从 GPT-3 和 ChatGPT 等大型语言模型 (LLM) 的最新进展中可以看出,在技术行业引起了很大的关注。这些模型对内容生成非常强大,但它们也有一些缺点,例如偏差1 和幻象2。LLM在聊天机器人开发方面特别有用。
基于意图的聊天机器人
传统聊天机器人通常是基于意图的,这意味着它们被设计为响应特定的用户意图。每个意图由一组样本问题和相应的响应组成。例如,“天气”意图可能包括类似“今天天气如何?”或“今天会下雨吗?”这样的样本问题,并且可能输出“今天将是晴天”的响应。当用户提出问题时,聊天机器人将其与最相似的样本问题匹配意图,并返回相应的响应。

然而,基于意图的聊天机器人也有自己的问题。其中一个问题是,它们需要大量特定的意图才能给出特定的答案。例如,用户说“我无法登录”、“我忘记了密码”或“登录错误”等话语可能需要三个不同的答案和三个不同的意图,尽管它们都非常相似。
GPT-3如何帮助
这就是GPT-3可以发挥的特别用处。每个意图可以更广泛,利用您的知识库文档。知识库 Knowledge Base 是存储为结构化和非结构化数据的信息,可用于分析或推断。您的知识库可能由一系列文档组成,解释如何使用您的产品。
因此,每个意图与文档相关联,而不是一组问题和特定答案,例如,一个“登录问题”的意图,一个“如何订阅”的意图等等。当用户询问有关登录的问题时,我们可以将“登录问题”文档传递给 GPT-3 作为上下文信息,并为用户的问题生成特定的响应。
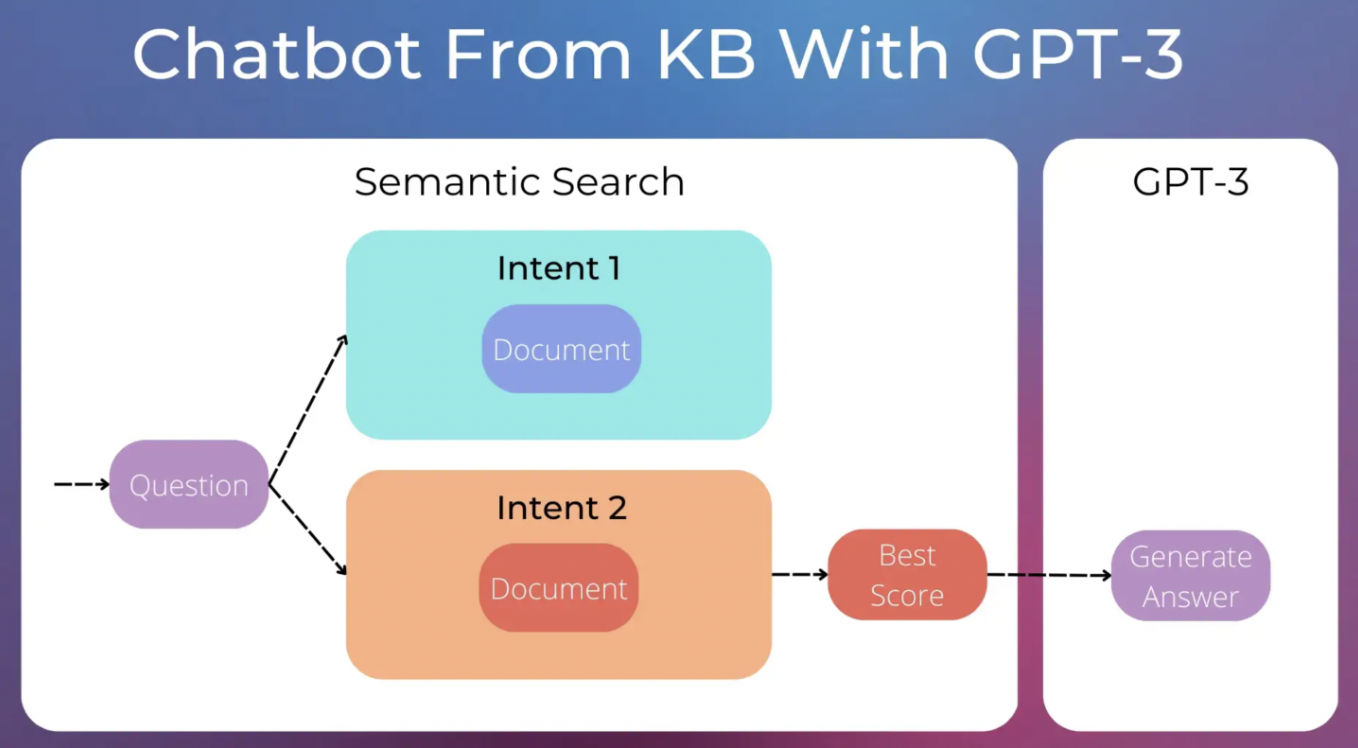
这种方法减少了需要处理的意图数量,并允许更好地适应每个问题的答案。此外,如果与意图关联的文档描述了不同的流程(例如“在网站上登录”的流程和“在移动应用程序上登录”的流程),GPT-3可以在给出最终答案之前自动询问用户以获得更多的上下文信息。
为什么不能将整个知识库传递给GPT-3?
今天,像GPT-3这样的LLM模型的最大提示的长度约为4k令牌(对于text-davinci-003模型),也就是2048个汉字,这很多,但不足以将整个知识库馈入单个提示中。 LLM由于计算原因具有最大提示的限制,因为使用它们生成文本涉及多个计算,随着提示大小的增加,计算量也会迅速增加。
未来的LLM可能不会有这种限制,同时保留文本生成能力。然而,就目前而言,我们需要一个设计解决方案来解决这个问题。
如何使用GPT-3构建一个聊天机器人
聊天机器人的流程可以分为以下两个步骤:
首先,我们需要为用户的问题选择适当的意图,即我们需要从知识库中检索正确的文档。 然后,一旦我们有了正确的文档,我们就可以利用GPT-3为用户生成适当的答案。在这样做的过程中,我们需要精心制作一个良好的提示。
第一步可以使用语义搜索semantic search解决。我们可以使用sentence-transformers库中的预训练模型,轻松地为每个文档分配一个分数。分数最高的文档将用于生成聊天机器人答案。

使用 GPT-3 生成答案
一旦我们有了正确的文档,我们需要创建一个好的提示,以便将其用于GPT-3生成答案。在以下实验中,我们将始终使用temperature为0.7的text-davinci-003模型。
为了制作提示,我们将尝试使用以下内容
- 角色提示: 一种启发式技术,为AI分配特定的角色。
- 相关的知识库信息, 即在语义搜索步骤中检索到的文档。
- 用户和聊天机器人之间最后一次交换的消息. 这对于用户发送的未指定整个上下文的消息非常有用。我们将在后面的例子中看到它。请查看此示例 了解如何使用GPT-3管理对话。
- 最后, 用户的问题.

让我们使用角色提示技术开始我们的提示。
As an advanced chatbot named Skippy, your primary goal is to assist users to the best of your ability.然后,假设语义搜索步骤从我们的知识库中提取了以下文档。所有文档都描述了类似于Instagram的虚构产品VideoGram的工作方式,但仅用于视频。

我们可以在提示中这样添加它的内容。
As an advanced chatbot named Skippy, your primary goal is to assist users to the best of your ability.
START CONTEXT
Login to VideoGram from Website
1. Open your web browser and go to the VideoGram website.
2. Click on the “Login” button located in the top right corner of the page.
3. On the login page, enter your VideoGram username and password.
4. Once you have entered your credentials, click on the “Login” button.
5. You should now be logged in to your VideoGram account.
Login to VideoGram from Mobile App
1. Open the VideoGram app on your mobile device.
2. On the main page, tap the “Login” button located in the bottom right corner.
3. On the login page, enter your VideoGram username and password.
4. Once you have entered your credentials, tap the “Login” button.
5. You should now be logged in to your VideoGram account.
END CONTEXT最后,我们需要将对话和用户问题添加到提示的末尾,就像以下示例中那样。
As an advanced chatbot named Skippy, your primary goal is to assist users to the best of your ability.
START CONTEXT
Login to VideoGram from Website
1. Open your web browser and go to the VideoGram website.
2. Click on the “Login” button located in the top right corner of the page.
3. On the login page, enter your VideoGram username and password.
4. Once you have entered your credentials, click on the “Login” button.
5. You should now be logged in to your VideoGram account.
Login to VideoGram from Mobile App
1. Open the VideoGram app on your mobile device.
2. On the main page, tap the “Login” button located in the bottom right corner.
3. On the login page, enter your VideoGram username and password.
4. Once you have entered your credentials, tap the “Login” button.
5. You should now be logged in to your VideoGram account.
END CONTEXT
SKIPPY: Hello, I’m Skippy! How can I help you?
USER: I can’t find the login button.
SKIPPY:将此提示传递给GPT-3,我得到了以下生成的答案。
No problem! On the website, the login button is located in the top right corner of the page. On the mobile app, the login button is located in the bottom right corner. Let me know if you need any further assistance!请注意,生成的答案中的信息来自知识库文档。
用GPT-3消歧用户问题
我们来试试更模糊的用户输入,比如“无法登录”。这是完整的提示。
As an advanced chatbot named Skippy, your primary goal is to assist users to the best of your ability.
START CONTEXT
Login to VideoGram from Website
1. Open your web browser and go to the VideoGram website.
2. Click on the “Login” button located in the top right corner of the page.
3. On the login page, enter your VideoGram username and password.
4. Once you have entered your credentials, click on the “Login” button.
5. You should now be logged in to your VideoGram account.
Login to VideoGram from Mobile App
1. Open the VideoGram app on your mobile device.
2. On the main page, tap the “Login” button located in the bottom right corner.
3. On the login page, enter your VideoGram username and password.
4. Once you have entered your credentials, tap the “Login” button.
5. You should now be logged in to your VideoGram account.
END CONTEXT
SKIPPY: Hello, I’m Skippy! How can I help you?
USER: Can’t login
SKIPPY:GPT-3试图更好地理解用户的问题,给出了以下回答。
I’m sorry to hear that. Can you tell me if you are trying to login via the VideoGram website or mobile app?接下来,这是完整的对话内容。为了方便查看,这里省略了提示的其他部分。
USER: Can’t login
SKIPPY: I’m sorry to hear that. Can you tell me if you are trying to login via the VideoGram website or mobile app?
USER: Mobile app
SKIPPY: OK, no problem. To login via the mobile app, open the VideoGram app on your mobile device. On the main page, tap the “Login” button located in the bottom right corner. On the login page, enter your VideoGram username and password. Once you have entered your credentials, tap the “Login” button. You should now be logged in to your VideoGram account. Please let me know if you need any further assistance.只要有正确的上下文信息,GPT-3就可以进行消歧义。
使用GPT-3生成答案时可能出现的问题
前面的例子都很正常运行。然而,这种聊天机器人可能会失败的几种方式。
如果我们询问“Is the mobile app free?”,将登录文档作为上下文传递给GPT-3,你通常会得到一个答案,比如“Yes, the VideoGram mobile app is free to download and use”,即使这样的信息并没有包含在上下文信息中。生成虚假信息对于客户服务聊天机器人来说非常可怕!
当用户问题可以在上下文中找到答案时,GPT-3很少生成虚假信息。由于用户问题通常是短小模糊的文本,我们不能总是依赖语义搜索步骤来检索正确的文档,因此我们总是容易受到虚假信息生成的影响。
结论
GPT-3非常适用于创建对话式聊天机器人,并能够根据插入的上下文信息回答一系列具体问题。然而,仅依靠上下文信息使模型产生答案很困难,因为模型往往会产生幻象(hallucination)(即生成新信息,可能是错误的)。生成虚假信息是一个不同严重程度的问题,这取决于使用情况。
相关论文
- Nadeem, M., Bethke, A., & Reddy, S. (2021). StereoSet: Measuring stereotypical bias in pretrained language models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 5356–5371. https://doi.org/10.18653/v1/2021.acl-long.416 ↩
- Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y., Madotto, A., & Fung, P. (2022). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys. https://doi.org/10.1145/3571730 ↩