目录
一、陈述式资源管理方法
1.kubernetes 集群管理集群资源的唯一入口是通过相应的方法调用 apiserver 的接口
2.kubectl 是官方的CLI命令行工具,用于与 apiserver 进行通信,将用户在命令行输入的命令,组织并转化为 apiserver 能识别的信息,进而实现管理 k8s 各种资源的一种有效途径
3.kubectl 的命令大全
kubectl --help
k8s中文文档:http://docs.kubernetes.org.cn/683.html
4.对资源的增、删、查操作比较方便,但对改的操作就不容易了
//查看版本信息
kubectl version

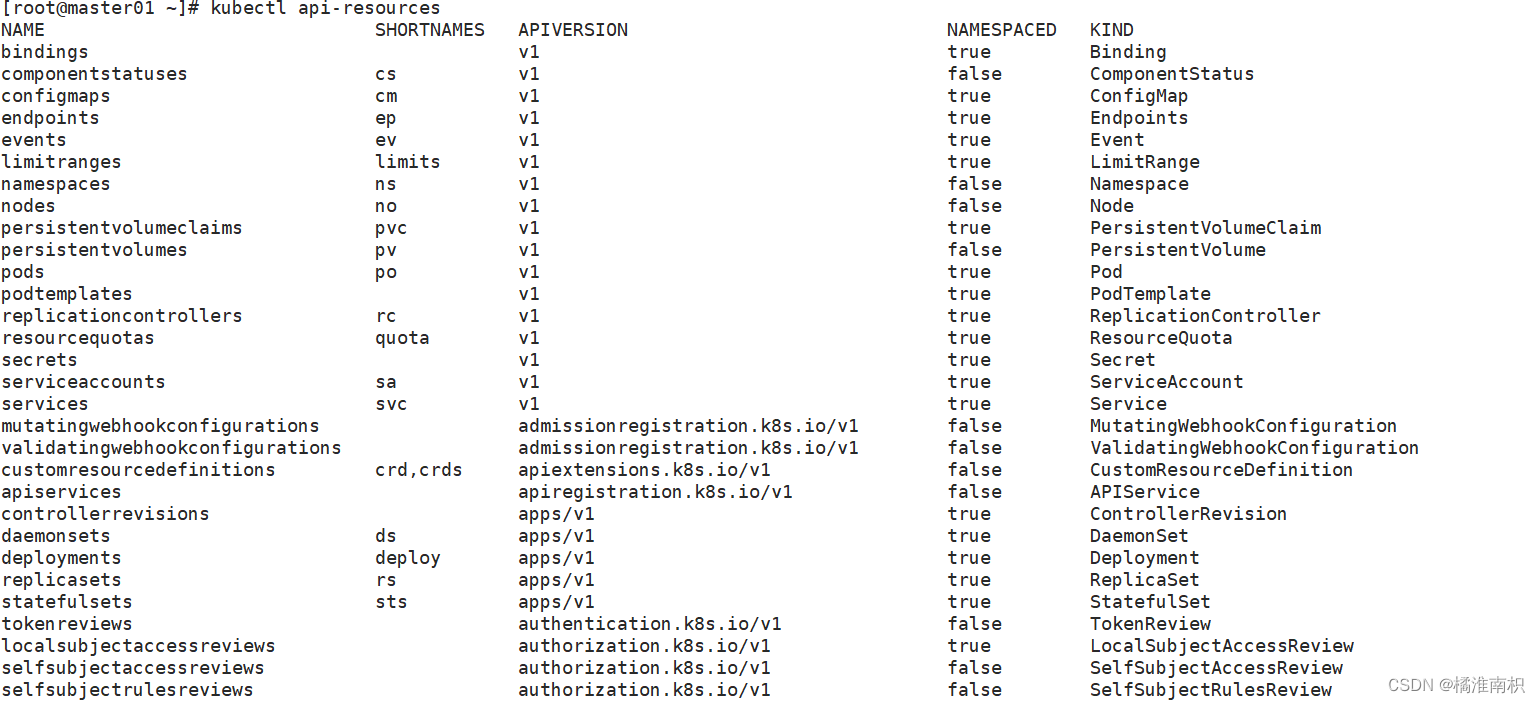
//查看资源对象简写
kubectl api-resources
//查看集群信息
kubectl cluster-info

//配置kubectl自动补全
source <(kubectl completion bash)
//node节点查看日志
journalctl -u kubelet -f
二、基本信息查看
kubectl get <resource> [-o wide|json|yaml] [-n namespace]
获取资源的相关信息,-n 指定命令空间,-o 指定输出格式
resource可以是具体资源名称,如pod nginx-xxx;也可以是资源类型,如pod;或者all(仅展示几种核心资源,并不完整)
–all-namespaces 或 -A :表示显示所有命名空间,
–show-labels :显示所有标签
-l app :仅显示标签为app的资源
-l app=nginx :仅显示包含app标签,且值为nginx的资源
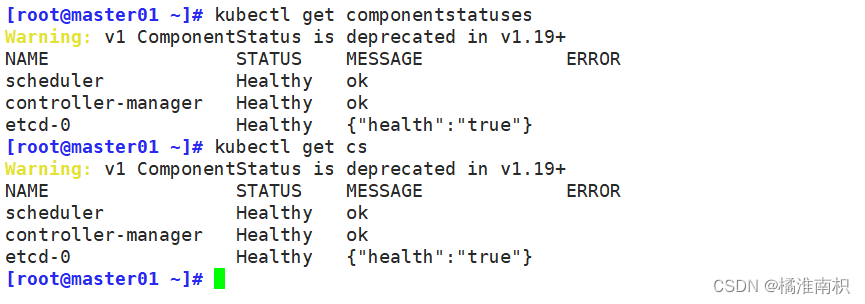
//查看 master 节点状态
kubectl get componentstatuses
kubectl get cs
//查看命名空间
kubectl get namespace
kubectl get ns
//命令空间的作用:用于允许不同 命名空间 的 相同类型 的资源 重名的
//查看default命名空间的所有资源
kubectl get all [-n default]

//创建命名空间app
kubectl create ns app
kubectl get ns

//删除命名空间app
kubectl delete namespace app
kubectl get ns
//在命名空间kube-public 创建副本控制器(deployment)来启动Pod(nginx-ll)
kubectl create deployment nginx-ll --image=nginx -n kube-public
//描述某个资源的详细信息
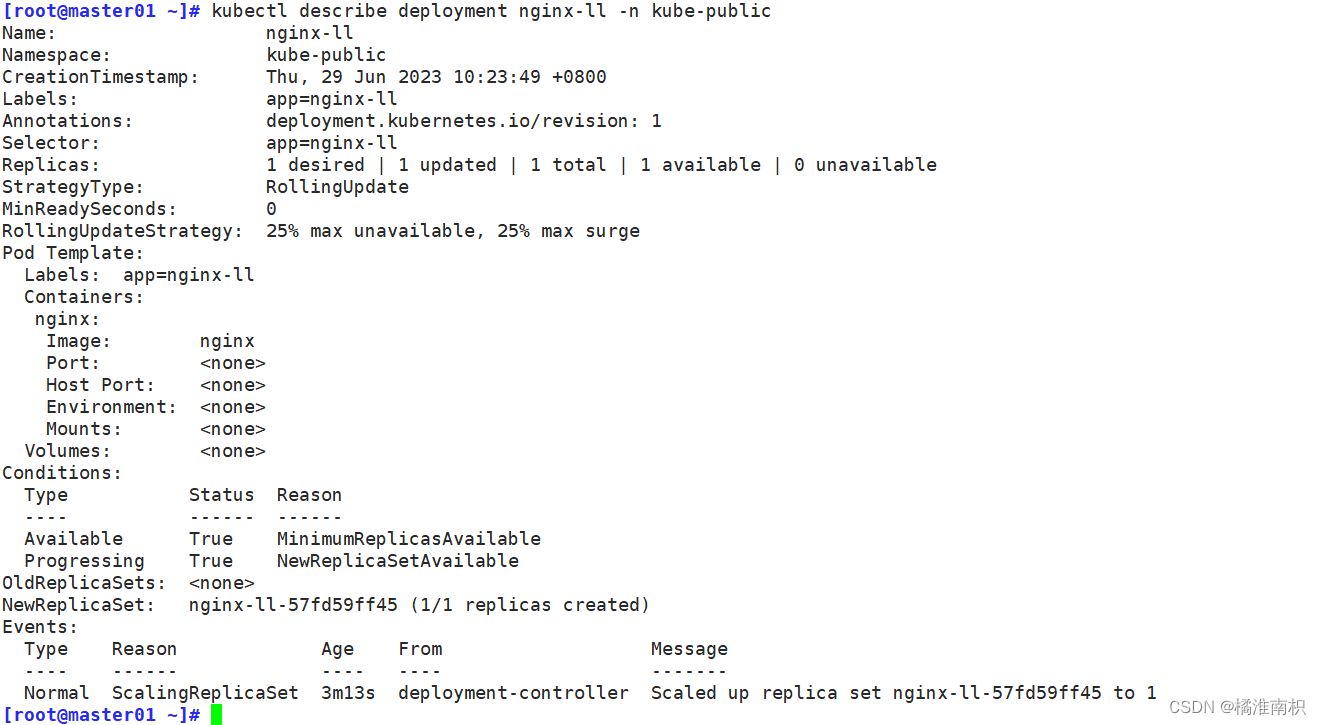
kubectl describe deployment nginx-ll -n kube-public
kubectl describe pod nginx-ll-57fd59ff45 -n kube-public
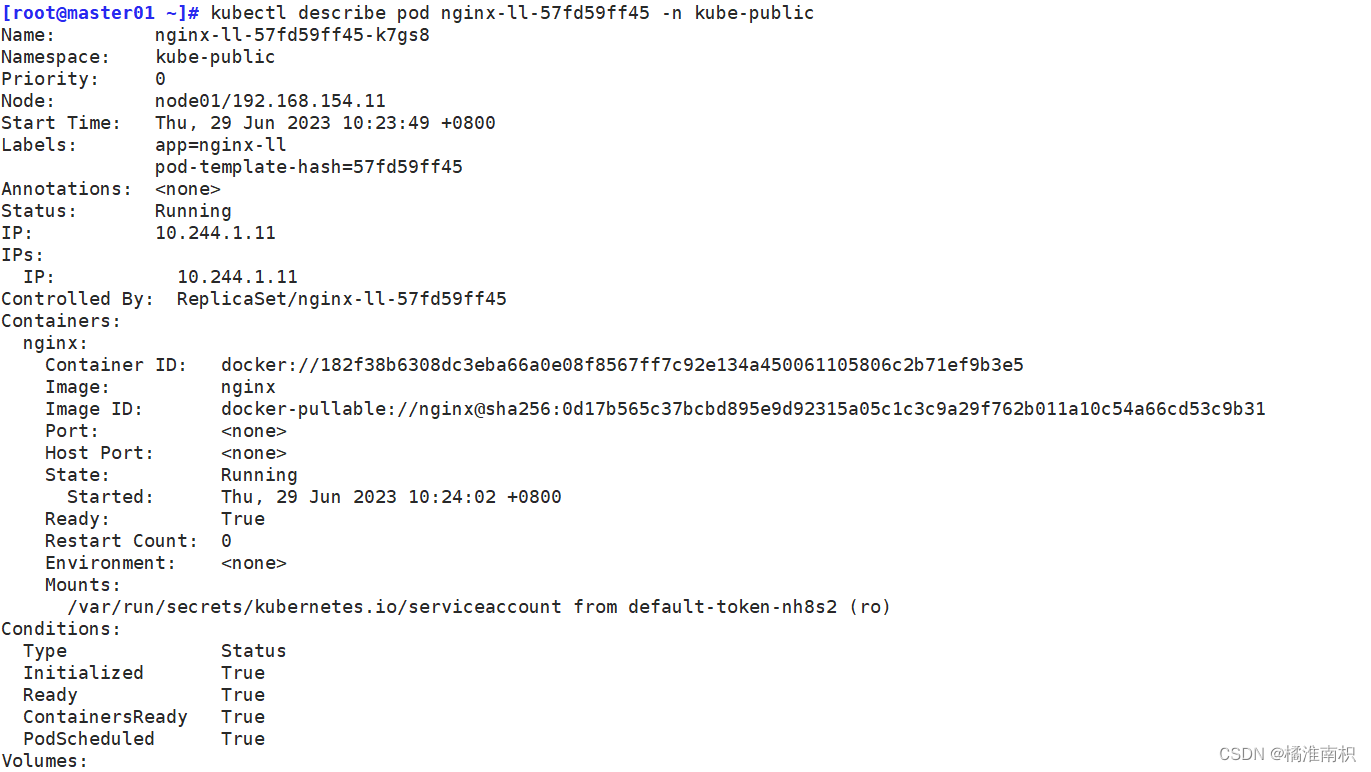
//查看命名空间kube-public 中的pod 信息
kubectl get pods -n kube-public
NAME READY STATUS RESTARTS AGE
nginx-ll-57fd59ff45-k7gs8 1/1 Running 0 29m

//kubectl exec可以跨主机登录容器,docker exec 只能在容器所在主机上登录
kubectl exec -it nginx-ll-57fd59ff45-k7gs8 bash -n kube-public

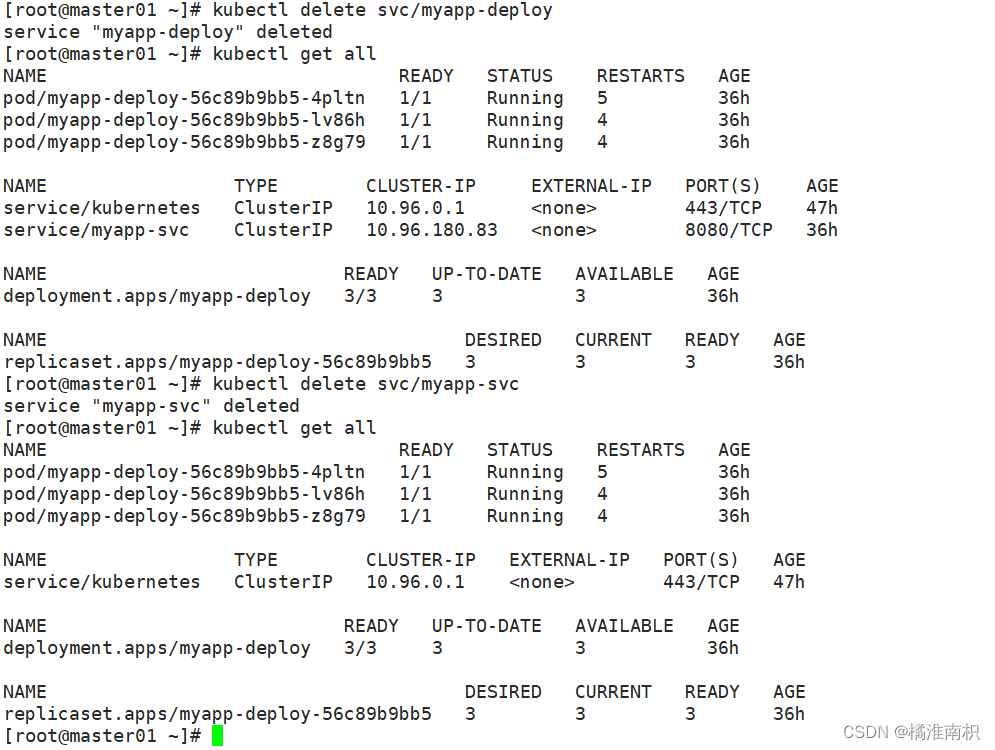
//删除(重启)pod资源,由于存在deployment/rc之类的副本控制器,删除pod也会重新拉起来
kubectl delete pod nginx-ll-57fd59ff45-k7gs8 -n kube-public

重点:若pod无法删除,总是处于terminate状态,则要强行删除pod
kubectl delete pod -n --force --grace-period=0
grace-period表示过渡存活期,默认30s,在删除pod之前允许pod慢慢终止其上的容器进程,从而优雅退出,0表示立即终止pod
//若pod无法删除,总是处于terminate状态,则要强行删除pod
kubectl delete pod <pod-name> -n <namespace> --force --grace-period=0
//grace-period表示过渡存活期,默认30s,在删除pod之前允许pod慢慢终止其上的容器进程,从而优雅退出,0表示立即终止pod
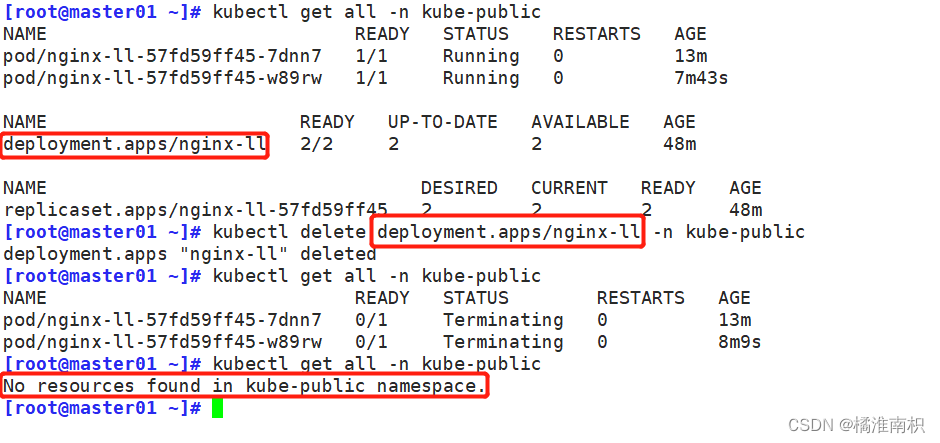
k8s没有重启的概念,只能删除重新拉取新的Pod,如果实在不想要这个Pod,就把控制器删了
kubectl delete <控制器NAME> -n <namespace>
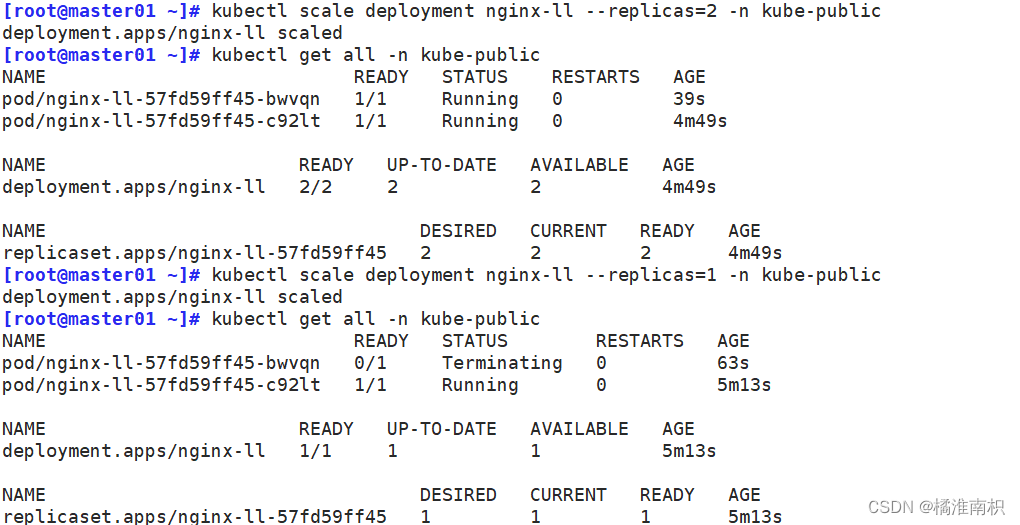
//扩缩容
kubectl scale deployment nginx-ll --replicas=2 -n kube-public // 扩容
kubectl scale deployment nginx-ll --replicas=1 -n kube-public // 缩容
//删除副本控制器
kubectl delete deployment nginx-ll -n kube-public
kubectl delete deployment/nginx-ll -n kube-public

项目的生命周期:创建–>发布–>更新–>回滚–>删除
2.1 创建 kubectl create命令
●创建并运行一个或多个容器镜像。
●创建一个deployment 或job 来管理容器。
kubectl create --help
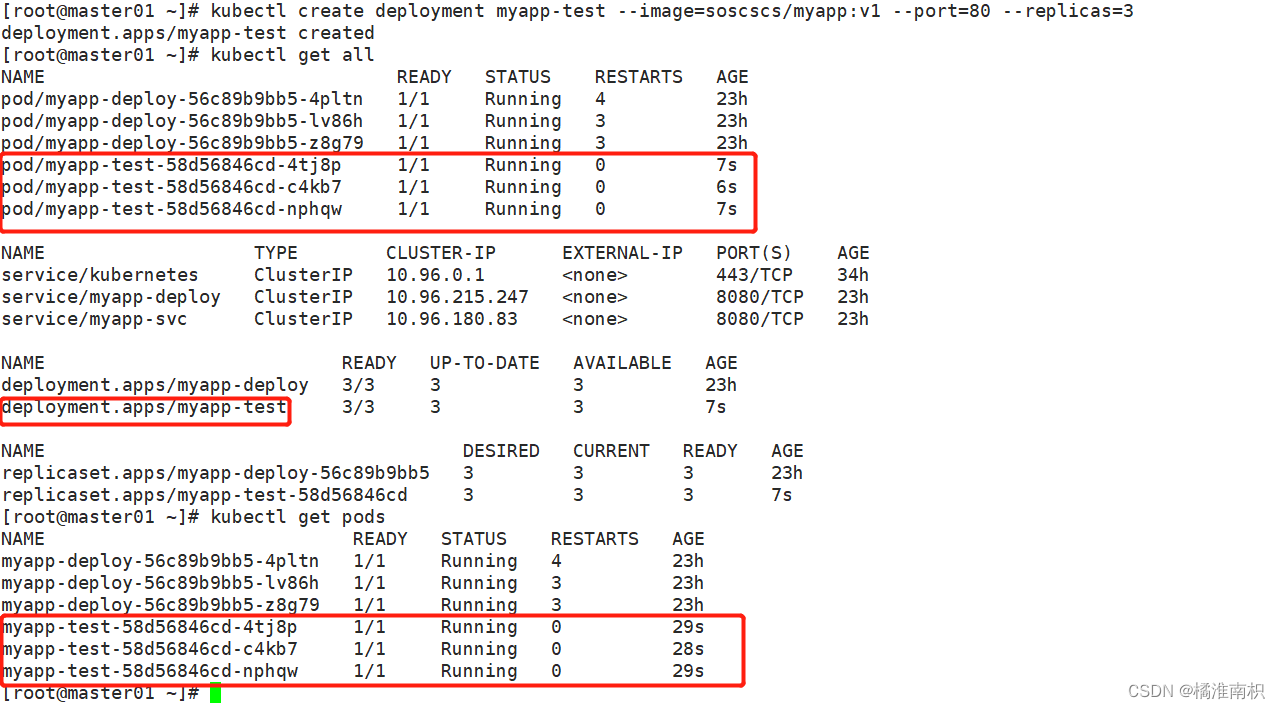
//启动一个实例,暴露容器端口 80,设置副本数 3
kubectl create deployment myapp-test --image=soscscs/myapp:v1 --port=80 --replicas=3
kubectl get pods
kubectl get all
2.2 发布 kubectl expose命令
●将资源暴露为新的 Service。
kubectl expose --help

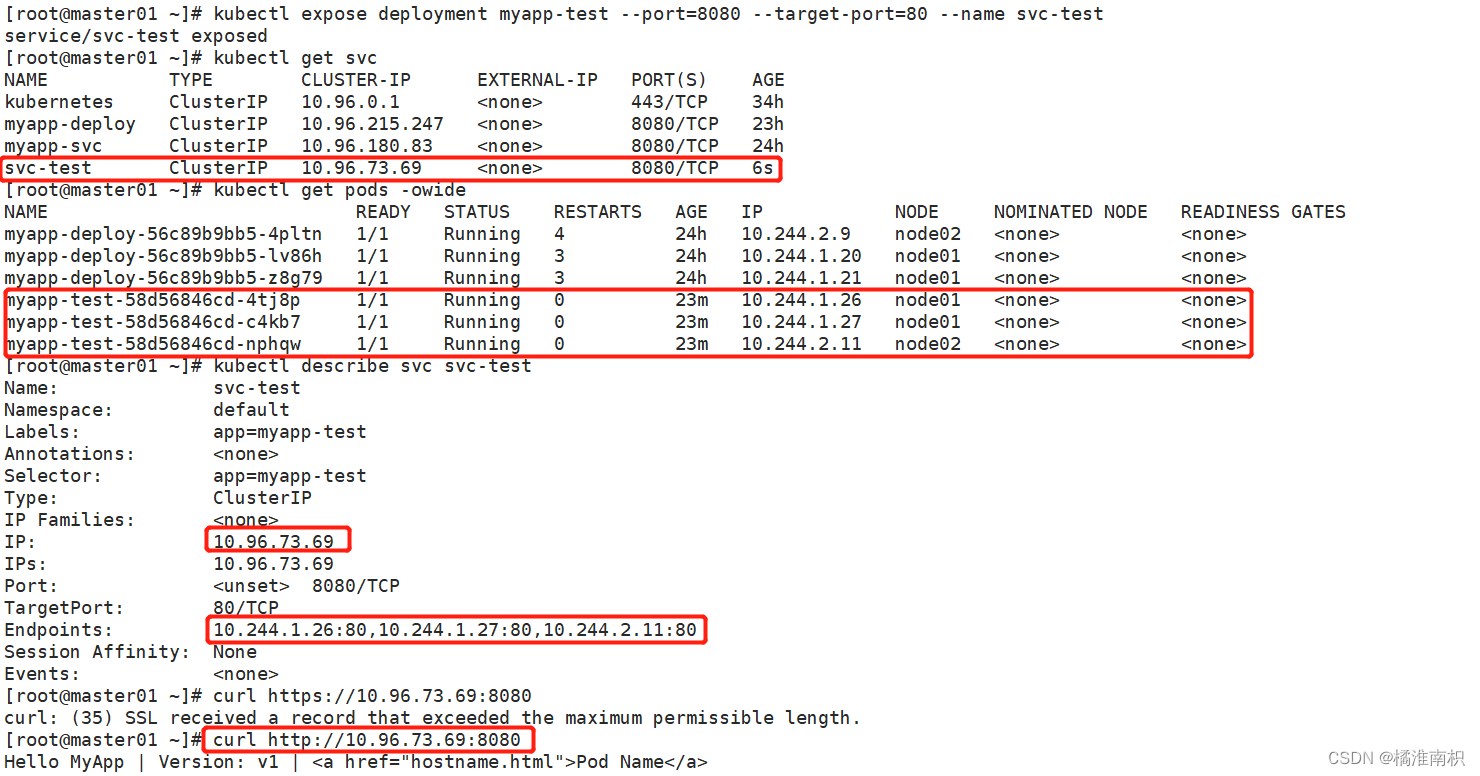
kubectl expose deployment myapp-test --port=8080 --target-port=80 --name svc-test
kubectl get svc
kubectl get pods -owide
kubectl describe svc svc-test
curl http://10.96.73.69:8080
//为deployment的nginx创建service,并通过Service的80端口转发至容器的80端口上,Service的名称为nginx-service,类型为NodePort
kubectl expose deployment myapp-test --port=80 --target-port=80 --name=nginx-service --type=NodePort
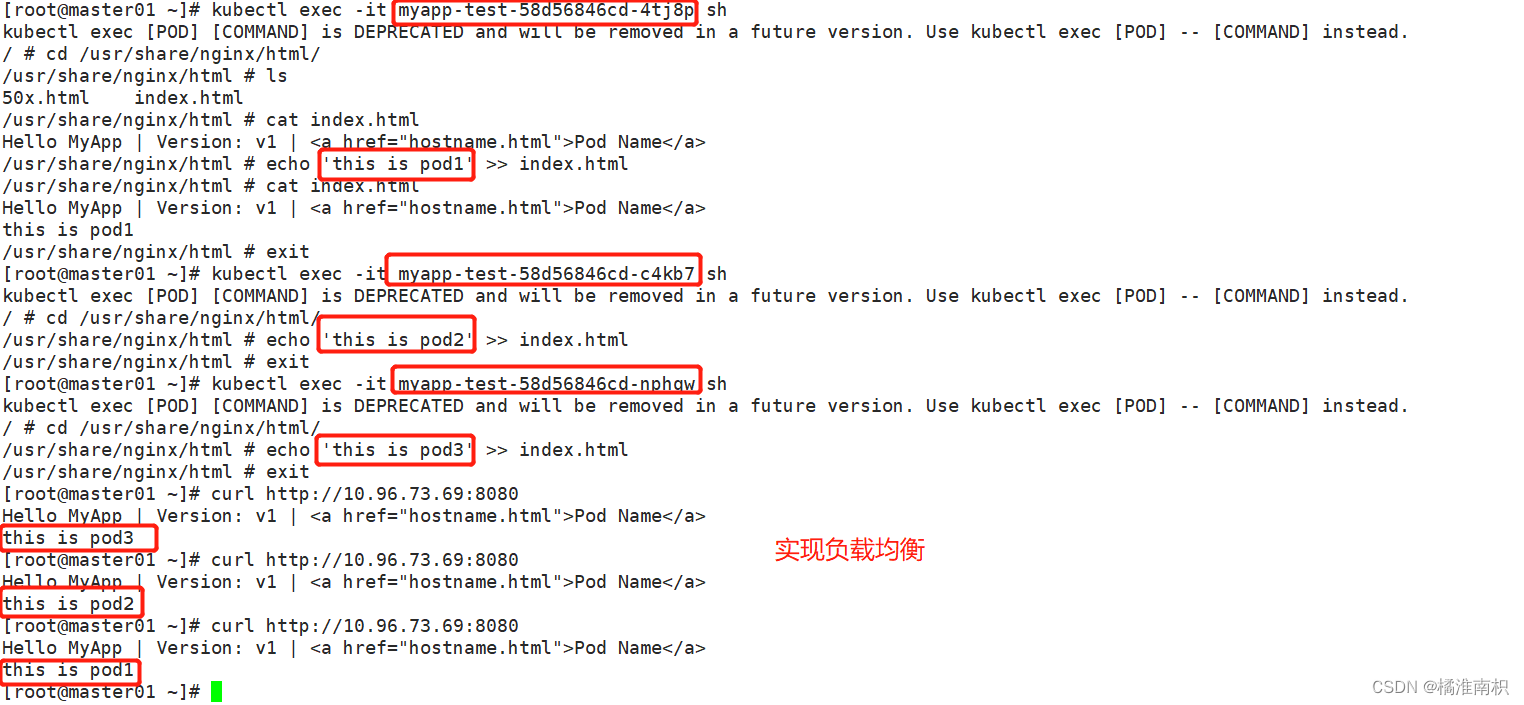
Kubernetes 之所以需要 Service,一方面是因为 Pod 的 IP 不是固定的(Pod可能会重建),另一方面则是因为一组 Pod 实例之间总会有负载均衡的需求。
Service 通过 Label Selector 实现的对一组的 Pod 的访问。
对于容器应用而言,Kubernetes 提供了基于 VIP(虚拟IP) 的网桥的方式访问 Service,再由 Service 重定向到相应的 Pod。
重点:Service是通过 Label Selector 关联到Pod的
2.3 service 的 type 类型
●ClusterIP:提供一个集群内部的虚拟IP以供Pod访问(service默认类型)
●NodePort:在每个Node上打开一个端口以供外部访问,Kubernetes将会在每个Node上打开一个端口并且每个Node的端口都是一样的,通过 NodeIp:NodePort 的方式Kubernetes集群外部的程序可以访问Service。
每个端口只能是一种服务,端口范围只能是 30000-32767。
●LoadBalancer:通过设置LoadBalancer映射到云服务商提供的LoadBalancer地址。这种用法仅用于在公有云服务提供商的云平台上设置Service的场景。通过外部的负载均衡器来访问,通常在云平台部署LoadBalancer还需要额外的费用。
在service提交后,Kubernetes就会调用CloudProvider在公有云上为你创建一个负载均衡服务,并且把被代理的Pod的IP地址配置给负载均衡服务做后端。
●externalName:将service名称映射到一个DNS域名上,相当于DNS服务的CNAME记录,用于让Pod去访问集群外部的资源,它本身没有绑定任何的资源。
k8s中的Ports
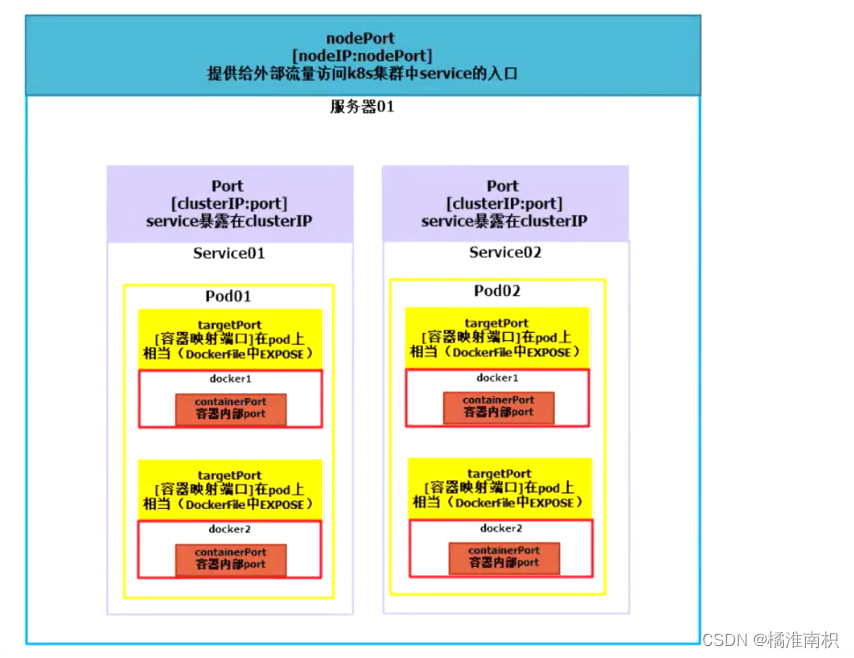
targetPort是容器映射端口 在集群内部,客户端通过clusterIP:port 转发 targetPort 再转发给容器内部;在外部客户端访问,通过 nodeIP:nodePort 转发到 targetPort 再转发给容器内部
containerPort是容器内部的端口 也是 kubectl create deployment --port (clusterip的端口) --target-port (容器端口) --name <自定义资源名称> --type (svc资源类型)

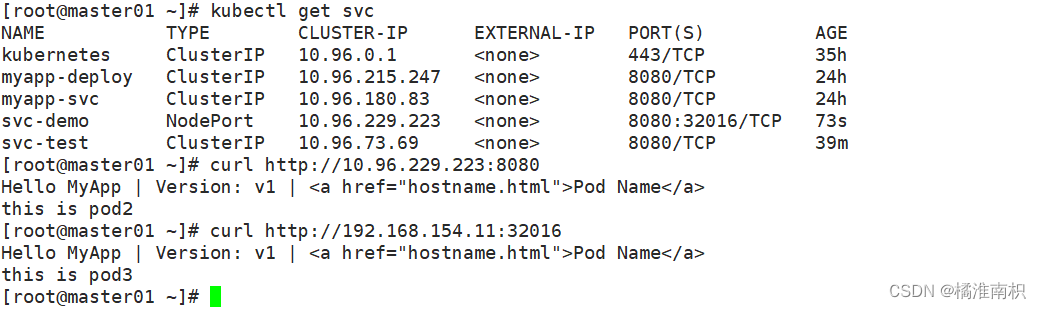
//查看pod网络状态详细信息和 Service暴露的端口
kubectl get pods,svc -o wide
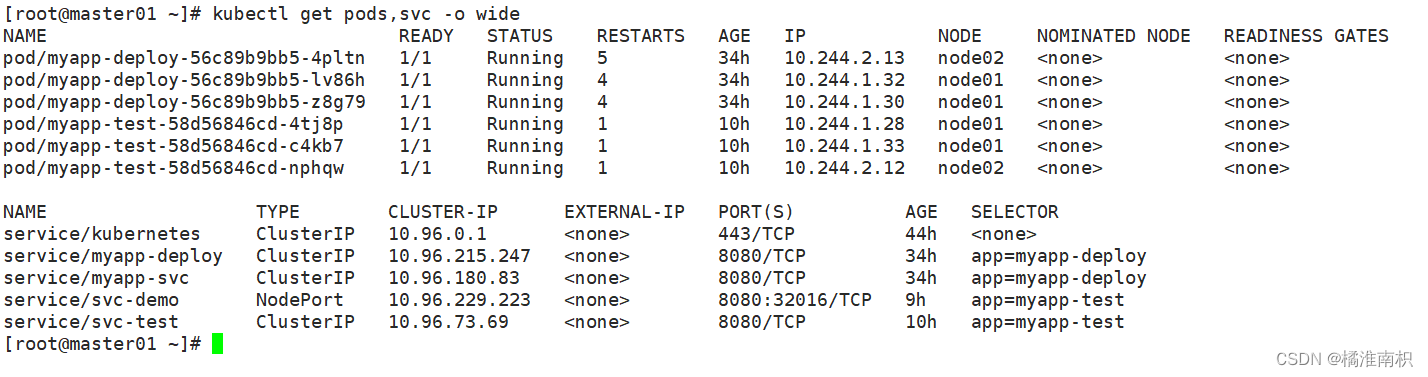
//查看关联后端的节点
kubectl get endpoints

//查看 service 的描述信息
kubectl describe svc svc-demo
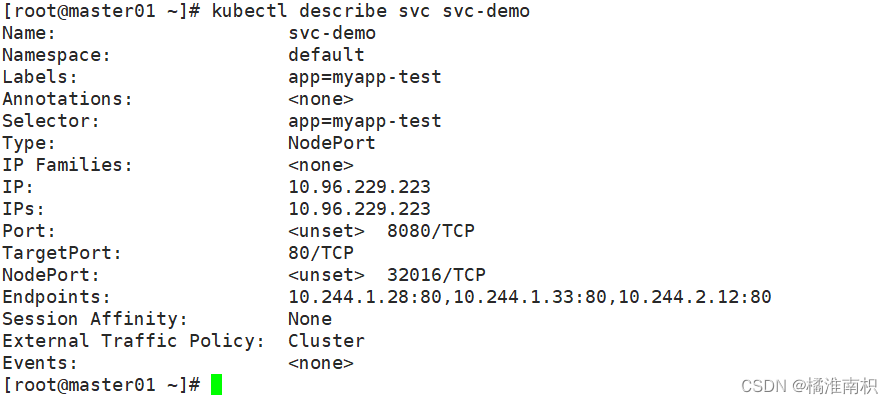
//在 node01 节点上操作,查看负载均衡端口
yum install ipvsadm -y
ipvsadm -Ln
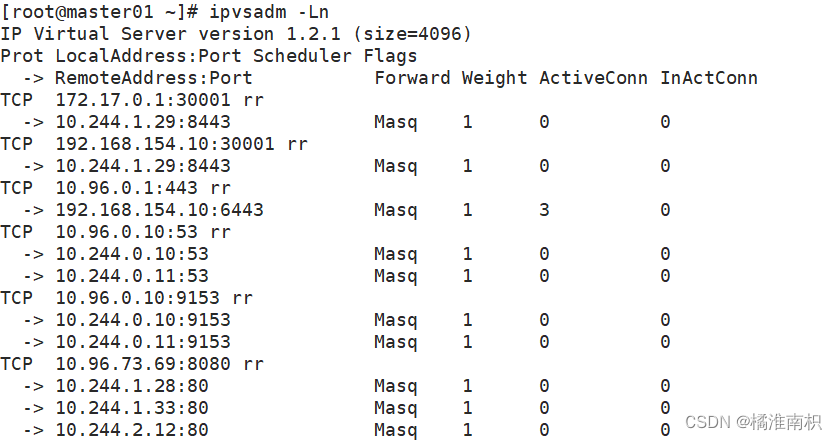
//在 master 节点上操作,同样方式查看负载均衡端口
kubectl get pod,svc
ipvsadm -ln -t 10.96.73.69:8080 #集群内部范访问的端口
ipvsadm -ln -t 192.168.154.10:32016 #外部访问的端口
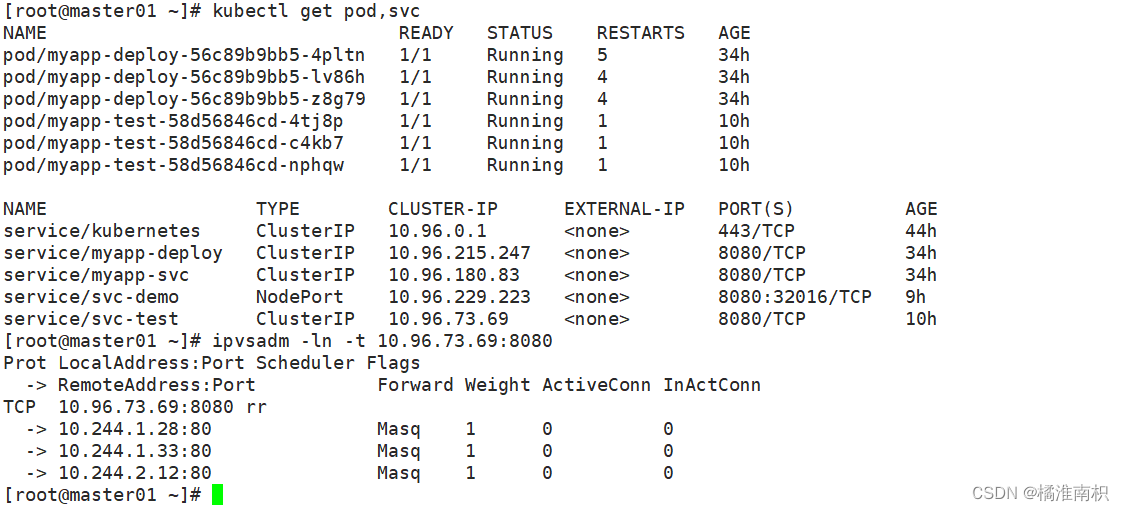

curl 10.96.73.69:8080
curl 192.168.154.10:32016
//在master01操作 查看访问日志
kubectl logs myapp-test-58d56846cd-c4kb7


2.4 K8s 如何查看 Pod 崩溃前的日志?
-
场景
当pod处于crash状态的时候,容器不断重启,此时用 kubelet logs 可能出现一直捕捉不到日志。 -
解决方法:
kubectl previous 参数作用:If true, print the logs for the previous instance of the container in a pod if it exists.
单容器pod:
kubectl logs pod-name --previous
多容器pod:
kubectl logs pod-name --previous -c container-name
比如:
NAME READY STATUS RESTARTS AGE
nginx-7d8b49557c-c2lx9 2/2 Running 5
kubectl logs nginx-7d8b49557c-c2lx9 --previous
Error: xxxxxxxxxxx
- 原理
kubelet会保持pod的前几个失败的容器,这个是查看的前提条件。 - 核心原理
kubelet实现previous的原理:将pod的日志存放在 /var/log/pods/podname,并且是链接文件,链接到docker的容器的日志文件,同时kubelet还会保留上一个容器,同时有一个链接文件链接到pod上一个崩溃的容器的日志文件,使用previous就是查看的这个文件
实践
比如查看一个pod:
ubuntu@~$ kubelet get pod
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 2394 99d
nginx-deployment-6wlhd 1/1 Running 0 79d
redis 1/1 Running 0 49d
到pod所在node查看kubelet放的两个日志文件:
ls /var/log/pods/default_busybox_f72ab71a-5b3b-4ecf-940d-28a5c3b30683/busybox
2393.log 2394.log
数字的含义:2393 证明是第 2393 次重启后的日志,2394 代表是第2394次重启后的日志。
实际这两个日志文件是链接文件,指向了docker的日志文件:
/busybox# stat 2393.log
File: 2393.log -> /data/kubernetes/docker/containers/68a5b32c9fdb1ad011b32e6252f9cdb759f69d7850e6b7b8591cb4c2bf00bcca/68a5b32c9fdb1ad011b32e6252f9cdb759f69d7850e6b7b8591cb4c2bf00bcca-json.log
Size: 173 Blocks: 8 IO Block: 4096 symbolic link
Device: fc02h/64514d Inode: 529958 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-01-31 13:32:03.751514283 +0800
Modify: 2023-01-31 13:32:03.039526838 +0800
Change: 2023-01-31 13:32:03.039526838 +0800
Birth: -
/busybox# stat 2394.log
File: 2394.log -> /data/kubernetes/docker/containers/2ed9ebf0585215602874b076783e12191dbb010116038b8eb4646273ebfe195c/2ed9ebf0585215602874b076783e12191dbb010116038b8eb4646273ebfe195c-json.log
Size: 173 Blocks: 8 IO Block: 4096 symbolic link
Device: fc02h/64514d Inode: 529955 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-01-31 14:32:03.991106950 +0800
Modify: 2023-01-31 14:32:03.183119308 +0800
Change: 2023-01-31 14:32:03.183119308 +0800
Birth: -
看到分别指向了这两个容器的日志文件,一个是当前pod里在跑的容器,一个是pod上次跑的容器,现在已经退出了
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2ed9ebf05852 ff4a8eb070e1 "sleep 3600" 24 minutes ago Up 24 minutes k8s_busybox_busybox_default_f72ab71a-5b3b-4ecf-940d-28a5c3b30683_2394
68a5b32c9fdb ff4a8eb070e1 "sleep 3600" About an hour ago Exited (0) 24 minutes ago k8s_busybox_busybox_default_f72ab71a-5b3b-4ecf-940d-28a5c3b30683_2393
使用logs的时候读的是当前容器那个文件,使用 –previous 的时候,读的是上次退出的容器的日志文件,由于kubelet为pod保留了上次退出的容器。
我们手动编辑这两个文件的内容,看kubelet是否读的是这两个文件
/busybox# cat 2393.log
{
"log":"last crash logs\n","stream":"stderr","time":"2022-11-05T08:11:27.31523845Z"}
/busybox# cat 2394.log
{
"log":"now pod log\n","stream":"stderr","time":"2022-11-05T08:11:27.31523845Z"}
ubuntu@10-234-32-51:~$ k logs busybox --previous
last crash logs
ubuntu@10-234-32-51:~$ k logs busybox
now pod log
由于是链接文件,那么可能实际是从别的地方读的,或者说直接读容器目录下的,由于链接文件我们改了后容器目录下的日志文件也跟着改了,我们直接创建两个文件来做验证:
ubuntu@10-234-32-51:~$ k get pod
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 2395 99d
nginx-deployment-6wlhd 1/1 Running 0 79d
redis 1/1 Running 0 49d
/busybox# ls
2394.log 2395.log
/busybox# rm 2394.log 2395.log
我们删除,然后自己创建,这时是regular file,而不是链接文件了:
/busybox# ls
2394.log 2395.log
/busybox# stat 2394.log
File: 2394.log
Size: 100 Blocks: 8 IO Block: 4096 regular file
Device: fc02h/64514d Inode: 529965 Links: 1
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-01-31 15:42:11.307170422 +0800
Modify: 2023-01-31 15:42:07.711225229 +0800
Change: 2023-01-31 15:42:07.711225229 +0800
Birth: -
/busybox# stat 2395.log
File: 2395.log
Size: 86 Blocks: 8 IO Block: 4096 regular file
Device: fc02h/64514d Inode: 529967 Links: 1
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-01-31 15:41:17.539989934 +0800
Modify: 2023-01-31 15:41:14.348038586 +0800
Change: 2023-01-31 15:41:14.352038525 +0800
Birth: -
/busybox# cat 2394.log
{
"log":"previous logs create by myself\n","stream":"stderr","time":"2022-11-05T08:11:27.31523845Z"}
/busybox# cat 2395.log
{
"log":"create by myself\n","stream":"stderr","time":"2022-11-05T08:11:27.31523845Z"}
ubuntu@10-234-32-51:~$ k logs busybox
create by myself
ubuntu@10-234-32-51:~$ k logs busybox --previous
previous logs create by myself
得出结论
kubelet读的是 /var/log/pods/ 下的日志文件,–previous 读的也是 /var/log/pods/ 下的日志文件,且专门有个链接文件来指向上一个退出容器的日志文件,以此来获取容器崩溃前的日志。
2.5 更新 kubectl set 命令
●更改现有应用资源一些信息。
kubectl set --help
//获取修改模板
kubectl set image --help
kubectl set image deployment myapp-test myapp=soscscs/myapp:v2
kubectl get pods -owide -w
kubectl describe deployments.apps
//处于动态监听 pod 状态,由于使用的是滚动更新方式,所以会先生成一个新的pod,然后删除一个旧的pod,往后依次类推
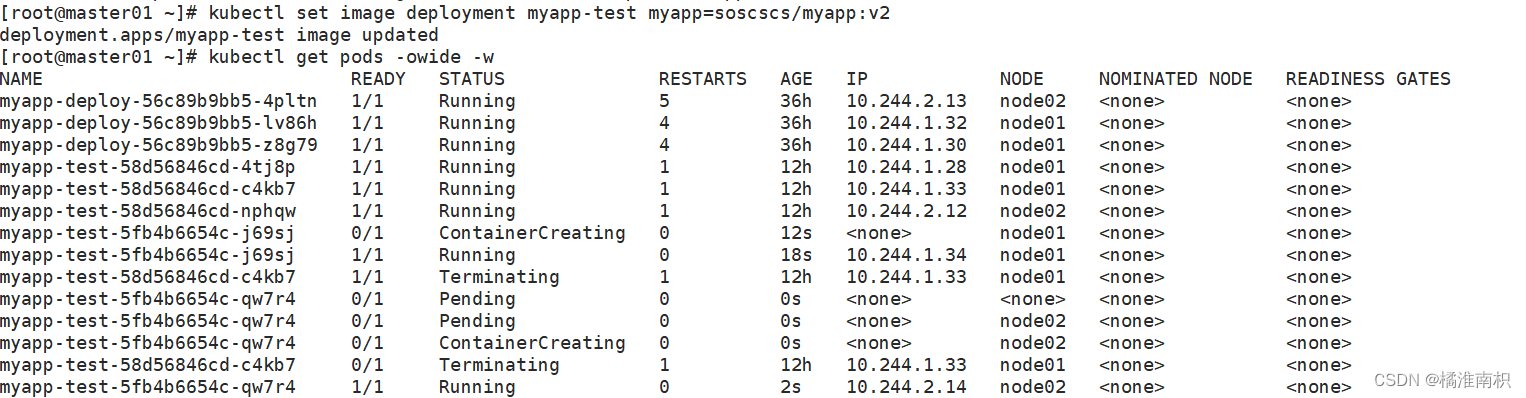

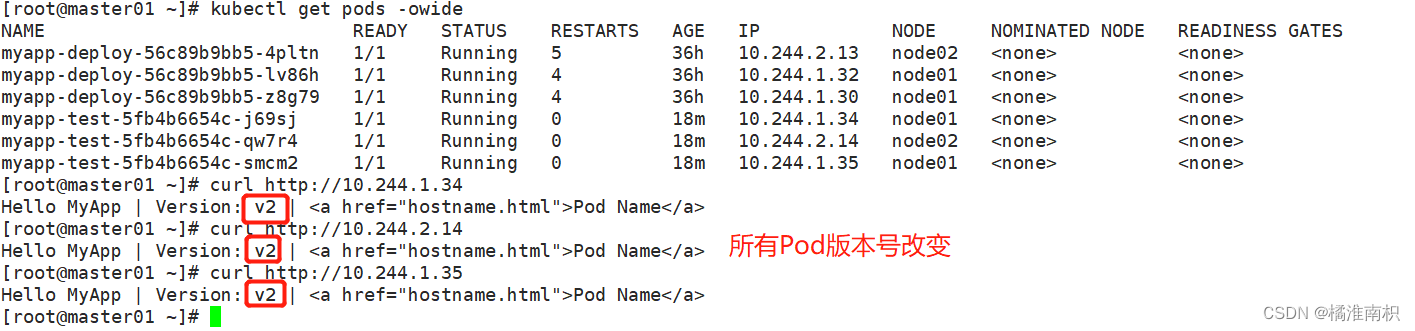
2.6 滚动更新详解
kubectl get all
DESIRED:表示期望的状态是 10 个 READY 的副本
CURRENT:表示当前副本的总数: 即8 个日副本 + 5 个新副本
UP_TO-DATE:表示当前已经完成更新的副本数: 即 5个新副本
AVAILABLE:表示当前处于 READY 状态的副本数: 即8个日副本。
kubectl describe deployment/nginx
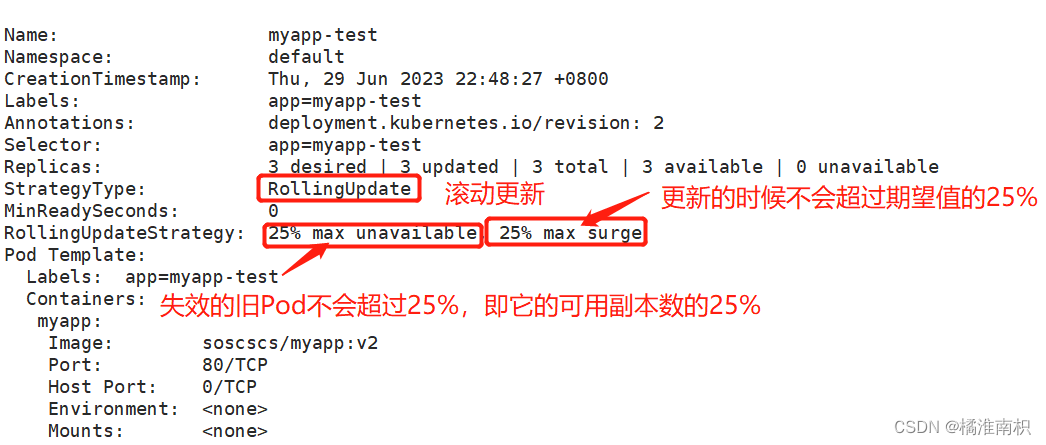
滚动更新通过参数 maxSurge 和 maxUnavailable 来控制副本替换的数量
maxSurge:此参数控制滚动更新过程中副本总数的超过 DESIRED 的上限。maxSurge 可以是具体的整数(比如 3),也可以是百分百,向上取整。maxSurge 默认值为 25%。
例如,DESIRED 为 10,那么副本总数的最大值为 10 + 10 * 25% = 13,即 CURRENT 为 13。
maxUnavailable:此参数控制滚动更新过程中,不可用的副本相占 DESIRED 的最大比例。maxUnavailable 可以是具体的整数(比如 3),也可以是百分百,向下取整。 maxUnavailable 默认值为 25%。
例如,DESIRED 为 10,那么可用的副本数至少要为 10 - 10 * 25% = 8,即 AVAILABLE 为 8。
因此 maxSurge 值越大,初始创建的新副本数量就越多;maxUnavailable 值越大,初始销毁的旧副本数量就越多。
理想情况下,DESIRED 为 10 的滚动更新的过程应该是这样的:
首先创建 3 个新副本使副本总数达到 13 个。
然后销毁 2 个旧副本使可用的副本数降到 8 个。
当这 2 个旧副本成功销毁后,可再创建 2 个新副本,使副本总数保持为 13 个。
当新副本通过 Readiness 探测后,会使可用副本数增加,超过 8。
进而可以继续销毁更多的旧副本,使可用副本数回到 8。
旧副本的销毁使副本总数低于 13,这样就允许创建更多的新副本。
这个过程会持续进行,最终所有的旧副本都会被新副本替换,滚动更新完成。
2.7 回滚 kubectl rollout
●对资源进行回滚管理
kubectl rollout --help
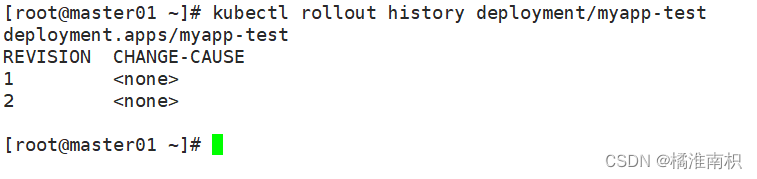
//查看历史版本
kubectl rollout history deployment/myapp-test
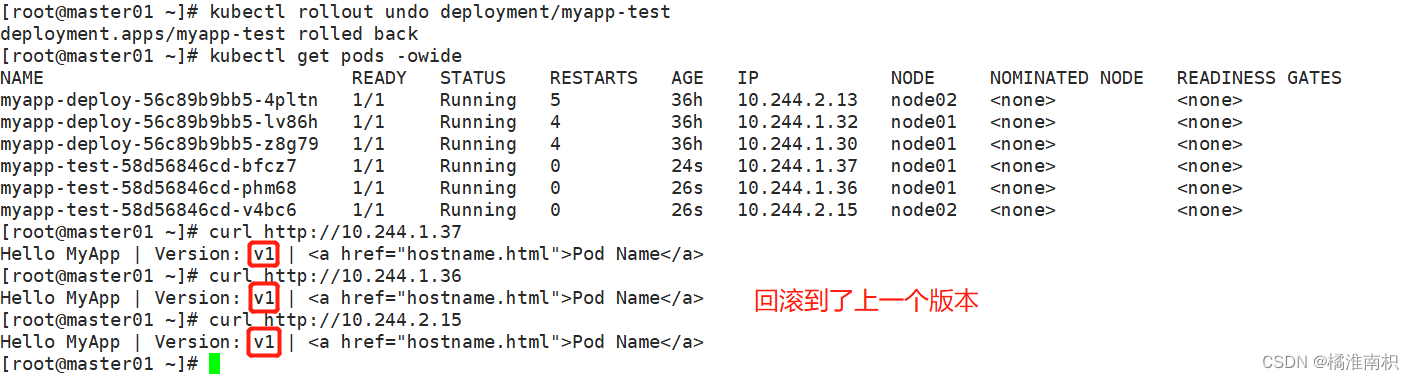
//执行回滚到上一个版本
kubectl rollout undo deployment/myapp-test
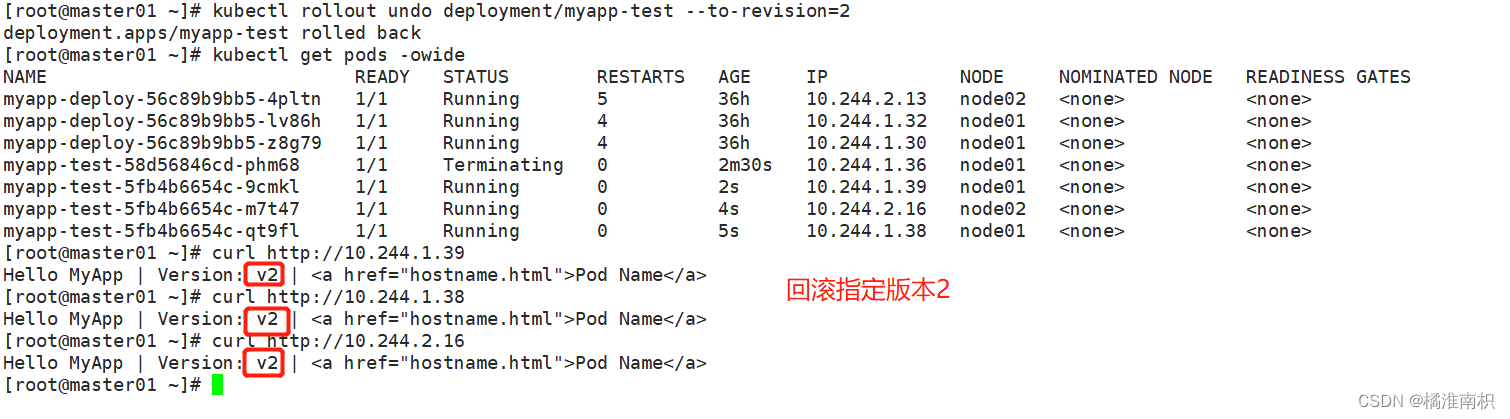
//执行回滚到指定版本
kubectl rollout undo deployment/myapp-test --to-revision=2
//检查回滚状态
kubectl rollout status deployment/myapp-test

2.8 删除 kubectl delete
//删除副本控制器
kubectl delete deployment/myapp-test

//删除service
kubectl delete svc/myapp-service
kubectl get all