卷友们好,我是rumor。
不知大家有没有注意到(也可能是我敏感了),最近一些大机构不约而同地开始挖新坑了,两个风向标DeepMind和OpenAI,先后发布了Gato和VPT,期望除了图像和文本之外,预训练模型也能够与环境交互。
这个方向,叫Embodied AI(具象AI)。
与具象AI对立的词是Internet AI[1],指通过互联网上的数据进行学习,比如我们一直在做的CV、NLP。而Embodied AI是指从与环境的交互中学习。
NLP+CV+RL,这个组合大概率是通向终极目标的必经之路,但我没想到这么快就要来了。而且随着预训练的颠覆,这个坑变成了:
如何通过互联网上丰富的多模态数据,训练一个通用模型,可以根据指令在环境中执行各种任务。
上述是我自己给出的问题定义,其中有以下两个难点:
如何提升学习效率:正如LeCun说的,通过与环境交互学习有很大风险,效率也低(正向奖励太少),而通过观察(observation),利用现有数据学习效率才更高,这样也可以延续预训练-精调/Prompt的范式,把更多的知识迁移到下游
复杂的输入输出和环境:在最复杂的情况下,模型的输入是多模态指令,输出是可以在真实环境执行的动作。其实针对Embodied AI的评估有多种任务,比如Navigation、Manipulation、Instruction following,但指令是可以描述所有任务的,需要更高维的理解。同时,输出的动作空间大小、环境是模拟的还是真实的,都会带来不同的挑战
以这两个难点为轴,上半年一些机构的进展如下:
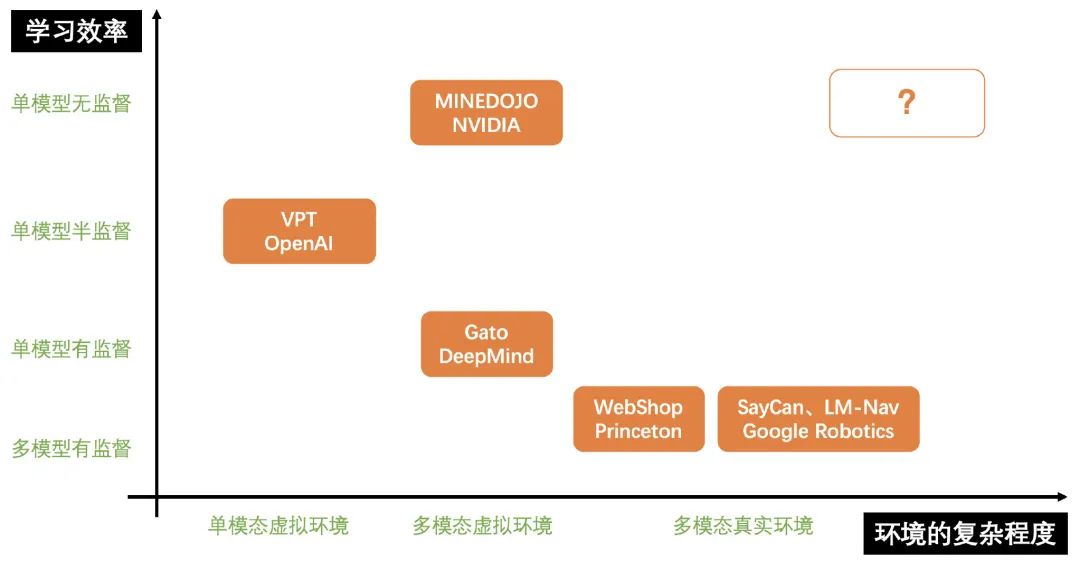
下面就从右下到左上的顺序介绍一下这些工作。
P.S. 这些工作大部分都是我近几个月在信息流看到的,如有遗漏请留言我。
SayCan、LM-Nav
在今年4月份,Google Robotics团队发布了一篇SayCan的工作[2],输入自然语言指令,让机器人在真实的环境中执行任务。
Robotics的团队还是比较偏RL的,作者的方法是搭建了一个Pipeline:
把指令变成Prompt,利用LM把指令分解成skill,这些skill都是提前用RL训练好的(比如机械手拿起眼前的物体就是一个skill)
通过训练好的价值函数,联合LM给出skill的概率分布,执行概率最大的
执行完第一个skill之后,再拼接成新的prompt生成第二个skill
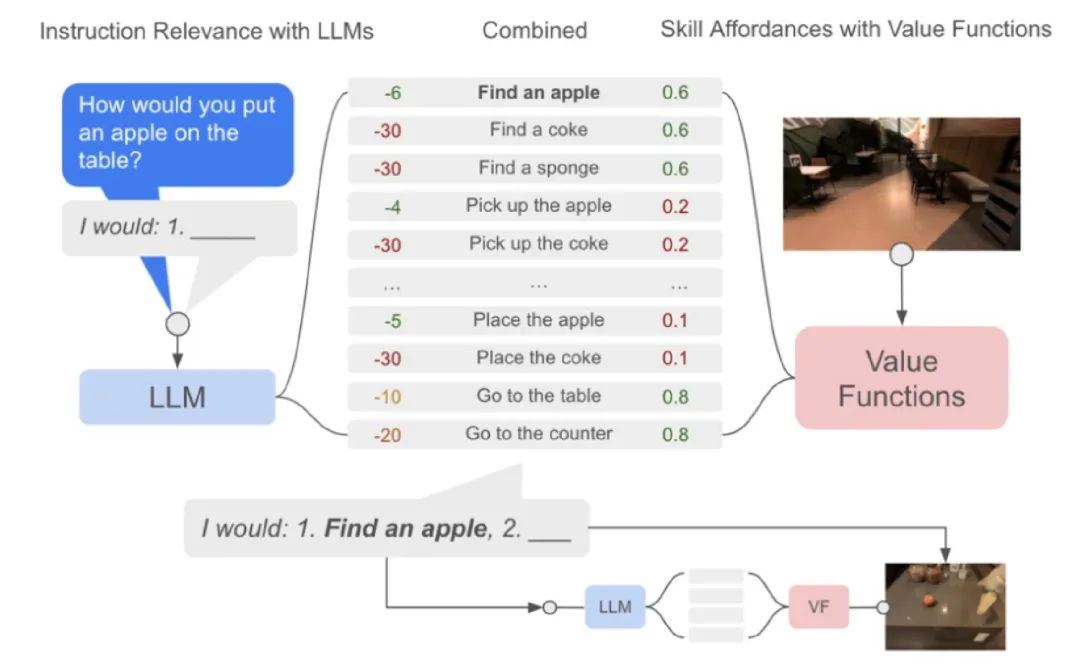
作者虽然能够在真实环境中执行任务,但在学习效率上还有待提高,每个skill都是单独训练的,只利用了训练好的语言模型来减少学习成本。
随后在7月初,这个团队又推出了一篇LM-Nav的工作[3],更加fancy,给小车一个指令,告诉它往哪走,在哪儿拐,小车就能自己开过去。
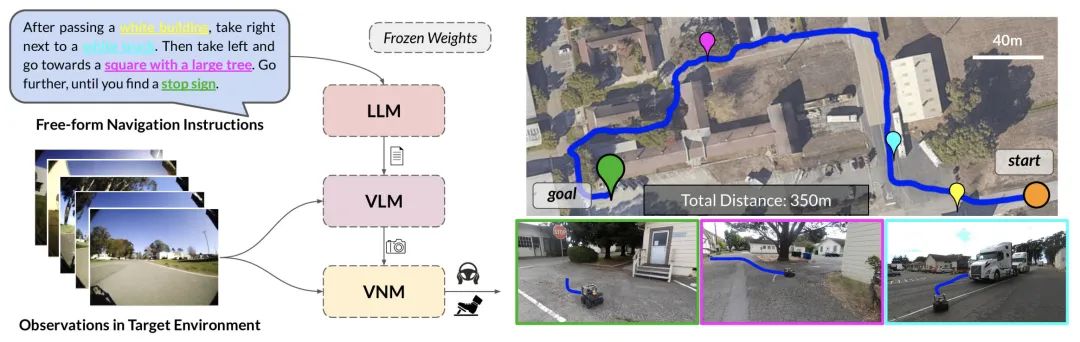
不过作者拆解得也更加复杂,总共用了三个模型:

执行的流程是:
VNM对环境进行建模
LLM对命令进行拆解
VLM对环境进行解析
把1和3结合起来,搜索最佳路径
用VNM执行

做Robotics的团队还是很强的,做完了就真的能直接在现实里跑起来,不过解决方案的效率离终极目标还有些距离。下面介绍的工作基本都是在虚拟环境中尝试了。
WebShop
WebShop[4]是7月份普林斯顿刚出的工作,作者做了一个简化版的电商APP,学习如何根据用户需求去下单商品。真正放到亚马逊上使用后成功率有27%,跟测试的28%很接近,不够本事就都是「虚拟环境」,比起上篇工作的复杂度还是弱一些。
作者也是通过Pipeline方案实现的:
对于输入的指令,用seq2seq模型生成搜索query
因为动作空间比较有限,作者训练了一个选择模型,分别给每个动作进行打分得到
S(o,a),从而采样出下一步动作,如下图
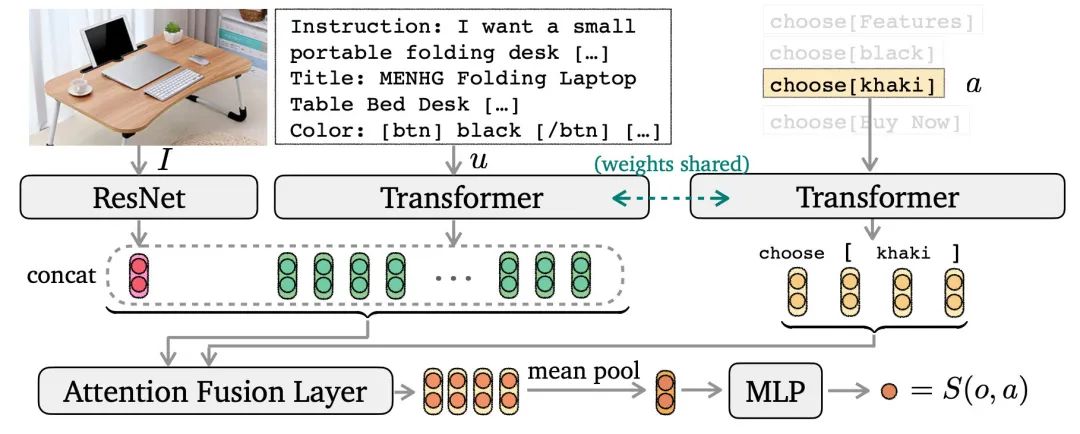
这份工作也是很好的尝试,除了真实环境之外,与手机、电脑的交互占据了我们生活中大部分时间,提效的第三方个性化工具也是有些发展前景的。
Gato
Gato[5]是DeepMind在5月份发表的工作,当时还是蛮刷屏的,如果说上面两个工作都仍旧把Embodied AI拆解成多模态理解+RL模型执行,那Gato则是证明了一个模型就可以做所有事情。
作者让一个自回归模型承担所有,包括打游戏(RL)、图像说明、聊天
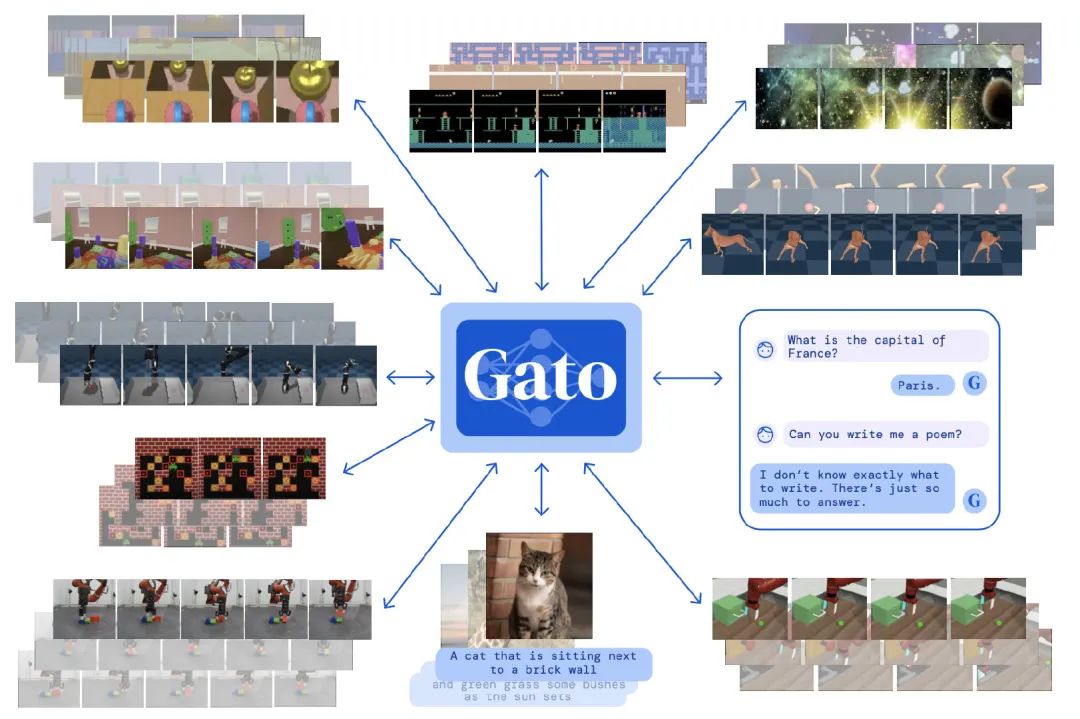
不过在学习打游戏时,是利用其他SOTA的强化模型直接生成的监督数据。
虽然在数据利用上没有延续预训练的范式,但终于完成了由Pipeline到End2End的突破。
VPT
VPT[6]是OpenAI在6月底提出的工作,就是那个在「我的世界」里玩的贼6的agent。
OpenAI延续了以往的风格,自回归 is all you need。
最粗暴的想法,就是输入图像,预测下一帧,但下一帧图像怎么映射成动作呢?
于是作者先训练了一个反向模型IDM(inverse dynamics model),输入双向上下文视频,预测当前帧对应的键盘和鼠标动作。训练完了之后给8年长的视频进行标注,这样监督数据就都有了。
于是延续老方法,自回归一把梭,训出了一个LM,根据输入的帧序列,预测未来的动作,就把游戏给玩6了。
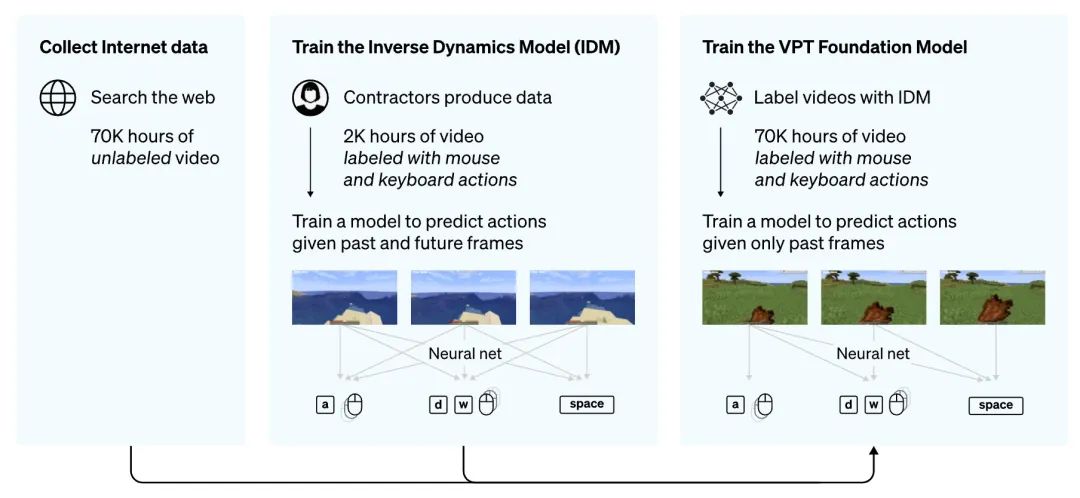
这个工作也把图像理解和动作预测结合到了一起,但输入没有指令,复杂程度还差一些。也可能是发布的比较仓促,因为就在这篇工作的前6天,英伟达发布了同样以「我的世界」为基础的MINEDOJO。
MINEDOJO
英伟达在6月中发布的MINEDOJO[7]是我目前个人最喜欢的一篇工作,比起VPT它有两个优点:
无监督,学习效率更高
指令作为输入,更加复杂
英伟达更多的还是从RL的角度来思考解决方案,RL最重要的就是奖励函数,它作为监督信号,会影响模型的动作,从而决定是否能采样到有效数据。
于是作者提出了MINECLIP模型,利用CLIP的思路进行预训练,计算视频和文本指令的相似度,作为RL的奖励值,有种生成器-判别器的感觉。
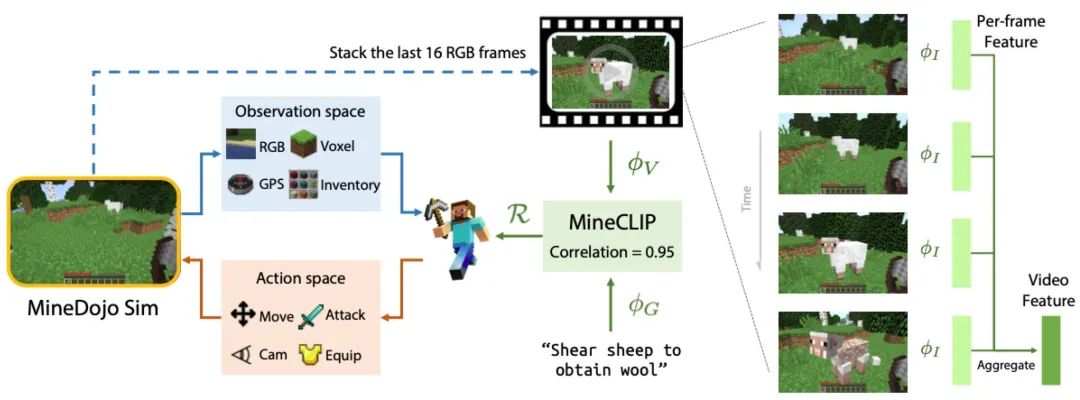
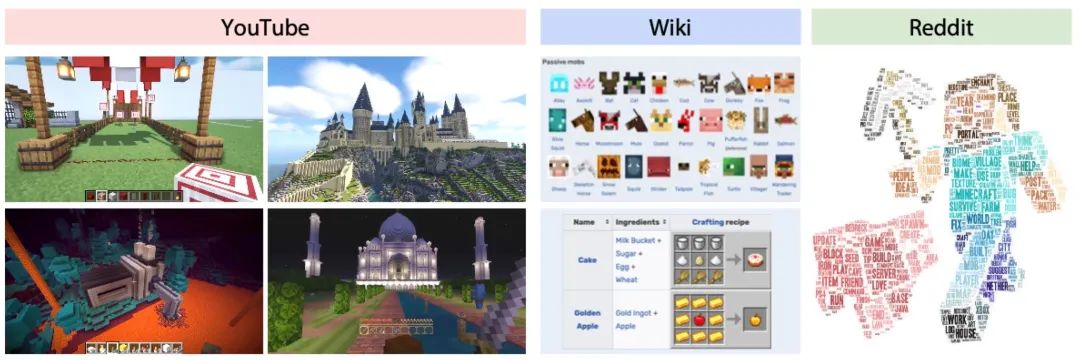
同时,相比起OpenAI整理的8年视频数据,英伟达收集了MineCraft相关的33年的视频、6k+维基百科、百万级别的reddit讨论,全部都开源出来了,真是太良心。
总结
最近业余时间主要关注了一些Embodied AI的工作,同时也给了我其他启发:如果说数据是算法的天花板,那现在的瓶颈,比如推理、常识学习,原因可能在于现有数据的多样性?
视觉、听觉、触觉都是我们认识世界的途径之一,他们之间的联系也会让我们加深理解,把模态叠加起来,让模型不断接近我们的现实世界,或许是突破单模态任务瓶颈的方法。
另外,这个方向也催生了另外一门生意,还记得靠模型和数据起家估值20亿的HuggingFace吗?到了Embodied AI时代,虚拟环境就是必需品了,OpenAI、英伟达、AllenAI都发布了他们的虚拟环境,能否滋生一个新的生态,未来可期。
参考资料
[1]
A Survey of Embodied AI: From Simulators to Research Tasks: https://arxiv.org/abs/2103.04918v5
[2]Do As I Can, Not As I Say: Grounding Language in Robotic Affordances : https://arxiv.org/abs/2204.01691
[3]LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action: https://arxiv.org/abs/2207.04429
[4]WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents: https://arxiv.org/abs/2207.01206v1
[5]A Generalist Agent: https://arxiv.org/abs/2205.06175
[6]Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos: https://arxiv.org/abs/2206.11795
[7]MINEDOJO: Building Open-Ended Embodied Agents with Internet-Scale Knowledge: https://arxiv.org/abs/2206.08853v1

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「我要个洗碗拖地按摩机器人就够」