目录
1.高并发
1.1.定义
高并发是指系统在同一时间内处理大量请求的能力。在软件开发中,为了应对高并发的情况,通常需要进行系统架构设计、代码优化、缓存策略等方面的优化。
1.2.术语
高并发相关常用的指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。TPS、QPS都是吞吐量的常用量化指标
QPS:每秒响应请求数。指一台服务器每秒能够响应的查询次数,在互联网领域,这个指标和吞吐量区分的没有这么明显。QPS 只是一个简单查询的统计,不建议用 QPS 来描述系统整体的性能
TPS:每秒事务数,一个事务是指客户端向服务器发送请求然后服务器做出反应的过程,
以单接口定义为事务举例,每个事务包括了如下3个过程:
- (1)向服务器发请求
- (2)服务器自己的内部处理(包含应用服务器、数据库服务器等)
- (3)服务器返回结果给客户端
如果每秒能够完成 N 次以上3个过程,TPS 就是 N
并发用户数:同时承载正常使用系统功能的用户数量。这个数值可以分析机器1s内的访问日志数量来得到
QPS与TPS区别:
(1)如果是对一个查询接口压测,且这个接口内部不会再去请求其它接口,那么 TPS = QPS,否则,TPS ≠ QPS
(2)如果是容量场景,假设 N 个接口都是查询接口,且这个接口内部不会再去请求其它接口,QPS = N * TPS
2.高并发系统设计的目标是什么
2.1.宏观目标
①高性能:性能体现了系统的并行处理能力,在有限的硬件投入下,提高性能意味着节省成本。
②高可用:表示系统可以正常服务的时间。一个全年不停机、无故障;另一个隔三差五出线上事故、宕机,用户肯定选择前者。另外,如果系统只能做到 90% 可用,也会大大拖累业务。
③高扩展:表示系统的扩展能力,流量高峰时能否在短时间内完成扩容,更平稳地承接峰值流量,比如双 11 活动、明星离婚等热点事件。
2.2.微观目标
性能指标:通过性能指标可以度量目前存在的性能问题,同时作为性能优化的评估依据。一般来说,会采用一段时间内的接口响应时间作为指标。
①平均响应时间:最常用,但是缺陷很明显,对于慢请求不敏感。比如 1 万次请求,其中 9900 次是 1ms,100 次是 100ms,则平均响应时间为 1.99ms,虽然平均耗时仅增加了 0.99ms,但 是 1% 请求的响应时间已经增加了 100 倍。
②TP90、TP99 等分位值:将响应时间按照从小到大排序,TP90 表示排在第 90 分位的响应时间, 分位值越大,对慢请求越敏感。
③吞吐量:和响应时间呈反比,比如响应时间是 1ms,则吞吐量为每秒 1000 次。
可用性指标:高可用性是指系统具有较高的无故障运行能力,可用性=平均故障时间/系统总运行时间
可扩展性指标:面对突发流量,不可能临时改造架构,最快的方式就是增加机器来线性提高系统的处理能力。.
因此,高扩展性需要考虑:服务集群、数据库、缓存和消息队列等中间件、负载均衡、带宽、依赖的第三方等,当并发达到某一个量级后,上述每个因素都可能成为扩展的瓶颈点。
3.高并发解决方案的演化
联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直(纵向)扩展(Scale Up)与水平(横向)扩展(Scale Out)
水平(横向)扩展:增加服务器数量,线性扩充系统性能。水平扩展对系统架构设计是有要求的
垂直(纵向)扩展:通过增加服务器的处理能力、内存、存储空间等硬件资源来提高系统的性能和容量。
3.1.初期的并发解决方案
垂直扩展:提升单机处理能力
垂直扩展的方式又有两种:
(1)增强单机硬件性能:通过增加CPU核数如32核,升级网卡升级万兆,机械硬盘升级固态,扩充硬盘容量如2T,扩充系统内存;CPU 从 32 位提升为 64 位;换掉免费的Tomcat,使用商用weblogic;优化Linux内核;购买高性能服务器等
(2)提升单机架构性能:使用缓存Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间
随着业务的不断增加,服务器性能很快又到达瓶颈
3.2.应用级别的解决方案
1)网页HTML 静态化(需要CMS项目支持)
2)图片服务器分离(常用解决方案)
3)缓存(常用解决方案) 上上策为分布式缓存
4)镜像(下载较多)
因为单机性能总会存在极限,所以最终还需要引入水平(横向)扩展
3.3.终极解决方案—分布式
由于目前现有网络的各个核心部分随着业务量的提高,访问量和数据流量的快速增长,其处理能力和计算强度也相应地增大,使得单一的服务器设备根本无法承担。在此情况下,如果扔掉现有设备去做大量的硬件升级,这样将造成现有资源的浪费,而且如果再面临下一次业务量的提升时,这又将导致再一次硬件升级的高额成本投入,甚至性能再卓越的设备也不能满足当前业务量增长的需求。
为了解决这个问题,采用分布式系统架构,通过集群部署以进一步提高并发处理能力,这种架构可以将不同的服务器设备连接在一起,共同承担业务量的增长。同时,也可以通过负载均衡来平衡不同服务器之间的负载,提高整个系统的性能和可靠性。
也可以使用云计算技术,将业务部署在云平台上,根据实际业务量的变化动态扩展计算资源,从而更好地应对业务增长的挑战。
4.系统架构
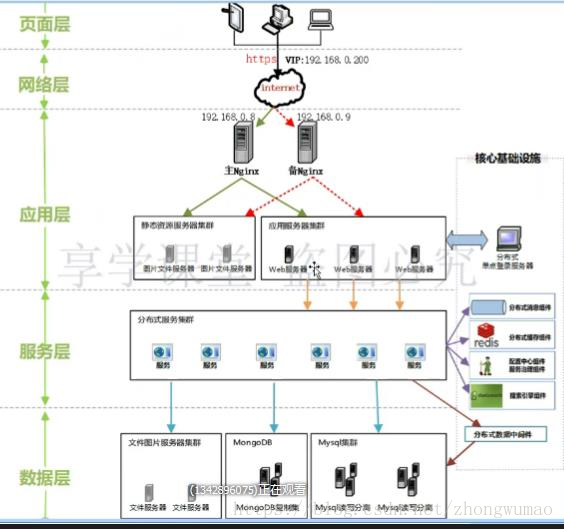
由图所示,简单的将系统的核心层分为:页面层、网络层、应用层、服务层、和持久层。
假如负载均衡层使用的是高性能的Nginx,则我们可以预估Nginx最大的并发度为:10W+,这里是以万为单位。
假设应用层我们使用的是Tomcat,而Tomcat的最大并发度可以预估为800左右,这里是以百为单位。
假设持久层的缓存使用的是Redis,数据库使用的是MySQL,MySQL的最大并发度可以预估为1000左右,以千为单位。Redis的最大并发度可以预估为5W左右,以万为单位。
所以,负载均衡层、应用层和持久层各自的并发度是不同的,那么,为了提升系统的总体并发度和缓存,我们通常可以采取哪些方案呢?
(1)系统扩容
系统扩容包括垂直扩容和水平扩容,增加设备和机器配置,绝大多数的场景有效。
(2)缓存
本地缓存或者集中式缓存,减少网络IO,基于内存读取数据。大部分场景有效。
(3)读写分离
采用读写分离,分而治之,增加机器的并行处理能力
4.1.解决方案
结合实际的业务,应对高并发,可以从垂直、水平等方向,辅以相应的业务策略,最终设计出稳定、可靠的系统。
将用户的请求,从客户端到 db 层,层层递减
4.1.1.页面层
- 轻重逻辑分离:以秒杀为例,将抢到和到账分开;
- 抢到,是比较轻的操作,库存扣成功后,就可以成功了
- 到账,是比较重的操作,需要涉及到到事务操作
- 用户分流:以整点秒杀活动为例,在 1 分钟内,陆续对用户放开入口,将所有用户请求打散在 60s 内,请求就可以降一个数量级;同理,12306购票,双十一秒杀,将瞬时流量平滑分配到较长的时间内,这就是所谓的削峰
- 页面简化:在秒杀开始的时候,需要简化页面展示,该时刻只保留和秒杀相关的功能。例如,秒杀开始的时候,页面可以不展示推荐的商品。
- 通过限制用户请求的速率,将高峰期的访问流量平滑地分布到整个时间段内,从而达到减轻服务器压力、提高服务质量的目的
- 重试策略:如果用户秒杀失败了,频繁重试,会加剧后端的雪崩。如何重试呢?根据后端返回码的约定,有两种方法:
- 不允许重试错误,此时 ui 和文案都需要有一个提示。同时不允许重试
- 可重试错误,需要策略重试,例如二进制退避法。同时文案和 ui 需要提示。
- ui 和文案:秒杀开始前后,用户的所有异常都需要有精心设计的 ui 和文案提示。例如:【当前活动太火爆,请稍后再重试】【你的货物堵在路上,请稍后查看】等
- 前端随机丢弃请求可以作为降级方案,当用户流量远远大于系统容量时,人工下发随机丢弃标记,用户本地客户端开始随机丢弃请求。
4.1.2.网络层、应用层
- 所有请求需要鉴权,校验合法身份
- 如果是长链接的服务,鉴权粒度可以在 session 级别;如果是短链接业务,需要应对这种高并发流量,例如 cache 等
- 根据后端系统容量,需要一个全局的限流功能,通常有两种做法:
- 设置好 N 后,动态获取机器部署情况 M,然后下发单机限流值 N/M。要求请求均匀访问,部署机器统一。
- 维护全局 key,以时间戳建 key。有热 key 问题,可以通过增加更细粒度的 key 或者定时更新 key 的方法。
- 对于单用户/单 ip 需要频控,主要是防黑产和恶意用户。如果秒杀是有条件的,例如需要完成 xxx 任务,解锁资格,对于获得资格的步骤,可以进行安全扫描,识别出黑产和恶意用户。
4.1.3.服务层
- 逻辑层首先应该进入校验逻辑,例如参数的合法性,是否有资格,如果失败的用户,快速返回,避免请求洞穿到 db。
- 异步补单,对于已经扣除秒杀资格的用户,如果发货失败后,通常的两种做法是:
- 事务回滚,回滚本次行为,提示用户重试。这个代价特别大,而且用户重试和前面的重试策略结合的话,用户体验也不大流畅。
- 异步重做,记录本次用户的 log,提示用户【稍后查看,正在发货中】,后台在峰值过后,启动异步补单。需要服务支持幂等
- 对于发货的库存,需要处理热 key。通常的做法是,维护多个 key,每个用户固定去某个查询库存。对于大量人抢红包的场景,可以提前分配。
4.1.4.存储层DB
对于业务模型而言,对于 db 的要求需要保证几个原则:
- 可靠性
- 主备:主备能互相切换,一般要求在同城跨机房
- 异地容灾:当一地异常,数据能恢复,异地能选主
- 数据需要持久化到磁盘,或者更冷的设备
- 一致性
- 对于秒杀而言,需要严格的一致性,一般要求主备严格的一致。
5.高并发最佳实践方案
5.1.高性能的实践方案1
集群部署:通过负载均衡减轻单机压力。
多级缓存,包括静态数据使用 CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点 Key、缓存穿透、缓存并发、数据一致性等问题的处理。
分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。 考虑 NoSQL 数据库的使用,比如 HBase、TiDB 等,但是团队必须熟悉这些组件,且有较强的运维能力。
异步化,将次要流程或耗时的操作通过多线程、MQ、甚至延时任务进行异步处理。
异步处理:将一些耗时的操作异步处理,如发送邮件、生成报表等,避免阻塞主线程,提高系统的并发能力。
限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx 接入层的限流、服务端的限流。 对流量进行削峰填谷,通过 MQ 承接流量。
并发处理,通过多线程将串行逻辑并行化。
预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
缓存预热,通过异步任务提前预热数据到本地缓存或者分布式缓存中。
减少 IO 次数,比如数据库和缓存的批量读写、RPC 的批量接口支持、或者通过冗余数据的方式干掉 RPC 调用。
减少 IO 时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存 Key 的大小、压缩缓存 Value 等。
程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For 循环的计算逻辑优化,或者采用更高效的算法。
各种池化技术的使用和池大小的设置,包括 HTTP 请求池、线程池(考虑 CPU 密集型还是 IO 密集型设置核心参数)、数据库和 Redis 连接池等。
JVM 优化,包括新生代和老年代的大小、GC 算法的选择等,尽可能减少 GC 频率和耗时。
锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
5.2.高可用的实践方案2
对等节点的故障转移,Nginx 和服务治理框架均支持一个节点失败后访问另一个节点。
非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL 的主从切换等)。
接口层面的超时设置、重试策略和幂等设计。
降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。 MQ 场景的消息可靠性保证,包括 Producer 端的重试机制、Broker 侧的持久化、Consumer 端的 Ack 机制等。
灰度发布,能支持按机器维度进行小流量部署,观察系统日志和业务指标,等运行平稳后再推全量。
监控报警:全方位的监控体系,包括最基础的 CPU、内存、磁盘、网络的监控,以及 Web 服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题
5.3.高扩展的实践方案3
合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层(但是需要评估性能,会存在网络多一跳的情况)。
存储层的拆分:按照业务维度做垂直拆分,按照数据特征维度进一步做水平拆分(分库分表)。
业务层的拆分:最常见的是按照业务维度拆(比如电商场景的商品服务、订单服务等),也可以按照核心接口和非核心接口拆,还可以按照请求源拆(比如 To C 和 To B,APP 和 H5)。 分布式 Trace、全链路压测、柔性事务都是要考虑的技术点
参考
https://mp.weixin.qq.com/s/uex9zkf2uPeTp56cfv4dHA
https://mp.weixin.qq.com/s/fDn4iHWuBEfzvNnVrWud2w
https://www.cnblogs.com/hanease/p/15863393.html
https://www.cnblogs.com/sy270321/p/12503504.html
https://zhuanlan.zhihu.com/p/109742840?from_voters_page=true&utm_id=0
https://juejin.cn/post/6865202367672320014