前言
本文是图像分割·专栏的第一篇。图像分割在整个图像处理过程中是很重要的一环,它大多数作为整个图像处理的预处理步骤,分割的目的主要是为了得到ROI区域,并且为后续的特征提取和模式识别打下坚实的基础。
本文主要介绍如何用Kmeans方法进行图像分割。
一、Kmeans是什么?
Kmeans是一种将输入数据划分为k个类别的简单聚类算法,该算法能不断提取当前分类的中心点,并最终在分类稳定时完成聚类。本质说,Kmeans是一种迭代算法。
Kmeans算法一般的用途是对数据进行分类,让计算机对数据进行分析,并且自动将数据划分为k个类别。而图片实际上就是二维或者三维数组,对图片进行Kmeans分类自然就完成了分割。
二、如何使用Kmeans
1.opencv中的Kmeans函数
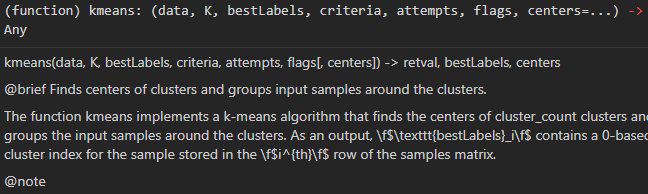
该图是opencv-python中Kmeans函数的参数解析,网上有很多资料,我就不在这赘述了。
2.Kmeans代码示例
对一维数据进行分类
from sys import flags
from cv2 import cv2
from matplotlib.image import imread
import numpy as np
from matplotlib import pyplot as plt
from numpy.core.defchararray import center
'''
Kmeans对一维数据进行聚类
'''
# 随机生成小米和大米两组数据,小米数值特征范围0到50,大米特征范围200到250,都是60个
xiaomi = np.random.randint(0,50,60)
dami = np.random.randint(200,250,60)
# 将大米小米数据按水平线方向合并,得到(120,)
mi = np.hstack((xiaomi,dami))
# print(mi.dtype)
# print(mi.shape)
# 将mi的形状变成一维向量,并且数据类型变成Kmeans需要的float32
mi = mi.reshape((120,1))
mi = np.float32(mi)
# 设置Kmeans的终止条件
critera = (cv2.TermCriteria_EPS+cv2.TermCriteria_MAX_ITER,10,1.0)
# 设置Kmeans的初始化方式
flags = cv2.KMEANS_RANDOM_CENTERS
# 将数据传入,进行聚类
r,best,center = cv2.kmeans(mi,2,None,criteria=critera,attempts=10,flags=flags)
print(r)
print(best)
print(center)
# 标签为0的是小米,将该结果数据利用逻辑索引取出赋给新变量xiaomi
xm = mi[best==0]
dm = mi[best==1]
# 展示结果
plt.plot(xm,'ro')
plt.plot(dm,'bo')
plt.plot(center[0],'rx')
plt.plot(center[1],'bx')
plt.show()
结果如下图
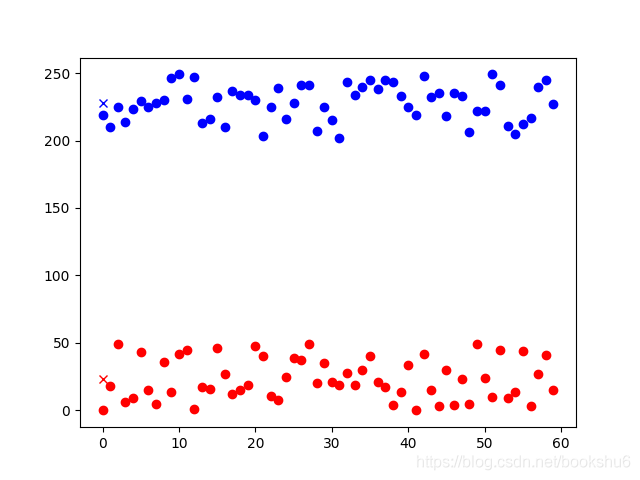
对二维数据进行分类
# 每组数据是二维,xiaomi数据是(30,2)的size,且数据范围是0到20,dami的size也是(30,2),范围是40到60
xiaomi = np.random.randint(0,20,(30,2))
dami = np.random.randint(40,60,(30,2))
# 将两种数据按照垂直方式合并,得到(60,2)
mi = np.vstack((xiaomi,dami))
print(mi.dtype)
print(mi.shape)
# 转换数据格式
mi = np.float32(mi)
# 设置Kmeans函数参数
critera = (cv2.TermCriteria_EPS+cv2.TermCriteria_MAX_ITER,10,1.0)
flags = cv2.KMEANS_RANDOM_CENTERS
r,best,center = cv2.kmeans(mi,2,None,criteria=critera,attempts=10,flags=flags)
print(r)
print(best.shape)
print(center)
# 因为是二维数据,得到的标签不是(120,),而是(120,1),是一个一维向量,所以逻辑索引和上面有的区别
xm = mi[best[:,0]==0]
dm = mi[best[:,0]==1]
plt.scatter(xm[:,0],xm[:,1],c='g',marker='s')
plt.scatter(dm[:,0],dm[:,1],c='r',marker='s')
plt.xlabel('height'),plt.ylabel('width')
plt.show()

对图片进行分割
# 对图像用kmeans聚类
# 显示图片的函数
def show(winname,src):
cv2.namedWindow(winname,cv2.WINDOW_GUI_NORMAL)
cv2.imshow(winname,src)
cv2.waitKey()
img = cv2.imread('segmentation/1.jpg')
o = img.copy()
print(img.shape)
# 将一个像素点的rgb值作为一个单元处理,这一点很重要
data = img.reshape((-1,3))
print(data.shape)
# 转换数据类型
data = np.float32(data)
# 设置Kmeans参数
critera = (cv2.TermCriteria_EPS+cv2.TermCriteria_MAX_ITER,10,0.1)
flags = cv2.KMEANS_RANDOM_CENTERS
# 对图片进行四分类
r,best,center = cv2.kmeans(data,4,None,criteria=critera,attempts=10,flags=flags)
print(r)
print(best.shape)
print(center)
center = np.uint8(center)
# 将不同分类的数据重新赋予另外一种颜色,实现分割图片
data[best.ravel()==1] = (0,0,0)
data[best.ravel()==0] = (255,0,0)
data[best.ravel()==2] = (0,0,255)
data[best.ravel()==3] = (0,255,0)
# 将结果转换为图片需要的格式
data = np.uint8(data)
oi = data.reshape((img.shape))
# 显示图片
show('img',img)
show('res',oi)
原图

结果图

总结
Kmeans对图像分割,本质上还是基于灰度的分割,既然是基于灰度的分割,就会对光照变化敏感。但这种分割和传统的阈值分割不同在于,它可以对彩色图像直接进行分割,而且比传统的阈值分割多了一种自适应性。当然,这种自适应性和大津算法(ostu)孰强孰弱还有待验证。