mysql慢日志分析,资源消耗监控,执行计划
慢日志
Mysql提供了慢日志记录,可以监控执行时间超过设定值的sql,并予以记录。
查看是否开启了慢查询日志:
show variables like '%slow%';
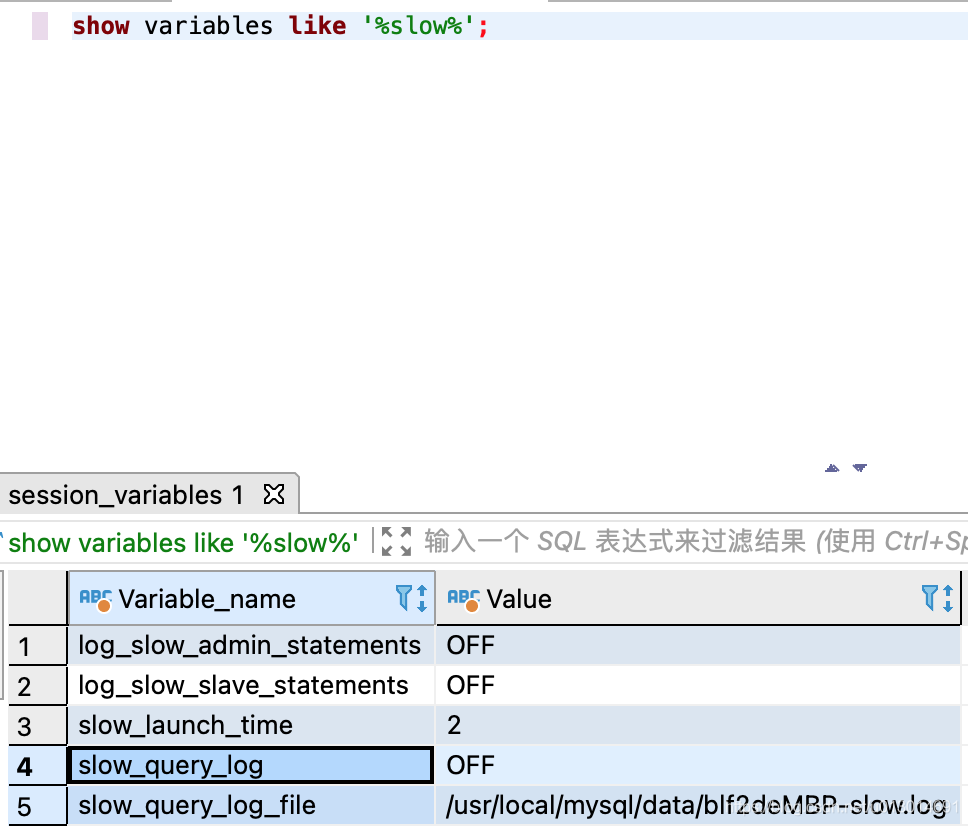
show variables like '%long_query_time%';
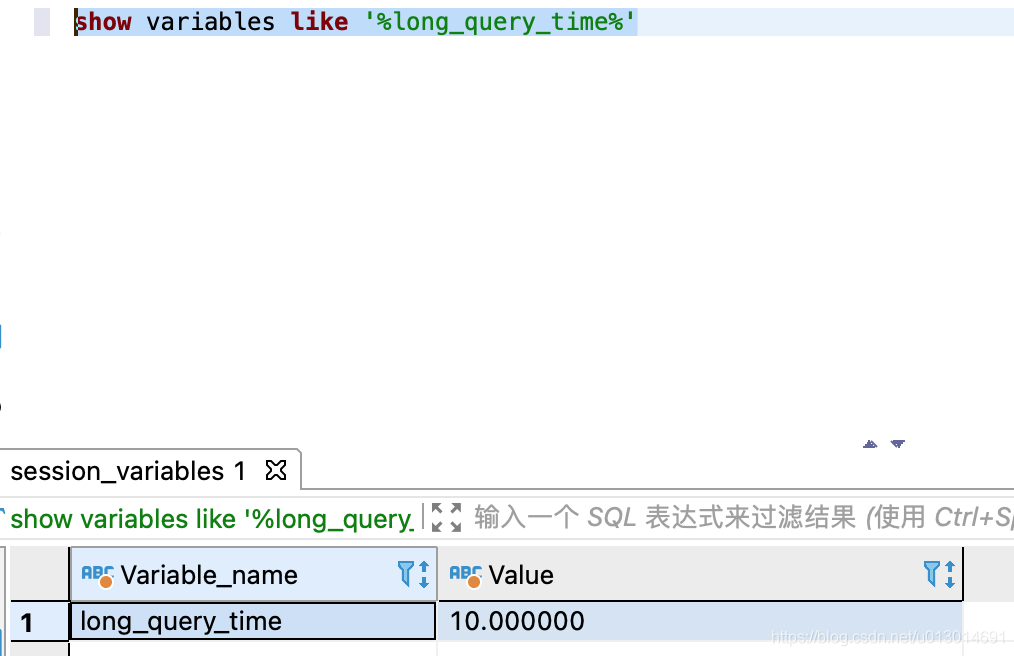
可以看到慢查询日志的状态slow_query_log是OFF,是关闭状态,slow_query_log_file是慢日志文件存储位置,long_query_time是超过多少秒视为慢查询,默认是10秒。这里我们将慢查询日志打开,并且设置时间超过1秒的查询则为慢查询。
-- 打开慢日志
set global slow_query_log = ON;
-- 判定时间设置为1秒
set long_query_time = 1;
再次查询可以发现慢日志打开了,并且时间设置成为1秒。

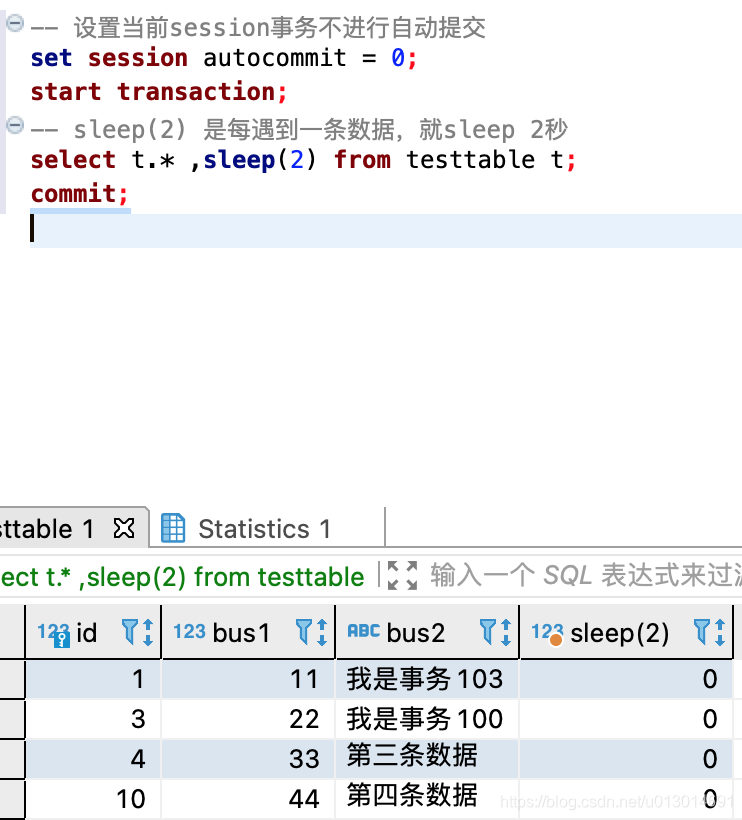
此时我们模拟一个查询,让它超过1秒,去查看慢日志记录(sql中的表testtable是我之前写博客的一个测试表,这里不必太纠结使用哪张表):
-- 设置当前session事务不进行自动提交
set session autocommit = 0;
start transaction;
-- sleep(2) 是每遇到一条数据,就sleep 2秒
select t.* ,sleep(2) from testtable t;
commit;
这时候我们去看一下慢查询日志:
cat /usr/local/mysql/data/blf2deMBP-slow.log
输出如下:
/usr/local/mysql/bin/mysqld, Version: 5.7.30 (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
# Time: 2021-07-10T11:57:45.761128Z
# User@Host: root[root] @ localhost [127.0.0.1] Id: 17
# Query_time: 8.020510 Lock_time: 0.008288 Rows_sent: 4 Rows_examined: 4
use test_user;
SET timestamp=1625918265;
/* ApplicationName=DBeaver 21.1.0 - SQLEditor <Script-17.sql> */ select t.* ,sleep(2) from testtable t
LIMIT 0, 200;
可以看到select t.* ,sleep(2) from testtable t LIMIT 0, 200;被监控到了(LIMIT 0,200是DbEver自动添加的),打开慢日志记录,能让我们查到哪些sql执行比较慢,然后个根据一定的规则去优化。
SQL 执行计划 EXPLAIN
执行语句格式:
explain sql语句
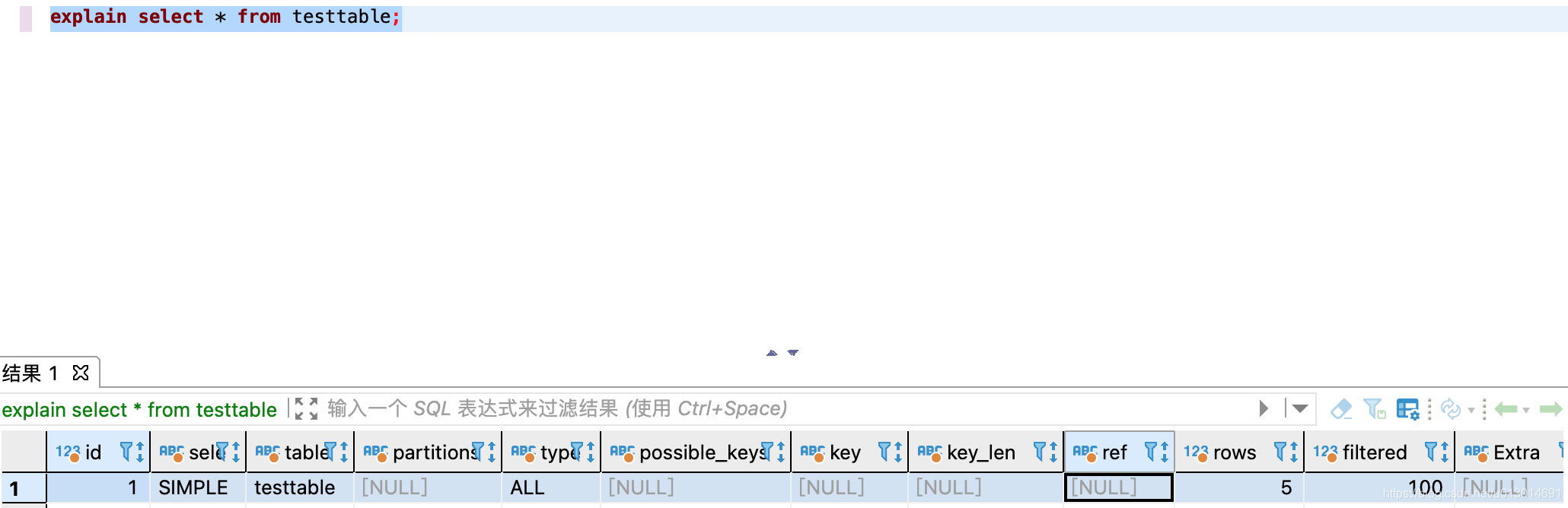
我们经常关注以下字段:
扫描二维码关注公众号,回复:
15491497 查看本文章

type 访问类型 以下类型性能从差到优
- all:全表扫描,这个代价是最大的,性能最差的,有很大的优化空间
- index:全索引扫描,扫描所有索引,比全表扫描快一点
- range:: 范围查询,这个范围一定是用了索引的范围,大多出现在
>,<,>=,<=,BWTWEEN这种带范围的查询 - ref:结果是使用了索引的(非主键索引,非唯一索引),我们知道索引是有序的,即使是这个索引有重复字段,也会在一个小范围内并且连续,不会全表扫描
- ref_eq:使用了索引结果只有一个,出现在查询用到了唯一索引或主键索引的场景
- const:当前查询使用了主键索引
possible keys
可能使用的索引
key
实际使用到的索引
ken_length
索引长度,长度越长,查询越慢
ref
查询中使用到的与其它表的关联字段,外键等
rows
预估扫描行数,这个数值是预估的,并不是真实准确的,优化器会根据预估行数来选择索引,所以存在因为预估误差太大选错索引的可能,此时使用force index给语句指定索引
Extra
- using where
使用where条件进行了数据过滤,一般遇到这个很难判定性能好坏,需要和type一起判断是否需要优化 - using index
使用了索引,一般来讲结果都在一颗索引树上查到(无需回表),性能较好,一般不需要优化 - using index condition
使用了索引,但是需要回表,此时优化一般是使用覆盖索引 - using filesort
使用了临时文件进行排序,一般出现在order by的排序中由于排序字段没加索引导致全部数据排序,并且没法再内存中完成排序,性能较差,一般会在排序字段上加索引,避免全部排序 - using temporary
使用了临时表,性能较差,一般出现在``group by和order by`一起的时候,分组字段和排序字段不一致导致需要中渐变暂存结果,优化方案一般是加索引 - using join buffer (Block Nested Loop)
需要循环计算,一般出现在两个表join操作但是join的字段没有加索引导致,一般优化方案是在join的字段上加索引