目录
前言

目前中国源代码贡献量已达到世界第二,开源软件开发者数量也已突破800万,居全球第二。在众多开发者的关注下,2023年开放原子全球开源峰会在北京隆重举办。各大开源领军企业都拿出了自己的“看家本领”,有阿里巴巴的龙蜥社区,有华为云的CCE Turbo,有腾讯云的TDSQL,有百度的XuperChain……但是最吸引我的是英特尔的展台和软硬协同开源论坛。
英特尔的开源之路

英特尔作为处理器领域的绝对领导者,早在上世纪80年代就开源了6位微处理器8086源代码,就此开启了x86架构的辉煌时代。而以x86架构为基础的个人电脑,引领了长达20多年的互联网热潮。这次开源极大地促进了处理器技术的发展,至今还被计算机科学家们作为典型教材。
在40多年的时间里,英特尔从未在开源上停下脚步。在很多颇负盛名的开源项目,如Linux kernel、Tensorflow、TBB、MKL、Kubernetes等,都能看到英特尔贡献的身影。至今,英特尔已经是Linux kernel最多的贡献者、并主导了100余个开源项目、参与维护300多个社区项目,同时也是700多个标准组织的会员。

在软硬协同开源论坛上,英特尔的科学家和工程师们分享了英特尔的软件开源生态建设、云原生的开源云解决方案、开源跨平台安卓工具Celadon等。然而作为一位算法工程师,最吸引我的是英特尔高级首席AI工程师张宇博士分享的英特尔在人工智能方向的优势与创新。
拥抱人工智能
AIGC的浪潮之巅

人工智能的浪潮之巅已经到来,这是一个全新的时代,智能化正在成为现实。随着人工智能技术的发展,智能化的应用正在让人们的生活变得更加便捷,更加高效。在过去的几十年中,科学家们一直在探索人工智能技术,并取得了许多重大突破。这些突破包括机器学习、深度学习、自然语言处理、计算机视觉等方面的技术,这些技术正在被广泛应用于生产、服务、医疗、教育等领域。
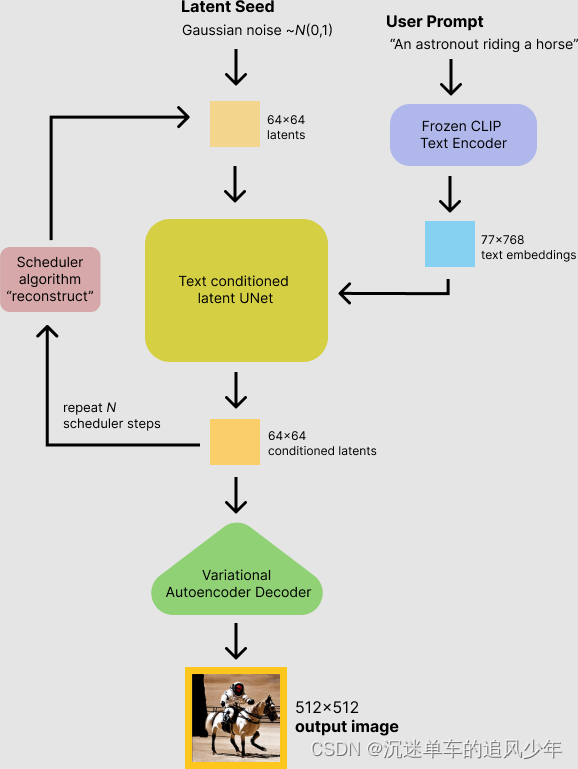
最近几年,以ChatGPT为代表的大型语言模型(LLM)和以Stable Diffusion为代表的多模态生成模型正深刻影响我们。在峰会现场展台中,英特尔工程师热情地为大家介绍了英特尔对人工智能,特别是针对生成模型的支持,并现场演示了stable diffusion加速部署,可以做到几秒的时间内生成一张高分辨率的图像,惊艳的效果赢得了在场的开发者们一致好评。

在AIGC的浪潮之巅中,涌现出了许多优秀的人工智能企业。这些企业通过自己的研发和创新,不断推动着人工智能技术的发展,创造出更多的人工智能应用和商业价值。同时,这些企业还积极参与到人工智能开源社区中,推进人工智能技术的开放和共享。英特尔无疑是在人工智能开源社区中发挥着重要作用的企业之一,英特尔一直致力于人工智能技术的研究和创新,推出了许多优秀的人工智能产品和解决方案,特别是全链路的软硬协同人工智能解决方案,结合了英特尔在硬件和软件方面的优势,能够提供全方位的人工智能解决方案,从算法设计到算力支持,从应用开发到系统调试,实现了人工智能技术的全链路支持。
全链路AI解决方案

英特尔的全链路软硬协同人工智能解决方案能够提供更加高效和优化的算力支持,充分利用了英特尔在硬件方面的多年积累,提供高效的并行计算和优化的数据处理能力,特别是英特尔推出了针对边缘人工智能优化的处理器: 酷睿™处理器、Data Center GPU Flex 系列、至强® 可扩展处理器等。这些处理器和芯片都针对不同的边缘人工智能场景进行了优化,具有高效、低功耗、高性能等特点。例如Data Center GPU Flex 处理器在媒体计算引擎和 Xe 矩阵扩展(XMX)加持下,Flex 170 在多种不同的编码格式和 AI 模型的组合中的性能测试表现,都超过了行业主流解决方案提供商。特别是在人工智能视觉推理上,可以结合多种场景使用,通过对视频流进行解码处理再进行 AI 运算,实现了多种工作负载融合的应用场景,展现了强大的灵活性。

除了这些专门针对人工智能优化的硬件,英特尔的全链路软硬协同人工智能解决方案还提供了非常丰富和完整的软件支持。例如 TensorFlow、CNTK、Caffe 这些著名的深度学习框架,都有英特尔的贡献。除此之外,英特尔提供了多种人工智能开发工具套件,包括Intel® Extension for Pytorch、Intel® Extension for Tensorflow、英特尔®高级矩阵拓展引擎和英特尔® Nervana™ 工具包等,充分释放了英特尔硬件对性能,进行软硬件协同优化加速运算。这些工具套件涵盖了深度学习模型的训练和部署推理优化的全过程,可以帮助开发者快速构建自己的人工智能应用。
极致性能优化
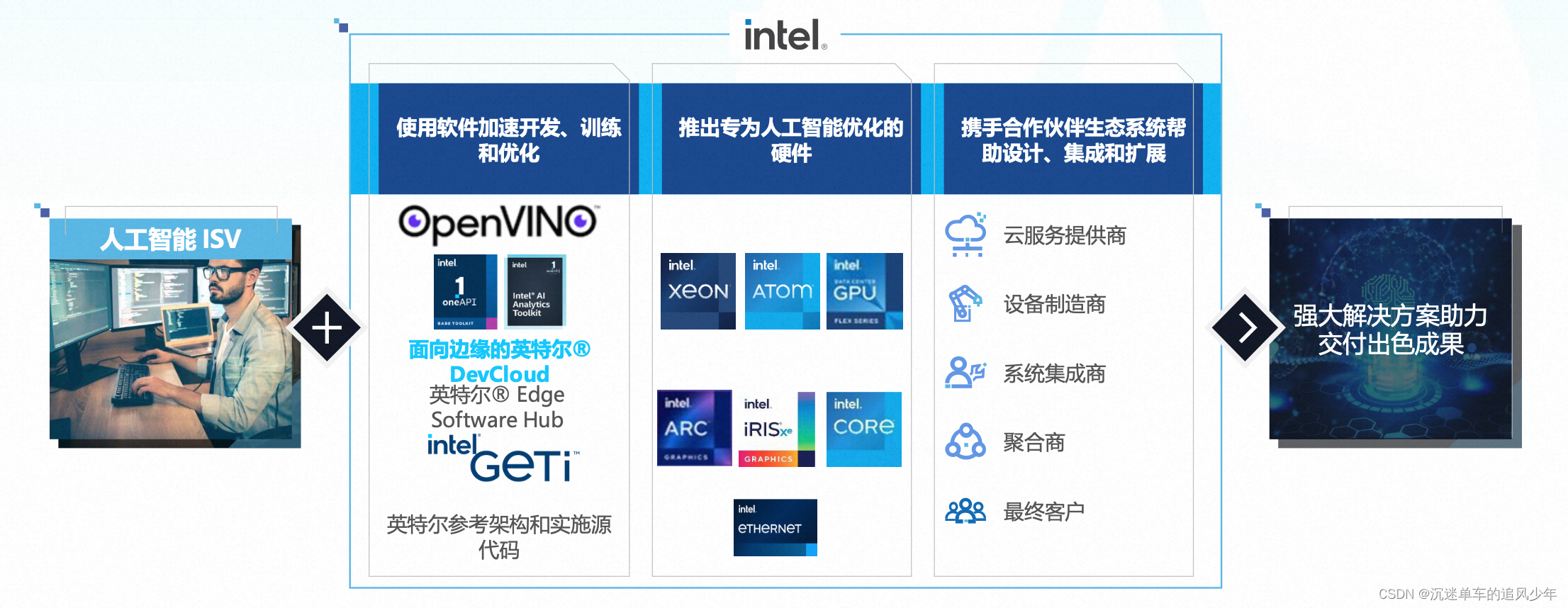
虽然目前有不少厂商都提供了人工智能解决方案,但是英特尔的软硬协同全链路解决方案能最大程度上释放性能,做到最极致的优化。现场张宇博士着重介绍了英特尔的开源套件OpenVINO,OpenVINO基于卷积神经网络(CNN)而设计,支持从边缘到云的深度学习推理。OpenVINO可以实现“一次编写,随处部署”,将编译后的模型转换成OpenVINO通用格式,可在包括 英特尔 CPU、GPU、VPU 和 FPGA 在内的英特尔硬件平台(包括加速器)一键部署上,扩展工作负载并实现性能最大化。
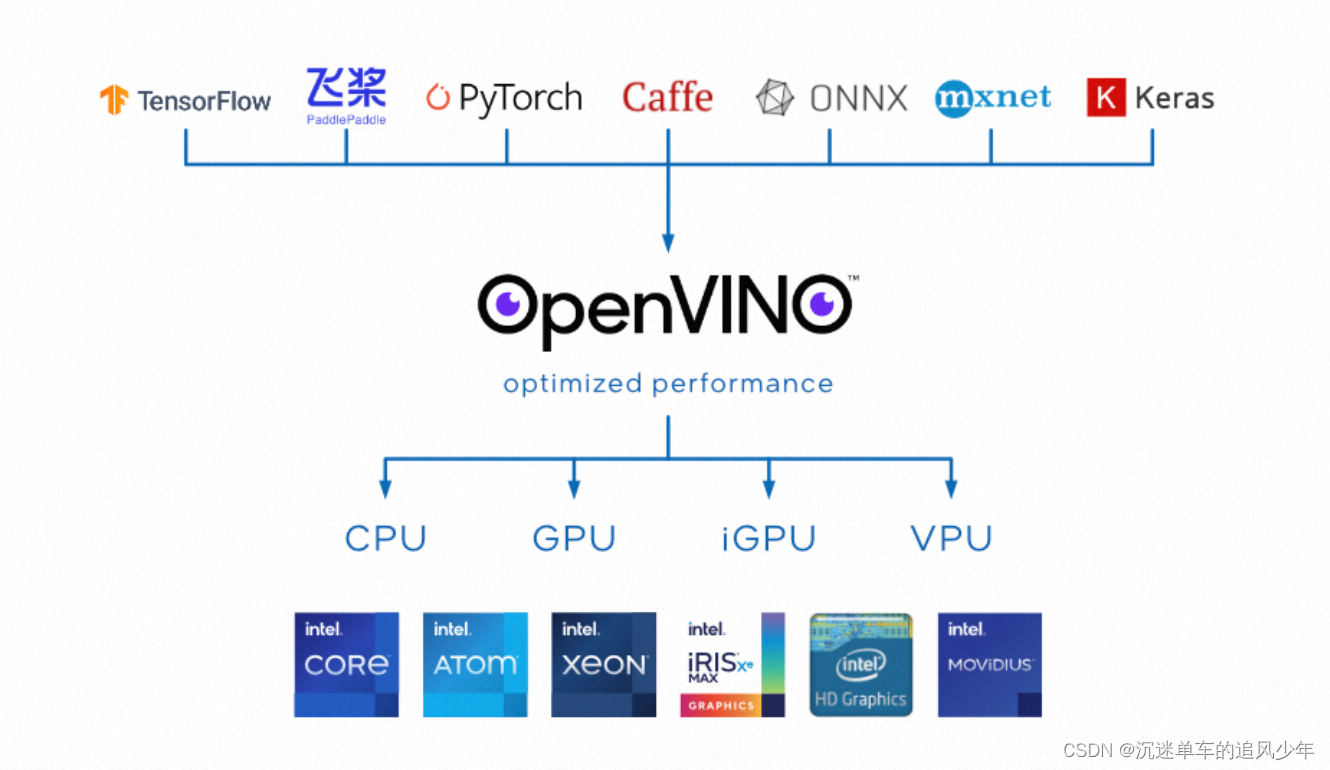
在最新的版本发布中,OpenVINO特别针对生成型AI的模型支持,例如GPT、CLIP、 BLIP,、Stable Diffusion 2.0、ControlNet等,针对这些模型和底层算子做了很多极致优化。还提供了非常全面的性能优化指南,包括精度检查器、训练后优化工具和其他用于精度测量、性能基准测试和应用调优的工具。OpenVINO开发套件可以让更多的开发者们可以在AIGC的浪潮中快速上手,不仅能够快速部署自己的AI任务,还可以最大限度地提高推理性能。
结束语
AI的大时代悄然而至,科技的发展正无处不在改变我们每一个人的生活。英特尔在中国开源的持续发力,共同为中国开源技术生态繁荣发力,在这个最好的时代,让我们拥抱AI,尽情享受这个浪潮之巅。
