SIEM系统有许多专家编写的规则来帮助追踪可疑的行为。然而,有许多攻击场景无法用严格的规则来描述,因此可以有效追踪。
考虑到SIEM系统每天处理的数据量,以及分析这些数据(旨在找到攻击者的行为)的具体挑战,今天应用机器学习是必要的,而且非常有效。
任务描述
在这个具体案例中,我们解决了以下挑战:一旦攻击者进入IT基础设施,他们会使用各种战术和技术来获得立足点并进一步推进,他们的所有活动都会以这样或那样的方式留下痕迹,随后会找到进入SIEM系统的方式。
大多数战术的使用将被记录在Windows日志事件中,这些事件与进程的启动有关(Sysmon EventID 1和Windows安全事件ID 4688)。抛开不必要的信息,我们的初始数据可以表示为以下表格:
| User name |
Process name |
| Ivanov Ivan |
cmd.exe |
| Petrov Petr |
outlook.exe |
| Sidorov Nikolay |
whoami.exe |
我们可以看到在基础设施中运行的所有进程和用户的列表,它们在谁的账户下运行。对我们来说,重要的是教会SIEM系统识别哪些进程对某个特定用户来说是正常的,哪些是不典型的--异常的。而且,正如你可能猜到的,一个用户的异常进程对另一个用户来说可能是完全正常的。
有了这一功能(检测用户异常进程的能力),我们将能够在早期阶段发现许多攻击企图。例如,想象一下两种情况:一个会计师在他的工作站上运行实用程序来查询活动目录域服务信息,而一个过去只用办公软件工作的秘书突然运行会计软件。这可能没什么,会计师的电脑只是一个系统管理员坐下来诊断网络问题,而秘书则得到了额外的职责。但也可能有另一种解释--该账户已被入侵者接管,并被侦查以获得晋升。或者这个秘书实际上是一个内部人员,正试图从公司偷走数据库。
这样的案例当然需要SIEM操作人员的关注和阐述,其中要考虑情况的背景和第三方事件,与特定事件的触发无关。
解决问题的基本方法
解决这个问题的方法有哪些?首先想到的是控制一个特定用户启动的所有进程,并检查它们对这个用户的允许性。
乍一看,这样一个简单的算法似乎可以解决这个问题。但当我们测试它时,我们得到了以下情况。
想象一下,我们组织里有一个程序员,他喜欢在他最喜欢的IDE--Visual Studio Code里写代码。有一天,一个朋友建议他试试另一个工具--PyCharm,他听从了他的建议。从我们算法的角度来看,有一个异常,一个非典型的行为。我们的用户从来没有在这个程序中工作过。但从SIEM操作员的角度来看,没有什么需要注意的地方。这是 false positive - 一个假阳性。而且会有很多这样的情况,这将使我们的算法的有用性降低到零。
我们如何解决这个问题呢?一个想法立即出现在脑海中:让我们不要用具体的应用程序来操作,而是用它们的功能目的来操作。让我们对所有的应用程序进行分类,并将它们组合成组。例如,PyCharm和Visual Studio Code将位于一个名为 "开发工具 "的组中,Microsoft Word和Microsoft Excel将位于 "办公程序 "组中。
对用户证书也可以这样做。我们的系统不会将用户视为个人,而是将其视为一组功能角色。例如,一个人是开发人员和兼职系统管理员,另一个人是会计。而系统将了解到,开发人员使用开发工具是可以的,会计人员使用会计软件也是可以的。而他们都使用办公软件也是可以的。
这种方法可以奏效,但不幸的是,只有在IT部门不断更新员工名单和他们的职责的公司里才行得通。此外,软件清单必须被跟踪和更新,这也是一个挑战,因为许多机构使用特定的或自行开发的软件。
一个机器学习的方法
因此,当人们发现标准的严格算法需要付出太多的努力时,是时候使用机器学习的 "魔法 "了。我们需要应用一种算法,它能真正 "理解 "每个用户的功能职责和每个具体程序的目的。
这看起来很复杂。但事实证明,我们的需求完全可以由一类叫做推荐系统的算法来满足。
推荐系统是一类机器学习算法,旨在向用户推荐产品或内容。
正如你可能猜到的那样,推荐系统在我们的生活中很普遍。只要你想用新的内容来保持用户的注意力,或者推荐一个新的产品来购买,都可以使用一种算法。
有两种方法来构建推荐系统:
• content-based;
• collaborative filtering.
Content-based 的技术需要额外的信息来工作。在这种情况下,有必要用一组属性来描述每个产品或用户。例如,在为用户选择一部电影的情况下,这可能是类型、主要角色的演员、发行年份、制作国家。正如我们所看到的,这种类型的推荐系统并不能满足我们在这个特定任务中的要求。
另一方面,collaborative filtering 技术只使用关于用户对某一产品的喜欢程度的信息。我们不需要收集每一个属性的数据。
让我们仔细看看协作式过滤是如何工作的。让我们想象一下,一个高级产品已经被一小部分购买其他高级产品的用户所购买。向其余的这些用户推荐该产品是有意义的。
很明显,对相同产品给予类似评价的人有类似的品味和偏好。而反过来也是如此:如果某组用户喜欢某个内容,那就说明它的特点很好。collaborative filtering 是基于这些简单的原则。
我们训练模型的任务是为每个用户和产品获得向量,当它们彼此相乘时,将给我们提供用户在购买时将给予的产品评级。
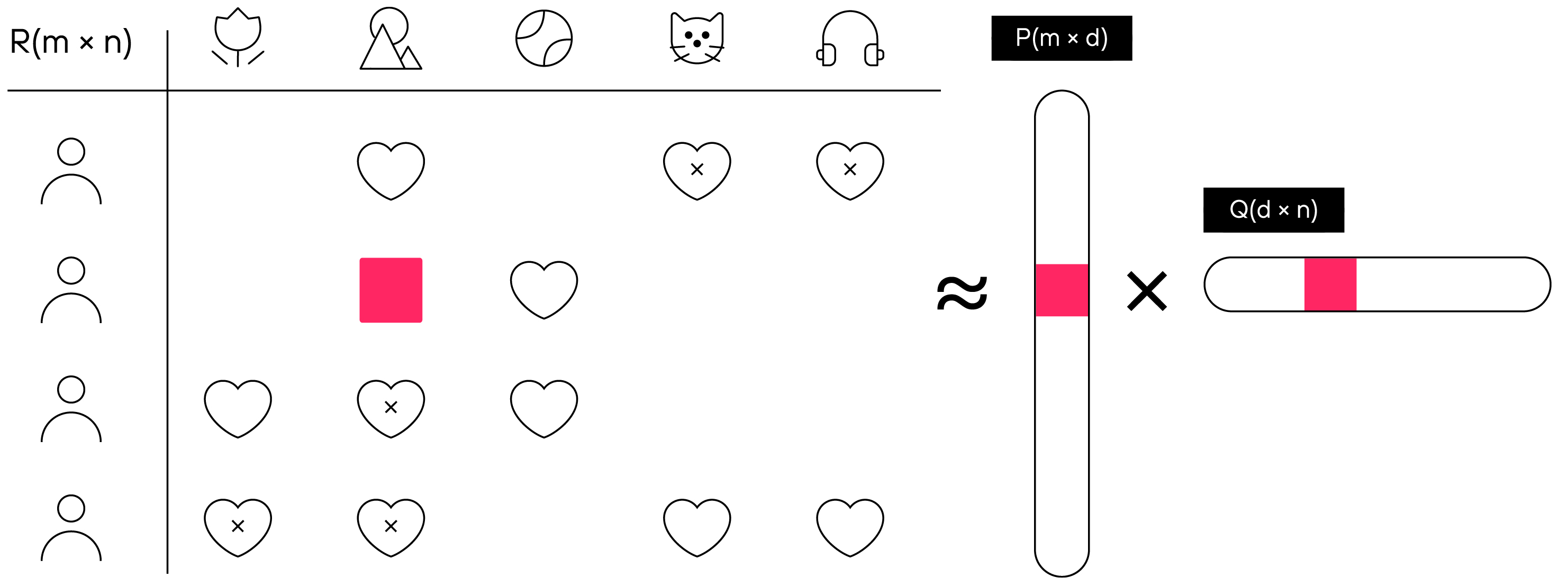
collaborative filtering 技术的原理,其中P是维数为m×d的用户向量矩阵,Q是维数为d×n的产品向量矩阵。
主要问题是,如果我们没有任何关于用户或内容的信息,我们如何制作这些矢量?但这只是乍看之下。我们有他们的评级历史,这对我们来说已经足够了。
例如,我们可以通过使用 alternating least squares(ALS)算法来做到这一点。在不深入研究数学的情况下,我们可以将其工作解释如下:我们固定一个用户向量的矩阵,对其进行优化并改变内容矩阵。我们使用损失函数的导数(梯度)并向与梯度相反的方向移动--在我们想要的方向,即 "真相 "所在的地方,我们的预测不会错。然后我们固定内容矩阵,对用户矩阵做同样的处理。我们重复多次,一步一步地接近期望值,"训练 "我们的模型。
通过这种方式,我们将得到我们需要的向量。当然,如果我们拿着一个具体的向量,从人类的角度来看,我们将无法理解任何东西。对我们来说,它将只是一组数字。但这个向量中的每个数字以及这些数字之间的相对位置将是有意义的,并反映出真实情况。
一个合理的问题出现了:我们如何使用推荐系统来发现异常情况?
符合逻辑的是,如果一个用户运行一个进程,他们就会喜欢这个进程。如果我们从推荐系统的角度讲,这个过程将有一个高分。
而相反的情况是:如果这个过程是不正常的,如果这个特定的用户和其他类似的用户从来没有运行过这个或那个过程,推荐系统将给出一个低分--它将说,我们的用户不喜欢这个过程。因此,他/她启动的东西,他/她喜欢,尽管他/她不应该(根据推荐系统)--这是一个异常情况。
这种方法在测试过程中被证明是很好的。事实证明,用户向量很好地描述了用户的功能职责,而应用向量在描述应用的功能集方面做得很好。用户向量很好地反映了现实,这一点可以从以下的例子中看出 例子。
让我们把所有的用户向量,反映在一个二维空间中。我们得到一个这样的画面。

用户账户的二维显示
一个点是一个特定的用户,点的颜色是他或她的职能职责,这是从人员配置表中提取的。我们可以看到,来自同一部门的用户被并排分组,这意味着我们的模型训练有素,其内部状态反映了现实。当然,在这种情况下会有例外,但它们与特定人的具体行为有关。
另一个需要注意的重要视角特征是这个图上的点(用户)的移动。如果一个用户从事大致相同的活动,他们将在空间中处于相同的位置。然而,如果在他的账户下开始了非典型的活动,我们将看到点的急剧 "跳跃"。制作一个方便的工具来检测和分析这样的 "跳跃",对保护运营商来说是很有用的。
现在让我们看看该模型的传统使用在实践中可能是什么样子的。

对一个用户的模型预测的时间系列
这张图绘制了一个特定用户的模型读数。y轴上的数值越低,用户的行为就越不 "正常"。在7月7日之前,该用户的行为没有任何异常 - 异常值没有低于0.9。然而,7月11日,一个入侵者掌握了这个账户--模型开始产生低值。
结论
在这个实验中,公用事业被用来对基础设施进行侦查。这当然不是一个用户的典型行为。我们应用了简单的、基本的推荐人系统。为了进一步发展这个想法,我们可以朝着使用基于内容和协作过滤的联合推荐系统的方向发展,我们还可以实现深度学习系统。从我们的实验中得出的主要结论是,使用推荐系统来寻找异常情况有很大的潜力,可以帮助解决广泛的网络安全问题。