作者:Sean Heelan

在这篇文章中,我将介绍 sysgrok,这是一个研究原型,我们正在研究大型语言模型 (LLM)(例如 OpenAI 的 GPT 模型)如何应用于性能优化、根本原因分析和系统工程领域的问题。 你可以在 GitHub 上找到它。
Sysgrok 是做什么的?
sysgrok 可以执行以下操作:
- 采用分析器识别出最昂贵的函数和进程,解释每个函数和进程提供的功能,并提出优化建议
- 获取主机和主机遇到的问题的描述,自动调试问题并建议补救措施和进一步的操作
- 获取已由探查器注释的源代码,解释热路径,并提出提高代码性能的方法
Sysgrok 的功能针对三大类解决方案:
- 作为性能、可靠性和其他系统相关数据的分析引擎。 在这种模式下,LLM (Large Language Model)会收到工程师使用的其他一些工具(例如 Linux 命令行工具、分析器或可观察性平台)的输出。 Sysgrok 的目标是使用 LLM 解释、总结并形成有关系统状态的假设。 然后,它还可能建议优化或补救措施。
- 作为针对特定性能和可靠性相关任务的专注的自动化解决方案。 在性能工程和 SRE 工作中,有些任务会反复出现。 对于这些,我们可以构建有针对性的自动化助手,工程师或 sysgrok 本身可以直接使用它们来解决其他问题。 例如,在性能工程中,回答以下问题:“Is there a faster version of this library with equivalent functionality (该库是否有具有同等功能的更快版本)?” 。 sysgrok 直接支持这一点。
- 作为性能和可靠性问题的自动化根本原因分析工具。 前两类解决方案是数据分析、解释、搜索和总结的组合。 至关重要的是,它们以集中的方式应用于工程师自己收集的数据。 在 sysgrok 中,我们还在研究使用 LLM 解决问题的第三种方法,其中 LLM 与其他工具相结合,自动执行给定问题的根本原因分析和解决方案。 在这种方法中,LLM 会得到问题描述(例如,“The web server is experiencing high latency(Web 服务器正在经历高延迟)”),并被告知可以使用哪些功能(例如,“ssh to host”、“execute arbitrary Linux command line tools”) )。 然后,LLM 被要求采取行动,利用其可用的能力,对问题进行分类。 这些操作由 sysgrok 执行,LLM 被要求分析结果、对问题进行分类、提出补救措施并建议后续步骤。
Sysgrok 仍处于早期阶段,但我们发布它是因为它已经可用于各种任务 - 我们希望它将成为其他人执行类似实验的便捷基础。 如果你有任何想法,请随时向我们发送 PR 或在 GitHub 上提交问题!
使用 LLM 分析性能问题
LLM,例如 OpenAI 的 GPT 模型,在过去几个月中迅速流行,为各种产品提供自然语言界面和核心引擎,从客户助理聊天机器人到数据操作助手,再到编码助理。 这种趋势的一个有趣的方面是,基本上所有这些应用程序都使用现成的通用模型,这些模型没有针对当前的任务进行专门训练或微调。 相反,它们接受了整个互联网大范围的培训,因此适用于各种各样的任务。
那么,我们能否利用这些模型来帮助进行性能分析、调试和优化呢? 有多种方法可用于调查性能问题、对根本原因进行分类并提出优化方案。 但从本质上讲,任何性能分析工作都将涉及查看各种工具(例如 Linux 命令行工具或可观察平台)的输出,并解释该输出以形成有关系统状态的假设。 GPT 模型训练的材料包括软件工程、调试、基础设施分析、操作系统内部结构、Kubernetes、Linux 命令及其用法以及性能分析方法。 因此,这些模型可用于总结、解释和假设性能工程师日常遇到的数据和问题,这可以加快工程师进行分析的速度。
我们可以更进一步,超越纯粹将 LLM 用于工程师自己的调查过程中的数据分析和问题回答。 正如我们稍后将在本文中展示的那样,LLM 本身可用于在某些情况下驱动该流程,由 LLM 决定运行哪些命令或查看哪些数据源来调试问题。

演示
有关 sysgrok 支持的全套功能,请查看 GitHub 存储库。 总的来说,它支持三种解决问题的方法:
方法一:作为性能、可靠性和其他系统相关数据的分析引擎
在这种模式下,LLM 会收到工程师使用的另一个工具的输出,例如 Linux 命令行工具、分析器或可观察平台。 sysgrok 的目标是解释、总结并提出补救措施。
例如,topn 子命令采用分析器报告的最昂贵的函数,解释输出,然后建议优化系统的方法。
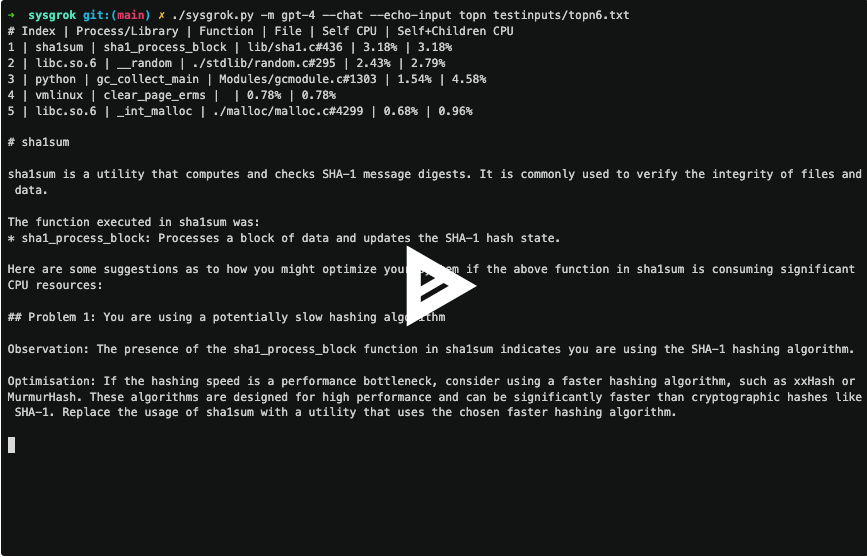
该视频还展示了 sysgrok 提供的聊天功能。 当提供 –chat 参数时,sysgrok 将在 LLM 的每次响应后进入聊天会话。
此功能还可以普遍应用于 Linux 命令行工具的输出。 例如,在《60 秒 Linux 性能分析》一文中,Brendan Gregg 概述了 SRE 在首次连接到遇到性能或稳定性问题的主机时应运行的 10 个命令。 analyzecmd 子命令将要连接的主机和要执行的命令作为输入,然后为用户分析和总结命令的输出。 我们可以使用它来自动化 Gregg 描述的过程,并向用户提供 10 个命令生成的所有数据的一段摘要,从而省去他们必须逐一查看命令输出的麻烦。

方法 2:作为针对特定性能和可靠性相关任务的集中式自动化解决方案
在性能工程和 SRE 工作中,有些任务会反复出现。 对于这些,我们可以构建有针对性的自动化助手,工程师或 sysgrok 本身可以直接使用它们来解决其他问题。
例如,findfaster 子命令将库或程序的名称作为输入,并使用 LLM 查找更快、等效的替代品。 这是性能工程中非常常见的任务。
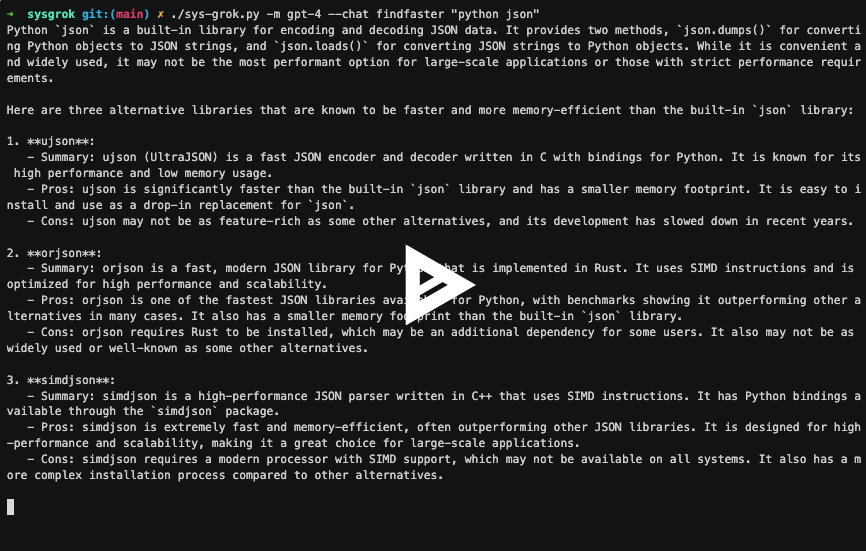
Sysgrok 中这种方法的另一个示例是 explainfunction 子命令。 该子命令采用库的名称和该库中的函数。 它解释了该库的用途及其常见用例,然后解释了该函数。 最后,如果该库和函数消耗大量 CPU 资源,它会建议可能的优化。

方法 3:作为性能和可靠性问题的自动化根本原因分析工具
LLM 的用途不仅限于集中回答问题、总结和类似任务。 它也不限于一次性使用,即提出一个单一的、孤立的问题。 sysgrok debughost 子命令演示了如何将 LLM 用作代理中的 “大脑”,以实现自动解决问题的目标。 在此模式下,LLM 嵌入到一个进程中,该进程使用 LLM 来决定如何调试特定问题,并使其能够连接到主机、执行命令和访问其他数据源。
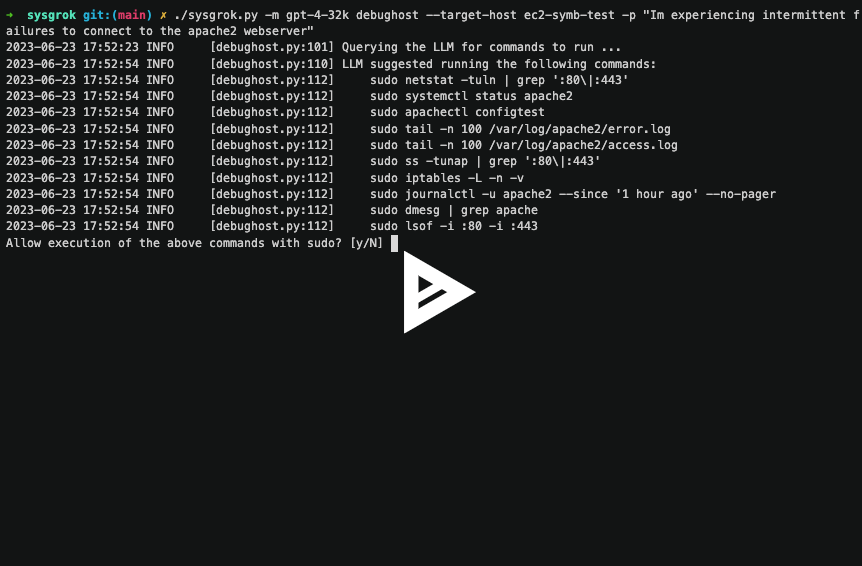
debughost 命令可能是 sysgrok 目前最具实验性的部分。 它展示了在性能分析自动化代理的道路上迈出的一步,但要实现这一目标还需要大量的研发工作。
结论
在这篇文章中,我介绍了 sysgrok,这是一种新的开源人工智能助手,用于分析、理解和优化系统。 我们还讨论了 sysgrok 实现的三大类方法:
- 用于性能、可靠性和其他系统相关数据的分析引擎:请参阅 topn、stacktrace、analyzecmd 和 code 子命令。
- 针对特定性能和可靠性相关任务的集中式自动化解决方案:请参阅 explainprocess、explainfunction 和 findfaster 子命令。
- 针对性能和可靠性问题的自动根本原因分析:请参阅 debughost 子命令。
你可以在 GitHub 上找到 sysgrok 项目。 请随意创建 PR 和问题,或者如果你想讨论一般 LLM 的项目或应用,你可以通过 [email protected] 直接与我联系。