点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心为大家分享行人轨迹预测的最新进展—关于自动驾驶安全性的思考,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【轨迹预测】技术交流群

为了确保在具有复杂车-人交互的城市环境中的安全自动驾驶,自动驾驶汽车具有实时预测行人短期和即时行动的能力至关重要。近年来,人们开发了各种方法来研究自动驾驶场景中行人行为的估计,但对行人行为缺乏明确的定义。在这项工作中,调查了文献空白,并提出了行人行为特征的分类法。此外,提出了一种新的多任务序列到序列Transformer 编码器-解码器(TF-ed)架构,用于行人行动和轨迹预测,仅使用自车辆相机观测作为输入。将所提出的方法与现有的用于动作和轨迹预测的LSTM编码器-解码器(LSTM-ed)架构进行了比较。在公开的联合注意力自动驾驶(JAAD)数据集、CARLA模拟数据以及在大学校园收集的实时自动驾驶接驳数据上评估了这两种模型的性能。评估结果表明,在JAAD测试数据上,该方法在动作预测任务上的准确率达到81%,比LSTM算法高7.4%,而LSTM算法在预测序列长度为25帧的轨迹预测任务上表现更好。
简介
与其他道路使用者的安全互动是开发和实施完全自动驾驶的智能车辆的一个关键挑战。城市驾驶环境更容易发生行人事故,因此对街道上行人行为的预测和估计以及及时做出机动决策是在混合交通中采用自动驾驶汽车的关键要求之一,例如城市驾驶场景或在大学校园、小城镇等非结构化驾驶环境中实现最后一英里连接的自动驾驶班车。
大量文献集中在通过纯粹基于视觉的行人检测和跟踪或轨迹预测进行行人建模。尽管这些方法显示出了有希望的结果,但对于行人感知的自动驾驶来说,这是不够的,因为行人的行为模式是高度动态的(运动计划和方向的突然变化),并且对即使是微小的环境变化也很敏感。
作为一种更高层次的行为建模,最关键和最常研究的问题之一是预测行人穿越/不穿越车辆/街道的行为。这在文献中通常被称为行人意图。一些工作使用可测量或可观察的实体来探索意图预测,例如来自视觉数据的轨迹、行人的动作、人体姿势和时空线索以及姿势数据。还探索了基于未来场景预测的动作分类和使用马尔可夫属性的预测意图,其中隐藏状态是行人意图。机器学习方法也被用于将意图建模为二元分类问题,其中输出是穿越/不穿越,并且这些方法在最先进的行人行为数据集上得到了验证。
在这项工作中,作者简要讨论了文献中关于行人行为定义的空白,并提出了一种分类法来描述与自动驾驶场景相关的各种行为水平。作者提出了一种用于行人轨迹和行动预测的多任务序列到序列Transformer 编码器-解码器架构,并使用相同的输入和任务与中提出的最先进的PV-LSTM模型进行了比较。使用真值信息评估了作者的方法在模拟(CARLA)、JAAD、数据集上的有效性。最后,作者在大学校园的自动驾驶接驳车上收集相机数据,并使用基于视觉的行人跟踪信息作为输入对这两个模型进行端到端评估。YOLOv5检测器和DeepSORT分别用于行人检测和跟踪。
分类
尽管文献中有大量工作,但行人行为缺乏一致的定义和分类。此外,现有的工作使用动作识别、轨迹估计、基于姿势的运动预测作为实际行人意图的替代。为此,作者在这项工作中提出并讨论了行人行为特征的分类法。下图1显示了该分类的高级流程图:
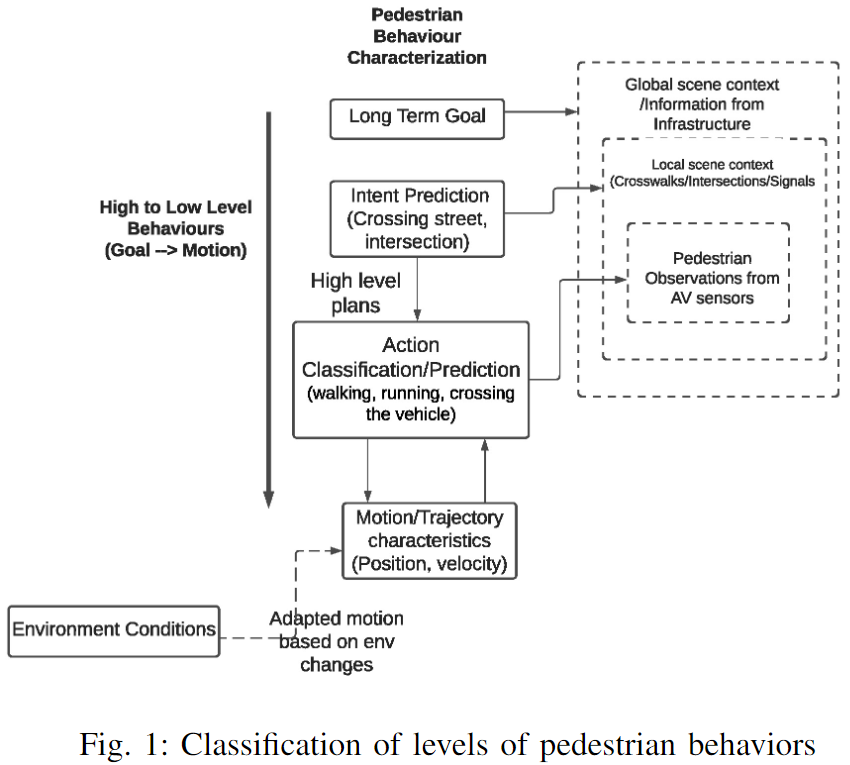
在交通场景中,行人可以有长期目标或目的地、短期目标/行动(例如穿过十字路口或街道)和即时行动(例如在街道上的车辆附近穿过)。通常,行为特征包括对行人计划做什么或他们的目标(意图)是什么、行人将要做什么(行动)、行人将走什么样的轨迹(运动)等问题的回答。这些之间存在层次因果关系,行人根据其高层计划或意图采取行动,这些行动的运动特征可能会随着交通/道路状况的变化而变化。对环境/交通场景信息的需求随着所需的行为估计水平成比例地增加。根据作者的分类法,真实意图预测(过街/不过街)需要局部场景上下文。如果没有这些信息,区分行人过街的意图和行人在车辆前面过街的行为是不明确的。由于行人行为取决于许多因素,如交通、环境和个人行人特征,作者建议行为估计应明确说明这些估计适用的范围。例如,考虑一名在公共汽车站等候的行人,如果他们踏上道路检查公共汽车,这可能被解释为一辆接近的自车按照基于轨迹的方法进行的穿越行为,但这并不能反映行人的总体目标或意图。因此,作者将具有运动特征的动作定义为相对于自车的低级行为,在某种程度上,其特征可以仅通过行人观察来确定,并且对自动驾驶汽车的安全路径规划和导航至关重要。意图是一种高级行为表征,不能直接观察到,也不能简单地使用行人的轨迹来估计,但需要从过去的行为、过去的动作、上下文场景信息等中进行更深入的推断。在本文中,作者重点关注行人(过街/不过街)相对于单车的低级行为表征,由于上下文场景信息和来自过去动作的推断既不是事先已知的,也不是估计的。
方法
问题公式化
作者将行人动作和轨迹预测公式化为多目标学习问题。让行人在时间t的位置和速度分别表示为pt和st。让行人在时间t的动作表示为,
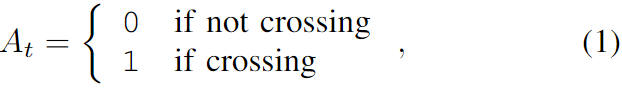
在时间t,给定长度为m+1的历史位置和速度轨迹,表示为,
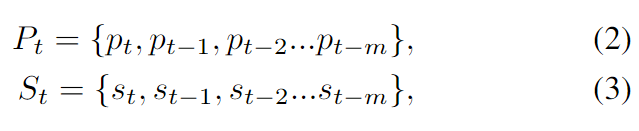
学到的概率分布为:
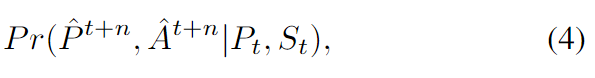
$\hat P^{t+n},\hatA^{t+n}P_t,S_t处预测接下来的n个位置和动作。
接下来,作者讨论了所提出的TF-ed和PV-LSTM模型的高级体系结构细节,包括模型输入和输出,然后分别描述了这两种体系结构。
架构
在这项工作中,作者提出了多任务Transformer 编码器-解码器(TF-ed)架构,并将其性能与PV-LSTM模型的LSTM编码器-解码器架构(LSTM-ed)进行了比较。整个TF-ed框架的高级图如下图2a所示。
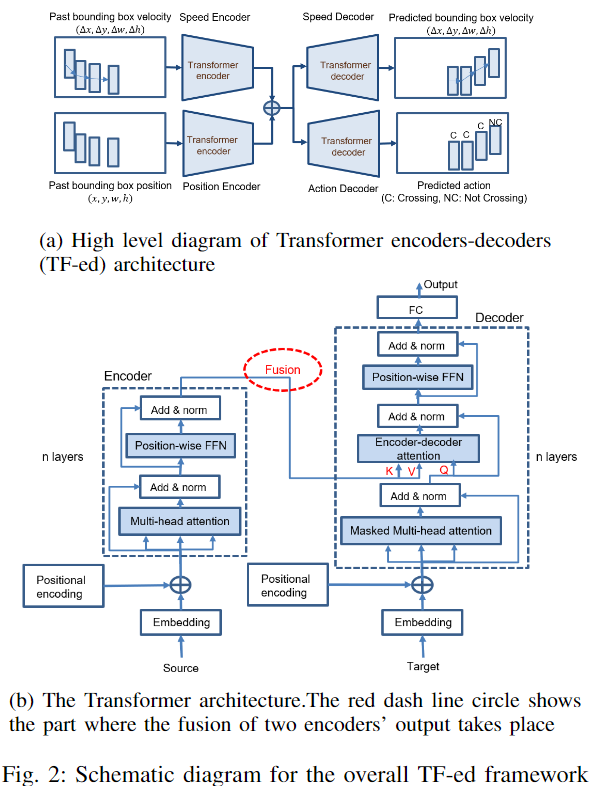
对于LSTM ed和TF-ed,通过相应的编码器对观察到的行人速度和位置的序列进行编码。高维隐藏特征在两个编码器的输出端相连,并传递给速度和动作解码器。最后,解码器的输出分别被反向投影到维度为4和2的预测速度和动作的序列。
1) 模型输入和输出:
行人周围的空间边界框坐标用于对行人的位置进行编码。bbox坐标通常可以从最先进的轨迹数据集中以真值的形式获得,或者可以作为实时多目标跟踪算法的输出获得。此外,行人的速度是另一个特征输入,它是通过减去同一行人的两个连续帧的bbox坐标而获得的。形式上,对于行人i,给定一系列历史位置和速度观测值(方程(2)和(3)),其中是bbox中心坐标(x,y,宽度,高度),是相应的速度。
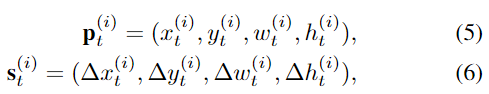
对于时间实例t+1到t+n,作者预测行人的速度和未来动作的序列,可以根据预测的速度来计算未来位置。
2) Transformer编码器解码器(TF-ed):
TF网络最早在[23]中提出用于自然语言处理。与LSTM一步一步处理输入序列不同,TF一次处理整个嵌入序列,这使得能够进行并行训练,见上图2b。TF由一个编码器和一个解码器组成。源序列和目标序列嵌入在被馈送到基于自注意堆叠模块的编码器和解码器之前被添加了位置编码。
a) 输入嵌入 :速度和位置源和目标输入首先通过完全连接层嵌入到更高的D维空间中。
b) 位置编码 :通过添加相同时间的位置编码掩码PE,每个输入嵌入都带有时间戳,PE计算为:
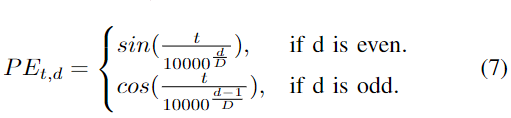
其中d表示整个d维嵌入的维度。
c) 多头自注意力:网络捕捉序列非线性的能力主要在于注意力模型。输入被嵌入到查询(Q)、键(K)和值(V)向量中。Q和K用于计算关注矩阵,该关注矩阵通过缩放的点积和softmax层反映输入序列之间的相关性。然后使用注意力矩阵对V进行加权,以确保输出的每一部分都与序列中其他部分的时间信息合并,如下所示:
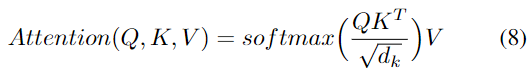
具体而言,在编码器-解码器注意力层中,Q来自前一解码器层的输出,K和V来自编码器输出。在解码器自关注中,Q、K和V都来自前一解码器层的输出。然而,解码器中的每个位置被允许仅关注解码器中直到该位置的所有位置,从而确保预测仅取决于已经生成的输出预测。在评估期间,由于与使用真值数据的训练不同,不存在真值目标,因此解码器的先前预测输出被迭代地用作新目标输入。
作者提出的TF-ed的总体架构如上面的图2a所示。两个TF编码器并行处理速度和位置输入,两个编码器的K和V输出通过级联进行融合,然后传递到单独的解码器速度预测和行动预测。预测的速度输出被扩展为用于计算行人未来轨迹的输出序列。
3) LSTM编码器-解码器(LSTM-ed):
LSTM能够从时间序列数据中学习长期相关性。除了具有递归神经网络的特性外,LSTM还包括一个专门构建的存储单元,它由一个输入门、一个遗忘门和一个输出门组成,见下图3。
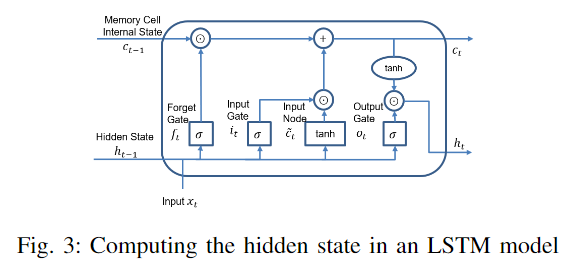
这些门控制并保护每个存储器单元中的信息流。给定一个输入向量。
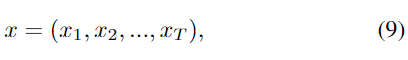
每个LSTM存储单元的隐藏层输出ht根据以下方程组在每个时间步长t从t=1到t=t进行计算和更新:
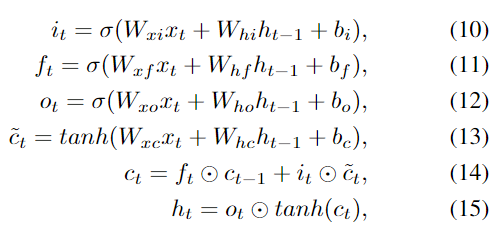
其中W和b是三个门和存储单元的权重矩阵和偏差,σ(x)是S形函数,
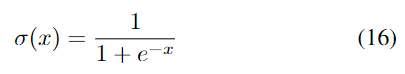
用于比较的整体LSTM ed架构来自论文[12]。给定观察到的速度和位置的输入序列,速度编码器和位置编码器在时间步长t生成相应的速度和姿势隐藏状态,这些隐藏状态被连接到包含所有特征的单个隐藏状态,然后分别传递给解码器用于轨迹和动作预测任务。
实验评估
作者评估了第三节中描述的方法,即LSTM ed和TF-ed架构,涵盖三种行动和轨迹预测场景:(1)CARLA模拟器中的模拟场景(2)最先进的JAAD数据集(3)在大学校园驾驶场景中的班车上收集的数据。通过CARLA和JAAD数据集,作者旨在单独评估行动和轨迹预测的性能,从而使用真值(GT)数据作为两个模型的输入。
然后,作者在自动驾驶班车上收集的数据上进行了评估,其中通过基于视觉的跟踪算法获得的行人数据被用作模型的输入。端到端评估(图像输入到动作和轨迹预测)对于验证该方法在存在噪声条件和潜在跟踪误差/故障的情况下对自动驾驶汽车的真实世界导航解决方案的有效性至关重要。
评估设置
a)CARLA :CARLA是一个用于自动驾驶研究的开源模拟器。在作者的工作中,CARLA(Town10HD)中的城市驾驶环境被用作模拟环境。下图4b显示了这种环境的鸟瞰图。

自车车载摄像头,分辨率为1920x1080,视野为90◦,在人行横道附近延伸(如图4a所示的相机视图),一个行人及其控制器在右侧人行道上一起延伸。行人沿着人行道行驶,在人行横道附近停了一会儿,然后开始穿过,直到到达路的另一边。在模拟过程中,GT框和相应的动作标签(如穿越/不穿越)被编程为自动生成。整个序列包含145个带有GT框和行人动作标注的帧。
b) 联合注意力自动驾驶(JAAD)数据集 :关注城市驾驶环境中自动驾驶背景下的联合注意力。该数据集旨在研究行人和驾驶员的行为,例如行人何时穿过/不穿过。JAAD包含在各种自然场景和光线条件下,以30 FPS、分辨率为1920x1080像素的前置摄像头拍摄的视频。共有346个视频,82032帧,视频长度从60帧到930帧不等。2793名行人被标注为bboxes,其中686人有行为标签,包括行走、站立、过街、看(交通)等动作。在数据集中,行走行为标注包括子行为:“边过边走”或“边走不过”。对于此评估,作者对于该评估,作者只使用与穿越行为相关的标签,穿越行为是走路的一个子集,用于动作预测,以便保持与[12]中相同的数据处理,以实现比较的一致性。
c)实时数据 :用于实时数据收集的车辆是从Autonomous Stuff购买的Polaris GEM e6,如下图5a所示。车辆配备了GPS、激光雷达和安装在车顶前部中央的摄像头。所有控制和传感软件都使用机器人操作系统(ROS)集成,数据在德克萨斯农工大学校园以15 FPS的帧速率收集。班车是以每小时10英里的平均速度手动驱动的。该数据由298帧组成,分辨率为1296x728像素,涵盖了校园内典型的行人过街/不过街场景。这些数据是故意在晚上不太理想的照明条件下收集的,以进行逼真的测试。

实现细节
1)数据预处理:用于动作预测的模型输入以行人的bbox像素坐标(x,y,w,h)的形式存在。对于JAAD和CARLA评估,使用了bbox坐标的真值。此外,从数据标注中提取行人ID和行为标签。一旦得到了所有帧中每个行人的 bbox 坐标和相应动作类的整个序列,该序列进一步划分为子序列,每个子序列包含长度为 O 的观测序列和对应的长度为 T 的真值数据序列。
对于自动驾驶班车数据评估,将基于视觉的检测/跟踪算法集成到pipeline中,并将跟踪输出用作动作预测模型的输入,如下图6所示。
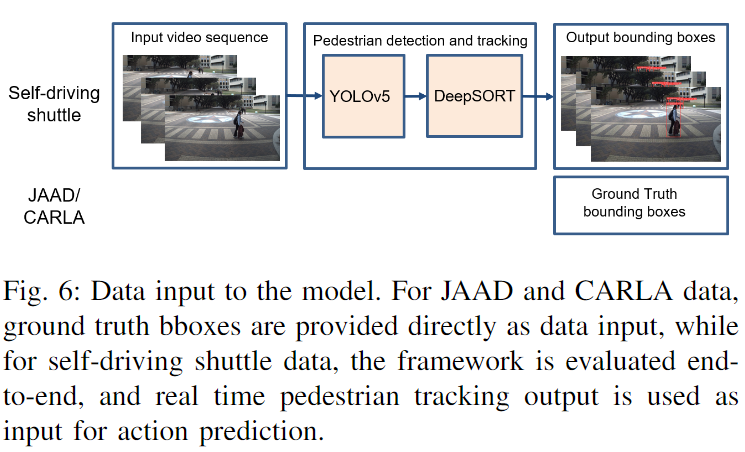
YOLOv5和DeepSORT算法用于检测和跟踪视频序列中的多个行人。由于研究中只需要行人的邮箱信息,因此当基于在YOLOv5的MS COCO数据集上预训练的权重crowdhuman-yolov5m和DeepSORT的osnet x1 0进行推断时,将要检测的对象类别设置为0(人)。
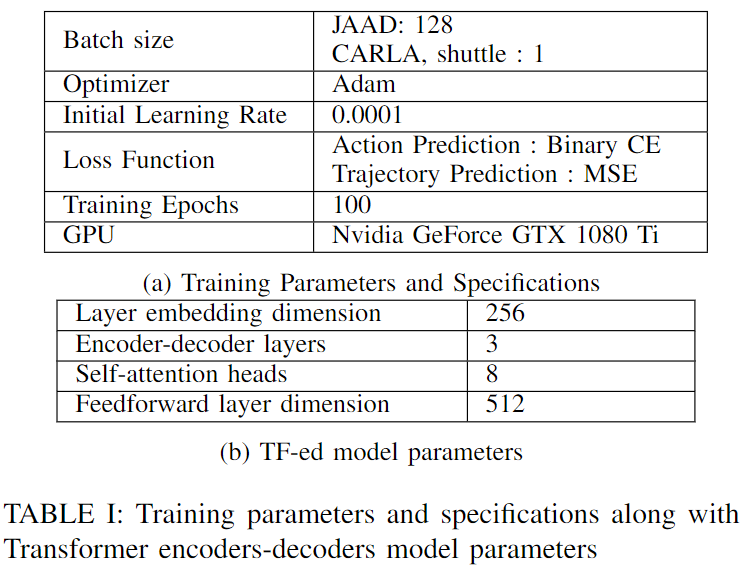
2) 训练和测试 :LSTM-ed和TF-ed模型都在JAAD训练和验证集上进行了训练,然后分别在CARLA模拟、JAAD测试集和自动驾驶班车数据上进行了评估。然而,由于没有真值标注,对自动驾驶班车数据的评估只能提供定性结果。JAAD数据集分为训练、验证和测试,比例为0.7:0.1:0.2。对于LSTM训练,作者采用了[12]中的参数,隐藏状态的维数为256,编码器-解码器层数为1。TF-ed架构的附加参数以及所有数据集的训练规范总结在下表I中。Pytorch库用于实现。
评估度量
bbox中心坐标的平均位移误差(ADE)和最终位移误差(FDE)被用作评估批量用于轨迹预测的模型参数度量(等式(17)、(18)),而精确度(等式(19))被用作动作预测的度量。ADE测量预测相对于真值的总体拟合,对每个时间步长的差异进行平均。
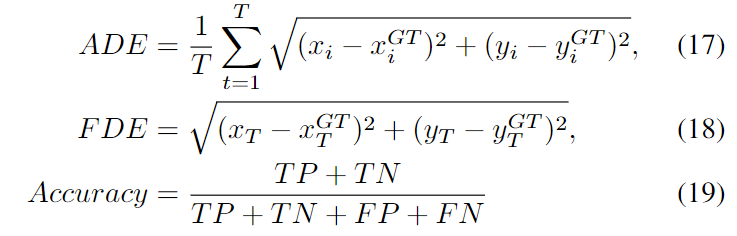
ADE是预测期间所有预测和真值的平方平均数误差(RMSE) ,而 FDE 是预测序列末尾的最终预测和相应的真值之间的 RMSE。本文的例子中,ADE 和 FDE 都是以像素为单位的。
结果和讨论
检测和跟踪
自动驾驶接驳数据的行人检测和跟踪样本输出帧如上图5所示,其中图像帧中的所有行人都被成功检测和跟踪,如图5b所示。图5c显示了未检测到路中央行人的故障场景(插图显示了行人的近景)。特别是在道路两侧树木覆盖严重的道路上观察到了上述间歇性检测故障,从而进一步影响了已经不太理想的夜间照明条件。
动作和轨迹预测
JAAD和CARLA测试集上的动作预测精度结果以及轨迹预测的ADE和FDE结果总结在下表II中,其中ADE和FDE是以批量方式计算的。
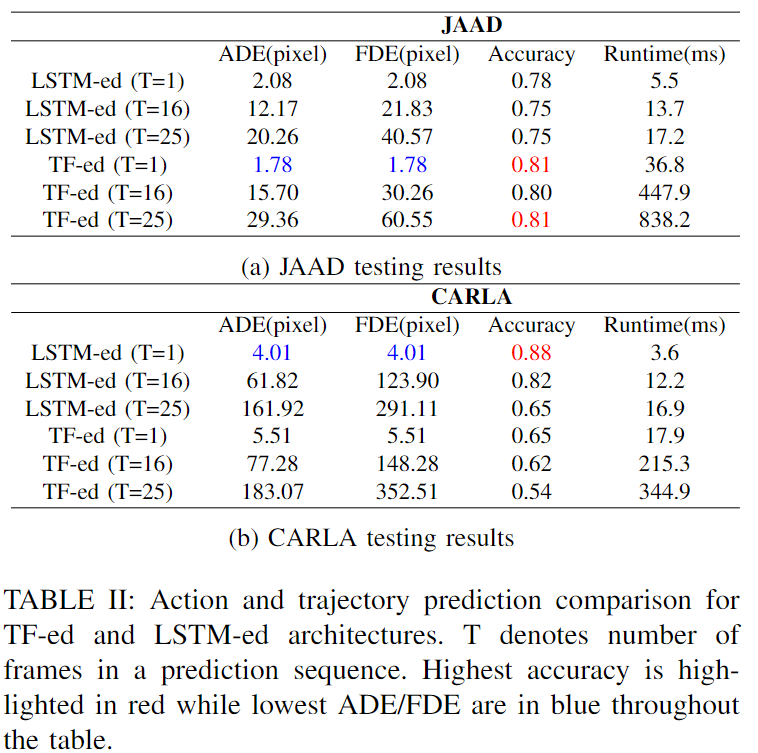
还报告了推理运行时在评估中只包括LSTM ed和TF-ed,因为其他模型由于不同的动作定义、使用的数据、pipeline等而无法直接比较。给定长度为O的观测值,作者预测下一个T帧的动作和轨迹,并将其称为长度为T的预测序列。报告了O=16、T=1、O=T=16和O=T=25的结果。特别是,TF-ed(T=1)模型使用1层1个head进行训练,而其他模型使用3层8个head。对于JAAD测试集,当只进行一次预测时,TF-ed模型在两项任务中都优于LSTM-ed模型,其中ADE和FDE降低了14.4%,准确率提高了近4%。随着预测序列长度增加到16和25,LSTM ed的ADE和FDE较低,但在动作预测方面不如TF ed准确。特别地,通过TF-ed,当T=25时,动作预测精度提高了7.4%。对于CARLA数据评估,LSTM-ed在所有情况下都具有更好的性能。一般来说,LSTM-ed的运行时间比TF-ed的要短得多。下图8显示了TF-ed模型的三个评估场景中的5组行动和轨迹预测示例,时间步长从左到右。

在图8a中,一名行人首先在路边等待,持续几秒钟,然后在第二帧中开始穿越,车辆同时靠近。图8b模拟了一个更远距离的人行横道,而自我车辆停在一段距离的人行横道后面。从结果中可以看出,尽管动作预测是正确的,但ADE和FDE随着预测序列的时间步长逐渐成比例地增加。这也在图8e所示的自动驱动接驳数据结果中观察到。这可以通过下图7所示的趋势来解释,图7显示了随着预测时间步长的增加而增加的累积误差。

换句话说,每个预测序列的第一个和最后一个预测帧分别具有最低和最高的ADE/FDE。应该注意的是,与图8a和8d相比,图8e中的误差偏移最为显著。这是因为只有图8e包括从同一预测序列采样的帧,从而反映了误差逐渐增加的更显著影响,而其他示例的图像帧是来自四个不同预测序列的第一个预测样本,以包括更长的行人轨迹,因此没有显示出误差逐渐增加。此外,作者观察到,对于图8e,行人在运动的前几秒没有被检测到并被稳健地跟踪,这解释了行动预测的延迟。
总之,只有bboxes坐标作为输入,当预测序列长度增加时,LSTM ed模型在行人轨迹预测任务上表现更好,而TF ed模型在步行动作预测任务上则表现更好。此外,作者还观察到了一些有趣的场景,这些场景值得讨论,以研究行人行为预测方法在安全自动驾驶中的有效性和局限性。例如,在下图9a中,有两名行人在自车的右侧穿过,而不是在车辆的路径上。在十字路口右转的车辆经常会遇到这种情况。在图9b中,当车辆靠近时,行人正对角穿过(没有人行横道)。在这两种情况下,算法都无法预测正确的动作。此外,在实时端到端评估中,跟踪ID切换是一个主要挑战其不利地影响下游行人动作和轨迹预测任务。在相机视野有限的情况下,在行人进入框架并开始穿过之前,车辆及时做出反应的缓冲时间有限,因为观察的积累需要时间。

这些挑战和场景强调了对车-人交互进行更详尽的测试和数据收集的必要性,尤其是在大学校园和有无信号穿越口的住宅区等地区。对于安全的自动驾驶,至关重要的是,对行人行为预测方法进行端到端的实时评估(例如:跟踪故障和准确性对行动预测准确性的影响),以便自动接驳或车辆能够稳健地预测短期行动,即使是在行人可能不直接在车辆前方的非平凡情况下,可能具有与通常在人行横道上观察到的轨迹轮廓略微不同的轨迹轮廓。
结论
作者提出了一个Transformer编码器-解码器多任务模型,用于城市驾驶场景中的行人轨迹动作预测,以实现安全的自动驾驶。该方法与LSTM编码器-解码器模型进行了比较,并使用真值数据在模拟、公开可用的JAAD数据集上进行了评估。这一点得到了对自动驾驶接驳数据的端到端pipeline评估的补充,其中该框架与基于视觉的行人检测和跟踪算法相集成。还提供了行人行为特征的分类法,并讨论了不同行为水平之间的层次因果关系。通过实验结果,作者得出结论,当涉及到自动驾驶接驳最后一英里连接驾驶场景时,纯粹依赖自车观察的短期行动预测方法存在局限性。在跟踪和预测多个行人的行动时跟踪ID切换也是一个挑战,这使得车辆几乎没有时间进行安全决策。为此,未来工作的一个有趣方向是探索群体行动与个体行人行动,并研究群体行动预测与仅针对关键行人识别和预测行动的权衡。
参考
[1].Learning Pedestrian Actions to Ensure Safe Autonomous Driving
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称