1. scrapy 与 scrapy-redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。
而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
2. scrapy-redis提供了下面四种组件
scrapy-redis在scrapy的架构上增加了redis提供了下面四种组件(components)(四种组件意味着这四个模块都要做相应的修改):
1)Scheduler(调度器)
2)Duplication Filter(requst的去重过滤器)
3)Item Pipeline(将Item存储在redis中以实现分布式处理)
4)Base Spider
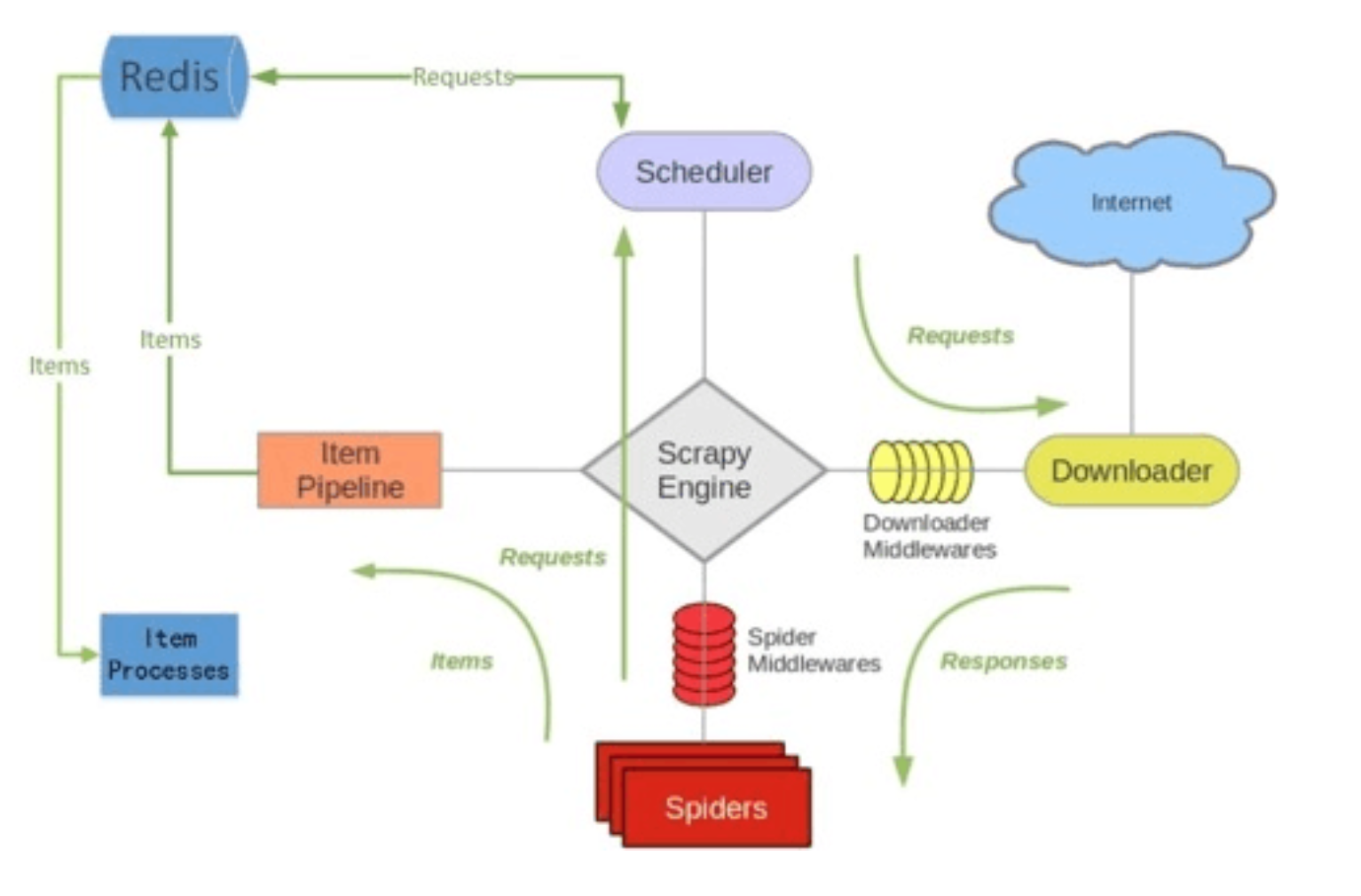
如上图所⽰示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:Scheduler、Duplication Filter、Item Pipeline、Base Spider
3 .scrapy-redis为什么支持分布式
1). scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue(点击打开链接git),但是scrapy多个spider不能共享待爬取队列scrapy queue, 即scrapy本身不支持爬虫分布式;
2). scrapy-redis 的解决是把这个scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
3). scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入scrapy queue),取出下一个要爬取的request(从scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构。然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
4. scrapy-redis中去重
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
5. Item Pipeline
scrapy中引擎将(Spider返回的) 爬取到的Item给Item Pipeline;
scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现 items processes集群。
所有的爬虫端共享一个数据库,新的请求的时候调度器交给redis比配是否已经爬过,如果没有爬,则交个调度器分配请求。也就是说redis数据库在内存中维护了,请求队列,指纹队列和请求到的数据(便于统一存储
6 . 安装scrapy-redis
Python3安装命令:sudo pip3 install scrapy-redis
使用git下载源代码:
git clone https://github.com/rolando/scrapy-redis.git