目录
简介:
在这篇博客文章中,我们将详细介绍如何从训练到部署,实现对旋转翼无人机的自动检测。无人机已经广泛应用于各个领域,如航拍、物流、农业等,然而随着无人机的广泛使用,如何快速并准确地检测出无人机的存在,对于无人机的安全管理和监控变得尤为重要。
在这篇文章中,我们将从数据收集和标注开始,然后详细介绍如何训练一个深度学习模型进行无人机检测,再到如何将训练好的模型部署到实际的监控系统中。我们将全面覆盖这个问题的各个步骤,并提供相关的代码和工具,使得读者可以跟随文章的步骤自己动手实现。
一、项目背景
这个数据集由Mehdi Özel为无人机比赛收集的。目前大部分的无人机数据集只包含无人机拍摄的照片(大部分是无人机对地视图)。与别的数据集不同,该数据集的图像是无人机的图像,可以用来训练我方无人机引导和躲避其他无人机。 该数据集有1359张照片,都有标签。数据集仅包括旋翼无人机。不包括固定翼。本项目基于该数据集训练了一个目标检测模型,使模型能够检测旋转翼无人机,在自行划分的验证集下达到mAP≥0.8的效果。
二、数据预处理
Step01:解压数据集
ERROR1:当我使用unzip指令解压数据集时,出现如下报错。
/bin/bash: -c: 行 0: 未预期的符号 `(' 附近有语法错误
/bin/bash: -c: 行 0: `unzip /home/aistudio/data/data191191/DroneDataset (UAV).zip -d /home/aistudio/work/'
SOLUTION1:重命名数据集,删除“()”。即DroneDataset (UAV).zip -> DroneDataset.zip。
In [ ]
!unzip /home/aistudio/data/data191191/DroneDataset.zip -d /home/aistudio/work/Step02: 区分文件夹中不同后缀名的文件
本项目用到的是dataset_xml_format中的图片和标注数据,由于图片和标注数据是存放在一起的,所以我们首先需要把两者分开存放,方便后续处理。
首先,我们在该目录下新建两个文件夹/home/aistudio/work/dataset_xml_format分别为JPEGImages和Annotations。
JPEGImages用于存放数据集中的图片。
Annotations用于存放标注文件。
然后通过下面的指令移动相同后缀名的文件到指定文件夹。
In [ ]
!mv /home/aistudio/work/dataset_xml_format/dataset_xml_format/*.png /home/aistudio/work/dataset_xml_format/JPEGImages/
!mv /home/aistudio/work/dataset_xml_format/dataset_xml_format/*.jpg /home/aistudio/work/dataset_xml_format/JPEGImages/
!mv /home/aistudio/work/dataset_xml_format/dataset_xml_format/*.JPG /home/aistudio/work/dataset_xml_format/JPEGImages/
!mv /home/aistudio/work/dataset_xml_format/dataset_xml_format/*.xml /home/aistudio/work/dataset_xml_format/Annotations/为了便于后面的处理,我们可以统一图片的后缀名。
In [ ]
%cd /home/aistudio/work/dataset_xml_format/JPEGImages/
!rename 's/\.jpg/\.png/' ./*
!rename 's/\.JPG/\.png/' ./*Step03: 划分数据集
首先安装PaddleX。
In [ ]
!pip install paddlex然后,我们通过paddlex中的split_dataset命令按照0.7:0.3的比例划分训练集和验证集。
In [ ]
!paddlex --split_dataset --format VOC --dataset_dir /home/aistudio/work/dataset_xml_format --val_value 0.3划分后我们可以看到当前路径下出现了train_list.txt、val_list.txt和labels.txt三个文件,分别代表:
- 训练集图片及其标注文件
- 验证集图片及其标注文件
- 数据集标签
三、代码实现
3.1 安装PaddleDetection
In [ ]
# 克隆PaddleDetection仓库
#!git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 安装其他依赖
%cd /home/aistudio/PaddleDetection/
!pip install -r requirements.txt
# 编译安装paddledet
!python setup.py install3.2 检测数据分析
检测框高宽比分析: 通过绘制检测框高宽比分布直方图反映当前检测框宽高比的分布情况。
In [ ]
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import glob
import matplotlib.pyplot as plt
def ratio(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
# count_0, count_1, count_2, count_3 = 0, 0, 0, 0 # 举反例,不要这么写
count = [0 for i in range(20)]
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
# 遍历文件的所有检测框
for obj in root.iter('object'):
xmin = obj.find('bndbox').find('xmin').text
ymin = obj.find('bndbox').find('ymin').text
xmax = obj.find('bndbox').find('xmax').text
ymax = obj.find('bndbox').find('ymax').text
Aspect_ratio = (int(ymax)-int(ymin)) / (int(xmax)-int(xmin))
if int(Aspect_ratio/0.25) < 19:
count[int(Aspect_ratio/0.25)] += 1
else:
count[-1] += 1
sign = [0.25*i for i in range(20)]
plt.bar(x=sign, height=count)
plt.savefig("/home/aistudio/work/hw.png")
plt.show()
print(count)
indir='/home/aistudio/work/dataset_xml_format/Annotations/' # xml文件所在的目录
ratio(indir)结果如下:
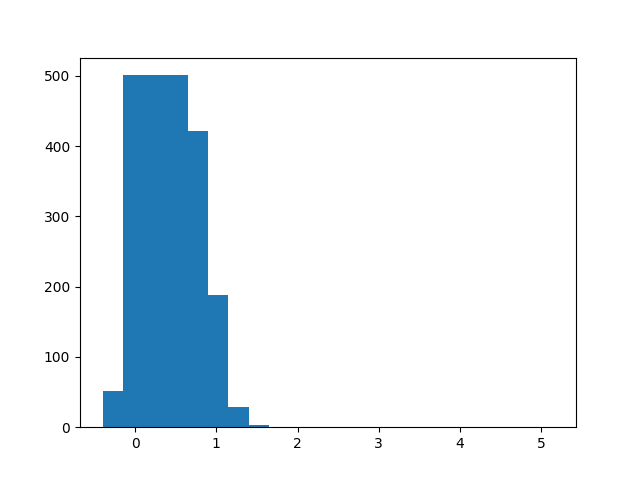
图像尺寸分析: 通过图像尺寸分析,我们可以看到该数据集图片的尺寸不一。
In [ ]
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import glob
def Image_size(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
width_heights = []
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text)
if [width, height] not in width_heights: width_heights.append([width, height])
print("数据集中,有{}种不同的尺寸,分别是:".format(len(width_heights)))
for item in width_heights:
print(item)
indir='/home/aistudio/work/dataset_xml_format/Annotations/' # xml文件所在的目录
Image_size(indir)3.3 模型训练
Step01: 将数据集移动到/home/aistudio/PaddleDetection/dataset目录下。
In [13]
!mv /home/aistudio/work/dataset_xml_format /home/aistudio/PaddleDetection/dataset/Step02: 单卡训练
本项目选择的是百度飞桨的自研模型PP-YOLOE+。PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免了使用诸如Deformable Convolution或者Matrix NMS之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。
PP-YOLOE模型训练过程中使用8 GPUs进行混合精度训练,而本项目在训练过程中使用的单卡V100,因此需要按照公式 �����=���������∗(����ℎ�������∗������������)/(����ℎ�����������∗����������������)lrnew=lrdefault∗(batchsizenew∗GPUnumbernew)/(batchsizedefault∗GPUnumberdefault) 调整学习率为原来的1/8。同时PP-YOLOE+支持混合精度训练。
ERROR2:我们可以看到在训练过程中出现了这样的警告libpng warning: iCCP: known incorrect sRGB profile。
SOLUTION2:通过skimage读取后重新保存,代码如下。
In [ ]
!pip install scikit-imageIn [ ]
import os
from tqdm import tqdm
import cv2
from skimage import io
path = r"/home/aistudio/PaddleDetection/dataset/dataset_xml_format/JPEGImages/"
fileList = os.listdir(path)
for i in tqdm(fileList):
image = io.imread(path+i)
image = cv2.cvtColor(image, cv2.COLOR_RGBA2BGRA)
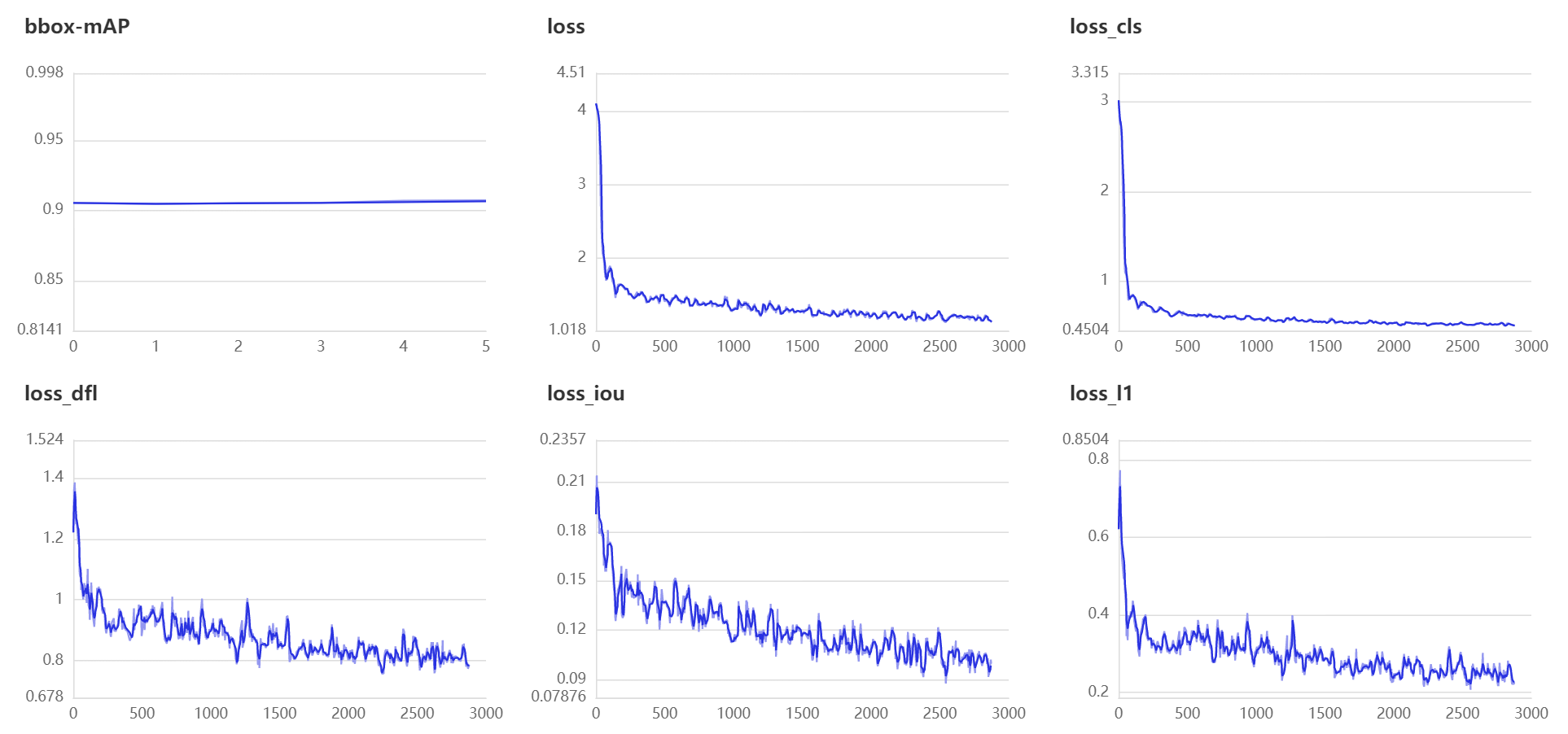
cv2.imencode('.png',image)[1].tofile(path+i)经过三十轮次的迭代,我们可以看到训练的模型已经在验证集取得了不错的效果,mAP为90.73%,满足了我们项目的标准。
In [ ]
%cd /home/aistudio/PaddleDetection/
!python tools/train.py -c configs/ppyoloe/voc/ppyoloe_plus_crn_l_30e_voc.yml --eval --amp --use_vdl True --vdl_log_dir vdl_log_dir/scalar损失函数如图所示:
3.4 模型评估
通过如下命令在单个GPU上评估我们的验证集。
In [ ]
!python tools/eval.py -c configs/ppyoloe/voc/ppyoloe_plus_crn_l_30e_voc.yml -o weights=output/ppyoloe_plus_crn_l_30e_voc/best_model.pdparams3.5 模型推理
我们可以通过以下命令在单张GPU上推理文件中的所有图片。
In [ ]
!python tools/infer.py -c configs/ppyoloe/voc/ppyoloe_plus_crn_l_30e_voc.yml -o weights=output/ppyoloe_plus_crn_l_30e_voc/best_model.pdparams --infer_dir=dataset/dataset_xml_format/JPEGImages --output_dir infer_output/3.6 模型导出
PP-YOLOE+在GPU上部署或者速度测试需要通过tools/export_model.py导出模型。
In [ ]
!python tools/export_model.py -c configs/ppyoloe/voc/ppyoloe_plus_crn_l_30e_voc.yml -o weights=output/ppyoloe_plus_crn_l_30e_voc/best_model.pdparams3.7 FastDeploy快速部署
环境准备: 本项目的部署环节主要用到的套件为飞桨部署工具FastDeploy,因此我们先安装FastDeploy。
In [ ]
!pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html部署模型:
导入飞桨部署工具FastDepoy包,创建Runtimeoption,具体实现如下代码所示。
In [34]
import fastdeploy as fd
import cv2
import osIn [35]
def build_option(device='cpu', use_trt=False):
option = fd.RuntimeOption()
if device.lower() == "gpu":
option.use_gpu()
if use_trt:
option.use_trt_backend()
option.set_trt_input_shape("image", [1, 3, 640, 640])
option.set_trt_input_shape("scale_factor", [1, 2])
return option配置模型路径,创建Runtimeoption,指定部署设备和后端推理引擎,代码实现如下所示。
In [ ]
# 配置模型路径
model_path = '/home/aistudio/PaddleDetection/output_inference/ppyoloe_plus_crn_l_30e_voc'
image_path = '/home/aistudio/PaddleDetection/dataset/dataset_xml_format/JPEGImages/foto00262.png'
model_file = os.path.join(model_path, "model.pdmodel")
params_file = os.path.join(model_path, "model.pdiparams")
config_file = os.path.join(model_path, "infer_cfg.yml")
# 创建RuntimeOption
runtime_option = build_option(device='gpu', use_trt=False)
# 创建PPYOLOE+模型
model = fd.vision.detection.PPYOLO(model_file,
params_file,
config_file,
runtime_option=runtime_option)
# 预测图片检测结果
im = cv2.imread(image_path)
result = model.predict(im.copy())
print(result)
# 预测结果可视化
vis_im = fd.vision.vis_detection(im, result, score_threshold=0.5)
cv2.imwrite("/home/aistudio/work/visualized_result.jpg", vis_im)
print("Visualized result save in ./visualized_result.jpg")推理结果如下:

四、效果展示
部分可视化结果如下:
