
题目: Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
Paper: https://arxiv.org/pdf/2303.14184.pdf
Code: https://make-it-3d.github.io/
前言
在本文中,研究者的目标是:从一个真实或人工生成的单张图像中创建高保真度的3D内容。这将为艺术表达和创意开辟新的途径,例如为像Stable Diffusion这样的前沿2D生成模型创建的幻想图像带来3D效果。通过提供一种更易于访问和自动化的创建视觉上惊人的3D内容的方法,研究者希望吸引更广泛的受众加入到轻松的3D建模世界中来。

本文探讨了仅使用单张图像创建高保真度3D内容的问题。这本质上是一项具有挑战性的任务,需要估计潜在的3D几何结构,并同时产生未见过的纹理。为了解决这个问题,论文利用训练好的2D扩散模型的先验知识作为3D生成的监督。Make-It-3D采用两阶段优化pipeline:第一阶段通过在前景视图中结合参考图像的约束和新视图中的扩散先验来优化神经辐射场;第二阶段将粗略模型转化为纹理点云,并利用参考图像的高质量纹理,结合扩散先验进一步提高逼真度。大量实验证明,论文的方法在结果上显著优于先前的方法,实现了预期的重建效果和令人印象深刻的视觉质量。论文是第一个尝试从单张图像为一般对象创建高质量3D内容的方法,可用于text-to-3D的创建和纹理编辑等各种应用。
提示:以下是本篇文章正文内容
一、方法
论文利用了文本-图像生成模型和文本-图像对比模型的先验知识,通过两阶段(Coarse Stage和Refine Stage)的学习来还原高保真度的纹理和几何信息,所提出的两阶段三维学习框架如图所示。
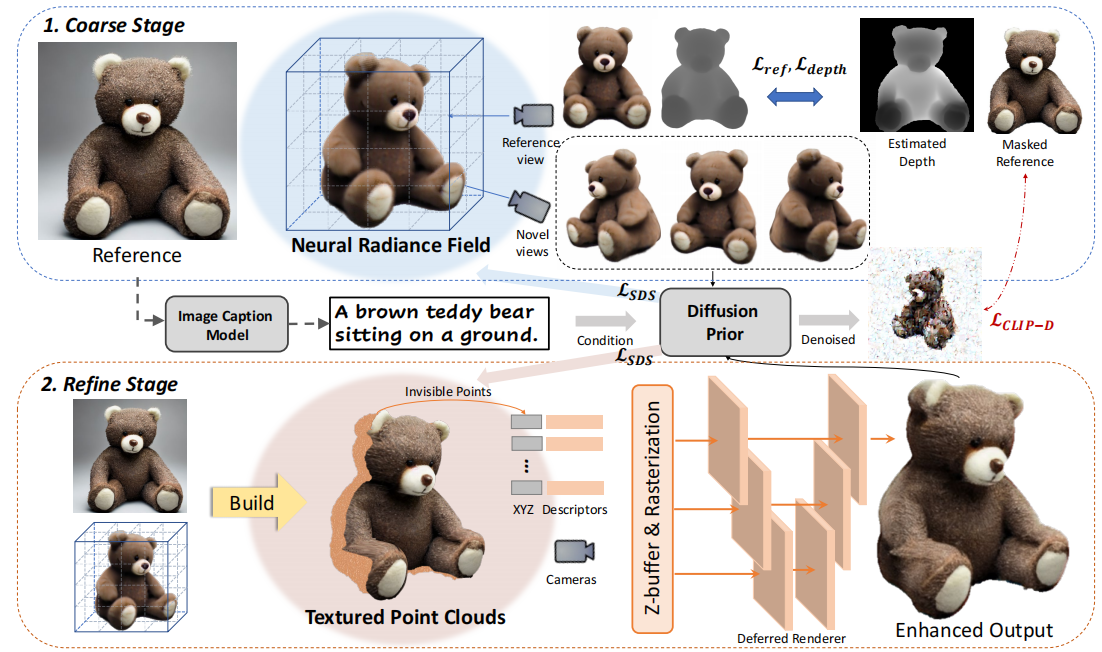
1.第一阶段 Coarse Stage: Single-view 3D Reconstruction
作为第一阶段,论文从单一参考图像 x 重建一个粗糙的NeRF,以扩散先验约束新的视角。优化的目标是同时满足以下要求:
1.优化后的三维表示应该与输入观测x在参考视图上的渲染结果非常相似
2.新视图渲染应该显示与输入一致的语义,并尽可能可信
3.生成的3D模型应该表现出引人注目的几何形状
鉴于此,论文对参考视图周围的相机姿态进行随机采样,并对参考视图和未可见视图的渲染图像 gθ 施加以下约束:
1.参考点的像素损失 Reference view per-pixel loss
优化后的三维表示应该与输入观测 x 在参考视图上的渲染结果非常相似,因此惩罚NeRF渲染图像和输入图像之间的像素级差异:
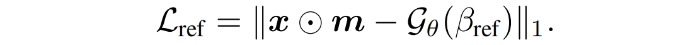
其中使用前景matting mask m 来分割前景。
2.扩散模型先验 Diffusion prior
新视图渲染应该显示与输入一致的语义,为了解决这个问题,论文使用一个图像字幕模型,为参考图像生成详细的文本描述 y。有了文本提示 y,可以在Stable Diffusion的潜空间上执行LSDS (利用text conditioned扩散模型作为3D感知先验),度量图像和给定文本提示符之间的相似性:
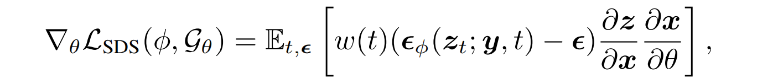
虽然 LSDS 可以生成忠实于文本提示的3D模型,但它们并不能与参考图像完全对齐(参见上图中的baseline),因为文本提示不能捕获所有的对象细节。因此,论文额外添加一个扩散CLIP损失,记为LCLIP-D ,它进一步强制生成的模型来匹配参考图像:
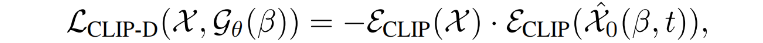
具体来说,论文并没有同时优化LCLIP-D 和LSDS 。论文在小timesteps使用LCLIP-D ,在大timesteps切换到LSDS 。结合LSDS和LCLIP-D,论文的扩散先验确保了生成的3D模型在视觉上是吸引人的和可信的,同时也符合给定的图像(见上图)。
3.深度先验 Depth prior
此外,模型仍然存在形状模糊,从而导致诸如凹陷面、过平面几何或深度模糊等问题(见图3)。为了解决这个问题,论文使用一个现有的单目深度估计模型来估计输入图像的深度 d 。为解释d 中的不准确性和尺度不匹配,论文正则化了NeRF在参考视点上的估计深度 d(βref) 和单目深度 d 之间的negative Pearson correlation,即:
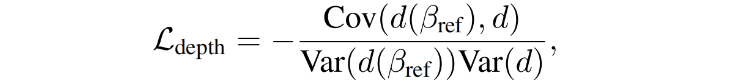
4.训练整体 Overall training
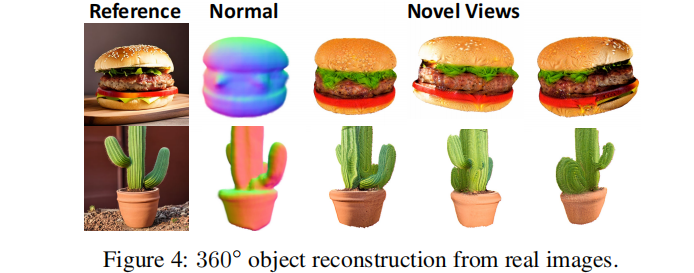
最终总的损失可以表述为Ldepth、Lref、LCLIP-D 和 LSDS 的组合。为了稳定优化过程,论文采用了渐进式训练策略,在参考视图附近从一个狭窄的视图范围开始,在训练过程中逐渐扩大范围。通过渐进式的训练,论文可以实现一个360°的物体重建,如上图所示。
2.第二阶段 Refine Stage: Neural Texture Enhancement
在coarse stage,我们获得了一个具有合理几何形状的3D模型,但通常显示出粗糙的纹理,可能会影响整体质量。因此,需要进一步细化以获得高保真度的3D模型。
论文的主要思路是在保留粗糙模型几何形状的同时,优先进行纹理增强。我们利用新视角和参考视角中可观察到的重叠区域,来将参考图像的高质量纹理映射到3D表示中。然后,论文着重于增强参考视角中被遮挡区域的纹理。为了更好地实现这一过程,论文 将 NeRF 导出到显式表示形式——点云(虽然NeRF 作为一种粗糙表示,可以连续处理拓扑变化,但将参考图像投影到它上是具有挑战性的)。与Marching Cube导出的噪声网格相比,点云提供了更清晰和更直接的投影。
1.Textured point cloud building 纹理点云构建
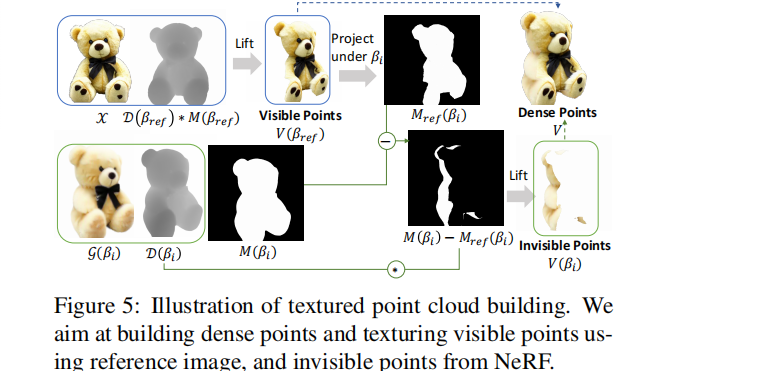
构建点云的一个简单尝试是从NeRF渲染多视图的RGBD图像,并将它们提升到3D空间中的纹理点。然而,我们发现这种简单的方法由于不同视图之间的冲突导致噪声点云:在不同视图[56]下,三维点在NeRF渲染中可能具有不同的RGB颜色。因此,我们提出了一个迭代策略来从多视图观测中建立干净的点云。如下图所示,我们首先根据NeRF的渲染深度D(βref)和alpha掩模M(βref)从参考视图βref 中构建点云,
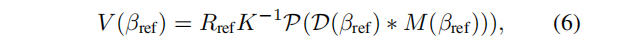
其中Rref 和 K 为相机的外在矩阵和内在矩阵,P表示深度到点的投影。这些点在参考视图下是可见的,因此可用GT 纹理着色。对于其余视图βi的投影,必须避免引入与现有点重叠但颜色冲突的点。为此,我们:
- 将现有的点V(βref)投影到新的视图βi中,以产生βi视角的伪掩模 Mref(βi)。
- 以这个掩模作为指导,我们只 lift 那些尚未观察到的点V(βi),如图5所示。
- 然后用NeRF渲染G(βi)中的粗糙纹理初始化这些看不见的点(也就是第一阶段产生的βi视角的结果 M(βi))。两者相减 M(βi)- Mref(βi),就得到 原始输入得到的点云中,看不见的背后点的mask。将其映射成3维点,再补充到 visible points 中。
2.Deferred point cloud rendering 延迟点云渲染
到目前为止,我们已经建立了一组纹理点云V = {V(βref)、V(β1)、…,V(βN)}。虽然 V(βref) 已经有了从参考图像投影出来的高保真纹理,但在参考视图中被遮挡的其他点仍然遭受了来自粗糙NeRF的平滑纹理,如下图所示。为了增强纹理,我们优化了其他点的纹理,并使用扩散先验约束了新视图渲染。具体来说,我们为每个点优化了一个19维的描述符F,它的前三个维度是用初始的RGB颜色初始化的。
为了避免噪声颜色和 bleeding 伪影[2],我们采用了多尺度延迟渲染方案:给出一个新的视图β,我们对点云V进行K次栅格化,得到K个不同大小为 [W/2i,H/2i ] 的特征映射 Ii,其中i∈[0,K)。然后,这些特征映射被拼接起来,并使用一个联合优化的U-Net渲染器Rθ 渲染成一个图像 I:
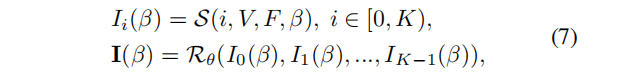
其中S是一个可微点光栅化器。纹理增强过程的目标类似于在第二节中讨论的几何创建。3.2,但是我们还包括了一个正则化术语,它惩罚优化纹理和初始纹理之间的巨大差异。
二、实验
1.实施细节
NeRF渲染。我们使用 Instant NGP 的多尺度哈希编码在粗优化阶段实现NeRF表示,较少计算代价。与Inestist-NGP类似,我们维持了一个占用网格,通过跳过空白空间来实现有效的射线采样。此外,我们在渲染图像上采用了一些阴影增强,如Lambertian 和 normal阴影。
点云渲染。对于延迟渲染,我们使用 具有gated 卷积的 2D U-Net 架构。点描述符的维度为19,其中前3个维度初始化RGB颜色,其余维度随机初始化。我们还为背景设置了一个可学习的描述符。
相机设置。我们以75%的概率随机抽样新的视图,并以25%的概率抽样预定义的参考视图。我们还在使用NeRF渲染时随机放大FOV。
分数蒸馏采样。我们在200到600之间随机抽样t,并根据时间步长将w (t)设置为均匀加权。我们还使用了无分类器的指导和指导权重ω: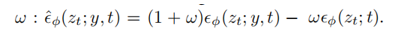
。我们的方法旨在将创建的三维模型与输入图像对齐,并使用引导权重ω = 10。
训练速度。Adam ,两阶段学习率都为0.001。粗阶段在100×100的渲染分辨率下训练5000次迭代;精细化阶段将以800×800的渲染分辨率再进行5,000次迭代。在一个特斯拉32GB V100 GPU上,训练大约2个小时。
测试基准。我们建立了一个由400张图像组成的测试基准,包括真实图像和由stable diffusion 生成的图像。基准测试中的每个图像都伴随有前景alpha掩码、估计深度映射和文本提示。对真实图像的文本提示从图像标题模型中获得。
2.与SOTA模型的比较
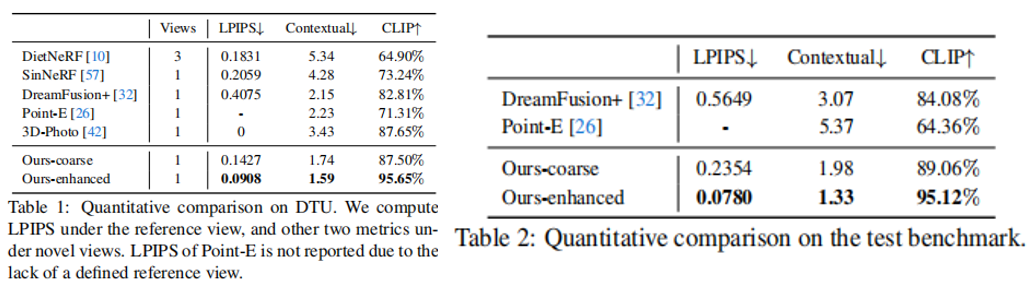
基线 。我们将我们的方法与五种有代表性的基线进行了比较。1) DietNeRF ,一个few-shot 的NeRF。我们用三个输入视图来训练它。2) SinNeRF ,一种单视图NeRF方法。3) DreamFusion由于它最初是基于文本提示的,我们也在参考视图中进行了修改,称为DreamFusion+,以进行公平比较。4)Point-E,基于图像的点云生成。5)3D-Photo,基于深度的图像扭曲和内部 inpaint 方法。
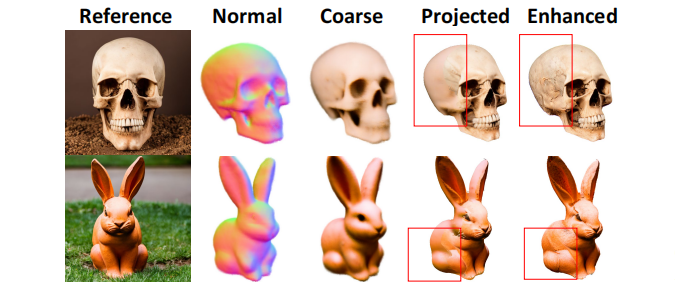
定性比较。我们首先将我们的方法与三维生成基线进行比较,其中DreamFusion++利用二维扩散作为3D先验,而PointE是一个三维扩散模型。如图7所示,他们生成的模型不能与参考图像对齐,并且遭受纹理平滑。相比之下,我们的方法产生了高保真的三维模型与精细的几何形状和真实的纹理。图8显示了对新视图合成的额外比较。由于SinNeRF和由于缺乏多视图监督,DietNeRF在重建复杂对象时遇到了困难。三维照片无法重建底层的几何图形,并在大视图中产生可见的伪影。相比之下,我们的方法在新颖的视角下实现了非常忠实的几何形状和视觉上令人愉悦的纹理。

总结
我们介绍了Make-It-3D,一种新的两阶段方法,从一个创建高保真三维内容的单一图像。利用扩散先验作为3D感知监督,生成的3D模型显示出 faithful 的几何形状和真实的纹理与扩散剪辑损失和纹理点云增强。Make-It-3D 适用于一般对象,赋予多用途迷人的应用。我们相信,我们的方法在将2D内容创建的成功扩展到3D方面迈出了一大步,为用户提供了一个全新的3D创建体验。