Spring中的Bean是线程安全的吗 178
7.1.9 Spring有几种依赖注入的方式 179
7.1.10 Spring如何解决循环依赖问题 180
7.1.11 Spring中用到了哪些设计模式 183
7.1.12 Spring中的事务传播行为有哪些 184
7.1.13 导致Spring事务失效的原因有哪些 185
7.1.14 Spring中实现异步调用的方式有哪些 187
7.1.15 谈谈你对Spring AOP原理的理解 190
7.2 Spring MVC框架 193
7.2.1 说说你对Spring MVC的理解 193
7.2.2 简述Spring MVC的核心执行流程 194
7.2.3 谈谈你对Spring MVC中9大组件的理解 197
7.2.4 Spring中@Autowired和@Resource的区别 202
7.3 Spring Boot框架 207
7.3.1 为什么越来越多的人选择Spring Boot 207
7.3.2 如何理解Spring Boot约定优于配置 210
7.3.3 Spring Boot自动装配机制的实现原理是什么 211
7.3.4 如何理解Spring Boot中的Starter 213
7.4 Spring Cloud框架 214
7.4.1 谈谈你对Spring Cloud的理解 214
7.4.2 谈谈Eureka Server数据同步原理 215
7.4.3 简述Nacos配置更新的工作流程 216
第8章 互联网常用框架 218
8.1 Dubbo框架 218
8.1.1 简述Dubbo和Spring Cloud的优缺点对比 218
8.1.2 Dubbo的服务请求失败怎么处理 220
8.1.3 Dubbo是如何动态感知服务下线的 221
8.2 Netty框架 223
8.2.1 谈谈你对Netty中Reactor模式的理解 223
8.2.2 Netty是如何实现零拷贝的 225
8.2.3 为什么Netty线程池默认大小为CPU核数的两倍 228
8.2.4 谈谈你对Netty中Pipeline工作原理的理解 229
8.3 MyBatis框架 231
8.3.1 谈谈你对MyBatis缓存机制的理解 231
8.3.2 MyBatis中#号和$号的区别是什么 233
8.3.3 MyBatis是如何进行分页的 234
第3篇 分布式与中间件 237
第9章 分布式与微服务 238
9.1 分布式通信 238
9.1.1 谈谈你对RPC框架的理解 238
9.1.2 HTTP和RPC有什么区别 240
9.2 微服务协调组件 242
9.2.1 分布式和微服务的区别是什么 242
9.2.2 谈谈你对负载均衡的理解 243
9.2.3 谈谈你对ZooKeeper的理解 248
9.2.4 简述ZooKeeper中的Watch机制的原理 250
9.2.5 ZooKeeper如何实现Leader选举 251
9.3 分布式锁 254
9.3.1 谈谈你对分布式锁的理解和实现 254
9.3.2 什么是幂等,如何解决幂等性问题 255
9.3.3 谈谈你对一致性Hash算法的理解 256
9.3.4 常用的分布式ID设计方案有哪些 260
9.3.5 实现分布式锁,ZooKeeper和Redis哪个更好 261
9.4 分布式事务 263
9.4.1 如何区分Spring中的事务和分布式事务 263
9.4.2 谈谈分布式事务的解决方案 264
9.4.3 谈谈你对Seata的理解 265
9.4.4 如何解决TCC中的悬挂问题 269
9.5 限流和鉴权 271
9.5.1 常用的限流算法有哪些 271
9.5.2 简述雪花算法的实现原理 273
9.5.3 简述Sentinel组件里的滑动窗口算法 278
9.5.4 谈谈你对OAuth的理解 279
9.6 DevOps与云原生 283
9.6.1 谈谈你对Swagger工作流程的理解 283
9.6.2 什么是云原生 286
9.6.3 什么是服务网格 287
9.6.4 谈谈你对IaaS、PaaS、SaaS的理解 290
第10章 MySQL数据库 293
10.1 存储引擎 293
10.1.1 存储MD5值应该用VARCHAR还是CHAR 293
10.1.2 能不能用MySQL的VARCHAR来存储一本小说 294
10.1.3 导致索引失效的原因有哪些 296
10.1.4 什么是聚集索引和非聚集索引 297
10.1.5 谈谈你对B树和B+树的理解 298
10.1.6 为什么MySQL的索引结构要采用B+树 302
10.1.7 MySQL索引的优点和缺点是什么 303
10.1.8 为什么SQL语句命中索引比不命中索引要快 304
10.1.9 MySQL中MyISAM和InnoDB引擎有什么区别 306
10.1.10 MySQL表设计时间列用datetime还是timstamp 309
10.2 事务 310
10.2.1 如何理解 MySQL的事务隔离级别 310
10.2.2 MySQL事务的实现原理 312
10.2.3 谈谈你对MVCC的理解 314
10.2.4 MySQL的InnoDB如何解决幻读 315
10.3 性能优化 318
10.3.1 执行SQL响应比较慢,你有哪些排查思路 318
10.3.2 数据库连接池有什么用,它有哪些关键参数 321
10.3.3 为什么分布式系统中不推荐使用多表关联查询 322
第11章 缓存与NoSQL 324
11.1 Redis缓存 324
11.1.1 谈谈你对Redis的理解 324
11.1.2 如何解决缓存雪崩、缓存穿透和缓存击穿问题 325
11.1.3 简述Redis持久化机制RDB和AOF实现原理 328
11.1.4 简述Redis中AOF重写的过程 330
11.1.5 Redis的内存淘汰算法和原理是什么 331
11.1.6 谈谈你对时间轮的理解 333
11.1.7 Redis到底是单线程还是多线程 334
11.1.8 Redis存在线程安全问题吗 336
11.1.9 Redis和MySQL如何保证数据一致性 337
11.2 其他NoSQL 340
11.2.1 谈谈你对NoSQL的理解 340
11.2.2 对比FastDFS说明MinIO的优缺点 342
11.2.3 谈谈你对Elasticsearch的理解 344
第12章 消息中间件 347
12.1 RabbitMQ 347
12.1.1 谈谈你对MQ(消息队列)的理解 347
12.1.2 谈谈你对RabbitMQ工作原理的理解 350
12.1.3 RabbitMQ是如何实现消息路由的 351
12.1.4 RabbitMQ如何保证线上MQ消息不丢失 353
12.1.5 RabbitMQ如何实现高可用 356
12.2 Kafka 358
12.2.1 Kafka为什么这么快 358
12.2.2 谈谈你对Kafka零拷贝原理的理解 360
12.2.3 Kafka如何保证消息不丢失 362
12.2.4 Kafka是怎么避免重复消费的 364
12.2.5 Kafka如何保证消息顺序消费 366
12.2.6 谈谈你对Kafka数据存储原理的理解 368
12.2.7 什么是ISR,为什么要引入ISR 370
12.2.8 Kafka副本是如何完成Leader选举的 371
12.3 其他中间件 373
12.3.1 RocketMQ为什么要放弃ZooKeeper 373
12.3.2 谈谈你对RocketMQ分布式事务原理的理解 375
12.3.3 谈谈你对Pulsar的理解 377
第4篇 经典场景与求职攻略 383
第13章 互联网经典场景 384
13.1 服务器反应慢 384
13.1.1 线上服务器CPU飙升,如何定位到Java代码 384
13.1.2 生产环境服务器变慢,如何诊断处理 386
13.1.3 线上接口负载剧增,快扛不住了,你的首选方案是什么 388
13.2 秒杀设计 388
13.2.1 从全局角度如何设计一个秒杀系统 388
13.2.2 如何解决秒杀系统中超卖、少卖等问题 391
13.2.3 如何设计百万并发场景中的抢优惠券业务 392
13.2.4 如何设计春节抢红包金额随机的算法 394
13.2.5 如何设计订单超时自动取消功能 396
13.3 架构设计 397
13.3.1 Java Web开发如何解决跨域问题 397
13.3.2 如何避免订单重复提交和支付 401
13.3.3 日数据量超300万条的监测系统,该如何设计数据库架构 403
13.3.4 手机扫码登录到底是怎么实现的 405
13.3.5 线上单表数据量达到1亿,如何做分表迁移 406
13.3.6 如何统计亿级用户的在线状态 408
13.3.7 线上MySQL数据库连接池泄漏,该如何排查 410
13.3.8 短信验证码接口被狂刷,怎么办 413
13.3.9 简述互联网架构20年来的演变过程 414
第14章 面试求职攻略 420
14.1 简历编写与投递技巧 420
14.1.1 找工作与从一份精美的简历开始 420
14.1.2 如何有效并且精准地投递简历 431
14.1.3 简历投递和职业发展的关系 433
14.1.4 什么时间投递简历最有效果 434
14.2 面试谈薪技巧 437
14.2.1 了解行业面试潜规则 437
14.2.2 打有准备的仗更容易获得胜利 440
14.2.3 面试过程中如何更好地展现自己 444
14.2.4 巧妙回答面试中的常见问题 448
14.2.5 捕捉面试官的微表情并做出及时反应 450
14.2.6 HR问薪资的时候,应该说多少 452
14.3 求职决策技巧 455
14.3.1 拿到多个Offer时应该如何选择 455
14.3.2 到底要不要去外包公司 458
14.3.3 如何和现在的公司友好地说分手 460
附录A 互联网程序员职业成长发展路线图 463
附录B 互联网程序员职业各成长阶段能力模型图 464
附录C Java互联网程序员技术成长路径 465
相信这本书可以成为你职业生涯中的有力助推器,事半功倍、轻松捞到心仪的Java工作。别犹豫了,已经给各位粉丝老爷申请到了最优惠的价格,冲冲冲,最后祝愿大家都能拿到自己心仪的Offer!
赠书!先到先得!
本次将送出5本作为粉丝福利
赠书规则:不抽奖,使用社区积分直接兑换!
兑换地址:http://spring4all.com/3249.html
快来一起来参与社区内容的建设,一起学习一起成长吧!
点击阅读原文,查看更多社区福利!