1 代表模型
1.1 Imagen(谷歌,未开源)
-
技术方案
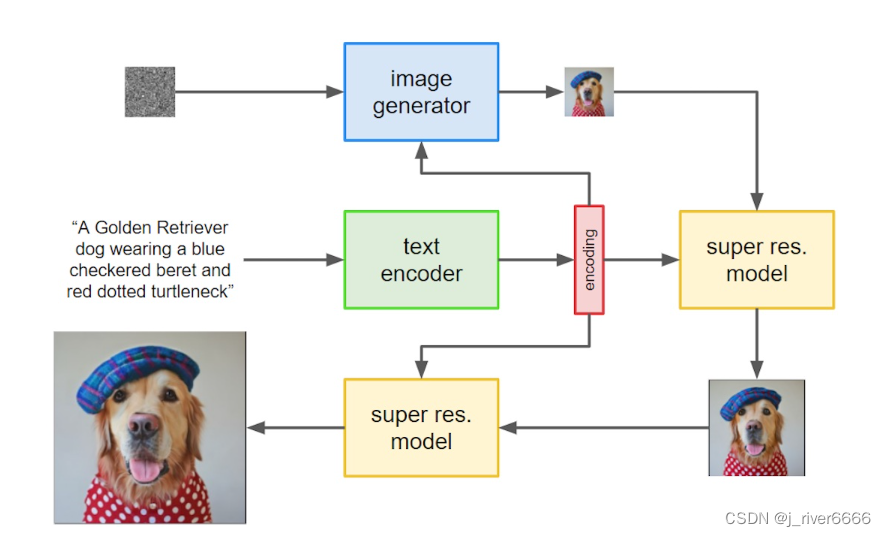
1.把prompt输入到frozen text encoder中,得到text embedding 2.把text embedding输入到扩散模型中。先先成低分辨率的图像,然后再串联2个super-resolution网络,这两个网络的输入是前面的低质量图像和text embedding。最终就可以输出高质量的图像。
-
模型结构
-
text_encoder: T5 (11B)
-
diffusion_model: U-net
-
Super-Resolution model: Efficient U-net
-
1.2 DALLE2 (OpenAI,未开源)
-
技术方案
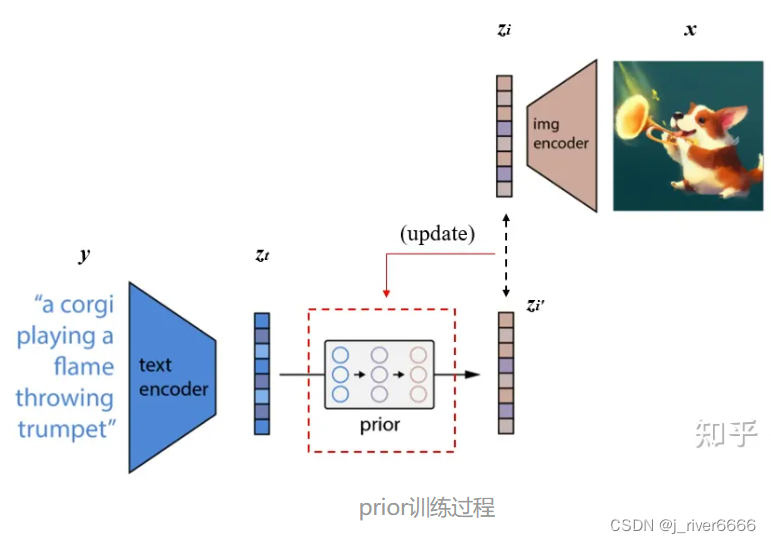
1. 训练CLIP,使其能够编码文本和对应图像 这一步是与CLIP模型的训练方式完全一样的,目的是能够得到训练好的text encoder和img encoder。这么一来,文本和图像都可以被编码到相应的特征空间。对应上图中的虚线以上部分。 2. 训练prior,使文本编码可以转换为图像编码 将CLIP中训练好的text encoder拿出来,输入文本y,得到文本编码z-t。同样的,将CLIP中训练好的img encoder拿出来,输入图像x得到图像编码z-i。我们希望prior能从z-t获取相对应的z-i。假设经过prior输出的特征为z-i',,那么我们自然希望z-i与z-i'越接近越好,这样来更新我们的prior模块。最终训练好的prior,将与CLIP的text encoder串联起来,它们可以根据我们的输入文本y生成对应的图像编码特征z-i了。 3. 训练decoder生成最终的图像 我们要训练decoder模块,从图像特征z-i还原出真实的图像x。

-
模型结构
-
text encoder, image encoder: clip(GPT + ViT)
-
prior: Unet
-
decoder: Unet
-
1.3 StableDiffusion (stability.AI,开源)
-
技术方案
1. 训练autoencoder, 包括encoder和decoder两部分,实现对图片的编码、解码。 2. 训练diffusion模型。使用autoencoder中的encoder对图片编码,映射到latent space,在图片latent space上进行扩散,显著降低计算量和计算时间。

-
模型结构
-
autoencoder: VQGAN(几百M)

-
diffusion model:U-net(856M)


-
text encoder: clip text encoder(63M)
-
2. 开源数据集
-
LAION-400M
-
4亿图文对
-
10TB
-
图片未经过滤处理
-
-
LAION-5B
-
50亿图文对
-
80TB
-
数据多样,包含各领域图片,且过滤不适图片
-
3. 自定义训练
3.1 数据处理
采用图片-文本对的形式,如 0001.jpg 0001.txt。 图片需要裁剪为正方形,如512*512。
3.2 GPU
目前大部分扩散模型显存占用均在10G以下,单张16g V100即可进行训练/推理
3.3 训练方式
3.3.1 textual inversion
paper(2022.8 arxiv): An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion (readpaper.com)
提出了 personalized text-to-image generation,也即个性化的文转图生成。可以基于文本+用户给的几张图("new concepts")来生成新的图像。
提出了“textual inversions”用于把图片概念转换成pseudo-words(text encoder的embedding),用这个embedding表示新的concept从而生成一些具备这样概念的图片。

-
特点
-
原模型参数固定,只学习自定义词的embedding
-
只需要少量图,单张v100几小时可完成训练
-
-
效果
-
相似图生成

-
风格迁移

-
概念组合

-
3.3.2 dreambooth
dreambooth 可适应用户特定的图像生成需求。"只需几张指定物体的照片和相应的类名(如“狗”)作为输入,并添加一个唯一标识符植入不同的文字描述中,DreamBooth 就能让被指定物体“完美”出现在用户想要生成的场景中。
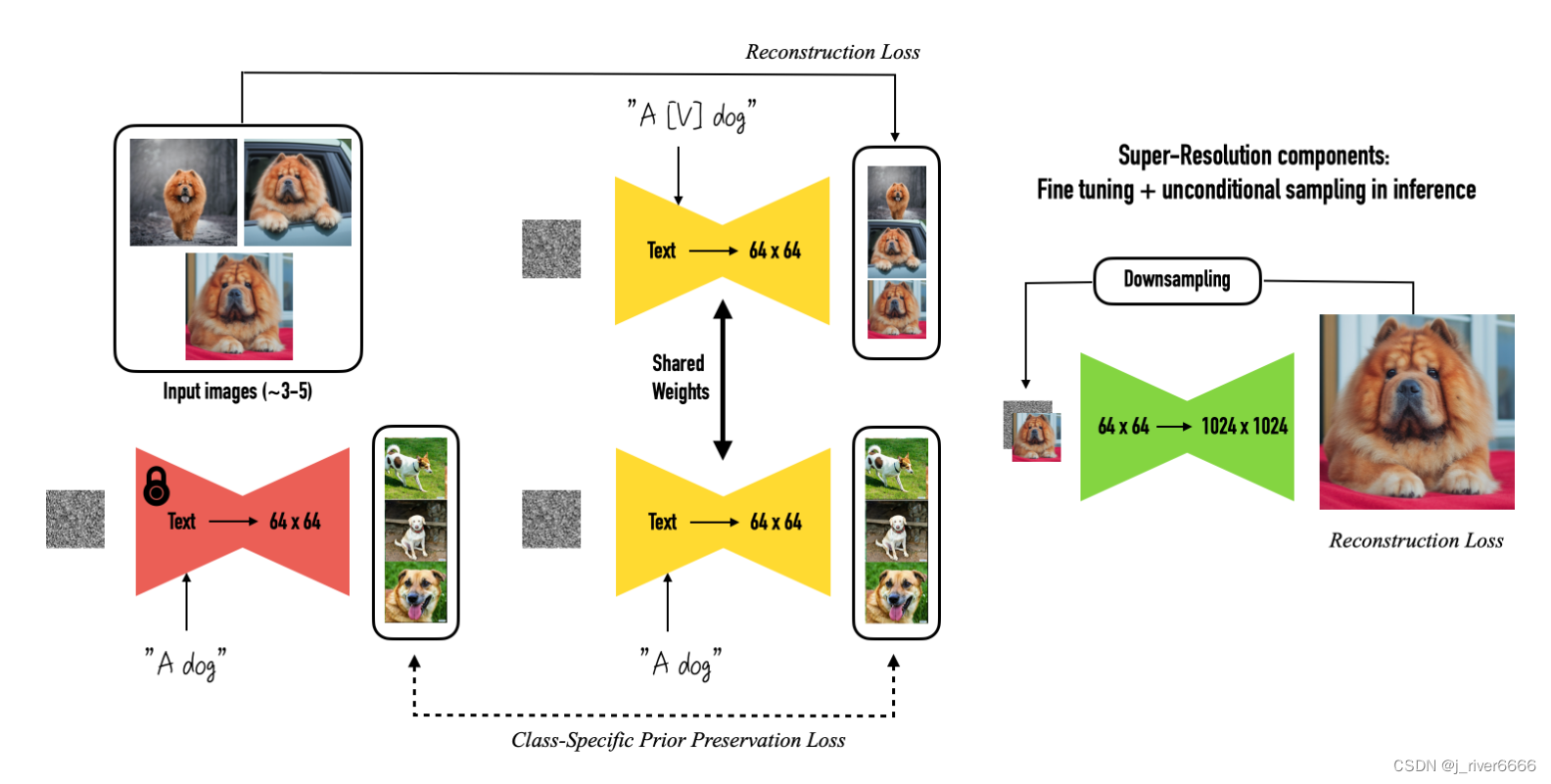
Given ~3-5 images of a subject we fine tune a text-to-image diffusion in two steps: (a) fine tuning the low-resolution text-to-image model with the input images paired with a text prompt containing a unique identifier and the name of the class the subject belongs to (e.g., "A photo of a [T] dog”), in parallel, we apply a class-specific prior preservation loss, which leverages the semantic prior that the model has on the class and encourages it to generate diverse instances belong to the subject's class by injecting the class name in the text prompt (e.g., "A photo of a dog”). (b) fine-tuning the super resolution components with pairs of low-resolution and high-resolution images taken from our input images set, which enables us to maintain high-fidelity to small details of the subject.

-
特点
-
对模型参数进行微调
-
只需要少量图片,单张v100几小时可完成训练
-
-
效果
-
特定物体构图

-
调整特定物体属性/风格


-
4 开源模型文件
-
stable diffusion 系列

-
太乙中文stable diffusion模型
首个中文Stable Diffusion模型开源,IDEA研究院封神榜团队开启中文AI艺术时代


-
其他个性化微调模型
5 AI绘图应用

-
应用场景
-
美图工具
-
海报/人物/头像/广告/插图设计
-
6 AI绘图局限
-
模型生成的图片和训练图片相似,有一定的创造性,但难以做到“无中生有”,即生成从未未见过的主体或内容。
-
存在版权风险