1.Zookeeper分布式锁的概念
分布式锁的概念图如下:一种演变过程。
在我们进行单机应用程序开发时,往往会涉及到并发同步的问题,一般都会采用synchronized或者Lock锁的方式来解决多线程间的代码同步问题,这些多线程都是运行在同一个JVM之下,是没有任何问题的。
场景:当有一个请求数据的线程进入JVM后,进行数据的操作,这是没有问题的,当同时有多个请求的线程时,就看会存在问题了,对于数据是不安全的,基于这种情况之下,我们就对JVM线程这块加一个锁,当请求进入后,锁打开,其他的请求就会处于等待的状态,当请求处理完成后,锁释放,新的请求进入。
给JVM加锁的方式仅适合单节点的模式,一旦是集群模式将不会再起作用。
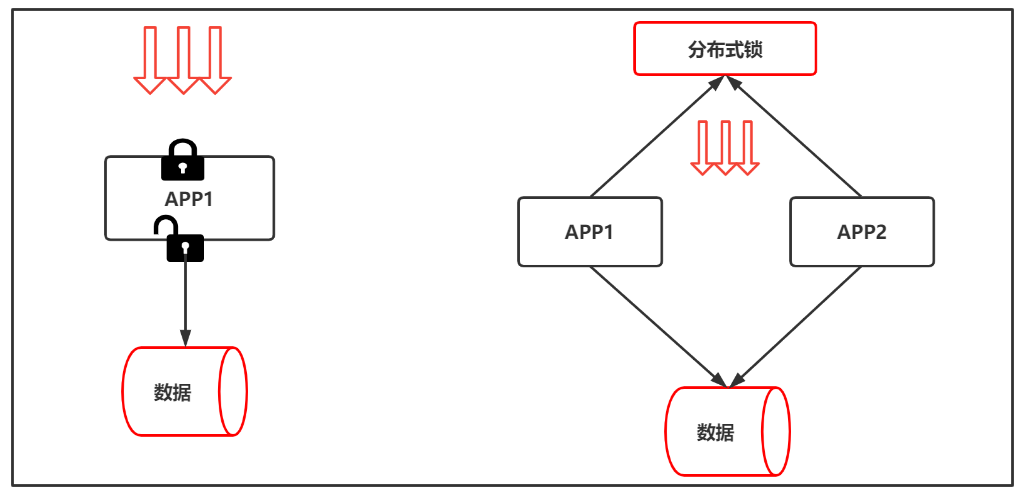
单节点是无法提供线上环境的使用的,随着业务量的增大,单体应用程序通常都会升级成分布式集群的工作模式,比如负载均衡,应用程序往往都会运行几十个甚至上百个,这时就属于多JVM的环境了,多个JVM之间是无法通过JVM的线程锁来解决数据请求/同步的问题的,JVM的锁只能管理当前JVM的线程,无法跨JVM进行管理。
场景:当集群中存在两个应用程序,通过负载均衡的方式为用户提供服务,当用户请求进来后,随机转发到一个应用程序上,如果有多个对同一数据操作的线程同时进行请求,这时JVM的锁就没有任何用处了,因为即使把第一个程序锁住了,那么请求到达第二个程序上还是可以进来处理数据的,JVM的锁无法跨JVM使用,这就导致数据的不安全了。
基于分布式的场景,JVM锁已经远远无法满足了,这时就需要一种统一配置的锁,那就是分布式锁的组件,让所有的程序副本都连接到这个分布式锁组件,由分布式锁提供一个唯一的锁,比如第一个请求到达APP1节点上了,此时APP1就会去分布式锁中取一个锁,让这个请求线程安心处理数据,当数据处理完成后,再将锁还回去,第二个请求进来如果发现锁已经被APP1使用了,那么就会处于等待的状态,当APP1处理完成后,APP2再拿到锁去处理数据。
分布式锁主要用于处理跨机器进程之间的数据同步问题。
2.分布式锁的实现方式
分布式锁可以通过以下三种方式实现:
- 基于缓存实现分布式锁
- 例如Redis、Memcache等等,缓存数据库的性能非常强,但是这种缓存数据库也有集群模式,也会产生数据的不同步。
- 基于Zookeeper实现分布式锁
- Zookeeper的性能也是比较强大的,自身就是分布式集群,对于实现分布式锁更加可靠。
- 基于数据库层面实现分布式锁
- 数据库的性能本身就低,基于数据库实现,需要在每次处理数据时添加一条类似于锁的数据,来保证数据的可靠性
- 常见的方式由乐观锁和悲观锁
3.Zookeeper分布式锁的原理
分布式锁的核心思想:当客户端需要获取锁时,则创建一个节点,使用完锁,就删除该节点。
当客户端需要从Zookeeper中获取一个锁时,就在/lock节点下创建一个子节点,使用完成后自动将创建的子节点删除。
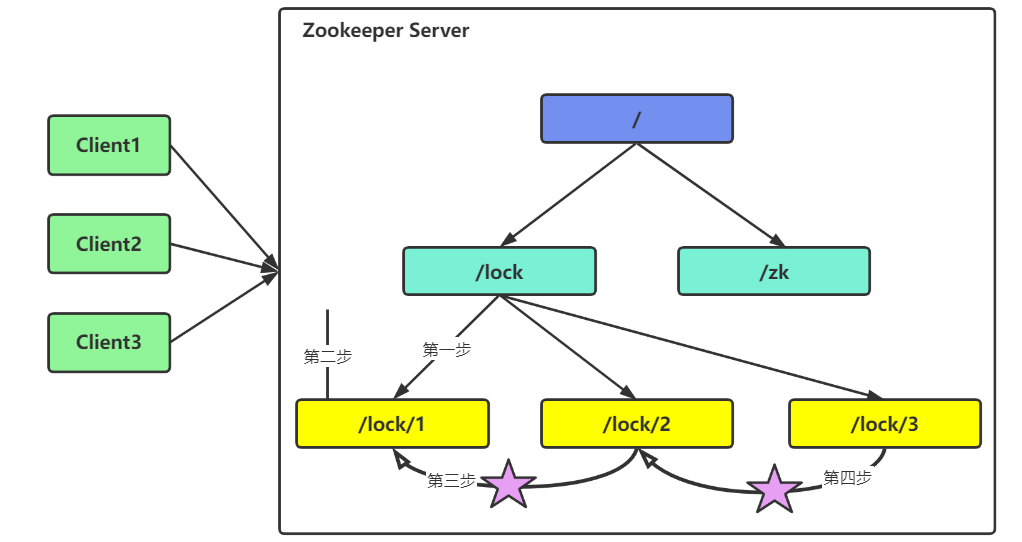
Zookeeper分布式锁的原理如下图所示:
1、客户端向Zookeeper发送请求获取锁,然后会在Zookeeper中的/lock节点下创建一个临时顺序的节点,如果有多个客户端请求相同的线程,则会同时在Zookeeper中创建多个子节点锁,并且节点都是顺序的,如/lock/1、/local/2、/local/3等等,依次类推,数字编号自动生成。
2、每个客户端都会获取/lock节点下所有创建的子节点(所有客户端创建的子节点锁),客户端获取到所有的子节点之后,开始比较子节点的顺序编号,顺序编号在这里就会起到决定性的作用,如果客户端发现自己创建的子节点顺序编号最小,那么就认为该客户端获取到了锁,使用完锁之后就会将节点删除。
如下图所示:每个客户端都获取到了所有的子节点,Client1这时就会发现自己创建的/lock/1节点编号最小,那么他就获得了锁
3、如果客户端发现自己创建的子节点编号并不是所有子节点中最小的,那么就表示并没有获取到锁,此时客户端就需要找到比自己小的子节点,同时对这个节点进行事件监听,监听删除子节点的事件。
如下图所示:Client2和Client3发现自己创建的子节点编号并不是所有节点中最小的,Client2创建的是/lock/2,Client3创建的是/lock/3,此时Client2的子节点就会找到比自己编号小的子节点/lock/1,然后去监听/lock/1子节点的事件信息,Client3也会找到比自己编号小的子节点/lock/2,然后去监听/lock/2子节点的事件信息。
4、如果客户端从监听事件中得知比自己子节点编号小的节点被删除了,此时会再次判断自己的子节点编号是不是所有子节点中最小的,如果是,则获取到锁,如果不是则重复上步骤继续获取到比自己小的子节点并且监听事件信息。
如下图所示:Client2从监听事件中得知Client1客户端创建的子节点删除了,此时Client2就会判断自己的子节点是不是所有子节点中最小的,如果是,那么client2成功获取锁,此时Client3也会去比较,结果发现还有比自己小的,Client3还需要进行监听然后等待。
客户端向Zookeeper获取锁时,为什么会创建一个临时顺序的子节点?
因为临时顺序的节点特点就是当会话关闭后,自动将创建的节点删除,恰好可以满足使用完锁,就删除节点的理念,试想一下,如果我们使用的是持久化节点,那么当客户端1去获取锁处理数据的过程中挂掉了,那么在Zookeeper中创建的子节点/lock/1是不会被删除的,那么其他相同操作的客户端是无法获取锁的,就会导致数据处理异常,其他的客户端一直处于等待锁的状态,如果我们使用的是临时节点,即使客户端1在处理数据的过程中挂掉了,也就意味着会话断开了,一旦断开了会话,临时节点就会自动删除,相同的请求会向Zookeeper中再次请求一个新锁,然后去处理数据,数据处理完成后自动删除创建的锁。
临时节点就是为了防止客户端数据处理完之后锁不释放的问题。
顺序节点的作用?
用于所有客户端创建的子节点间进行比较,如果发现自己的子节点编号比较小,那么就获取锁。