前言
需要提取的图像特征:
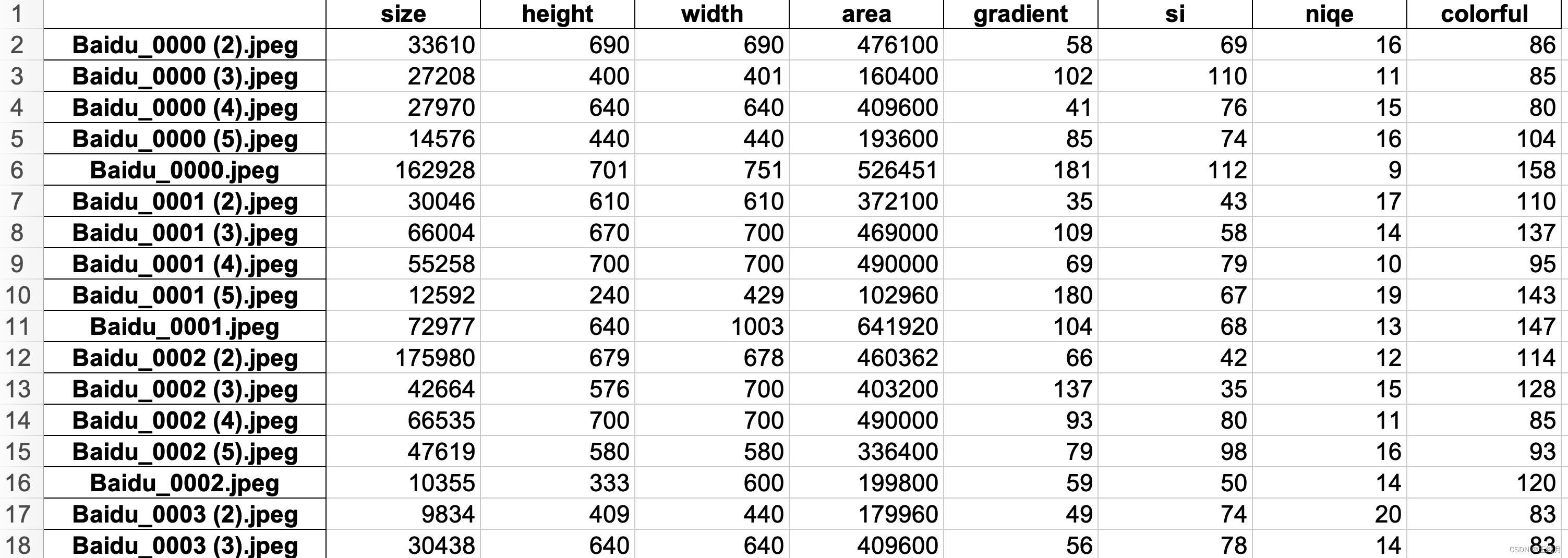
1.文件大小;2.宽;3.高;4.图片尺寸;5.图像梯度(表征图像纹理的复杂程度);6.sobel算子(表征图像复杂度);7.色彩丰富度;8.无参考图像评价指标NIQE。
最后根据上述图像信息可对相同的图片进行去重操作
代码
# *encoding=utf-8
import re
import os
import cv2
import math
import numpy as np
import pandas as pd
import skvideo.measure
# sobel算子
def SI_IMG(img):
sobelx = cv2.Sobel(img, cv2.CV_64F, dx=1, dy=0)
sobelx = cv2.convertScaleAbs(sobelx).astype('float32')
sobely = cv2.Sobel(img, cv2.CV_64F, dx=0, dy=1)
sobely = cv2.convertScaleAbs(sobely).astype('float32')
a = sobelx * sobelx + sobely * sobely
result = np.sqrt(a).astype('float32')
stddv = result.std()
return stddv
# 色彩丰富度
def colorfulness_img(img):
B, G, R = cv2.split(img)
rg = R - G
yb = (R + G) / 2 - B
mean_rg = rg.mean()
stddv_rg = rg.std()
mean_yb = yb.mean()
stddv_yb = yb.std()
a1 = math.sqrt(stddv_rg * stddv_rg + stddv_yb * stddv_yb)
a2 = 0.3 * math.sqrt(mean_yb * mean_yb + mean_rg * mean_rg)
a = a1 + a2
return a
# 提取图像特征
def get_img_info(img_path):
try:
img = cv2.imread(img_path, flags=cv2.IMREAD_COLOR)
except:
return None
file_size = os.path.getsize(img_path)
img_height, img_width = img.shape[:2]
# img = img[img_height//4: img_height//4*3, img_width//4: img_width//4*3]
# img_height, img_width = img.shape[:2]
img_dy = img[:img_height - 1] - img[1:]
img_dx = img[:, :img_width - 1] - img[:, 1:]
img_gradient = np.mean(np.abs(img_dx)) + np.mean(np.abs(img_dy))
img_si = SI_IMG(img)
img_colorful = colorfulness_img(img)
if img_height > 192 and img_width > 192:
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
try:
img_niqe = skvideo.measure.niqe(img_gray)[0]
except:
img_niqe = -1
else:
img_niqe = -1
return file_size, img_height, img_width, img_height * img_width, img_gradient, img_si, img_niqe, img_colorful
if __name__ == '__main__':
root_dir = "../Image-Downloader-master/download_images/gan/emoji_combine" # emoji_all"
file_suffix = "jpeg|jpg|png"
output_excel = "img_combine_info.xls"
img_info_list = []
img_name_list = []
file_list = os.listdir(root_dir)
for img_name in file_list:
# 对处理文件的类型进行过滤
if re.search(file_suffix, img_name) is None:
continue
print(img_name)
img_path = root_dir + "/" + img_name
img_info = get_img_info(img_path)
if img_info is None:
print("error:", img_name)
continue
img_info_list.append(img_info)
img_name_list.append(img_name)
img_info_np = np.array(img_info_list)
img_info_df = pd.DataFrame(img_info_np, index=img_name_list,
columns=["size", "height", "width", "area", "gradient", "si", "niqe", "colorful"])
# 去重
img_info_df = img_info_df.drop_duplicates()
# 输出统计特征
writer = pd.ExcelWriter(output_excel)
img_info_df.to_excel(writer, index=True, float_format="%.f")
writer.save()
结果展示