VOGUE: Secure User Voice Authentication on Wearable Devices using Gyroscope
VOGUE:使用陀螺仪在可穿戴设备上进行安全用户语音认证
文章目录
2022 19th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON)
Abstract
语音助手在输入和输出能力有限的可穿戴设备中很受欢迎,但是容易受到语音攻击,这些攻击通过在用户不知情的情况下播放伪造的语音命令来欺骗语音助手。
在本文中,我们提出了VOGUE,它捕获了可穿戴设备中嵌入陀螺仪的扬声器的独特而稳定的语音移动序列模式,以区分注册的合法用户和恶意攻击者(人或机器)。
VOGUE的设计基于两个关键的观察。
- 首先,言语作为一种高度复杂的运动任务,本质上需要许多口面肌、喉肌、咽肌和呼吸肌的协调动作。
- 其次,为了生成某个单词,已知说话者的语音运动序列是独特的,并且可以被惯性传感器捕获。
我们在智能眼镜、智能手表、智能手机三种COTS android设备上实现了VOGUE,并对性能进行了综合评估。实验结果表明,即使在复杂的语音模仿攻击下,VOGUE的平均错误接受率(FAR)和错误拒绝率(FRR)分别为2.23%和2.48%。
关键字:语音认证,重放攻击,语音移动序列,陀螺仪,活性检测
对FAR, FRR的理解
错误拒绝率FRR:分类问题中,若两个样本为同类,却被系统误认为是异类,则为错误拒绝案例。(本该接受的没接受)错误拒绝率为错误拒绝比例在所有同类匹配案例中占的比例。
错误接收率FAR:分类问题中,若两个样本为异类,却被系统误认为同类,则为错误接受案例(即本不该接受的但接受了)。错误接受率为错误接受案例在所有异类匹配案例的比例。
等错误率(Equal Error Rate,EER):调整阈值,使得误拒绝率(False Rejection Rate,FRR)等于误接受率 (False Acceptance Rate,FAR),此时的FAR与FRR的值称为等错误率。
扫描二维码关注公众号,回复: 15503686 查看本文章
I. INTRODUCTION
相比于可穿戴设备(手表、眼镜、腕带等)的点击式交互方式,基于语音的交互(例如,Siri、Alexa、Cortana 和 Google Assistant 等语音助手应用程序)不需要用户键入命令并允许用户拨打电话、播放音乐和发送消息。
然而,基于语音交互,声音很容易被记录下来,被重放攻击。并且,目前的研究表明,通过只学习非常有限数量的受害者的声音样本,攻击者就能够建立一个非常接近的模型来代表受害者的声音。此外,这些伪造的语音命令可以在没有人注意的情况下注入声音通道[2]、[3],导致错误授权。
为了防御语音欺骗攻击,应用了活跃性检测来区分来自人类说话者的合法语音样本和来自机器的伪造语音样本。
VOGUE
本文提出了一种基于语音运动序列的活跃度检测方案Vogue。Vogue的核心思想是利用可穿戴设备中的内置陀螺仪,在用户说密码时捕捉用户特定的语音动作序列,并验证该序列的合法性。人与人之间的语音运动序列(即使是相同的密码短语)存在着不可忽视的差异。这种独特的特征可以被用来检测试图模仿真实用户的语音移动序列的攻击者。
VOGUE包含两个过程:离线用户注册和在线身份验证。
- 离线用户注册过程,在该过程中,用户多次说出预定的密码短语,并收集相应的语音运动序列并将其存储为模板。
- 在线身份验证过程,用户说一次注册的密码短语,并将相应的语音移动序列与这些模板进行比较。
VOGUE面临的三大挑战:
- 如何有效地感知语音引起的微动?通过分析常用内置传感器的感觉数据,发现语音运动往往具有较小的加速度,而身体部分的旋转相对较大,因此我们使用陀螺仪对语音运动序列进行采样。
- 如何选择能够表征说话人的运动特征?常用的统计特征不能很好地描述整个运动的细粒度趋势,而将整个运动序列送入分类器需要大量的训练样本。因此,我们选择表征注册模板和测试样本之间的相似性。将测试口令短语与top-k模板进行比较,以增强基于相似度的特征向量的稳健性。
- 在计算两个运动信号之间的相似度时,如何消除不同说话节奏所带来的影响?我们引入了语音感知 DTW (VA-DTW),其中我们根据时间对齐的麦克风信号扭曲陀螺仪信号。然后比较对齐的陀螺仪信号的相似度。我们观察到来自真实用户的语音运动序列在实现与模板序列的最佳匹配时应该具有较小的失真,因此定义了 Warping 分数来衡量语音运动序列与 VA-DTW 距离之间的相似性。
II. RELATED WORK
现有的检测语音欺骗攻击的工作可以分为两类:活性检测和信道特征检测。
A. Liveness Detection
活性检测系统区分人类说话者的合法语音样本和重放的语音样本。目前已经提出了三种活性检测方法:
- 基于面对人脸的检测方法:使用摄像机提取嘴唇运动 [4] 或检测可靠的面部 [5]。然而,人脸识别受光照限制,低端可穿戴设备可能不配备摄像头。缺点:首先,方案的有效性取决于照明条件。其次,他们需要访问设备的摄像头,这带来了安全风险。
- 基于超声波验证的方法:基于超声波的验证利用智能手机的内置扬声器传输高频声音,并在用户说出密码时收听麦克风反射的多普勒频移(由于发音姿势)[6] [7],智能手机必须放置在非常靠近扬声器的位置,并且恰好位于扬声器的正前方,这样超声波就会被咬合架反射,这使得在眼镜、项链和耳机等设备上使用检测不方便。缺点:扬声器需要将智能设备靠近嘴巴,并做出特定的姿势,才能清晰地捕捉反射信号。
- 基于振动的检测方法:冯等人依靠具有非常高采样率(11kHz)的振动传感器,该传感器被封装为可穿戴设备的硬件扩展。它被放置在演讲者的喉咙附近,以捕捉声带振动并将其与麦克风接收的语音信号进行匹配[8]。缺点:为了捕捉声带的振动,需要额外的传感器设备,并且应该放置在靠近扬声器喉部的地方。
B. Channel Characteristic Detection
基于信道特征的方案检测由高保真录音设备转录的数据与声音信道上的原始数据之间的差异。在UBM (通用背景模型)的基础上,利用语音数据的静音段对信道进行建模,判断待认证信道是否与训练语音的信道相同[ 12 ]。然而,静音段的幅度较小,比语音段更容易受到噪声污染,并且基于语音段的一般背景模型并不总是能够训练出准确的信道模型。
我们的VOGUE属于活体检测的范畴。与现有解决方案相比,VOGUE没有对可穿戴设备的放置进行任何限制,也不需要额外的硬件,也不存在潜在的隐私风险。
III. PRELIMINARIES
A. System and Attack Model
说话人在注册时被要求说出预先确定的密码短语,将来将使用相同的短语进行验证。VOGUE可以应用于各种COTS可穿戴设备,该设备应被由用户佩带。
攻击者可以发起重放攻击(即预先记录受害者的声音并重新播放),也可以发起语音模仿攻击(即将合成或模仿的密码短语注入音频通道)。此外,我们假设攻击者可以获得受害者的设备,并知道VOGUE的详细设计。我们特别考虑以下两种类型的攻击场景:
- 场景A:零知识冒充攻击。当重播(或广播)密码时,攻击者佩戴目标设备并同时说出密码(但不能发出声音),以产生相应的身体动作。(身体模仿)
- 场景B:窥探和冒充攻击。窥探攻击与零知识攻击具有相同的过程,不同之处在于攻击者首先了解其受害者如何发音密码,例如通过拍摄受害者的视频,然后在发动攻击之前进行排练。
B. Speech Movement Sequence
语音运动序列是指由说话引起的一系列复杂的身体运动,包括:
- 与语音有关的100多块肌肉的即时同步运动,包括横隔肌、胸大肌、脑肌、颊肌、颈阔肌等;
- 其他远端肌肉和身体部分的牵引力引起的运动(位移),其原因是肌肉纤维相互粘连,人体骨骼是交叉连接的。
C. Capturing Diversity of Speech Movement Sequence
考虑到语音运动序列隐含着肌肉的收缩和身体部分的位移,我们认为使用运动传感器捕获语音运动序列是可能的。因此,我们使用广泛安装在可穿戴设备上的加速计和陀螺仪来测量扬声器的身体运动。我们发现,首先,陀螺仪比加速度计更灵敏,这与语音运动往往有小的加速度,而身体部分的旋转相对较大的直觉是一致的。
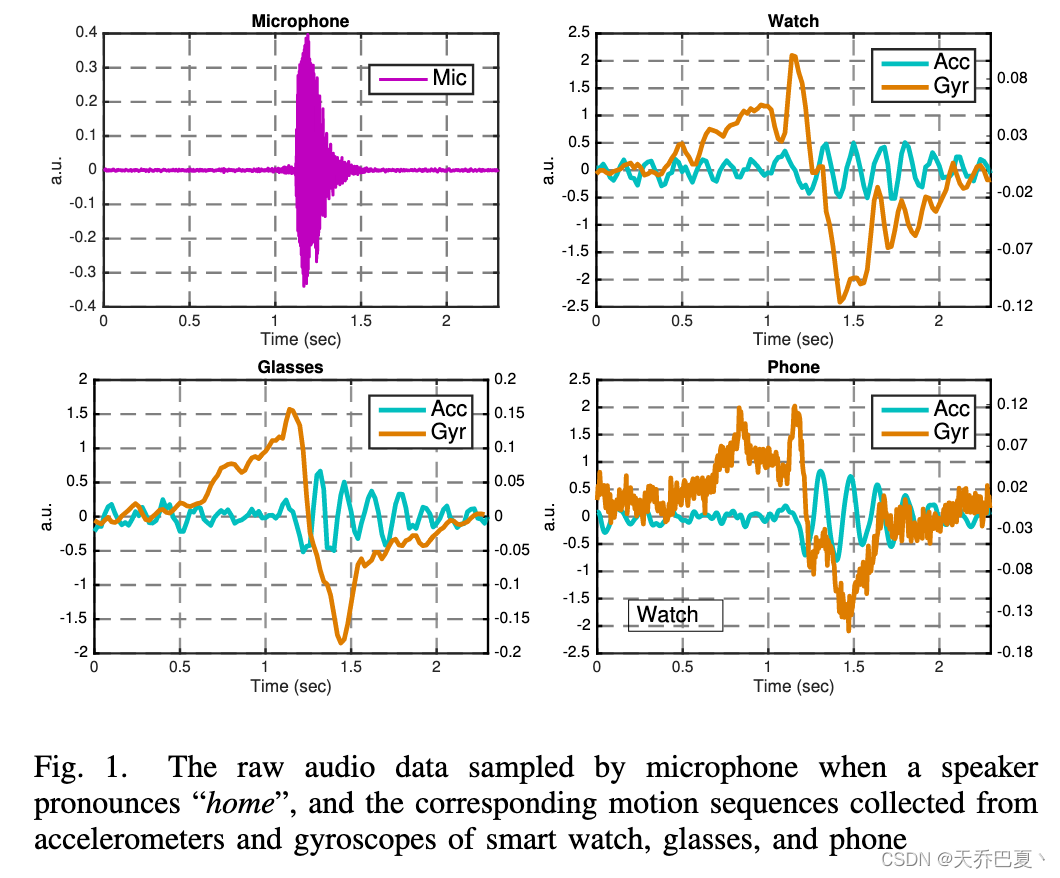
可以看出,说话对陀螺仪数据的波动比对加速度计数据的波动大得多,即使是位于身体远处的设备,即手和手腕,也可以感知到语音引起的微小运动。
此外,由于肌肉、骨骼和关节的大小、形状、强度以及肌肉施力方式的个体差异,我们认为,为了产生特定的口令,说话人相应的语音运动序列将显示出独特的、可重复的时空特征。图2显示了两名志愿者A(左)和B(右)在两次读"America"时采样的智能手表的陀螺仪数据的时间序列。
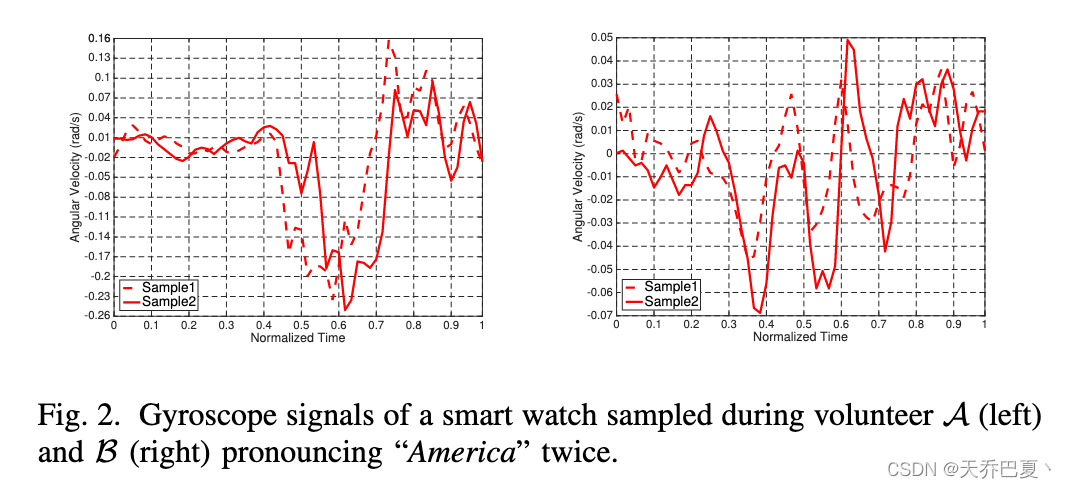
可以看出,来自同一说话人的两个样本具有很高的相似性,而来自不同说话人的样本之间存在明显的差异。
IV. DESIGN OF VOGUE
A. Overview
VOGUE:当用户对设备说出密码时,其声音和身体动作将同时被麦克风和陀螺仪记录下来。一旦麦克风信号通过语音认证,陀螺仪数据将被VOGUE进一步验证。
VOGUE分为线下训练和线上认证两个阶段。
- 在训练阶段,用户多次说出口令,以收集语音和运动信号的模板,用于构建分类器。
- 在身份验证阶段,将测试输入与这些模板进行比较,以确定它是否来自注册用户。
原始模板不适合训练分类器,原因有两个。
- 首先,说话者可能会以不同的速度读出相同的密码短语,这意味着这些模板的长度不同。
- 其次,模板中的数据点数量很大,特别是对于较长的密码短语。这意味着需要大量的训练模板来保证较高的准确率,这增加了用户的注册负担。
一个合理的选择是从原始信号中提取有效的特征来形成特征向量,但这并不简单。时间序列中常用的统计特征,如最大值和最小值、标准差及其组合,其表现都不尽如人意。**由于分类的基本因素是陀螺仪数据时间序列的变化趋势而不是其分布,而不能用统计特征来表示。**换句话说,原因是特征应该出现在数据序列的预期位置上。
例如图3显示了眼镜的两段陀螺仪数据,分别属于不同发“do”的说话人。我们可以看到这两个段的形状不同。但是,它们的最大值、最小值和标准差非常相似。
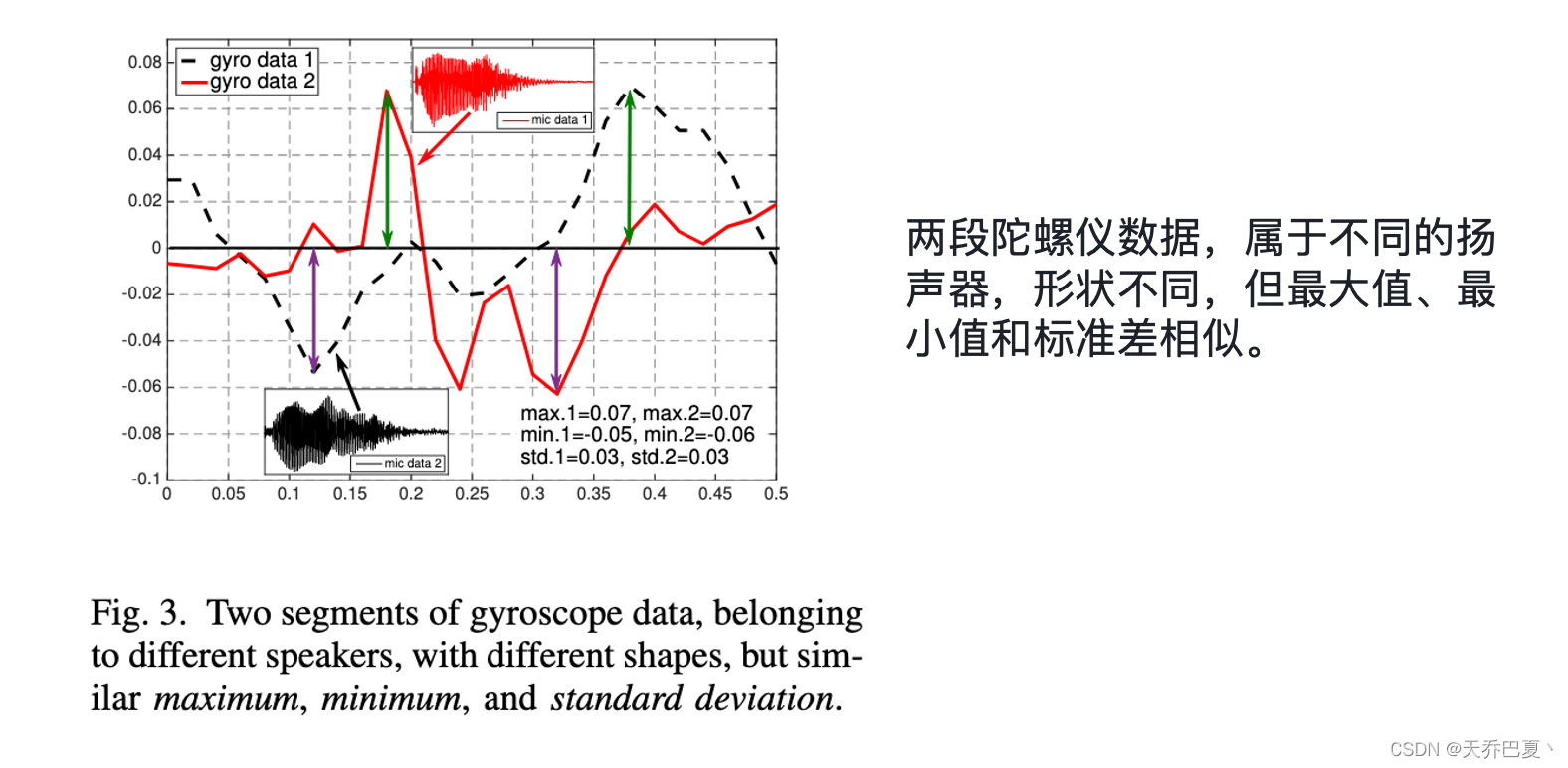
我们提出了一种语音感知DTW(VA-DTW)算法来实现两个语音对齐的运动序列之间的形状匹配。如果两个语音命令是由同一个人发出的,则两个相应的运动序列将具有较小的VA-DTW距离以及较短的warping路径。我们对语音运动序列对进行VA-DTW来提取距离向量。同时利用VA-DTW距离和warping评分对分类器进行训练。
- DTW(动态时间规整)算法原理与应用:按照距离最近原则, 构建两个序列元素之间的对应关系,评估两个序列的相似性。

B. Data Collection
收集下面两组数据:
Trace A:收集30天。一般而言,每个志愿者在不同的演讲量和语速下,每天都会对选定的每一条指令进行10次演讲。具体来说,每个命令在一个正常的发音量中发音6次,在常规、慢速和快速的节奏中分别发音2次,在较高和较低的音量中分别发音2次。为了考察VOGUE是否受到身体姿势的影响,我们要求志愿者分别在第1、第2和最后10天完成站立、坐直和驼峰的数据采集。这样,对于每个指令,我们收集了300个麦克风信号,以及相应的陀螺仪信号。此外,我们使用摄像机记录数据收集的过程,这些数据将用于发起模拟攻击。
Trace B:是关于冒充攻击的。我们选择五名志愿者作为受害者,其他人作为攻击者。首先,每个攻击者针对受害者的每个命令发起十次零知识模拟攻击(见场景A)。之后,攻击者任意观看记录受害者说话方式的视频,然后对受害者的每个命令说10次,尽量模仿受害者说话的方式(即场景B)。这样,对于两种类型的模拟攻击,受害者的每个命令都会被攻击 100 次。
C. Pre-processing
假设我们从麦克风和陀螺仪采集到一对时序序列,即采样的语音命令和语音运动在时间上同步。我们执行以下两步预处理。
- 去除不发声片段:因为我们只关心与语音相关的动作,我们使用静音去除[14]来去除音频信号中的不发声片段。在此之后,语音命令V可能被切割成若干段以及相应的陀螺仪信号G,从而获得若干对麦克风和陀螺仪数据段,每个数据段都用Si = (Vi, Gi), i小于1表示,其中Vi和Gi分别表示音频和运动段。
- 归一化:直观地说,声音的响度与语音运动的强度密切相关,因此与陀螺仪信号的振幅密切相关。为了消除说话音量对陀螺仪信号的影响,我们对每个陀螺仪信号段Gi的振幅进行归一化处理。
D. Voice Aware DTW based Similarity
DTW距离不足以区分两段陀螺仪信号是否来自同一个人。图4分别描绘了来自相同和不同人的两段陀螺仪信号(相同的语音命令)之间的DTW距离的CDF曲线(实线)。
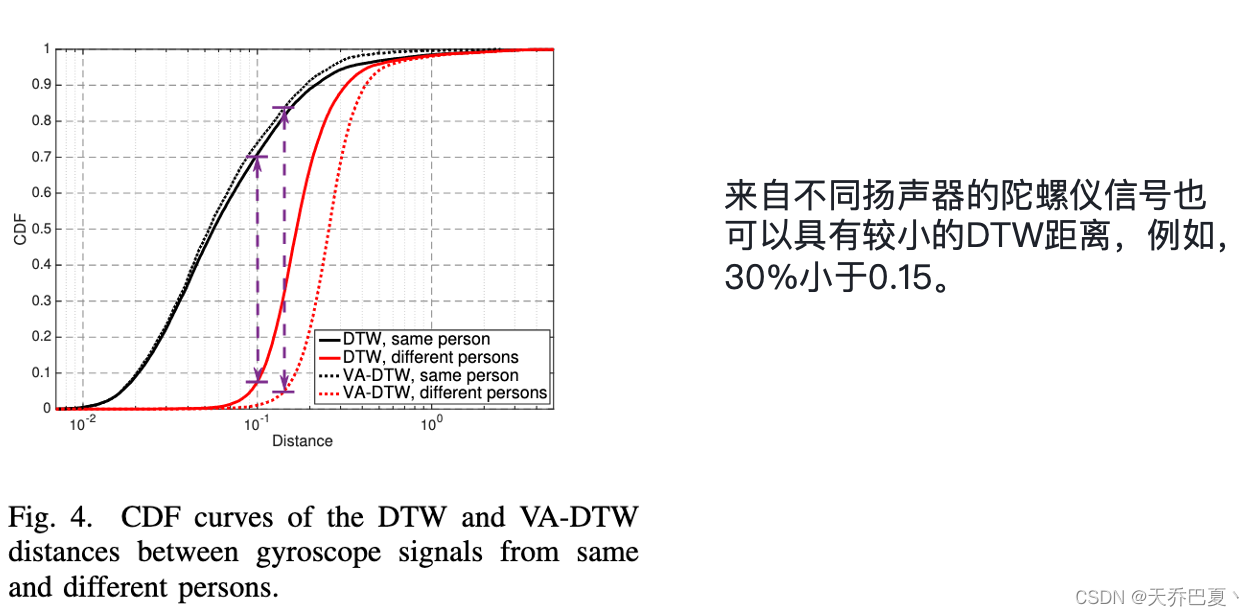
任意的扭曲的陀螺仪可能会导致属于不同音素的片段被匹配,这会导致 DTW 距离较小(巧合)但warping路径很长。
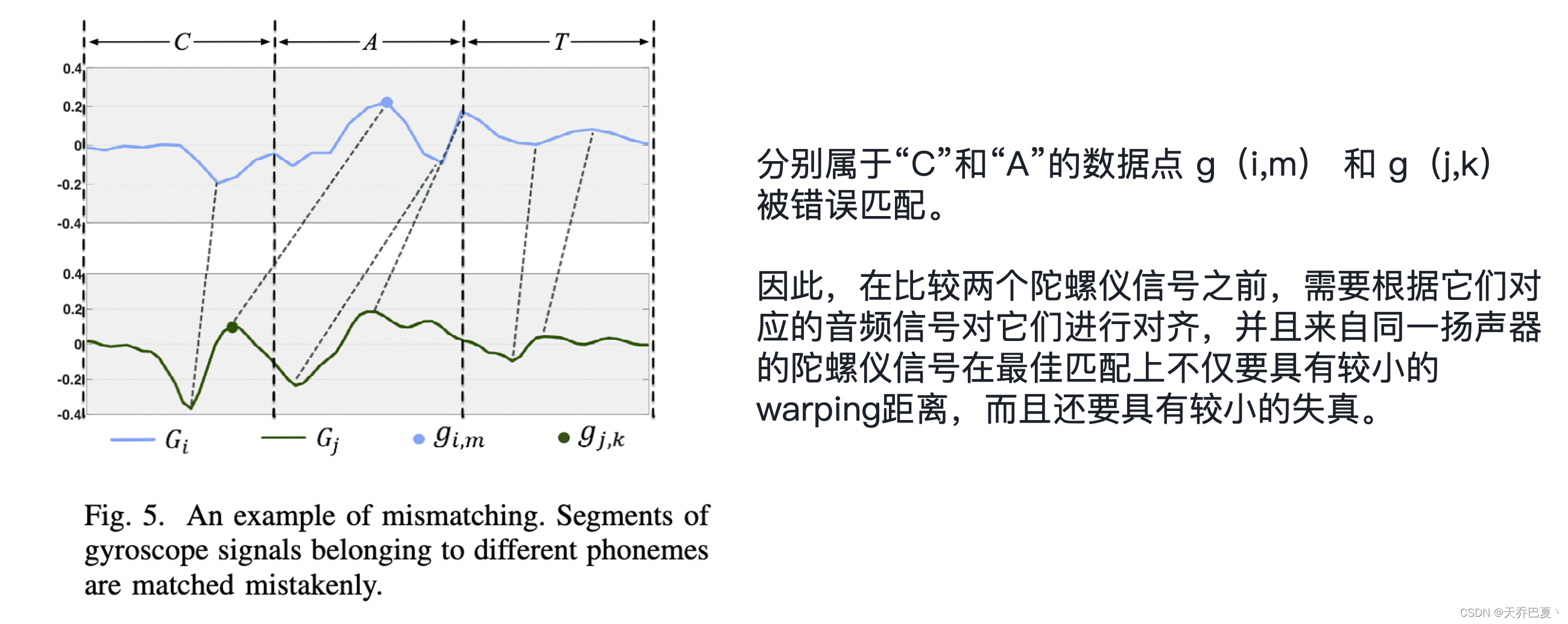
我们引入 VA-DTW 距离来消除比较陀螺仪信号时的这种不匹配。
- 一般来说,给定 Si 和 Sj ,我们对其麦克风信号V进行 DTW,并记录相应的 warping 函数,并将其应用于相应的陀螺仪信号G,获得语音对齐的陀螺仪信号。
- 然后,我们计算它们之间的 DTW 距离作为它们的 VA-DTW 距离,以及相应的 warping 分数,形成距离的二元组,它表征陀螺仪信号之间的相似性,并作为后续分类器的输入。
具体而言,应执行以下程序:
-
音频信号的下采样:由于麦克风的采样率远大于陀螺仪的采样率,这意味着 Vi 和 Vj 之间的 warping 函数不能直接应用于陀螺仪信号,我们在进行 DTW 之前对麦克风信号进行下采样,这也减少了计算量DTW 的成本。一种简单的下采样方法是通过整数因子 D 抽取原始麦克风信号;也就是说,只保留每第 D 个样本。但是麦克风的采样率是陀螺仪的882(即44100/50)倍,这样的稀疏重采样很容易漏掉原始信号的峰值,导致重采样信号与原信号不相似的趋势原来的。相反,我们找到 Vi 的包络,然后用 D=882 抽取上部包络以获得下采样音频序列。包络是使用样条插值法在局部最大值上确定的,该最大值由至少 σ(我们根据经验将 σ 设置为 1500)个样本分开。
-
翘曲陀螺仪信号:给定 V i V_i Vi 和 V j V_j Vj 的下采样信号,记为 A = { a 1 , ⋅ ⋅ ⋅ , a I a_1, · · · , a_I a1,⋅⋅⋅,aI } 和 B = { b 1 , ⋅ ⋅ ⋅ , b J b_1, · · · , b_J b1,⋅⋅⋅,bJ},我们对它们进行 DTW。为了让A和B对齐,我们构建了一个 I × J I × J I×J 矩阵 M,其中 M 中的 ( i t h , j t h i^{th}, j^{th} ith,jth) 元素定义为 d ( i , j ) = ( a i − b j ) 2 d(i, j) = (a_i − b_j )^2 d(i,j)=(ai−bj)2,表示 a i a_i ai和 b j b_j bj对齐。
在计算 A 和 B 之间的 DTW 距离时,我们同时得到相应的 warping 路径 W = w 1 , … , w l , … , w L , ( w l = ( i , j ) l , m a x ( I , J ) ≤ L ≤ I + J − 1 ) W = w_1,…, w_l,…, w_L, (w_l = (i, j)_l, max(I, J) ≤ L ≤ I +J −1) W=w1,…,wl,…,wL,(wl=(i,j)l,max(I,J)≤L≤I+J−1), 其中 1 L ∑ l = 1 L d ( w l ) \frac{1}{L} \sqrt{ \sum_{l=1}^L d(w_l)\ } L1∑l=1Ld(wl) 达到最小值。这意味着当 A 等于 B 时,最短翘曲路径与矩阵的对角线 j = i j = i j=i重合,长路径意味着严重翘曲。
然后,我们根据 W 拉伸 G A = g 1 ( A ) , ⋅ ⋅ ⋅ , g I ( A ) G_A = {g^{(A)}_ 1 , · · · , g^{(A)}_I } GA=g1(A),⋅⋅⋅,gI(A)和 G B = g 1 ( B ) , ⋅ ⋅ ⋅ , g J ( B ) G_B ={g^{(B)} _1 , · · · , g^{(B)}_J } GB=g1(B),⋅⋅⋅,gJ(B),得到拉伸陀螺仪信号 G A ′ = g ( i 1 ) ( A ) , ⋅ ⋅ ⋅ , g ( i l ) ( A ) , ⋅ ⋅ ⋅ , g ( i L ) ( A ) G^′_A = {g^{(A) }_{(i_1)}, · · · , g^{(A) }_{(i_l)} , · · · , g^{(A) }_{(i_L)}} GA′=g(i1)(A),⋅⋅⋅,g(il)(A),⋅⋅⋅,g(iL)(A)和 G B ′ = g ( j 1 ) ( B ) , ⋅ ⋅ ⋅ , g ( j l ) ( B ) , ⋅ ⋅ ⋅ , g ( j L ) ( B ) G^′_B = {g^{(B) }_{(j_1)}, · · · , g^{(B) }_{(j_l)} , · · · , g^{(B) }_{(j_L)}} GB′=g(j1)(B),⋅⋅⋅,g(jl)(B),⋅⋅⋅,g(jL)(B), 其中 i l i_l il和 j l j_l jl指的是 w l w_l wl中i和j的值。请注意, G A ′ G'_A GA′和 G B ′ G'_B GB′的长度分别等于 A 和 B 的长度。
-
测量VA-DTW距离和Warping 分数:得到 G i ′ G ' _i Gi′和 G j ′ G ' _j Gj′后,计算两者之间的DTW距离,记为 C ( G i ′ , G j ′ ) C(G '_ i, G '_j) C(Gi′,Gj′),即 G i G_i Gi和 G j G_j Gj的VA-DTW距离。
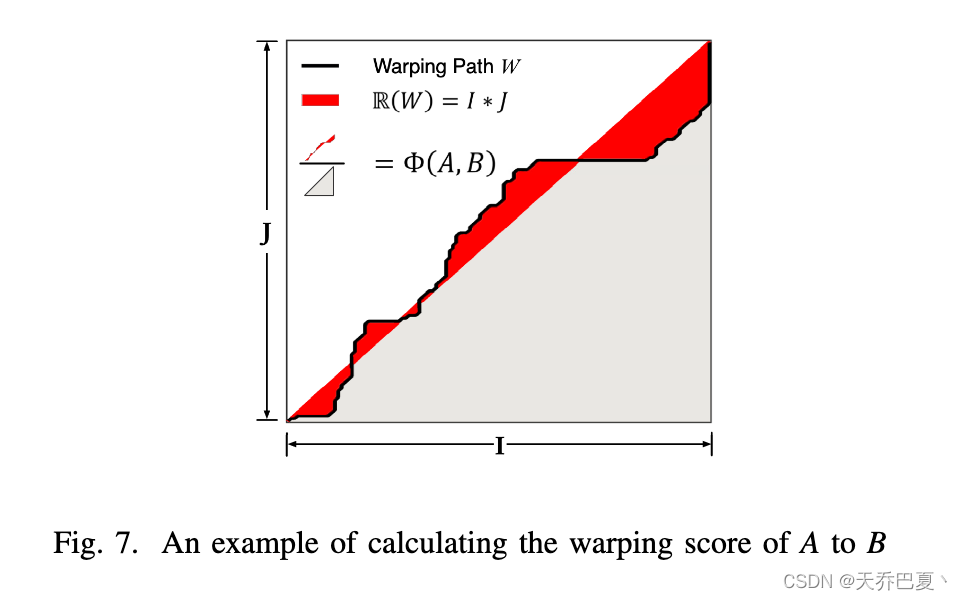
给定两个长度相同的序列A和B,即A = a 1 , a 2 , … , a i , … , a I a_1, a_2,…, a_i,…, a_I a1,a2,…,ai,…,aI, B = b 1 , b 2 , … , b j , … , b J b_1, b_2,…, b_j,…, b_J b1,b2,…,bj,…,bJ,其中 I = J I = J I=J,矩阵M与翘曲路径W以对角线j = i所围成的面积,记为R(W),可计算为
R ( W ) = ∑ l = 1 L ∣ ( i l + 1 − i l ) [ j l + j l + 1 − J I ( i l + i l + 1 − 2 ) − 2 ] 2 ∣ R(W) =\sum_{l=1}^L |\frac{(i_{l+1} −i_l )[j_l +j_{l+1} − \frac{J}{ I} (i_l +i_{l+1}−2)−2]}{2}|\ R(W)=l=1∑L∣2(il+1−il)[jl+jl+1−IJ(il+il+1−2)−2]∣
我们定义A到B得warping 分数为:
Φ ( A , B ) = 2 R W I 2 Φ(A, B) = \frac{2RW}{I^2} Φ(A,B)=I22RW
如图7所示, Φ ( A , B ) Φ(A, B) Φ(A,B)的值在0到1之间。现在,我们计算 G i ′ G '_i Gi′到 G j ′ G '_j Gj′的扭曲分数,即 Φ ( G i ′ , G j ′ ) Φ(G '_i, G '_j) Φ(Gi′,Gj′),并形成一个距离元组,即 ( C ( G i ′ , G j ′ ) , Φ ( G i ′ , G j ′ ) ) (C(G '_i, G '_j), Φ(G '_i, G '_j)) (C(Gi′,Gj′),Φ(Gi′,Gj′))。
E. Classification
在离线训练阶段,将收集到的所有训练模板(每个模板是一对语音和动作信号)进行比较。假设需要比较两对传声器和陀螺仪数据信号 S i S_i Si和 S j S_j Sj。首先,根据IV-C将它们分割成两个信号序列,即 S i 1 , … , S i n S_{i_1},…, S_{i_n} Si1,…,Sin,和 S j 1 , … , S j n S_{j_1},…, S_{j_n} Sj1,…,Sjn。然后构造它们之间的距离向量 D i , j D_{i,j} Di,j,即 C ( G i 1 ′ , G j 1 ′ ) , Φ ( G i 1 ′ , G j 1 ′ ) , … , C ( G i n ′ , G j n ′ ) , Φ ( G i n ′ , G j n ′ ) C(G '_{i_1}, G '_{j_1}), Φ(G '_{i_1}, G '_{j_1}),…, C(G '_{i_n}, G '_{j_n}), Φ(G '_{i_n}, G '_{j_n}) C(Gi1′,Gj1′),Φ(Gi1′,Gj1′),…,C(Gin′,Gjn′),Φ(Gin′,Gjn′)通过比较模板得到的所有距离向量将被输入到一类分类器中,例如KNN或SVM。
此外,我们引入了一个步骤来识别top-K训练模板。给定N个训练模板,我们首先确定最接近所有训练样本的k个模板。对于每个模板,我们计算其与其他模板的VA-DTW距离,然后选择平均距离最小的K个模板。
在在线认证中,关注top - K模板而不是全部模板带来了减少计算开销、增强对训练模板中噪声的鲁棒性等优点。在在线认证过程中,测试样本 S i S_i Si将通过检查其到top- k模板的距离向量来接受或拒绝。具体来说,我们将 S i S_i Si与top-K模板进行比较,得到K个距离向量,即 D i , k ( 1 ≤ k ≤ K ) D_{i, k}(1≤k≤K) Di,k(1≤k≤K),然后计算这些向量的中心,即 D i ‾ = 1 K ∑ k = 1 K D i , k \overline{D_i}=\frac{1}{K}\sum_{k=1}^K D_{i, k} Di=K1∑k=1KDi,k。最后将 D i ‾ \overline{D_i} Di输入到分类器进行判断。
V. EVALUATION
我们根据第IV-B小节中描述的trace对VOGUE进行全面评估。陀螺仪和麦克风的数据都被传输到PC机上进行离线分析。我们采用FAR和FRR作为评价标准。
- FAR被定义为错误接受的非法输入数量与所有非法测试输入数量之间的比率。
- FRR定义为错误拒绝的合法输入数量与所有合法测试输入数量的比值。
- 接收者工作特征(ROC)曲线说明了二元分类器的诊断能力,因为它的区分阈值是不同的。
- 我们从ROC曲线中获得相等错误率(EER),其中FAR和FRR相等。
除了模拟攻击(在V-E中)使用Trace B外,我们在大多数实验中都使用Trace A。
A. Effectiveness of σ
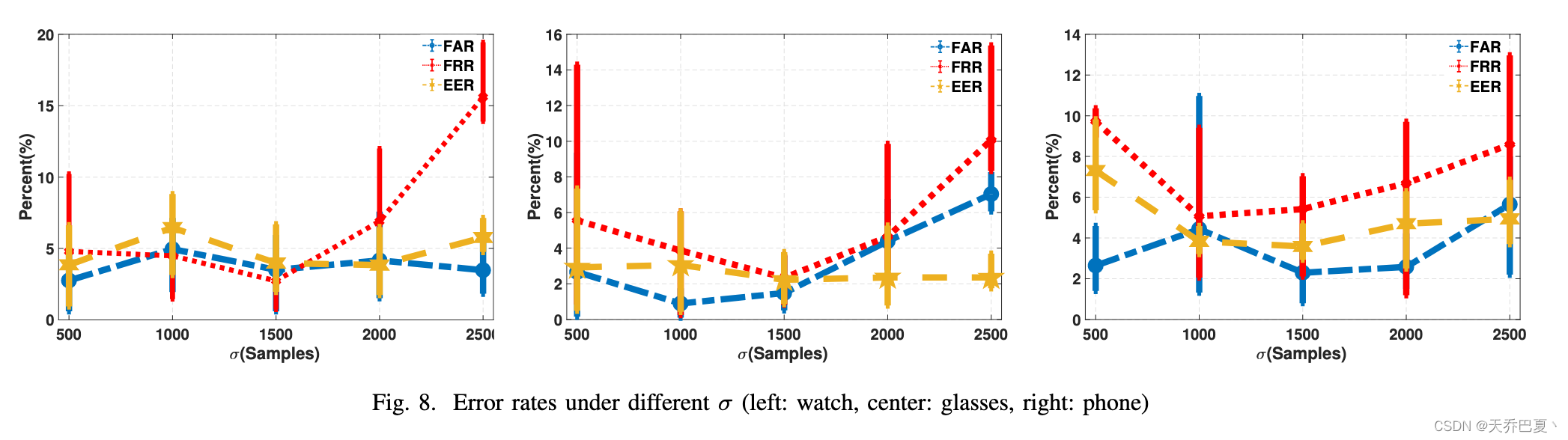
图 8 绘制了在不同设备上作为 σ 函数的所有志愿者的 FRR、FAR 和 EER 的平均值、最大值和最小值。我们在这个实验中使用三词命令,σ 的值从 500 增加到 2500,间隔为 500。我们将 K 设置为 4,并使用单类 SVM 分类器。可以看出,当 σ =1500 时,所有器件均达到最佳性能。通过分析结果包络,我们发现这是因为小的σ使得结果包络包含很多不必要的细节,而大的σ会导致包络上的大失真,这两者都会导致原始信号和下采样信号之间的巨大差异。因此,我们在以下实验中将 σ 设置为 1500。
B. Effectiveness of T
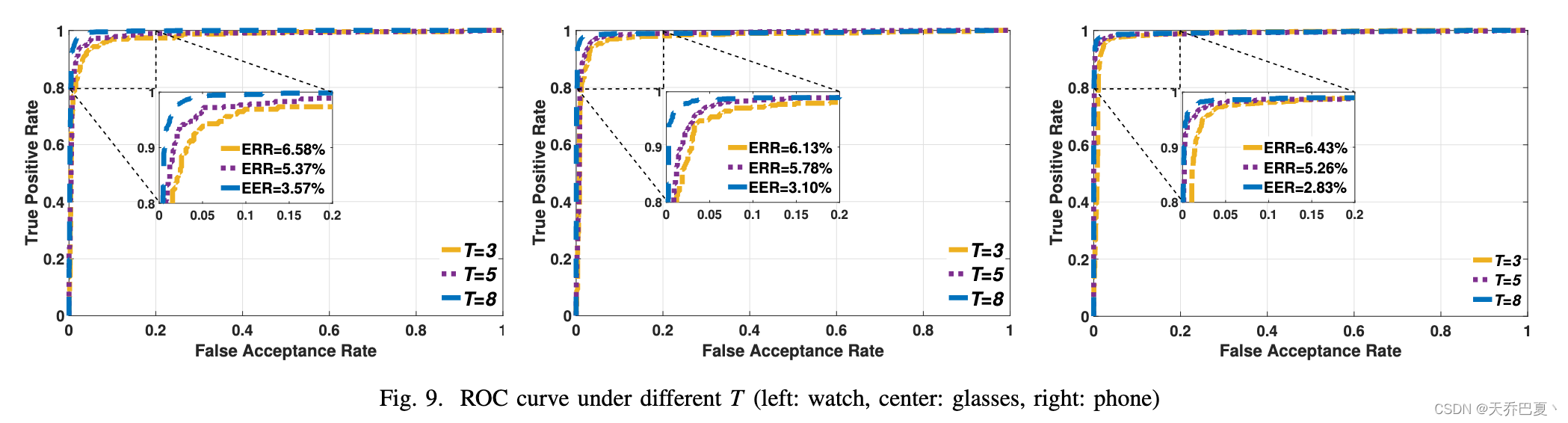
我们检查了不同训练数据大小下的 VOGUE 性能,即 T = 3、5 和 8。我们将 K 设置为 4,并使用单类 SVM 分类器并将区分阈值从 0.0 增加到 1.0,间隔为 0.01,并绘制ROC 曲线,如图 9 所示。我们观察到,在所有三个设备上,随着 T 的增加,平均 EER 逐渐下降。当 T = 8 时,VOGUE 表现最佳。T 的值对在线认证阶段的计算开销没有影响,因为测试样本只会与 Top-K 模板进行比较。因此,在接下来的研究中,我们使用八个训练样本。
C. Effectiveness of K
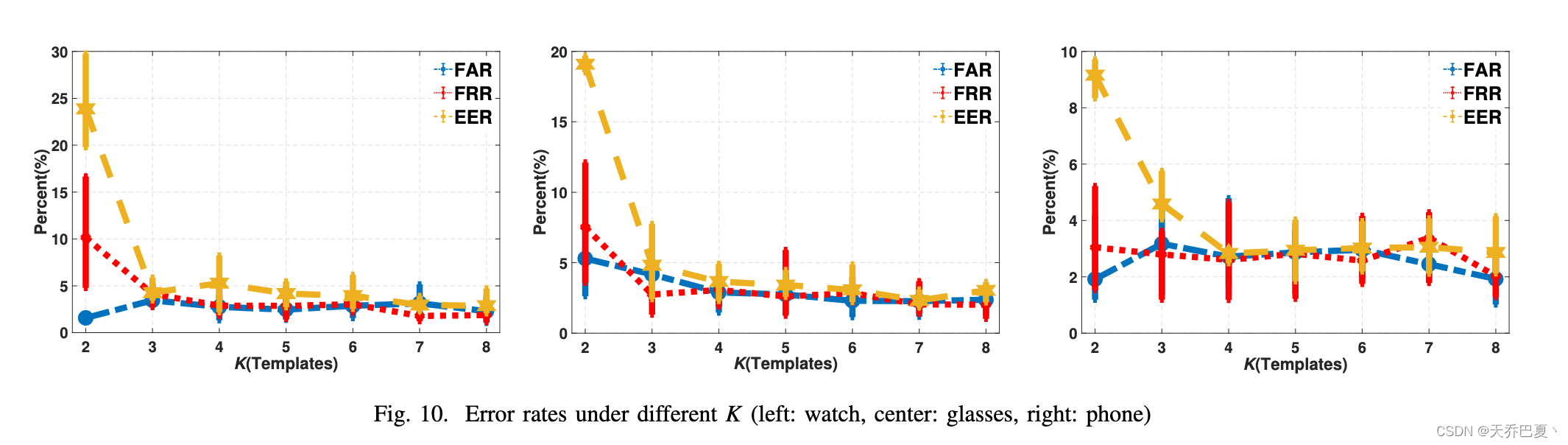
图 10 分别在三个设备上绘制了所有志愿者的 FRR、FAR 和 EER 的平均值、最大值和最小值作为 K 的函数。我们在这个实验中使用三个单词的命令。 K 的值以 1 的间隔从 2 增加到 8。我们有两个观察结果。首先,当 K 从 2 增加到 4 时,三种类型的错误都显着下降,然后随着 K 不断增加到 8 而逐渐下降。其次,即使是很小的 K(例如 3),也可以在所有设备上实现相当不错的性能。在线认证时,测试样本将与Top-K模板进行比对。大 K 意味着高计算成本和长身份验证延迟。因此,我们在研究的其余部分将 K 设置为 3,这在性能和成本之间实现了最佳折衷。
D. Effect of Classifier
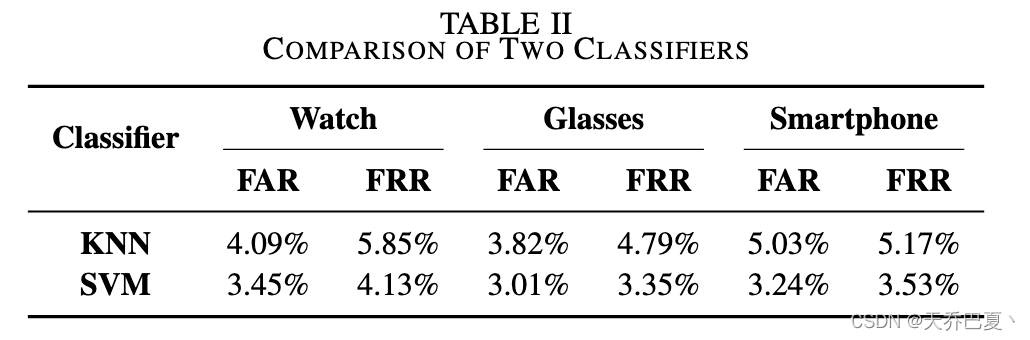
我们比较了两个单类分类器的性能,即 KNN [15] 和 SVM [16]。为了选择 KNN 分类器的参数 κ,进行了 κ 范围从 1 到 10 的多次测试。选择最佳参数 κ = 3。对于 SVM 分类器,我们使用径向基函数 (RBF) 作为核函数。为了获得 c 和 g 的适当参数,我们在 [2−4,24] 的相同范围内进行网格搜索,并对训练组进行交叉验证。实验结果如表二所示。可以看出,两种分类器都能取得令人满意的性能,SVM分类器略优于KNN。但是,考虑到随着训练数据量的增加,KNN 的预测效率会降低,我们在接下来的实验中使用 SVM 分类器。
E. Defending against Impersonation Attacks
我们使用 Trace B 根据第 III-A 节中提出的威胁模型检查 VOGUE 的安全性。
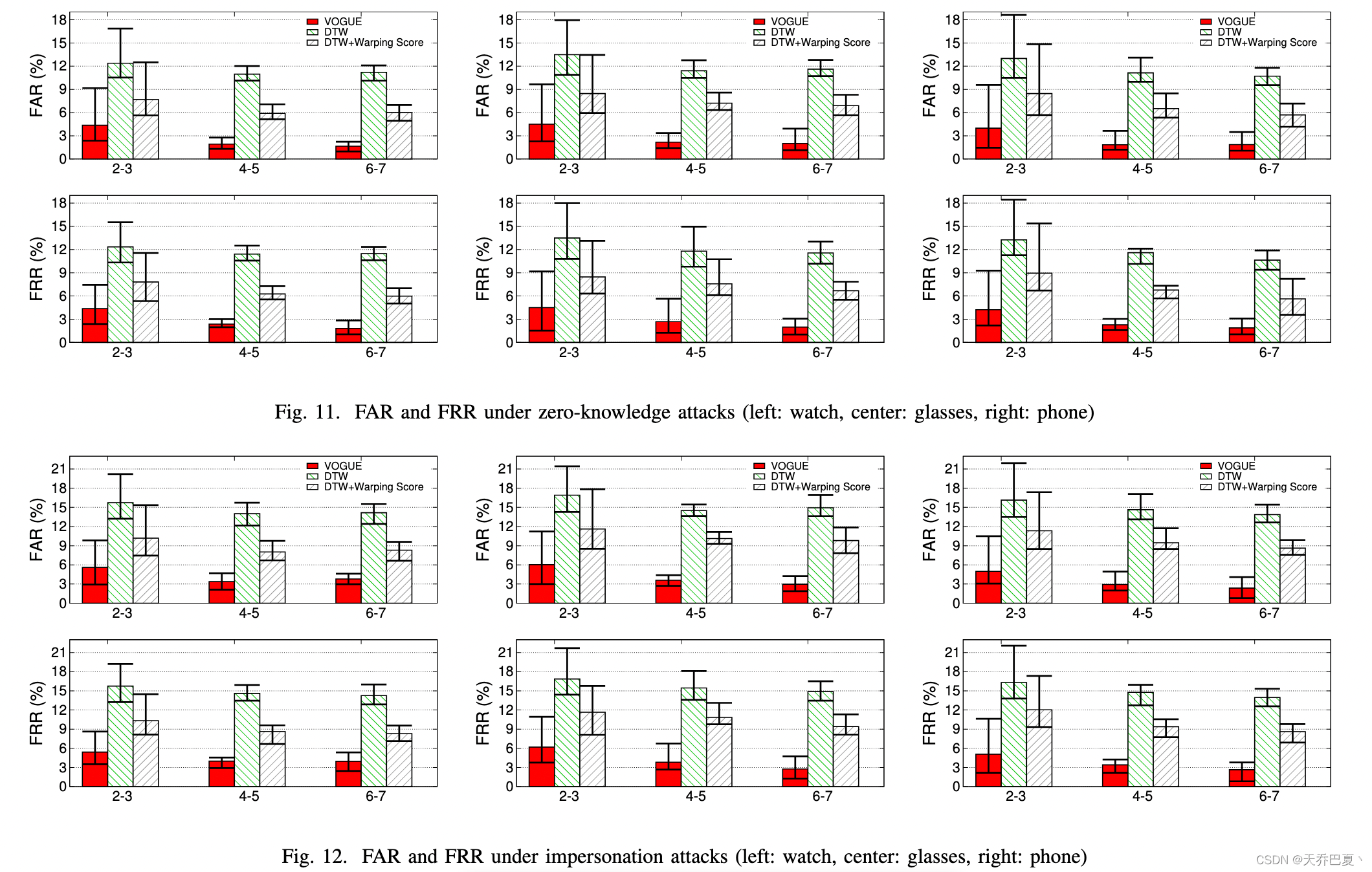
- 零知识冒充攻击:图 11 说明了 VOGUE 对一般零知识攻击的弹性。可以看出,与正常使用场景相比,VOGUE 的 FARs 和 FRRs 对于短命令(2-5 个词)仅略有增加(约 1%),而对于 6-7 个词的命令几乎没有变化,但是两者在所有情况下,使用或不使用基于翘曲分数的方案的 DTW 错误都会显着增加。
- 窥探和模仿攻击:图 12 表明,尽管进一步增加,但 VOGUE 的错误不超过 6% 和 3%,对于 2-3 和分别为 4-7 个单词的命令,并且在所有情况下它都比其他两种方法更能抵抗假冒攻击。例如,对于4到7个单词的命令,VOGUE的平均FARs增加量在1%左右,而其他两种方法分别超过7%和5%。
VI. CONCLUSION
在本文中,我们开发了一种用于语音认证的欺骗检测系统 VOGUE,它利用可穿戴设备的内置陀螺仪来捕获说话者的语音运动序列。 VOGUE实用性强,不需要额外的硬件和繁琐的操作,适用于不同位置佩戴的可穿戴设备。广泛的实验证明了它的有效性和稳健性。
尽管如此,VOGUE 也有一些局限性。例如,在现阶段,VOGUE只能在说话人静止时使用,否则FRR可能会很高。这也为我们今后的工作指明了方向。未来我们将通过独立分量分析来消除扬声器运动状态的影响。此外,我们将在更多类型的可穿戴设备和大量用户上评估VOGUE,这是一个成熟的解决方案所必需的。