大数据平台不仅需要稳定地运行生产任务,还需要提供数据开发的能力。因此,不少大数据平台都会为每个任务区分开发模式与线上模式,可以通过提交上线的方式,将开发模式任务提交到线上,让其用于线上数据生产工作。
开发模式与线上模式其实可以看成两个代码相似,但完全独立的任务,为了便于后续描述,将其分别称为开发模式任务与线上模式任务。
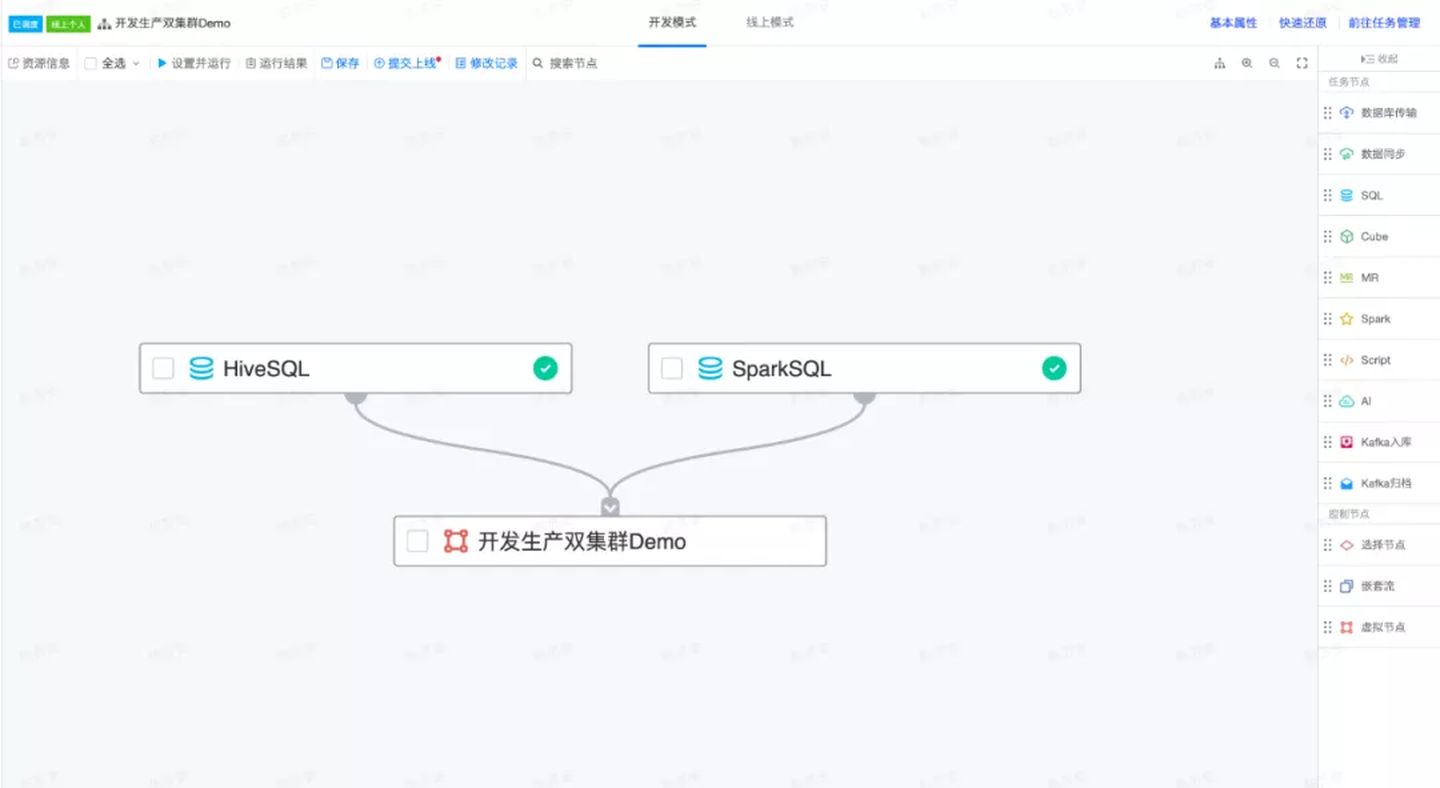
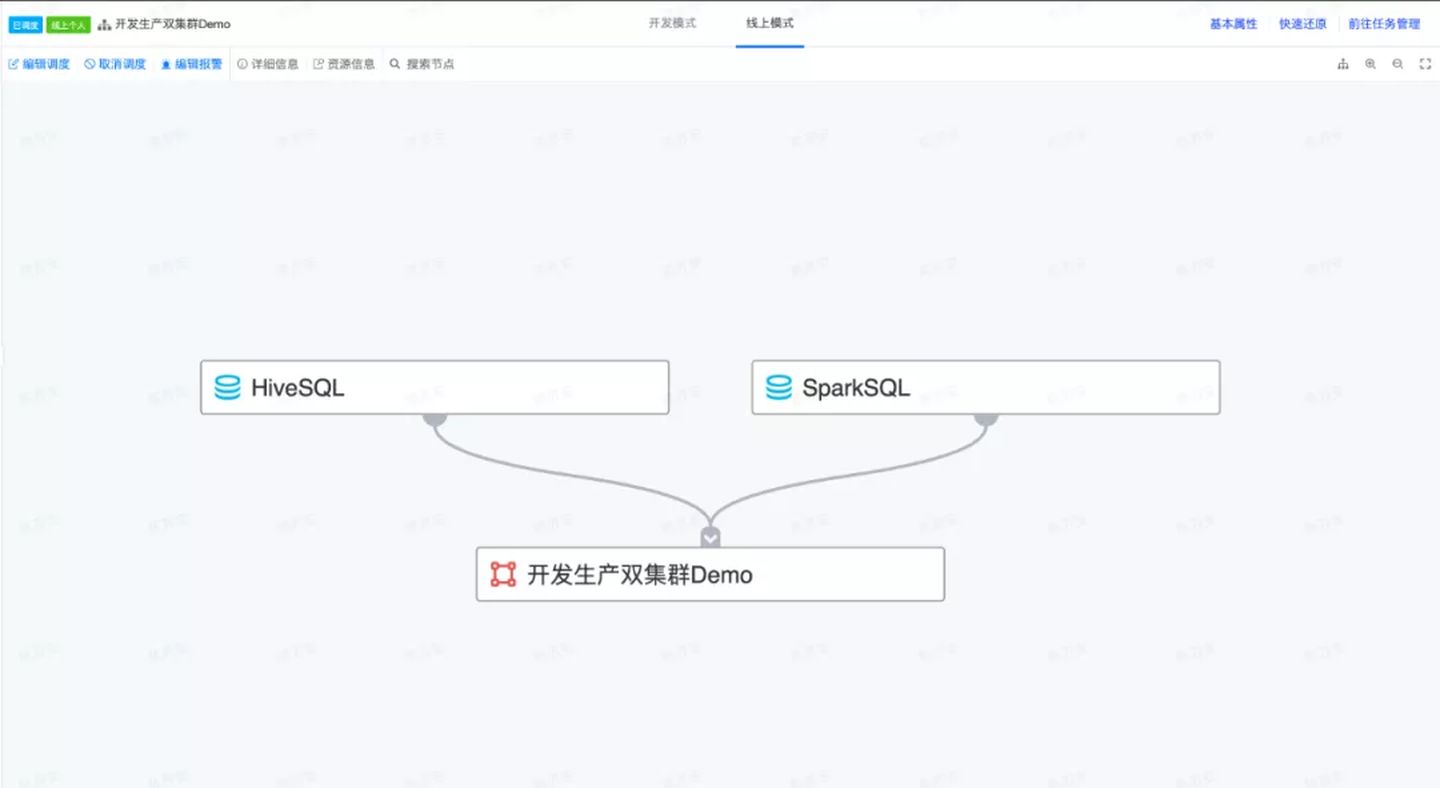 开发模式下的任务可以进行编辑、运行、调试。当任务开发完毕后,通过提交上线功能,将开发模式的任务提交到线上,也即使用开发模式的任务代码覆盖原本的线上模式任务代码。线上模式下的任务是用于生产的,因此该模式下的任务不可以编辑、调试,但可以配置调度、依赖、报警。
开发模式下的任务可以进行编辑、运行、调试。当任务开发完毕后,通过提交上线功能,将开发模式的任务提交到线上,也即使用开发模式的任务代码覆盖原本的线上模式任务代码。线上模式下的任务是用于生产的,因此该模式下的任务不可以编辑、调试,但可以配置调度、依赖、报警。
问题背景
开发模式任务与线上模式任务代码虽然相似,但却是完全独立的,修改开发模式任务,并不会影响到线上模式任务。这在一定程度上避免了“开发阶段影响线上”的问题,但在实际的开发过程中,用户在调试某个开发任务时,由于数据与线上任务是同一份(引用了同一个 table 或者同一份 hdfs 数据),因此极易影响到线上的产出数据,造成线上数据被污染情况。
例如,某线上模式任务的代码如下:

由于业务需求的改变,需要将 ods_student 的数据按照年龄进行过滤(仅需要小于 18 岁的学生数据),则 SQL 被改写成:

但该 SQL 在开发阶段如果执行的话,会直接影响到线上的数据。针对该问题,大部分数据开发人员会建立一个 school.dwd_student_dev 表(该表作为 school.dwd_student 的开发表),然后在开发模式下写入数据到该表。
在提交上线时,再将 school.dwd_student_dev 改成 school.dwd_student。
虽然这样可以在一定程度上避免数据污染问题,但需要在提交上线时修改代码。由于生产级别的 SQL 非常复杂,会涉及很多表,因此很容易导致数据开发人员出现漏改、错改的情况。一旦将错误的代码提交上线后,便会导致线上问题/事故。
传统方案及优化空间
针对上述问题,业内最常见的解决方案是搭建完全独立的两套集群(不仅包含 hadoop 集群,还包含大数据平台子系统),一套作为开发集群、一套作为线上集群。在开发集群进行数据开发、测试,经过验证后,再通过手动/半自动的方式将开发任务、调度信息导入到线上集群。

传统双集群架构图
这种方式虽然完全避免了开发阶段影响线上的问题,但却失去了一些灵活性。
1. 实际的开发场景会经常遇到:开发阶段,需要读取线上数据进行开发、测试(往往是开发集群无此数据、或者在任务调优阶段开发集群数据量过小,无法模拟真实场景)。为了满足读取线上数据的需求,只能在使用的时候导入线上数据。导数过程非常耗时,针对一个存储数据较多的 table/hdfs 往往需要数个小时,这无疑给此方案增加了很多使用成本,致使该方案难以在业务落地。
2. 由于线上集群、开发集群是两套完全独立大数据平台,而且它们中间还需要保持数据的一致性(任务、表、调度数据的一致性)。众所周知,一致性在两套系统中是很难保证的,因此极有可能出现:提交上线的时候,发现线上没有该表;该表字段与开发集群不一致;设置依赖时发现被依赖的任务在线上集群不存在等等。
基于数据沙箱的集群隔离方案
网易有数大数据平台,引入了一种“数据沙箱”的机制,将代码与代码运行所需要的数据、环境变量解耦,根据代码的运行环境,自动关联所需要的数据和环境变量。一套代码,可以在不同的环境之间,无缝切换。下面,我们重点介绍一下,数据沙箱在生产、测试物理集群隔离场景下的应用。
“开发、生产双集群”方案的架构图如下所示:
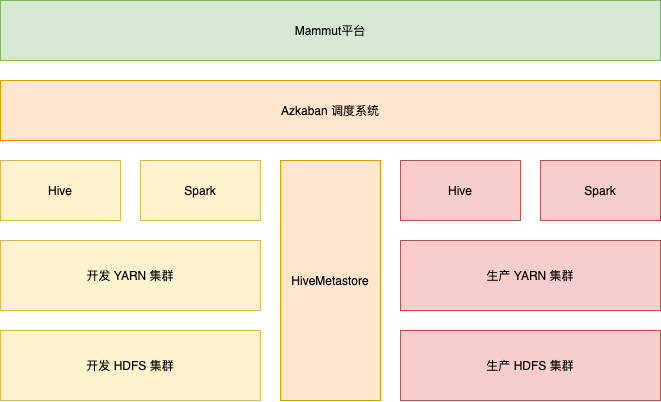
通过架构图可以看出,网易有数大数据平台具备真正意义上的开发模式任务与线上模式任务的数据、计算隔离。
在双集群场景下,网易有数大数据平台拥有两套独立的 HDFS 集群与 YARN 集群,在开发模式下默认读写开发 HDFS 集群,在线上模式下默认读写线上 HDFS 集群。这两套集群公用同一个 HiveMetastore 服务,开发模式下的 table 处于开发库下面,线上模式下的 table 处于线上库下面,这两个 table 的 location 分别指向开发 HDFS 集群、线上 HDFS 集群。同时,网易有数大数据平台还提供 ${database} 的宏定义,在开发模式下支持将其自动替换为 database_dev,在线上模式下支持将其自动替换为 database。
以 school.ods_study 表举例,对应的开发表为 school_dev.ods_study。它们的 location 分别为:
线上表为“hdfs://online/warehouse/school.db/ods_study/”;
开发表为“hdfs://dev/warehouse/school.db/ods_study/”。
可以看出这两个表的 location 只有 authority 不同,path 部分完全一致。这样无论是使用 SQL 直接读写这两个表,还是通过 hdfs 操作这两个表的数据(外表操作),结合宏定义之后,代码都是完全相同的。
基于数据沙箱的开发生产双集群应用实践
在介绍完网易有数大数据平台“开发、生产双集群”功能的实现后,再了解一下双集群的使用姿势,以便更好的理解双集群的实现细节。
ETL 任务大部分都是 SQL 任务(操作 hive 表),还有少部分 MR、SparkRDD 任务(直接操作 HDFS 数据)。
操作SQL
开发阶段仅读写开发集群数据
SQL 编写如下:

该 SQL 在开发模式下运行,相当于执行如下 SQL:

该 SQL 在线上模式下运行,相当于执行如下 SQL:

从开发模式与线上模式的 SQL 可以看出,该 SQL 在提交上线时完全不需要修改代码的,便可以在执行时通过宏替换的方式,动态的完成开发模式下读写开发集群数据,线上模式下读写线上集群数据。
开发阶段读线上集群数据,写开发集群数据
SQL 编写如下:

该 SQL 在开发模式下运行,相当于执行如下 SQL:

该 SQL 在线上模式下运行,相当于执行如下 SQL:

从开发模式与线上模式的 SQL 可以看出,该 SQL 在提交上线时完全不需要修改代码的,便可以在执行时通过宏替换的方式,动态的完成开发模式下读线上集群数据写入到开发集群,线上模式下读线上集群数据写入到线上集群。
操作 HDFS
HDFS 双集群使用姿势与 SQL 双集群使用姿势基本类似,SQL 是通过宏定义实现的,HDFS 是通过 default.fs 实现的。
比如:读开发集群的 HDFS 数据,写入到开发集群的 HDFS。
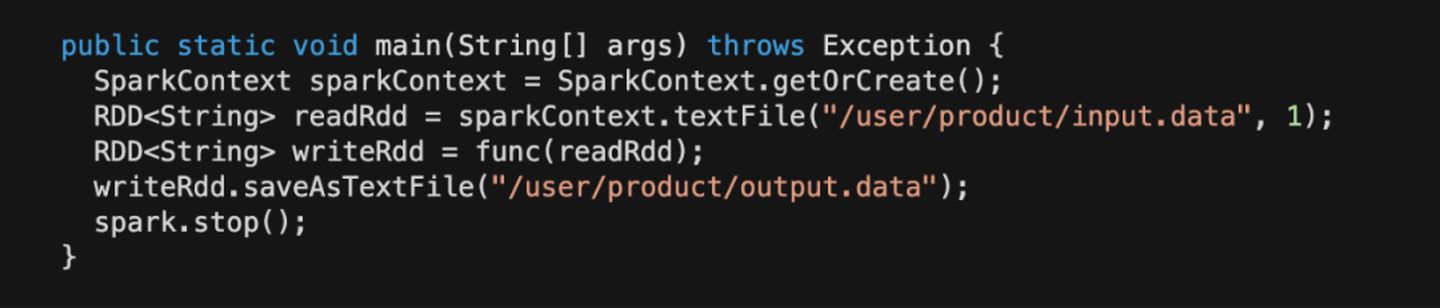
读开发集群的 HDFS 数据,写入到线上集群的 HDFS。

通过代码对比可以发现,使用MR、SparkRDD操作 HDFS 数据时,也无需修改代码即可提交上线,同一份代码在两套环境都完全适用。同时还完全保留了,开发环境读写开发集群数据、开发环境读线上数据,写开发数据的特性。
应用效果
网易有数大数据平台通过开发、生产双集群,实现了开发模式任务与线上模式任务,在代码、数据、计算上的隔离,同时在提交上线节点还避免了修改代码。通过开发、生产双集群功能,即保证了开发的效率,还保证了线上数据不被污染的问题。
同时,在开发、生产双集群中,网易大数据平台还引入了数据脱敏的功能,在开发阶段,如果读取线上敏感数据,将会进行脱敏处理。在保证数据安全的前提下,解决了数据开发、测试、发布阶段效率问题。